基于深度学习的车辆和行人检测算法的研究
2021-10-16张凤
张凤

摘要:针对实际交通环境下行人和车辆检测问题,提出一种基于YOLOv3改进的目标检测网络YOLO-CP,对YOLOv3网络结构进行压缩剪枝,并进行特征提取的优化,使用自主采集标注的交通数据集,进行稀疏化训练。在实际交通场景中,YOLO-CP在GPU下检测速度达到25帧/秒,车辆检测准确率达到96.0%,行人检测准确率达到93.3%,优化算法满足了ADAS对实时性和高精度的要求。
关键词:行人检测;车辆检测;YOLOv3;ADAS
中图分类号:TP391.41;TP18 文献标识码:A 文章编号:2096-4706(2021)07-0059-04
Research on Vehicle and Pedestrian Detection Algorithm Based on Deep Learning
ZHANG Feng
(Shandong Huayu University of Technology,Dezhou 253034,China)
Abstract:Aiming at the problem of pedestrian and vehicle detection in actual traffic environment,this paper proposes an improved target detection network YOLO-CP based on YOLOv3,which compresses and prunes the YOLOv3 network structure,optimizes the feature extraction,and uses the independently collected and labeled traffic data set for sparse training. In the actual traffic scene,the detection speed of YOLO-CP under the GPU reaches 25 frames/s,the vehicle detection accuracy rate reaches 96.0%,and the pedestrian detection accuracy rate reaches 93.3%.The optimization algorithm meets the real-time and high-precision requirements of ADAS.
Keywords:pedestrian detection;vehicle detection;YOLOv3;ADAS
收稿日期:2021-03-22
基金项目:2020年山东华宇工学院科技计划项目(2020KJ16)
0 引 言
近年来,随着交通车辆数量的高速增长,尤其是共享单车的兴起,人们出行方式发生巨大改变,使得交通安全面临的挑战越来越大。ADAS(高级驾驶辅助系统)和自动驾驶技术逐渐成为国内外研究者的关注热点,行人和车辆防碰撞预警系统是ADAS的关键技术之一,该系统要求能够实时准确地检测出前方的车辆,并及时向驾驶员发出警告,以采取有效措施,避免交通事故的发生。
目前,基于单目视觉的检测方法仍是实现前方行人和车辆检测的主要手段,与超声波、激光、雷达等技术相比,视觉检测更符合人眼捕捉信息的习惯,而且实施成本更低。车辆辅助驾驶系统的检测目标包括车辆、行人、交通标志等,其中行人和车辆是道路交通环境的主要参与者。行人不是刚性物体,姿势和外观是可变的,背景环境也是复杂的,增加了识别和检测的难度。尤其是车载行人和车辆实时检测系统是辅助驾驶系统的重要组成部分,一个体积小、功耗低、准确、实时的检测系统可以有效地保护行人和车辆。
基于机器学习的目标检测方法需要手工设计特征,提取到的特征好坏对系统性能有着直接的影响,尽管机器学习的方法不断优化,检测的效果有所改善,但实际交通场景复杂多变,当受外界环境如光照的变化、阴影、背景、遮挡等影响时,对单目视觉检测算法的影响比较大,不能有效的保证具有一定的检测准确率。
R-CNN[1]作为利用深度学习进行目标检测的先行者,提出选择性搜索等经典算法,提升了目标检测的准确率,而后相继出现Fast R-CNN[2]、Faster R-CNN[3]、YOLO[4]、YOLO 9000[5]、SSD[6]、YOLOv3[7]目标检测网络的优化。新型网络结构的提出(如AlexNet、VGG、ResNet[8]等)使得识别性能不断提高的同时,网络模型的参数和大小也不断增大,对存储资源和计算资源的需求也越来越高,需要对网络模型做压缩剪枝处理,才能用于嵌入式设备。随着嵌入式端性能的不断优化提高,将CNNs应用于ADAS关键环节之一的行人和车辆检测,有利于进一步推动自动驾驶汽车技术的发展。
