基于卷积神经网络的图像特征描述方法
2021-10-15马金盾郭理彬王江峰
马金盾,张 雷,郭理彬,王江峰,韩 斌
(1.陆军装甲兵学院 兵器与控制系, 北京 100072; 2.中国人民解放军63966部队, 北京 100072)
1 引言
目前图像局部特征描述方法在目标检测与识别[1]、目标跟踪[2]、三维重建[3]以及位姿估计[4]等领域都被广泛运用。它是使得计算机理解图像信息的基础,一个提取速度快、区分度好、受环境影响小的局部特征描述子能够大大提高计算机视觉任务的完成效果。特征点法视觉SLAM位姿估计算法就是通过提取局部特征进行匹配来完成前端数据关联的,具有良好不变性、可区分性和鲁棒性的特征描述子能够极大地提高特征匹配的正确率,进而提高前端数据关联的准确性、降低后端计算的错误率,从而提高位姿估计的精度。由于实际过程中图像视频流的输入包含大量的图像帧序列,因此视觉SLAM算法对特征描述子的实时性也有很高的要求。目前被广泛使用在视觉SLAM算法中的特征描述方法是ORB[5](Oriented FAST and Rotated BRIEF)描述子,它的求解速度快,并且其采用灰度质心法求解关键点方向进而获取旋转不变性的方法也使其具有一定的不变性和鲁棒性。而在目前的局部特征描述方法中,诸如SIFT[6](scale invariant feature transform)、SURF[7](Speeded Up Robust Features)等描述子虽然不变性要远优于ORB,但其巨大的耗时是其无法应用在视觉SLAM算法中的关键原因[8]。
近年来,随着深度卷积神经网络在图像分类、目标检测等方面发挥的巨大作用[9-10],大量的实验证明基于大数据训练卷积神经网络提取图像特征的方法表现出了远优于传统手工特征的表征能力。同时研究人员对基于深度学习的图像局部特征描述算法也进行了较多的研究[11-12],涌现出了诸如DeepDesc (Deep Convolutional Feature Point Descriptors)、TFeat (triplets in learning local feature descriptors)、SuperPoint (Self-supervised interest point detection and description)等相关算法。这些算法在应对在光照、尺度以及旋转变化等方面都表现出了优于传统手工描述子的鲁棒性,而且浅层网络算法TFeat在GPU下的提取耗时达到了和ORB一样的水平。