基于RefineNet的胸环靶图分割方法
2021-10-15黄应清陈晓明谢志宏田钦文
黄应清,陈晓明,谢志宏,田钦文
(陆军装甲兵学院, 北京 100072)
1 引言
在基于计算机视觉的自动报靶系统中,胸环靶图分割是后续进行弹孔识别与环数判定等步骤的重要基础。如何在复杂环境下对胸环靶纸图像进行快速、精准的分割一直是一个技术难点。现有的自动报靶系统基本都不是建立在以复杂环境为前提的基础上的,少部分考虑了这一问题,但也都有所欠缺。
文献[1]提出了一种基于灰度特征的胸环靶图分割方法,该方法只能对胸环靶靶面占据像素最多的图像进行有效分割,且对靶场环境要求较高,无法适应下雾等对采集到的图像灰度特征影响较大的天气。文献[2]根据靶面图像纹理特征获取胸环靶心位置,从而完成胸环靶图的分割。该方法只能实现胸环靶的粗分割,且极易受到背景干扰影响,实用性较差。文献[3]提出了一种基于颜色特征的胸环靶图分割方法,这种方法在背景无绿色干扰的情况下能够较好的完成胸环靶分割任务,但真实靶场往往存在大量的草木、涂装等绿色干扰物,因此,该方法同样具有较强的局限性。
近年来,随着深度学习技术的兴起,也出现了基于深度神经网络的分割方法。文献[4]提出了一种基于PSPNet的胸环靶图分割方法,较好的完成了复杂环境下胸环靶的像素级分割任务。该方法的不足之处在于仅提取了包含有效靶面和浅色靶纸背景的图像,并没有对靶面有效区域进行分割,导致后续的报靶环节还要根据弹着点位置判断是否脱靶。为解决上述问题,提高自动报靶系统的环境适应性以及分割精度,本文采用深度学习的方法,提出了一种基于RefineNet的胸环靶图有效区域分割方法。实验结果表明:该方法可以适应复杂的靶场环境,对胸环靶有效区域进行精准的分割,有效解决了现有靶面分割方法存在的缺陷。
2 数据集
2.1 数据集采集
数据集的建立是训练深度学习模型的第一步,也是至关重要的一步。由于目前还没有用于胸环靶分割实验的公共数据集,本文所用数据均为自行搜集并标定。由于特殊原因,基层部队实弹射击训练项目的视频图像资源极少外传,想要搜集大量数据是非常困难的,本文研究遵循宁缺毋滥的原则,通过以下几个途径获取数据:
1) 利用图像采集设备实地采集靶场图像,包括不同时刻、不同环境下的真实靶场,以室外靶场为主。
2) 利用Photoshop软件对上述采集到的真实靶场图像进行背景替换。
3) 通过互联网搜集各类靶场图像。对获得的数据进行筛选、整理后,建立了包含5 200张靶场图像的数据集,部分样本如图1所示。