1 网络结构设计
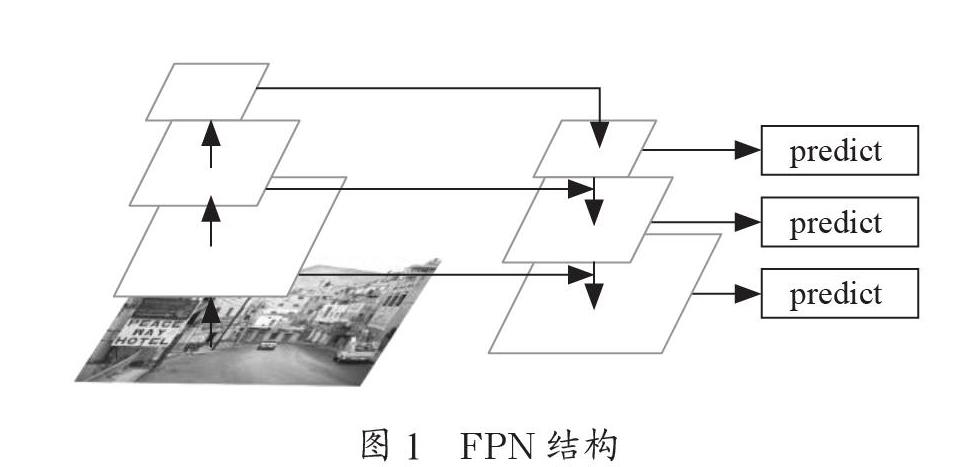
本文提出的检测系统所用的网络与YOLOv3(You Only Look Once v3)具有相似的结构,YOLOv3已被证明是一种先进的通用目标检测深度学习方案,YOLOv3网络结构则是在Darknet-19[9]网络的基础上结合残差网络ResNet组成,网络使用连续的3×3和1×1卷积层,并使用batch normalization[10]来提高稳定性,加速收敛。本文提出的检测系统使用独立的逻辑回归做二分类,采用金字塔网络结构FPN[11]进行多尺度预测,FPN结构如图1所示。
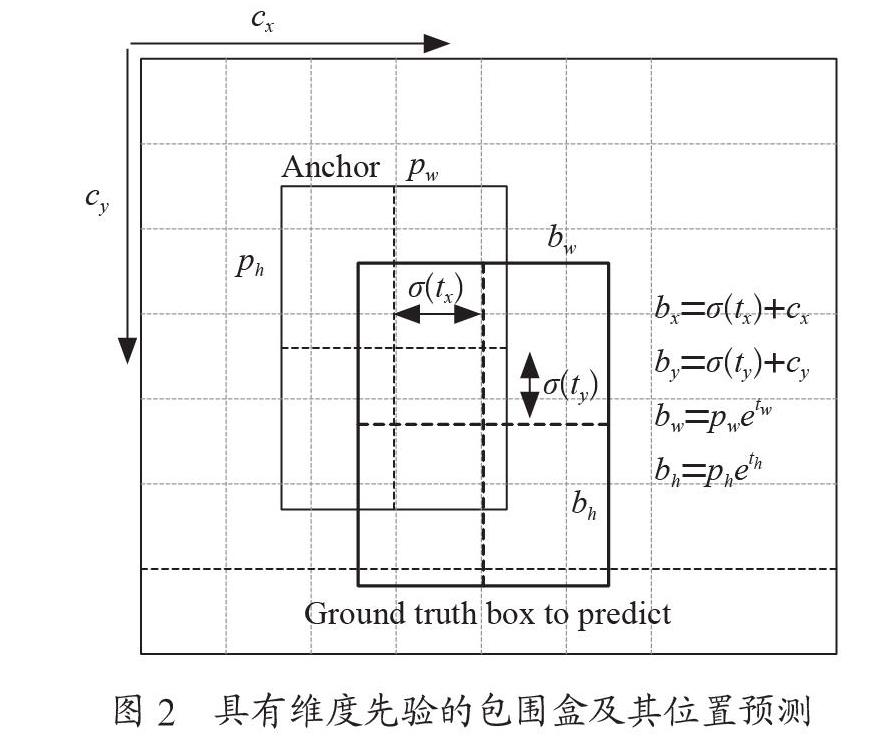
YOLOv3预测3种不同尺度的框,每种尺度预测3个box,最后预测得到一个3-d tensor,包含bounding box信息,目標信息以及类别的预测信息。针对检测系统的特点,使用k-means聚类来确定边界框的先验,选择9个聚类和3个尺度,然后在整个尺度上均匀分割聚类,产生anchor box的长宽分别是Pw和Ph,网络预测四个值:tx、ty、tw、th。如果某个单元距离图像的左上角距离为(cx,cy),则该单元内的bounding box的位置和形状参数如图2所示,bx、by、bw、和bh就是预测得到的bounding box的中心坐标和大小。输出的特征图的大小是N×N×[3×(4+1+C)],其中C是类别数。
在使用k-means聚类自动选择最佳初始框的时候,如果使用标准的k均值与欧氏距离,较大的box会产生比较小的box更多的误差。然而,想要增加IOU(Intersection over union)的分数,可使用以下距离公式:
d(box,centroid)=1-IOU(box,centroid) (1)
根据标准的k均值和欧氏距离结果,选择初始anchor boxes时,k=5。这些措施有利于保持原速度,提高精度。
2 压缩剪枝
一般来说,神经网络层数越深、参数越多,所得结果越精细。但与此同时,网络越精细,意味着所消耗的计算资源越多。对于嵌入式设备,模型的运行速度和文件大小都极其重要。神经网络的参数众多,但其中有些参数对最终的输出结果贡献不大而显得冗余,剪枝顾名思义,就是要将这些冗余的参数剪掉。
为了使本文的网络模型能够在嵌入式设备上使用,需要对YOLOv3网络进行压缩剪枝[12],去掉一些对网络不重要的通道参数,本文将压缩剪枝后的网络称为YOLOv3-CP。压缩剪枝的步骤如图3所示。
压缩率计算公式为:
(2)
其中:n表示权重个数,b表示存储的比特位数,k表示权重个数,用log2k表示编码的权重索引。Python版剪枝部分代码为:
def prune_by_std(self, s=0.5):
for name, module in self.named_modules():
if name in ['fc1', 'fc2', 'fc3']:
threshold = np.std(module.weight.data.cpu().numpy()) * s
print(f'Pruning with threshold : {threshold} for layer {name}')
module.prune(threshold)
剪枝將权重的数量减少了10倍,这样需要存储的数据量大大减少,量化进一步提高了压缩率。然后将最后的权值和权值索引进行哈夫曼编码,总的压缩率达到50%。
3 实验与结果
3.1 数据处理
本文检测目标是道路场景中常见的行人和车辆目标,因此,为进一步提高检测准确率,把COCO的80类目标转换为三个大类、七个小类:person、vehicle(包含:car、bus、truck、bicycle、motorbike)和background。训练所需的原始图像来源于已知开源的大型目标检测数据集:PASCAL VOC2007、PASCAL VOC2012、Cityscapes、COCO2014、Bdd100k数据集,以及自主采集的实际交通视频数据集CityImages,采用VOC2007数据集的格式及评价算法工具。首先需将Cityscapes、COCO2014和Bdd100k数据集转换为PASCAL VOC2007数据集格式,步骤为:
