基于不完整乳腺癌数据的模型预测研究
2021-10-16邓钰芳


摘要:针对不完整乳腺癌数据问题,该研究提出kmeans-KNN方法处理缺失值。首先对训练集进行聚类并采用KNN进行缺失值填充,基于完整训练集训练线性回归模型填充测试集的缺失值,然后使用机器学习算法XGBoost、RF、KNN、SVM对完整训练集进行训练建模,利用建立好的模型对完整测试集进行测试。结果证明kmeans-KNN在缺失值预处理上优于EM、MICE等常用的缺失值填补方法,在准确度和AUC上,kmeans-KNN+SVM取得最优。
关键词:不完整数据;乳腺癌;诊断预测
中图分类号:R737.9 文献标识码:A 文章编号:2096-4706(2021)07-0050-04
Model Prediction Research Based on Incomplete Breast Cancer Data
DENG Yufang
(School of Computer,Electronics and Information,Guangxi University,Nanning 530004,China)
Abstract:Aiming at the problem of incomplete breast cancer data,the study proposed the kmeans-KNN method to deal with missing values. First,cluster the training set and use KNN to fill in missing values,and train a linear regression model based on the complete training set to fill in missing values in the test set. Then,machine learning algorithms XGBoost,RF,KNN,and SVM are used to train and model the complete training set and complete test is used to test. The results show that kmeans-KNN is better than EM,MICE and other common missing value filling methods in missing value preprocessing,and kmeans-KNN+SVM is the best in accuracy and AUC.
Keywords:incomplete data;breast cancer;diagnosis prediction
收稿日期:2021-03-09
0 引 言
据国际癌症研究机构(IARC)发布的最新数据显示[1],截至2020年乳腺癌已成为全球女性发病率最高的癌症。在大数据时代,使用机器学习方法建立乳腺癌诊断模型进行诊断预测为医生的临床决策提供科学参考是非常有意义的。然而机器学习方法的应用是基于完整可分类的数据。如果不对缺失数据进行处理则很难通过机器学习方法建立有效的生存预测模型,缺失数据的存在给乳腺癌生存预测带来了很大的难度,甚至有可能会使整个数据失去价值。因此针对缺失数据进行合理处理是非常有必要的。