图1 数据集展示图形Fig.1 Display of datasets
2.2 数据集处理
本文研究的是在复杂环境下针对胸环靶有效区域的二元分割问题,因此要将图像像素标注为两类,即胸环靶面有效区域和有效区域外的背景。本文使用图像标注软件Labelme对目标进行标注,标注后的部分样本如图2所示。

图2 标注结果图形Fig.2 Labeling results
3 实验
3.1 RefineNet网络
随着计算机硬件性能的提升,研究者们纷纷将深度学习技术用于图像分割领域,并提出了FCN[5]、DeepLab[6-9]、U-Net[10]、SegNet[11]、PSPNet[12]等一系列算法。在深度卷积神经网络中,大量的卷积和池化层会导致初始输入图像的分辨率显著下降,造成了数据信息的损失。为解决此问题,Guosheng Lin等[13]于2017年提出了RefineNet网络架构。该模型可以被看作是U-Net的升级版,主要用于实现高精度的语义分割任务,在PASCAL VOC、NYUDv2、Person-Parts等数据集上进行测试,均取得了优秀的结果。RefineNet网络结构如图3所示。
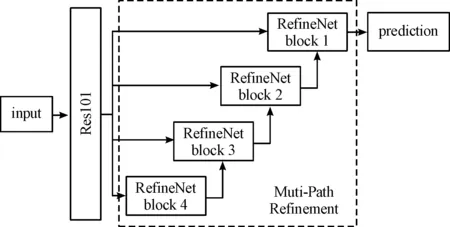
图3 RefineNet网络结构框图Fig.3 Architecture of RefineNet
图3左侧向下传播的通路以ResNet网络为基础,通过下采样提取图像语义特征,并将输出的4组特征传入相应的RefineNet模块。图3右侧向上传播的通路以多路径优化(Multi-Path Refinement)结构为基础,利用RefineNet模块对各层级的特征进行融合,从而最大限度地利用下采样过程中的可用信息,RefineNet模块结构如图4所示。
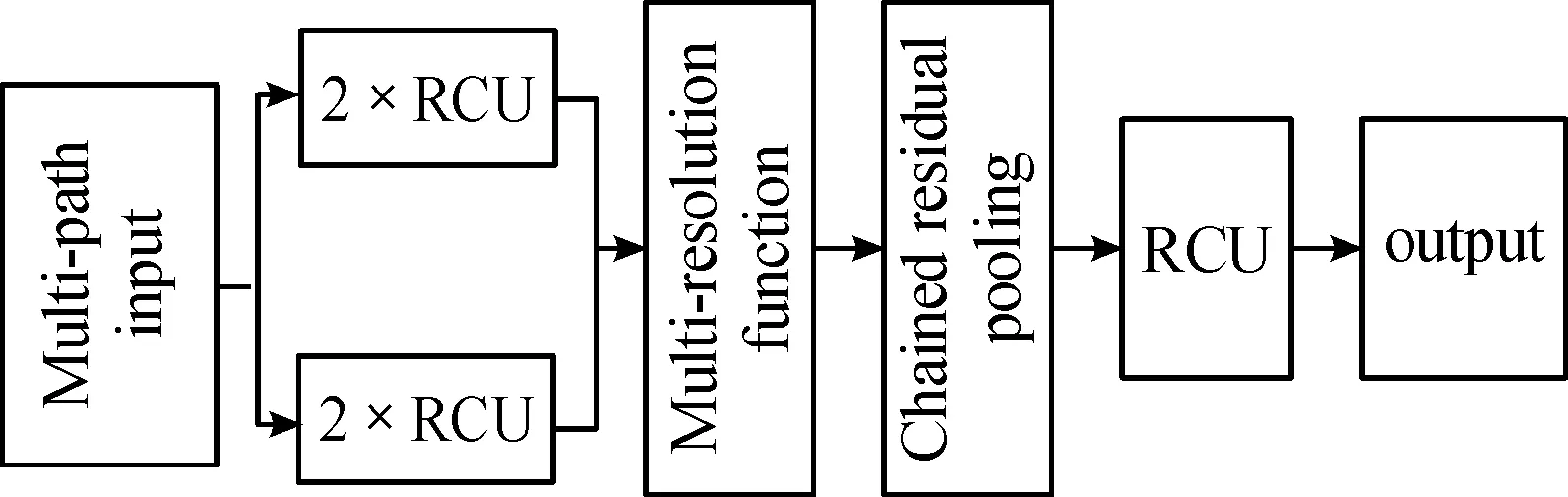
图4 RefineNet模块结构框图Fig.4 Architecture of RefineNet block
