嵌入通道注意力的YOLOv4火灾烟雾检测模型
2021-10-15谢书翰张文柱杨子轩
谢书翰, 张文柱, 程 鹏, 杨子轩
(西安建筑科技大学 信息与控制工程学院,陕西 西安710048)
1 引 言
随着经济的发展,大型场景的火灾检测任务越发重要,而传统火灾检测环节中传感器的检测能力较差,检测环节易受各种干扰因素的影响,从而使检测的准确率较低[1]。随着图像、视频处理技术的迅猛发展,各种基于图像、视频处理技术的烟雾检测算法被提出,在各种大型空间火灾检测任务中效果显著。烟雾先于火焰的发生而发生,且烟雾具有比火焰更强的扩散性,摄像头更加容易捕捉到烟雾图像,所以烟雾检测在火灾检测任务中显得格外重要。
目前,传统基于图像、视频的火灾烟雾检测算法主要是根据烟雾的形状、色彩、纹理、湍流、飘动等特征进行火灾烟雾识别,研究者通过研究烟雾的一种或多种特征,使用各种不同的分类算法进行火灾烟雾识别。Genovese等人[2]研究烟雾在YUV空间的颜色特性,得到烟雾检测算法,但是对于扩散缓慢的烟雾以及复杂背景的烟雾视频效果不佳。Sedlák V等人[3]研究了烟雾的运动特性、烟雾的颜色、面积增长率和运动方向,通过多特征进行分类识别,但是该方法小区域烟雾以及扩散不明显的烟雾区域检测效果较差。Gubbi等人[4]提出一种结合小波变换的检测烟雾方法,利用小波分解得到子带图像,提取出几十种烟雾特征。李红娣等人[5]通过图像金字塔和池化操作,提取LOBP和EOH直方图,得到烟雾特征矢量,最后放入支持向量机进行训练得到火灾烟雾识别模型。
这些算法从烟雾的本质特征进行研究,通过提取烟雾的一种或者多种特征进行烟雾识别。对于烟雾区域较大、背景单一的烟雾视频图像,传统的视频烟雾检测效果较好,但是火灾初期以及远距离火灾烟雾视频图像,烟雾区域往往较小,此时检测效果较差,出现漏检情况严重,而且不能在多场景任务中应用。
随着卷积神经网络CNN的发展,针对上述问题,Zhang等人[6]和张倩等人[7]利用Faster R-CNN对烟雾图像进行烟雾的识别。Frizz等人[8]和李鹏等人[9]使用卷积神经网络作为特征提取器,得到烟雾检测模型,较传统特征提取手段有着更佳的性能。富雅捷等人[10]通过选择性搜索法获取候选区域,将候选区域经过CNN网络得到高层特征,最后放入支持向量机训练,得到烟雾检测模型。冯路佳等人[11]提出了MD_CNN 烟雾检测模型,通过背景差分法得到运动目标区域,将运动目标区域放入CNN网络进行分类,最后得到烟雾区域。刘丽娟等人[12]利用SSD对烟雾图像进行识别。