针对不完整数据的处理,国内外已有大量的相关研究。如Hadi等人采用不处理、均值、EM和K-近邻(KNN)四种缺失值处理方法进行比较研究,并使用KNN、决策树、逻辑回归和支持向量机(SVM)四种机器学习算法构建乳腺癌生存模型,结果显示KNN+KNN建立的模型最佳,而均值填充法的效果远差于EM和KNN填充法[2]。但是大多数研究是先删除缺失数据然后基于随机缺失假定来采用缺失值填充法进行缺失值处理,并用均方根误差和错误率评价填充效果[3,4]。而实际应用过程中往往无法验证随机缺失的假定是否正确[5],且删除数据容易导致构造模型时出现偏倚。正如文献[3]所说的要根据数据集缺失情况和所要研究内容来决定缺失值处理方法,因此为建立有效的乳腺癌诊断模型,本文提出kmeans-KNN进行缺失值预处理,然后采用XGBoost、随机森林(RF)、KNN、SVM四种机器学习算法进行建模。
1 不完整乳腺癌数据的预处理方法
数据缺失问题一直是数据预处理的挑戰之一。目前对缺失数据的处理的常见方法有(1)删除(2)不处理(3)填充[3]。删除往往是对含有缺失值的样本进行删除,不处理则是对含有缺失值的样本不进行任何处理,然而在基于以机器学习为基础的数据挖掘中,除了采用XGBoost、决策树C4.5树形模型进行数据建模外,其他的机器学习方法都难以处理含有缺失值的数据。填充法是对存在缺失值的样本进行填充。因此为提高乳腺癌诊断模型的精度,kmeans-KNN的缺失值处理方法步骤为:
(1)划分数据集D,训练集:测试集=70%:30%,将训练集完整的样本记为Dc,含有缺失值的样本记为Df。
(2)使用kmeans对Dc聚类。采用曼哈顿距离如式(1)计算数据集Df和Dc聚类之间的相似性。假设有样本X1(X11,X12,…,X1n)和X2(X21,X22,…,X2n),曼哈顿距离公式dist为:
dist=|X1k-X2k| (1)
并将Df数据划入到相应的Dc聚类,即对数据集D进行聚类。
(3)在聚类内采用KNN填充缺失值,然后合并聚类样本得到完整的训练集。
(4)基于训练集训练线性回归模型对测试集中的缺失值进行填充,最后利用机器学习算法建立乳腺癌的诊断模型。
2 机器学习算法
随着人工智能的成熟应用,机器学习算法已被广泛应用于医疗领域研究,如疾病的诊断预测和药物疗效预测等[6,7]。
2.1 XGBoost算法
XGBoost是陈天奇等人于2016年开发的机器学习算法[8],该算法是boosting算法中的一种,它是集成许多决策树模型的强分类器。其算法思想就是不断地添加树,即不断地进行特征分裂来生长一棵树,而每次添加一棵树,其实质是学习一个新函数,去拟合上次预测的残差。对训练集,當我们训练完成得到k棵树,则样本分数是根据这个样本的特征落到每棵树中对应的叶子节点的对应分数,最后将每棵树对应的分数加起来就是该样本的预测值。本文利用XGBoost分类算法对已做缺失值预处理的完整的乳腺癌训练集进行建模,首先根据基尼系数选出最优的特征,如密度,并把该特征作为树节点进行分裂。每棵树的深度为1,然后利用已建立好的模型对完整的测试集进行测试。
2.2 随机森林算法
随机森林算法(RF)是一个集成了多个决策树的集成分类器。给定训练集之后,(1)从训练集中采取有放回随机抽取n个样本作为决策树的训练集;(2)在训练决策树模型的节点的时候,在节点上所有的样本特征中选择一部分样本特征,并在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分以增强模型的泛化能力。重复(1)(2)两步,建立m棵决策树,在分类任务中,m棵决策树投出最多票数的类别为最终类别。本实验采用sklearn包中的随机森林分类器对完整乳腺癌训练集进行分类建模,该模型集成100棵决策树,每棵树采用基尼系数选出最优树节点进行分裂,每棵树的深度为1。