Step1:从PASCAL VOC2007、PASCAL VOC2012、COCO 2014、Cityscapes数据集中抽取出包含person、vehicle(car、bus、truck、bicycle、motorbike)实际场景中常见行人和车辆图片,并统一按照00000*.jpg的格式命名。
Step2:将Cityscapes、COCO2014、Bdd100k数据集按照PASCAL VOC2007 数据集格式要求,制作包含person、vehicle(car、bus、truck、bicycle、motorbike)目标的xml标注文件。
Step3:对自主采集的实际交通视频数据集CityImages按照Step1和Step2的要求对数据集进行标注。本文制作的车辆样本数据集包括140 000张彩色三通道图像,训练集和测试集按照4:1的比例划分。
Step4:扩展雨雾天气场景下的图片,适应不同环境下的行人和车辆检测,提高模型的泛化能力,进而提高检测的准确率。
3.2 模型训练
实验中,采用流行的深度学习框架Caffe实现了检测模型,根据YOLOv3的网络结构作相应修改,为了加快网络的训练速度,采用GPU的计算模式,训练样本时采用的主要硬件配置为:处理器Intel(R) Core(TM) i7-6850K CPU @3.60GHz 六核,内存32 GB,GPU卡,NVIDIA GeForce GTX TITAN X。
网络剪枝后的训练步骤分为两步:
Step1:采用在ImageNet数据集预训练得到的VGG16模型作为训练的模型,来训练包含person、vehicle(car、bus、truck、bicycle、motorbike)目标的数据集,并对原参数进行调优,初始学习率设置为0.001,冲量设置为0.9,权重衰减设置为0.000 5,batchsize大小为64,迭代次数为30万次,得到训练模型YOLOv3.caffemodel。
Step2:对Step1训练得到的模型YOLOv3.caffemodel进行压缩剪枝,将压缩后的模型作为训练的原始模型,来训练包含person、vehicle(car、bus、truck、bicycle、motorbike)目标的数据集,并对参数进行调优。在训练过程中,使用随机梯度下降,初始学习率设置为0.001,冲量设置为0.9,权重衰减设置为0.000 5,batchsize大小为128,迭代次数为30万次。在训练期间,使用数据增强方法,通过对输入图片进行随机左右翻转,随机扭曲图像的饱和度、色调、对比度和亮度等,防止模型的过拟合现象。
在训练过程中,改变模型输入大小,使模型对图像具有鲁棒性。对于每个图像,除了执行水平翻转之外,还随机调整其大小,然后每10轮将其送入网络。具体来说,调整每个图像的大小为{320,352,384,416,448,480,512,544,576,608}中的一个。因此,最小的选项是320×320,最大的是608×608。在将图像输入模型之前,从每个图像中减去整个数据集的平均RGB值,以减少概率分布对像素值的影响。这种训练方法迫使模型适应不同输入分辨率。
在网络训练期間,采用的YOLOv3网络将Softmax多分类损失函数换为二分类损失函数,因为当图片中存在物体相互遮挡的情形时,一个box可能属于好几个物体,这时使用二分类的损失函数就会更有优势。
3.3 模型检测
以下为行人和车辆检测的步骤:
Step1:在检测阶段,输入经过压缩剪枝后训练得到的网络模型YOLOv3-CP。
Step2:使用NMS算法来消除对同一行人或者车辆的重复检测并使检测框均匀分布。为避免误报,本文选择0.7作为从YOLOv3网络输出的分类结果的阈值。
Step3:处理视频的时候,对视频的每一帧,按照序列或者尺寸尽量与之前检测过的行人或车辆匹配。通过与之前记录的尺寸和速度的估算做比较,若是二者的重合度超过0.5,则认为匹配成功。若匹配不成功,则将它们认为是新出现的行人或车辆,超过十帧还没有被识别的行人或车辆将会被忽略,得到最终结果之前,行人或车辆必须在至少十帧内被检测到。
Step4:根据世界坐标和图像坐标的转换关系,测量和前方行人或车辆的距离,设定阈值,检测到小于此阈值的行人或车辆,被认为有可能会发生碰撞,并生成报警信息,提醒驾驶员,注意前方安全。
3.4 实验结果及分析
本文将训练和测试图像尺寸预设定为320×320,本文训练自己建立的数据集(7类)得到的模型和YOLOv3算法的80类数据集训练得到的模型在PASCAL VOC 2007测试集上的测试对比结果如表1所示。