此算法的提出充分表明了深度特征描述子能够较好地解决视觉SLAM算法中特征描述子性能和耗时不能兼顾的问题。虽然TFeat算法的精度性能优于传统描述方法,但仍然低于HardNet等描述子提取方法,不能达到最高水平,而HardNet方法却由于网络结构较深提取耗时长而不能运用到特征点法视觉SLAM算法中[13]。
针对上述问题,本文中提出了一种基于深度可分离卷积和反向残差网络改进的特征描述方法。在HardNet深层网络的基础上,通过合理利用深度可分离卷积和反向残差网络构建改进型提取网络模型,以保证网络深度、降低计算复杂度,再结合三分支网络训练方法,使用基于指数函数的三元组损失函数和基于余弦距离矩阵的负样本挖掘策略训练网络,从而得到兼顾精度和耗时的深度描述子提取方法,对提高视觉SLAM算法的位姿估计精度具有积极作用。
2 相关工作
目前的深度图像描述方法主要有DeepDesc[14](2015)、TFeat[15](2016)、L2-Net[16](2017)、HardNet[17](2017)等单纯特征描述子提取网络算法和SuperPoint[18](2018)、D2-Net[19](2019)等融合关键点检测和描述子描述网络为一体进行优化的相关算法。
DeepDesc是在2015年由Edgar Simo-Serra等人提出的,其单分支网络共3层,属浅层网络,每层包含滤波层、非线性层、池化层和归一化层4个子层,64*64的图像块输入在第3层产生128维浮点型输出。它是早期使用双分支结构来进行图像块的描述子向量提取网络训练的代表性工作,其损失函数如下:

(1)
其中‖D(x1)-D(x2)‖2为2个描述子之间的欧式距离,C为边界阈值。
此损失函数就是在训练时最小化正样本间的距离,最大化负样本间的距离,来获得具有较好表征能力的网络参数。同时DeepDesc在训练时还采用积极挖掘的策略扩大了参与到训练中的样本数量,提高网络的表征能力,通过训练得到的网络可以作为传统 SIFT描述子的替代。
TFeat是在2016年由Vassileios等人提出的,此网络仍然采用浅层网络的方式来提取特征,网络共包含4层结构,输入32*32图像块输出128维浮点型描述子。不同的是此网络是首次采用三分支网络结构来进行训练,并采用基于锚点交换的负样本挖掘策略来提取最难区分负样本,提高了网络的训练效果,原文实验表明此描述子的鲁棒性和耗时都优于DeepDesc描述子、SIFT描述子,而且其提取耗时在GPU下达到了与二进制描述子相同的水平。这也是此描述子的一个显著优势。