2.3 K-最近邻算法
K-近邻(KNN)算法是一种基本分类和回归的算法。对于给定的训练集,对新的输入样本,采用距离度量,如欧式距离、马氏距离等相似距离方法,在训练集中找到与该样本最邻近的K个样本,这K个样本的多数属于某个类,就把该样本分类到这个类中。且K的取值往往依赖于数据的分布特点。本文采用sklearn包中的KNN分类算法对完整的乳腺癌训练集进行分类建模,K的取值为3,即对每个样本寻找距离最近的3个样本来确定样本的类别。
2.4 支持向量机
SVM是按监督学习方式对数据进行二元分类的广义线性分类器,其基本模型是在特征空间上找到最佳的分离超平面使得训练集上二分类样本间隔最大。给定训练集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{+1,-1},i=1,2,…,n。wx+b=0为分离超平面,其中w,b分别为超平面的法向量和截距。则线性SVM学习算法步骤为:
(1)选择惩罚参数C>0,构造并求解凸二次规划问题求最优解α=(α1,α2,…,αn)T。
min aiajyiyj(xi ,xj)-ai,s.t. aiyi=0,
0≤αi≤C,i=1,2,…,n
(2)计算w=aiyixi,选择满足0≤α≤C的α,计算b=yj-aiyi(xi,xj)。
(3)求解超平面wx+b=0,则分类决策函数为f(x)= sign(wx+b)。
本文采用sklearn包中的SVM分类算法对完整的乳腺癌训练集进行分类建模,该算法的核函数为线性核函数,即在完整训练集中找到一条直线使得患良性和恶性肿瘤的患者能较好地区分开来。
3 数据集与缺失数据处理方法的效果评价
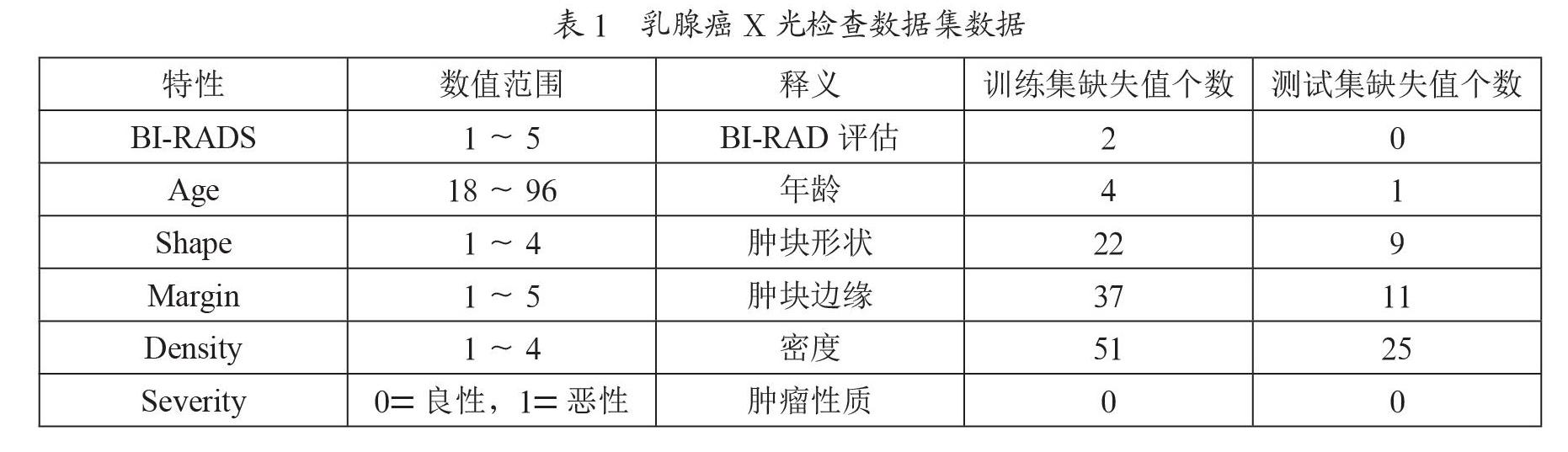
本实验数据来源于UCI数据集(http://archive.ics.uci.edu/ml/datasets.php)中的乳腺X光检查数据集,共961例包含6个属性其中最后一行为标签,如表1所示。
数据缺失类型分为三种:完全随机性缺失、随机缺失、非随机缺失[3]。完全随机缺失是缺失值与数据集中已知或者未知的特征是完全无关的。如该数据集中年龄字段是否缺失是完全随机的,它只取决于患者本身与患者的其他特征信息无关。随机缺失是指该类数据的缺失依赖于其他完全变量。如该数据集中缺失的肿块形状信息往往依赖于肿块大小。非随机缺失指的是数据的缺失依赖于不完全变量自身。如良性肿瘤患者的肿块大小信息缺失。
针对不完整乳腺癌数据建立乳腺癌诊断模型,模型评价指标是依据混淆矩阵的准确度、精确度、特异度、召回率和AUC面积。
4 仿真实验与结果
本文基于乳腺X光检查数据集进行实验,首先对该数据集随机地划分70%训练集和30%测试集,训练集和测试集中缺失值情况如表1所示。针对训练集的缺失数据,该实验先将训练集划分为无缺失值的完整样本和含有缺失值的不完整样本,对完整样本采用kmeans聚成三类,依据曼哈顿相似距离计算不完整样本和三个聚类中心的距离并将该样本划入最相似的聚类内,即对训练集聚为三类。在类内采用KNN填充法填充缺失值,使缺失值样本尽可能地符合实际值。为了验证kmeans-KNN方法的有效性,该实验还与EM、MICE等七种常用的缺失值处理方法进行比较研究。对于测试集中的缺失值则采用线性回归法训练训练集并填充相应的缺失值。数据缺失值预处理完成后,分别采用XGBoost、RF、KNN、SVM四种机器学习算法对训练集进行训练建模,这四种分类算法基于sklearn包实现,参数设置中XGBoost、RF的最大深度为1,SVM的核心函数为“linear”,其他的参数为sklearn包的默认设置。最后用训练好的模型对测试集进行测试,用准确度、精确度、特异度、召回率和AUC五个评价指标对模型效果进行评价。