RefineNet模块由残差卷积(Residual convolution unit,RCU)、多分辨率融合(Multi-resolution fusion)和链式残差池化(Chained residual pooling)3种模块构成。残差卷积模块是从ResNet[14]中提取出来的模型,每个输入通过2个残差卷积模块,对预训练ResNet的权重进行微调。多分辨率融合模块用于将多个输入融合到高分辨率特征图上。链式残差池化模块则用于获取较大图像区域的上下文背景信息,并对得到的分割结果进行优化。本文对RefineNet网络进行一定改进,使用2种不同尺度的输入,并将五个RefineNet模块进行级联,改进后的网络结构如图5所示。

图5 本文使用的RefineNet网络结构框图Fig.5 Architecture of proposed model
3.2 实验环境
本文实验基于Windows 10系统,处理器为3.60 GHz Intel Core i7-9700K,16 GB内存,使用Nvidia GeForce RTX 2080显卡加速模型训练。通过PyTorch深度学习框架搭建RefineNet网络进行训练和测试。
3.3 模型训练
本文模型训练过程中的部分参数如表1所示。
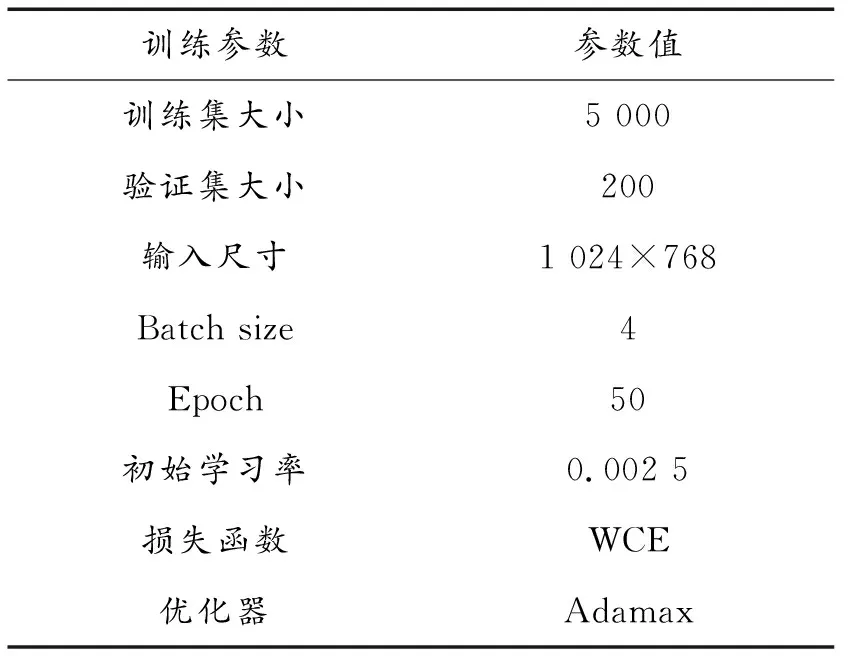
表1 模型参数
受条件所限,本文实验所采集的数据集样本量偏少,这可能会导致过拟合问题,因此,进行数据增强处理是十分必要的。本文对采集的原始图和掩码图按适当概率进行旋转、水平翻转以及添加高斯模糊处理,以提高训练后模型的泛化性。在模型中,图像数据是以每个批次为单位进行训练的,为了防止神经网络学习错误的数据分布特征,将数据集打乱顺序,按比例随机划分训练集和验证集,其中训练集包含5 000个样本,验证集包含200个样本,验证集不参与模型训练。另外,由于靶面有效区域分割完成后输出的图像还需进行弹孔识别等后续处理,所以应尽量防止图像信息缺失。考虑实验使用的数据大部分为现场采集到的靶场图像,这部分样本的分辨率为2 048×1 536,因此将输入的图像尺寸全部按比例调整为1 024×768。Batch size表示一次训练所选取的样本数,引入它虽然会降低深度神经网络参数的学习速度,但能令梯度下降的方向更准确。结合以往的经验,综合考虑实验硬件环境与网络模型结构影响,设置batch size为4。Epoch表示深度神经网络进行训练的轮次,模型每经过一代训练,训练集中的所有样本都会被训练一次。这项参数的设置比较依赖个人经验,为保证模型能够收敛,将epoch的值设为50。学习率是机器学习中重要的超参数,它决定了模型在训练过程中参数更新的幅度。学习率设置过大可能会导致梯度下降过程中在最小值附近产生震荡,模型无法有效收敛,而设置过小则会造成收敛过程缓慢。