L2-Net和HardNet是在2017年分别由尹润田和Anastasiya等人提出的,2种算法的单分支网络结构相同,共包含7层结构,是较为深层的网络结构,输入32*32的图像块得到128维的描述子向量,这两种算法都取得了优于基于数据驱动的浅层描述子的性能。其中L2-Net采用双塔结构并结合渐进采样策略和包含三项的专用损失函数进行深度监督训练,而在其之后的HardNet算法在使用L2-Net网络结构的基础上,采用三分支网络结构结合基于距离矩阵的高效负样本挖掘策略进行训练。输入一个三元组图像块,其中a和b是一对正样本,c是通过挖掘得到的与a最相似的负样本,其三元组损失函数表示为
其中:n为边界阈值,m为一个批次中三元组的组数,‖·‖2为描述子之间的欧式距离。
SuperPoint是在2018年由Magic Leap公司的Daniel等提出的结合关键点检测和描述子提取为一体的网络结构,此结构能够达到实时效果。其描述子提取网络是基于UCN算法和DeepDesc算法提出的。通过对整幅图像进行全卷积编码,输出半稠密的描述子而后再进行双三次多项式差值、L2归一化得到整体描述子向量。此方法和双分支网路训练得到描述子的思路基本一致。
D2-Net是2019年由Mihai Dusmanu等人提出的,它打破了传统的先检测关键点再进行特征向量描述的特征提取方法,而是采用卷积神经网络同时进行检测和描述,在应对光照变化有很好的鲁棒性,但特征局部性不足,检测精度较低。
综合分析,深层网络的精度要高于浅层网络,但耗时也随之增加。目前的深度描述子提取网络主要是基于三分支结构进行训练,其中负样本的挖掘策略对训练后网络的参数影响较大。因此基于现有的研究成果,本文中提出了下述的网络结构和训练策略。
3 网络结构及训练策略
深度可分离卷积替代标准卷积,先进行深度卷积再进行逐点卷积,能够极大地减少模型的参数和运行时间[20],将此方法应用在图像描述子提取的网络结构中能够提高深层网络的计算速度。深度可分离卷积替代标准卷积增加了网络的深度,将会导致训练过程中梯度的爆炸和消失,从而带来一定程度的精度下降。而文献[21]在深度可分离卷积的基础上提出了利用线性瓶颈结构和反向残差结构实现了在减小参数量和计算量的同时,又增加网络的表征能力,在一定程度上缓解了由于深度可分离卷积带来的精度下降问题。