实验结果如图1和图2所示,对于未处理数据,由于RF、KNN、SVM无法提供缺失值的自动处理而无法有效建模,而XGBoost可将缺失值作为稀疏矩阵自动处理从而建立有效的模型且模型的准确度和AUC分别为78.2%和78.9%。该实验将kmeans-KNN与EM等七种缺失值填充法进行比较研究,结果表明kmeans-KNN建立的模型准确度和AUC普遍优于其他结合方法。除了均值填充法外,经缺失值处理后XGBoost模型准确度、精确度、特异度、召回率、AUC普遍高于数据未处理建立的XGBoost模型效果。而在所有的方法结合中,kmeans-KNN+SVM建立的模型准确度和AUC最优,且对于在同一缺失值处理下,SVM建立的模型准确度优于XGBoost、RF、KNN模型的准确度,对于XGBoost、RF、KNN建立的模型效果比较则难分优劣。
5 结 论
本文提出的kmeans-KNN方法可以有效解决缺失数据问题,且SVM在分类性能上表现最优。通过该研究可知即使可以采用类似XGBoost方法在建模过程中自动处理缺失值,但先做预处理再建模的效果往往会更好。
参考文献:
[1] 世界卫生组织国际癌症研究机构(IARC).Estimated age-standardized incidence rates(World)in 2020 [EB/OL].(2021-03-02).https://gco.iarc.fr/today/online-analysis-multi-bars.
[2] DHAHRI H,MAGHAYREH E A,MAHMOOD A,et al. Automated Breast Cancer Diagnosis Based on Machine Learning Algorithms [J/OL].Journal of healthcare engineering,2019:4253641[2021-03-29].https://www.hindawi.com/journals/jhe/2019/4253641/.
[3] 劉星毅,农国才.几种不同缺失值填充方法的比较 [J].南宁师范高等专科学校学报,2007,24(3):148-150
[4] 李琳,杨红梅,杨日东,等.基于临床数据集的缺失值处理方法比较 [J].中国数字医学,2018,13(4):8-10+80.
[5] 闫世艳,郭中宁,何丽云,等.临床研究缺失数据多重填补敏感性分析方法 [J].世界科学技术-中医药现代化,2020,22(3):823-828.
[6] 彭佳丽,刘春容,李旭,等.采用XGBoost和随机森林探索中国西部女性乳腺癌危险因素 [J].现代预防医学,2020,47(1):1-4.
[7] 吴兴惠,周玉萍,邢海花,等.机器学习分类算法在糖尿病诊断中的应用研究 [J].电脑知识与技术,2018,14(35):177-178+195.
[8] CHEN T Q,GUESTRIN C. XGBoost:A Scalable Tree Boosting System [C]//KDD16:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York City:Association for Computing Machinery,2016:785-794.
作者简介:邓钰芳(1996.10—),女,汉族,广西南宁人,硕士研究生在读,研究方向:机器学习数据挖掘。