对训练得到的网络模型进行50%的压缩剪枝,然后进行微调再训练,经过压缩剪枝之后,模型的参数数量降低了一半,模型的大小由580 M降低为80 M,并且基本保持了检测精度不变,如表2所示。
为验证算法的有效性,采用了实际不同场景下的视觉图像进行测试。测试结果如图4所示,图中以粉红线框出的目标为检测出的行人,以黄色线框出的目标为检测出的车辆。
实验结果表明,适度增加样本的数量和多样性,可以提高深度网络的检测准确度,尤其对较小目标的检测精度增加明显,适当降低深度网络的检测目标的类别数,一定程度上提高了目标检测的准确率。
4 结 论
本文利用深度学习目标检测算法YOLOv3的框架,对网络结构进行压缩剪枝。扩展了训练所用的数据集,根据实际场景自主采集交通视频,并对其进行标注,使得训练的特征更加接近实际场景。实验结果分析表明,在满足实时性或准实时性的要求下,本算法的行人检测准确率可以达到93.3%,车辆检测准确率可以达到96.0%。嵌入式视觉和深度学习技术的结合为进一步开发具有避撞功能的安全辅助驾驶系统提供了可能。
参考文献:
[1] ROSS G,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[2] GIRSHICK R. FAST R-CNN [C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:10-15.
[3] REN S Q,HE K M,Girshick R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE transactions on pattern analysis and machine intelligence,2017,39(6):1137-1149.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:13.
[5] REDMON J,FARHADI A. YOLO9000:Better,Faster,Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6517-6525.
[6] LIU W, ANGUELOV D, ERHAN D,et al. SSD:Single Shot MultiBox Detector [C]//Computer Vision-ECCV 2016. Amsterdam:Springer,Cham,2016:21-37.
[7] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-18).https://arxiv.org/abs/1804.02767.
[8] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:770-778.
[9] REDMON J. Darknet:Darknet:Open Source Neural Networks in C. [EB/OL].[2021-03-10].http://pjreddie.com/darknet/.
[10] IOFFE S,SZEGEDY C. Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift [J/OL].arXiv:1502.03167 [cs.LG].(2015-02-11).https://arxiv.org/abs/1502.03167.
[11] LIN T Y,Dollár P,Girshick R,et al. Feature Pyramid Networks for Object Detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:936-944.
[12] HAN S,MAO H,DALLY W J. Deep Compression:Compressing Deep Neural Networks with Pruning,Trained Quantization and Huffman Coding [J/OL].arXiv:1510.00149 [cs.CV].(2015-10-01).https://arxiv.org/abs/1510.00149.
作者簡介:张凤(1991—),女,汉族,山东临沂人,讲师,硕士研究生,研究方向:图像处理。