其在ImageNet数据集上的实验精度超过了GoogleNet(Google Inception Net),与VGG-16(Visual Geometry Group Network-16)相当,而其计算量是VGG-16的1/25,耗时比VGG-16提高了40倍。因此,本文在使用深度可分离卷积的基础上,又在描述子网络中增加了反向残差结构的使用以提高网络的表征能力。因此本文提出了一种基于深度可分离卷积和反向残差结构的改进型描述子提取网络,单分支网络结构如图1所示。单分支结构网络以HardNet网络结构为基础,主体总共包含7层网络,每层网络基础采用基于深度可分离卷积和线性瓶颈结构的反向残差结构,共进行两次逐点卷积操作和一次深度卷积操作,此外网络主体还包含一个L2归一化层。输入32*32的图像块,最后通过L2归一化输出128维的图像描述子。第2层和第4层由于初始特征通道数较少故进行两倍的扩张操作,其余5层不进行扩张操作。在第3层、第5层采用步长为二对特征图进行下采样,避免池化带来的特征丢失。第7层使用8*8的卷积核进行深度卷积操作,并且pad(padding)设置为零,不进行补零操作,其余层都采用3*3的卷积核进行深度卷积,并且pad设置为一,确保在卷积操作后不改变特征图的大小。
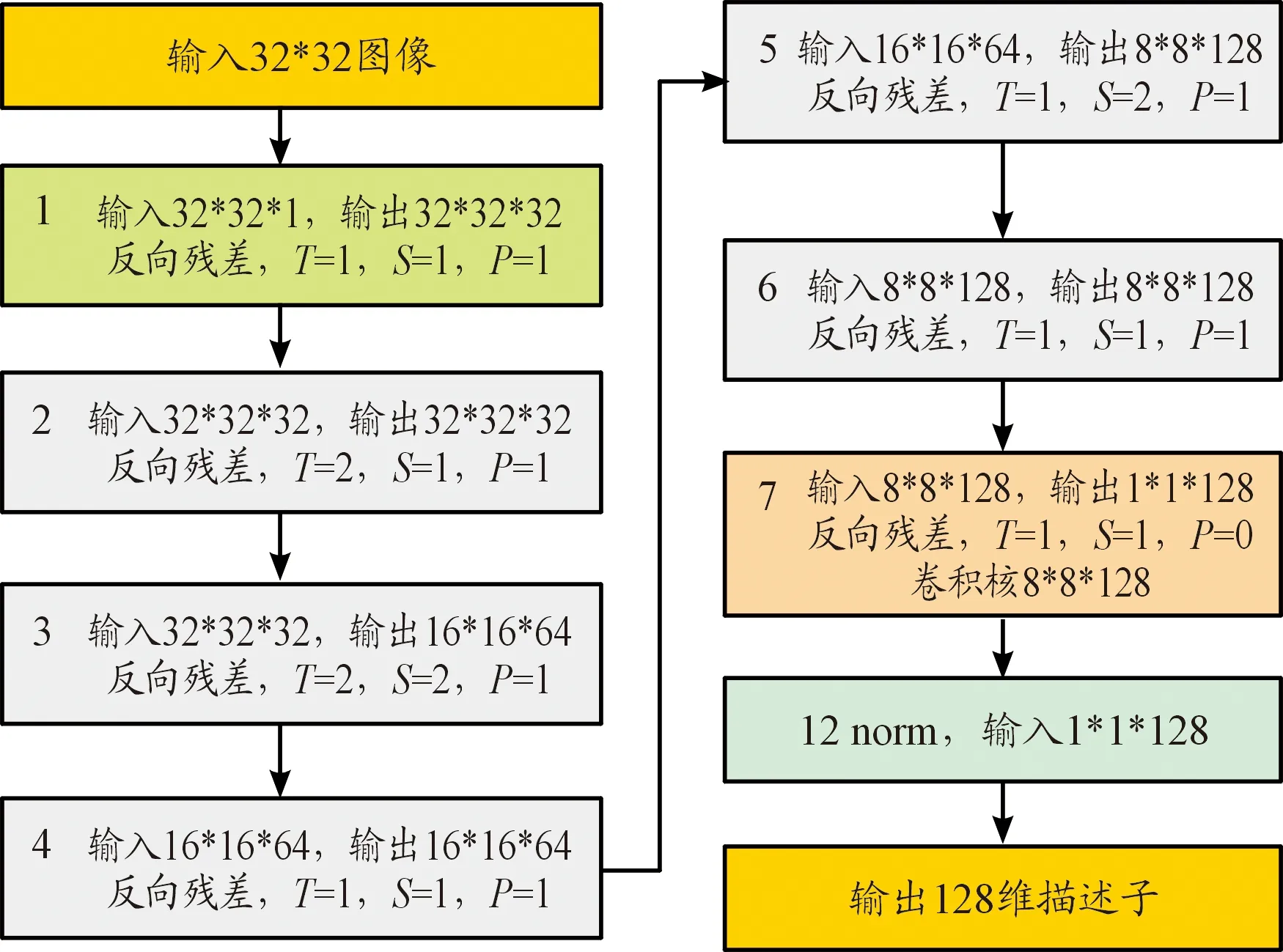
图1 网络结构框图Fig.1 Network structure framework
3.1 深度可分离卷积
深度可分离卷积和标准卷积计算过程如图2所示。输入Df*Df*M大小的特征图,输出Df*Df*N的特征图,其中M和N为通道数、Df为特征图尺寸大小。标准卷积操作是用Dk*Dk*M*N的卷积核进行操作,深度可分离卷积是先用Dk*Dk*M的卷积核进行深度卷积,然后进行批规范化(BN,Batch Normalization)和ReLU (Rectified Linear Unit) 激活,之后再利用1*1*M*N的卷积核进行逐点卷积操作将各个通道的特征图关联起来,再进行批规范化(BN)和ReLU激活。标准卷积的计算量为Df*Df*Dk*Dk*M*N,深度可分离卷积的计算量为Df*Df*Dk*Dk*M+Df*Df*M*N,对于HardNet第1层标准卷积而言,替换后可减少252 928次计算,是原来计算量的1/7,可大大提升网络的速度。