在火灾烟雾检测这一特定的领域,使用深度学习方法的研究和数据集相对较少。本文提出一种改进的YOLOv4[13]的火灾烟雾检测算法,在YOLOv4的基础上嵌入通道注意力,以提高网络预测头的特征提取能力;使用K-means聚类获取更符合火灾烟雾检测的候选框尺寸;根据火灾烟雾检测这一二分类场景,精简了损失函数;训练阶段引入随机擦除和标签平滑,以降低过拟合风险。实验结果表明,该算法能够在多场景精准实现火灾烟雾检测。
2 本文算法
2.1 YOLOv4实时目标检测框架
YOLOv4是一种端到端的实时目标检测框架,由YOLOv3[14]改进而来,YOLOv4模型见图1。YOLOv4主要包含 CSPDarkNet53 特征提取主干网络、SPPNet(Spatial Pyramid Pooling Network)、PANet(Path Aggregation Network)多尺度预测网络以及网络预测头(YOLO Head)。其中CSPDarknet53由5个大残差块组成,这5个大残差块包含的小残差单元个数分别为1,2,8,8,4,也即是两个CBM卷积模块和一个CSPX卷积模块共同构成一个大残差块。在CSPDarknet53的最后一个特征层输出之后加入SPPNet,分别利用4个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13×13,9×9,5×5,1×1(1×1表示无处理),这种池化操作能够在几乎不增加模型的推理时间的情况下提高模型的推理能力。PANet由上采样和下采样两部分构成,充分利用了特征融合。
YOLOv4有3个网络预测头,3个网络预测头输出的形状分别为(13,13,18),(26,26,18),(52,52,18)。最后一个维度为18,是因为该检测算法基于火灾烟雾数据集,仅识别火灾烟雾一个类别,而YOLOv4针对每一个网络预测头存在3个先验框,每个先验框占据6维信息。
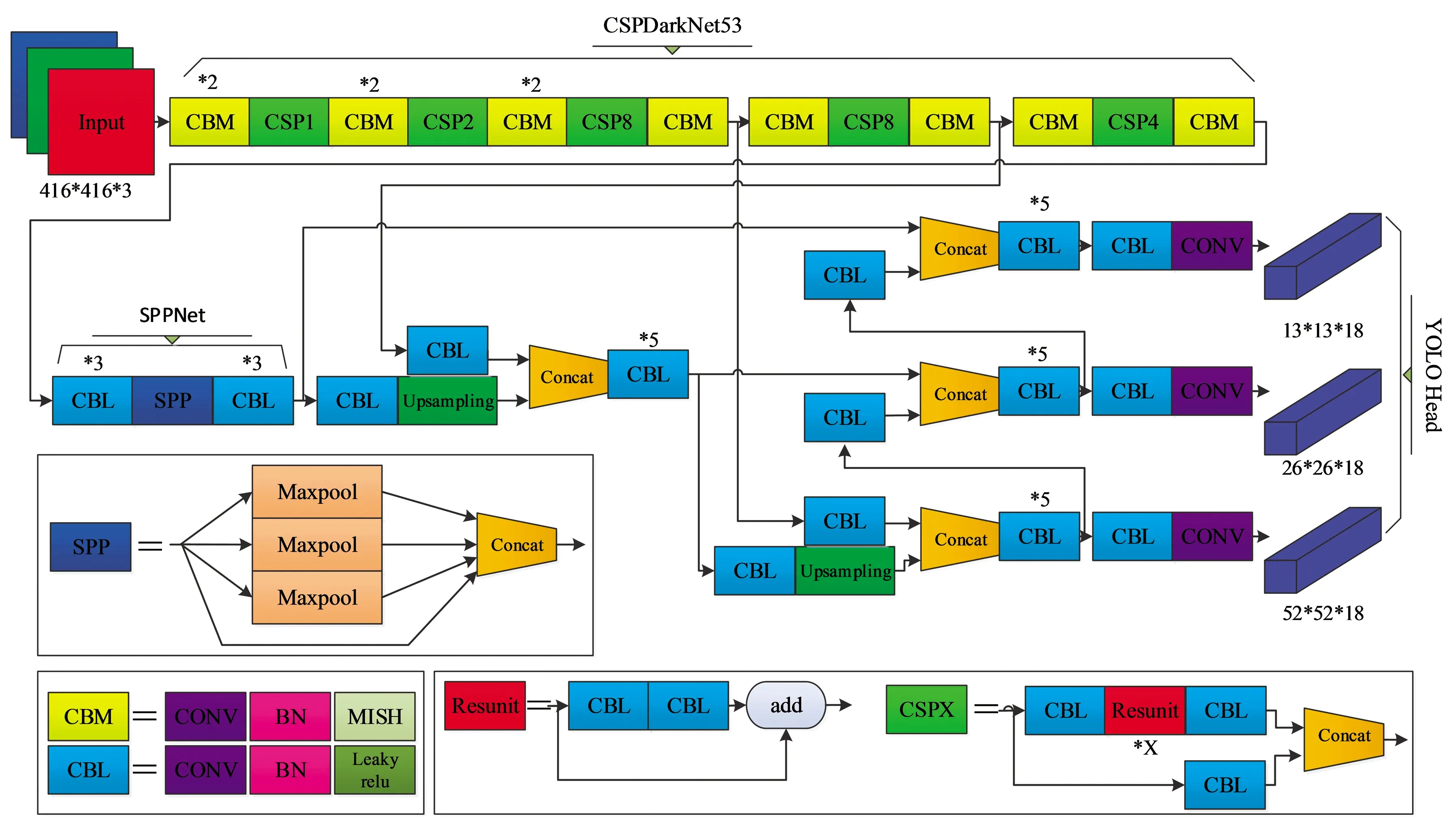
图1 YOLOV4 网络结构图Fig.1 YOLOV4 network structure diagram
2.2 候选框改进
网络预测头中候选框尺寸的设置是十分重要的,选择符合烟雾大小特征的候选框尺寸可以有助于烟雾预测框位置的回归,故在火灾烟雾检测任务中对候选框尺寸进行改进。
本文使用K均值聚类(K-means)为火灾烟雾数据集生成新的候选框尺寸,本文算法的输入火灾烟雾图像尺寸为416×416,使用K-means对416×416的火灾烟雾图像生成的9个新的候选框尺寸分别为12×16,19×36,40×28,36×75,76×55,72×146,142×110,192×243,362×322。
2.3 网络预测头改进
2.3.1 通道注意力