本文设置的初始学习率为0.002 5,并引入学习率控制器,使其随训练轮次呈指数衰减。二类的图像分割问题往往采用二元交叉熵损失函数(binary cross entropy loss)作为代价函数。本文实验的目标是对胸环靶有效区域进行识别,从实际应用的角度来考虑,为保证图像分割的误差对后续弹孔识别工作造成的影响最低,应尽量避免靶面有效区域的弹孔像素被误判为背景类的情况。故对假阳性的容忍度更高,而应尽量降低假阴性。因此,引入加权交叉熵损失函数(Weighted cross entropy loss)为正样本加权,其表达式如下:

(1)
(2)
其中,ω为权重,设置ω>1即可减少假阴性。
3.4 评估指标
为了对胸环靶有效区域的分割效果进行评估,本文从主观和客观2个方面对实验结果进行分析与比较。主观评价主要是通过人眼进行观察,从视觉效果上评估图像的整体分割情况以及边缘细节分割情况。在客观评价中,选取平均像素精度(Mean Pixel Accuracy)和平均交并比(Mean Intersection over Union)2种常用评估标准,将训练后模型的分割结果与人工标注结果进行对比,其公式如下:
(3)
(4)
其中,k表示图像分割任务中类(不包含背景)的数量,pii表示被正确分类的i类像素数量,pij表示本应属于i类但被错误分为j类的像素数量。平均像素精度指计算分割任务的每个类别中正确分类的像素数比例,并求出所有类别比值的平均值。平均交并比即为在图像语义分割任务中,计算每个类别的交并比(对预测结果及其真实值的交集与并集的比值),之后再求和并取平均值,其值为1时,表示各类别的真实值和预测值的交集与并集完全相同。
4 结果与分析
经过50轮的训练,模型的输出结果如图6所示。将Sobel边缘检测算法、Otsu自动阈值分割算法[15]、区域生长算法这3种传统的图像处理算法以及原始的RefineNet网络模型[13]、文献[4]算法与本文算法进行对比,整体对比结果如图7、图8、图9所示。图7(a)为光照强度较低、靶面部分清晰而背景虚化模糊的样本,图8(a)为靶面区域面积小且弹孔多、背景以绿色植被为主的样本,图9(a)为靶纸表面光照不均,且靶面上端有部分形变以及阴影遮盖的样本。为方便对比,将传统算法分割结果以及根据深度神经网络输出的标签图生成的分割图进行二值化处理。

图6 模型输出结果展示图形Fig.6 Results of proposed model