在每个卷积过程中,一些复杂的干扰信息不可避免地会分布在某些通道上,导致网络性能降低。注意力机制在神经网络中得到了广泛的使用[15-16],随着对通道注意力机制的深入研究,调整各通道信息的通道权重,对各通道信息赋予不同的权值,根据权值大小对通道信息进行筛选,这样能有效缓解干扰信息的影响。通道注意力的典型代表是SENet(Squeeze-and-Excitation Networks)[17]。 如图2所示。

图2 通道注意力Fig.2 Channel attention
图2中,输入特征图X,X有C个通道,每个通道空间大小为H×W,对每个通道进行全局平均池化,则通道权重Z的计算公式如式(1)所示:
(1)
其中输出Z是长度为C的一维数组,表示压缩通道得到的权重;(i,j)表示在大小为H×W的特征图上横纵坐标分别为i和j的点。
然后使用激活函数对各通道权重进行相关程度建模。公式如下:
SC=Fex(Z,W)=Sigmoid(W2×ReLU(W1,Z)),
(2)
其中:SC的维度是1×1×C,SC对应生成的通道注意力权重。通道注意力权值是需要经过前面这些全连阶层和非线性学习得到的;W1的维度是C/r×C,W2的维度是C×C/r,r为放缩系数,这是由两个全连接层组成。
最后对输入通道进行加权调整,通道注意力加权公式为:
(3)
SENet可以嵌入任意卷积层中,假若每个卷积层都嵌入SENet会带来巨大的参数量,SENet的参数数目公式如下:
(4)
其中:N为参数数目,n为嵌入SENet的次数,参数数目主要来自于放置的两个全连接层,所以C和r以及n决定了给网络带来的参数大小。
SENet带来的参数量决定了SENet只能在某些卷积层使用。在特征提取主干网络上加入SENet,可以提升特征提取主干网络对图像特征的提取,如文献[18-19]取得了不错的结果。本文算法的特征提取主干网络为CSPDarkNet53,CSPDarkNet53结构比较庞大,特征提取能力就火灾烟雾图像而言已经足够,不适宜嵌入SENet。
2.3.2 嵌入通道注意力
本文在网络预测头嵌入SENet,这样做主要有两个优点:第一,减轻干扰信息的干扰,提升了网络预测头对特征信息的提取能力,从而提升了整个网络的性能;第二,带来了极小的参数量,仅为网络增加了3MB的参数量。
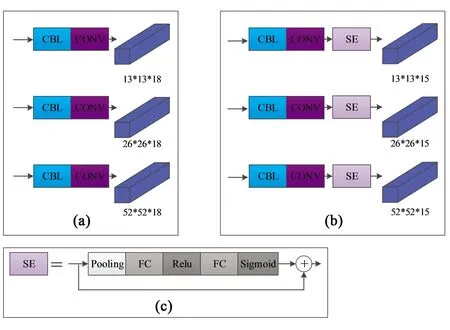
图3 算法改进前后对比。(a)改进前;(b)改进后;(c)SENet。Fig.3 Comparison of algorithm before and after improvement. (a) Before improvement; (b)After improvement; (c) SEnet.
本文在网络预测头嵌入SENet,如图3所示。在3个CONV卷积操作后面加入SENet,图3(c)为SENet的结构。由上文知,第一个FC层的神经元个数为C/r,第二个FC层神经元个数为C,缩放系数r一般取2,4,8,16,SENet的效果会随着缩放系数r的增大而变弱,但缩放系数r的增大会降低参数量,由于本文在网络预测头嵌入SENet,参数量是非常小的,所以缩放系数r取2是比较合理的。
2.4 损失函数改进
YOLOv4的损失函数如下:
L=Lcoord+Liou+Lclass,
(5)
其中:L为总损失函数;Lcoord为置信度损失函数,回归是否存在物体信息;Liou为框损失函数,回归位置信息;Lclass为分类损失函数,回归类别信息。
火灾烟雾数据集,仅存在火灾烟雾一类,是二分类问题,所以Lcoord和Lclass是存在计算冗余的,本文采用式(6)作为损失函数。
L=Lcoord+Liou,
(6)
改进后的损失函数去掉了分类损失函数,精简了损失函数的构成以提升网络的收敛速度和抗干扰性。
故3个网络预测头输出的形状分别从(13,13,18),(26,26,18),(26,26,18)变为(13,13,15),(26,26,15),(26,26,15),如图3所示。
3 实验设计
3.1 火灾烟雾数据集
本文除了主动在网上爬取火灾烟雾图像,还采用了目前烟雾检测方向较为认可的中国科学院大学火灾重点实验室、韩国启明大学和土耳其比尔肯大学的烟雾视频数据,这些数据大多为avi格式的视频数据,本文将视频数据一帧一帧地制作成图片数据加以使用。这些火灾烟雾图像包含远景、近景、夜晚以及背景干扰因素较多的烟雾图像,以此火灾烟雾数据集作为证明本文算法有效性的证据。部分火灾烟雾如图4所示。

图4 部分真实火灾烟雾图像Fig.4 Part of the real fire smoke images
3.2 实验环境
本文实验环境为:NVIDIA GeForce RTX 1660,64 位Win10操作系统。编程语言为Python,深度学习框架为Keras。
本文对于主干网络CSPDarkNet53使用ImageNet大型数据集下分类任务的预训模型,可以加快网络收敛速度。根据文献[13]实验结论指出训练阶段分两阶段进行会有更好效果,第一阶段冻结主干网络CSPDarkNet53网络参数,调整非主干网络参数,优化器使用Adam,此阶段是粗调阶段,最大学习率应设置得比第二阶段要大,设置为0.001,Batch size根据显卡的性能,由于只调整非主干网络参数,故可以设置为8,训练20个epoch;第二阶段释放主干网络CSPDarkNet53网络参数,优化器使用Adam,此阶段是微调阶段,最大学习率设置得比第一阶段要小,设置为0.000 1,Batch size根据显卡的性能,由于调整整个网络参数,故设置为2。
3.3 数据增强
在目标检测中,为了防止检测模型过拟合现象的出现,提升算法性能,需要输入足够的训练数据。现实中无法满足足够的训练数据,此时就要对数据集进行数据增强操作,以弥补数据量小带来的缺点。
本文采用了图像翻转、放缩、随机擦除等数据增强方法以弥补数据量小带来的缺点,从而降低过拟合风险。
放缩:图像有75%的概率进行随机比例的宽高放缩。
翻转:图像有75%的概率进行左右、上下翻转。
随机擦除:随机擦除在目标检测中得到大量应用,均取得不错的效果[20-21]。训练时,随机擦除方法会在原图随机选择一个矩形区域,将该区域的像素替换为随机值。这个过程中,参与训练的图片会做不同程度的遮挡,这样可以降低过拟合的风险并提高模型的鲁棒性。

图5 实验检测效果。(a)大区域烟雾;(b)中区域烟雾;(c)白天烟雾;(d)小区域烟雾且与背景相似;(e)小区域烟雾且烟雾不明显;(f)夜晚烟雾。Fig.5 Experimental detection effect. (a) Smoke in a large area; (b) Smoke in a medium area; (c) Daytime smoke; (d) Smoke in a small area and similar to the background; (e) Smoke in a small area and smoke is not obvious;(f) Night smoke.