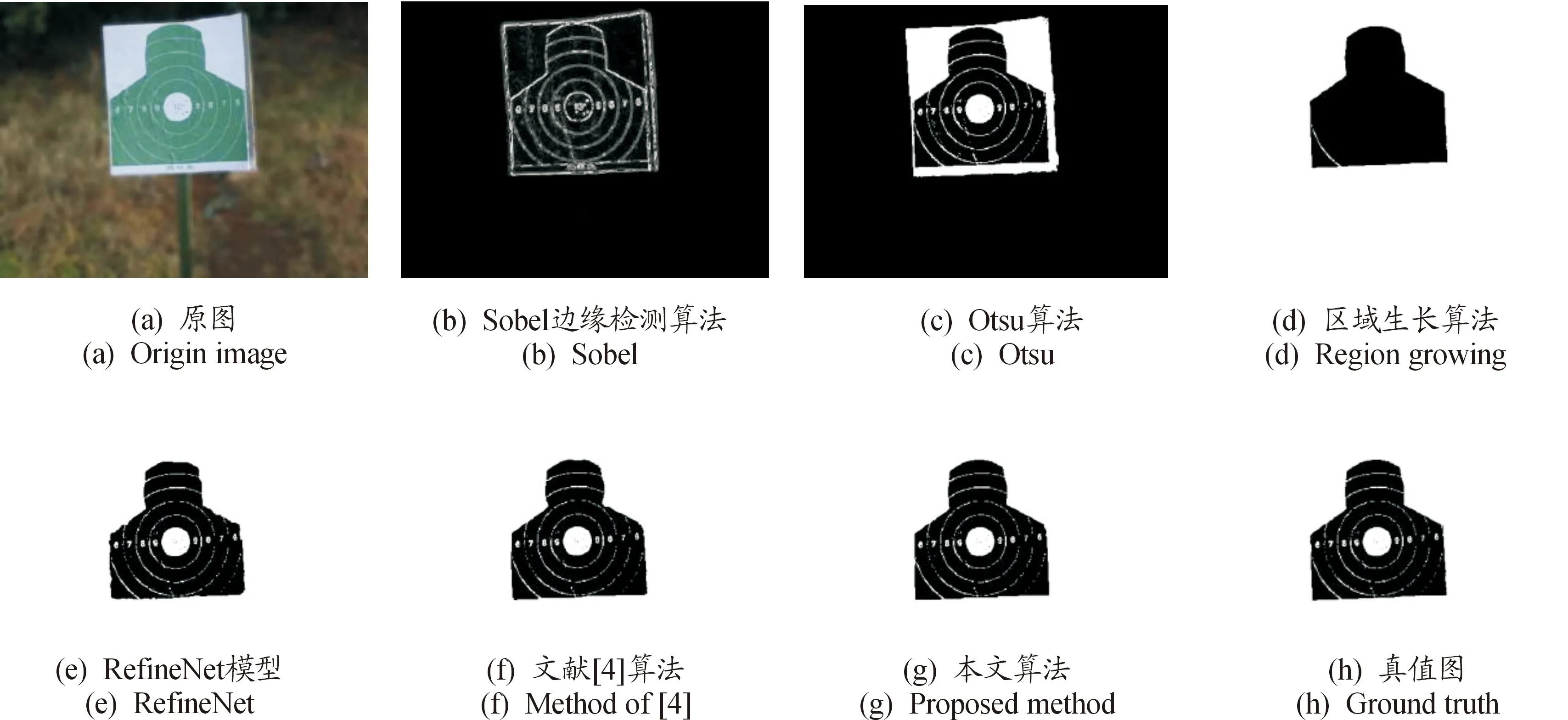
图7 不同算法分割结果图形Fig.7 Segmentation results using different algorithms

图8 不同算法分割结果图形Fig.8 Segmentation results using different algorithms

图9 不同算法分割结果图形Fig.9 Segmentation results using different algorithms
由图7、图8、图9可以看出:3种传统的图像分割方法在特定情形下可以得到较好的结果,但具有较强的局限性,难以适应复杂多变的靶场环境。Sobel边缘检测算子可以很好的克服光照强度变化带来的影响,但是当背景没有进行虚化处理时,无法区分靶面区域与背景环境,仅能用于靶场背景的边缘特征较弱的样本。Otsu阈值分割算法在处理背景灰度值较高的图像时的表现较差,会将背景的一部分也分割出来,且当靶面受到的光照不均时,会造成胸环靶有效区域的灰度值相差较大,使得在分割时部分靶面区域信息丢失。区域生长算法在种子点选取合理、背景灰度值较高的情况下可以很好的分割胸环靶有效区域,但是当背景灰度较高时,便无法准确分割,且在分割过程中会出现弹孔信息丢失的现象。由图7、图8、图9不难看出:相比于传统的图像分割方法,基于深度学习的分割方法明显更加优秀。原始的RefineNet模型在分割过程中会丢失部分边界细节信息,导致部分边界较为粗糙。文献[4]使用的PSPNet分割精度在此基础上有所提升,但也低于本文所用的网络模型的分割结果。
通过视觉观察来评价算法的优劣虽然比较直接,但容易受到人主观因素的影响,因此,基于本文验证集对3种神经网络模型进行定量评价,结果如表2所示。训练的模型在胸环靶有效区域分割任务中的平均像素精度达到了96.31%,平均交并比达到了91.55%,两项参数均为最高。
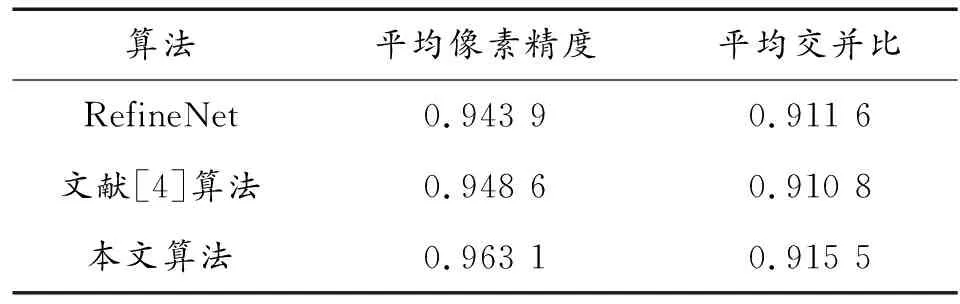
表2 不同分割算法的定量分析结果
5 结论
本文主要对RefineNet模型的结构进行了改进,建立数据集,调节参数,完成了模型的训练,最终实现了对胸环靶有效区域的像素级语义分割。实验结果表明,本文算法在复杂靶场环境下对于胸环靶有效区域具有较高的分割精度,有效推动了基于计算机视觉的自动报靶系统在复杂环境下的应用进程。