4 实验结果及分析
4.1 评价指标
本 文 通 过 训 练 后 模 型 检 测 的 准 确 率(Precision)、召回率 (Recall)、调和平均值(Harmonic mean)、每秒检测帧数FPS(Frames Per Second)以及模型大小(Size)作为参考进行对比,准 确 率、召回率和调和平均值由式(7)~(9)计算所得。
(7)
(8)
(9)
式(7)~式(9)中:P为准确率;R为召回率;H为调和平均值,调和平均值综合了准确率和召回率,调和平均值越大,算法性能越好;TP为真正例;FP为假正例;FN为假负例。
4.2 实验结果
YOLOv4与SE-YOLOv4的检测结果对比如表1所示,实验结果表明,SE-YOLOv4网络模型仅牺牲了0.1帧/s的代价,准确率和召回率分别提高了0.9%,1.5%。
为了进一步验证本文模型在火灾烟雾检测上的有效性,本文对比了文献[6-7]提出的Faster R-CNN的烟雾检测模型以及文献[12]提出的SSD烟雾检测模型,检测结果对比见表1。
由表1可以看出,本文的火灾检测模型在准确率和召回率中有大幅度的提高,较文献[6-7]无论从精度和速度都有较大提升;较于文献[12]在准确率和召回率领先了1.9%,2.1%,在FPS落后了8.4帧/s的速度。
FPS的高低往往由模型的参数量所决定,一般情况下参数量越小,计算量则越小,检测速度就越快。文献[12]的FPS如此之高,是因为文献[12]是基于SSD烟雾检测模型,SSD网络结构精简、参数量少,其网络结构拥有多尺度分类器,能较好地兼顾提取大、小目标。文献[12]又将SSD的主干特征提取网络VGG16改进为MobileNetV2,整个模型的计算量和参数量有明显的下降,并且MobileNetV2作为主干特征提取网络优于VGG16。本文烟雾检测模型的参数量是文献[12]烟雾检测模型参数量的近4倍,但是文献[12]烟雾检测模型结构精简、参数量少,不可避免地性能达不到最优。
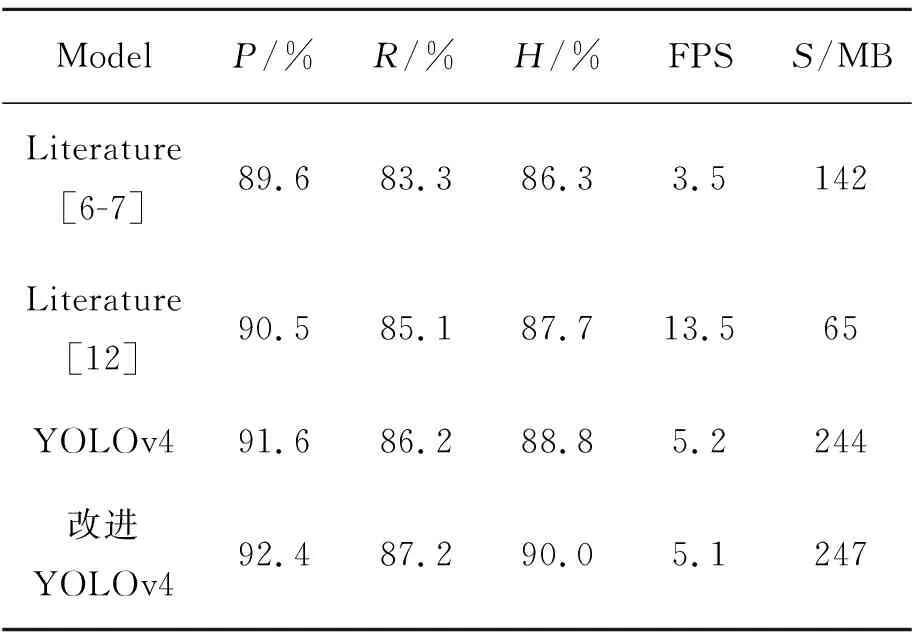
表1 其他烟雾检测模型与本文模型对比Tab.1 Comparison of results between other fire smoke detection models and this model
实验结果表明,本文模型具有一定的优越性。本文基于YOLOv4的烟雾检测具备良好的泛化能力,拥有高的准确率和召回率,适于多场景火灾烟雾检测,特别是在小区域火灾烟雾图像上也有良好表现。
4.3 YOLOv4-tiny
YOLOv4-tiny是YOLOv4轻量化的网络架构,本文对YOLOv4-tiny进行了实验对比,如表2所示。
YOLOv4-tiny是在YOLOv4的基础上所轻量化的算法,主干特征提取网络进行了精简;多尺度预测由3个降为2个,候选框则从9个降为4个;不使用PANet作为特征融合,改为使用传统的FPN进行特征融合等。极大地精简了网络结构和减少了参数量以及计算量。在精度上虽然有所降低,但在速度上远超本文算法以及文献[12]中的检测算法,这给优化本文模型带来了思路,为之后如何平衡检测精度和检测速度带来方向。
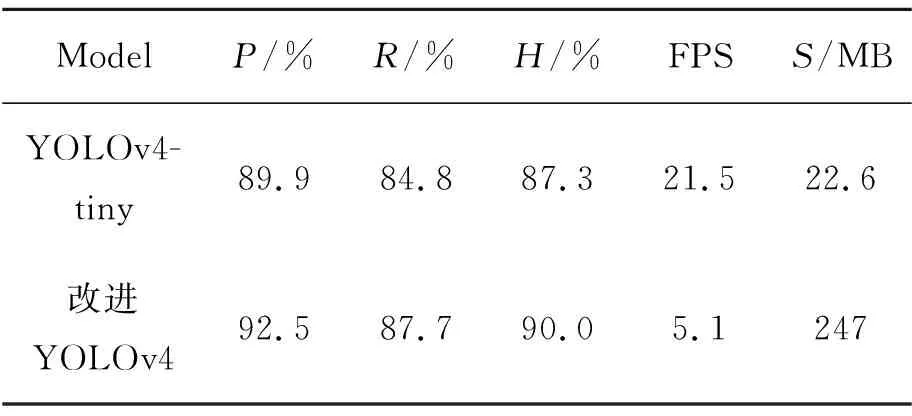
表2 YOLOv4-tiny与本文模型对比Tab.2 Comparison of detection results between YOLOv4-tiny and this model
5 结 论
本文在 YOLOv4的基础上嵌入SENet,明显提高了算法在多场景火灾烟雾检测上的性能;使用K-means聚类算法得到更加贴近火灾烟雾数据集的候选框尺寸;引入翻转和随机擦除等数据增强手段降低过拟合风险;在二分类的基础上,精简了损失函数,提高了网络的抗干扰能力。
实验结果表明,本文改进后的方法与同类火灾检测算法相比,在准确度和速度上都具有良好的表现,在数据集上达到了 92.5%的准确率,87.7%的召回率,平均检测速度达 5.1帧/s;但在平均检测速度上还有很大的进步空间,在之后的工作中可以在不牺牲性能的情况下,减小模型大小,以提高平均检测速度。火灾烟雾数据可以继续得到扩展,增加更多的火灾烟雾场景,提高火灾烟雾数据质量。