图2 深度可分离卷积和标准卷积计算过程示意图Fig.2 Deep separable convolution and standard convolution calculation procedure
3.2 反向残差
线性瓶颈结构和反向残差结构的计算过程如图3所示。它的计算是基于深度可分离卷积进行的,先对M通道的输入图像进行逐点卷积,将其扩张为M*T通道的特征图,随后进行BN和ReLU6非线性优化,再在扩张后的高维图像上进行分组深度卷积计算提取图像特征,随后再次进行BN和ReLU6,再进行逐点卷积得到 通道的输出图像,然后进行BN和Linear线性激活。当输入输出通道数目一致且深度卷积步长为1时,进行M-ADD残差计算。最后的线性激活函数替代ReLU6非线性激活能够减少从低维通道中输出信息的损失率,而反向残差结构的使用不仅能够使网络在更高的维度上进行特征提取,增加特征表达能力,而且能有效地解决训练中由于网络深度增加而导致的梯度消失问题带来的网络精度下降问题。

图3 反向残差结构的计算过程框图Fig.3 Reverse residual structure
3.3 负样本数据构建
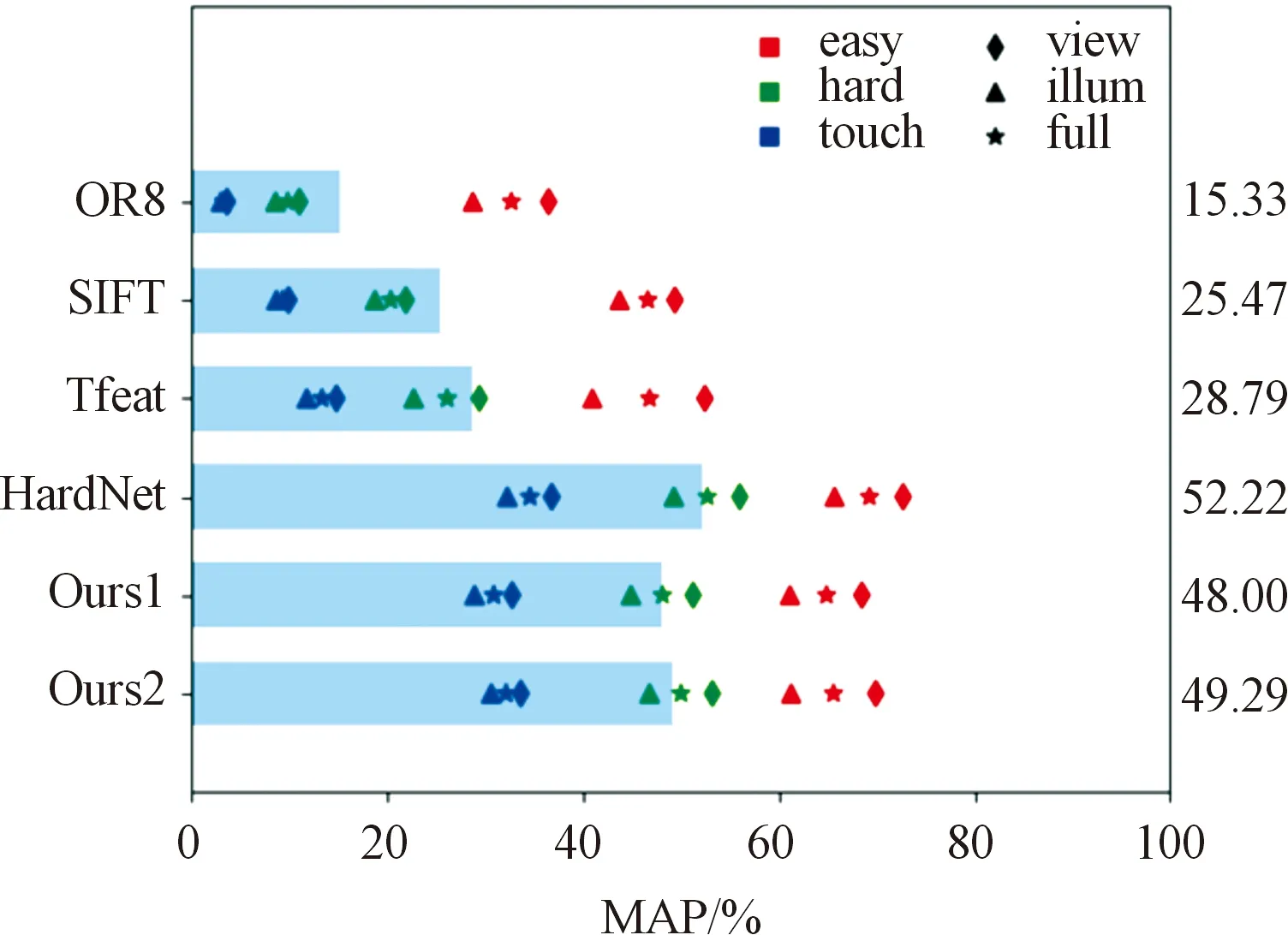
本文采用和HardNet类似的负样本采样方法,不同的是建立其余弦距离矩阵。因为文献[22]指出角距离在多维数据中对于相似度的计算效果要优于欧式距离。所以本文的负样本采样方法如图4所示,对于一个批次中的N对正样本图像块(Ai,Pi),将其通过图1的网络结构得到128维的归一化描述子向量(ai,pi),对于每一对(ai,pi)计算式3得到一个批次的余弦距离矩阵。对于每一对(ai,pi)即当i不变时,找到最小的dij和dji,若dij 图4 负样本采样方法示意图Fig.4 Negative sample sampling method dij=1-aipj (3) 其中i=1,2,…,N,i≠j。 损失函数是描述模型产生结果与真实数值偏差程度的一类函数的总称,通过不断地更改模型参数来使损失函数值越来越小,以达到优化模型的目的。传统的三元组损失函数如式(2)所示,目的是最大化负样本间的距离、最小化正样本间的距离。而当训练一段时间后,模型有了一定精度,由于阈值的存在,之后输入的训练数据得到的损失函数结果将为零,导致训练陷入局部最优,后续训练失去意义,所以本文在传统三元组损失和文献[22]中余弦距离求解相似度的基础上,将原来求最大化的损失函数改为求指数损失函数,去除边界阈值,对负样本和正样本间的距离差求指数,当距离差异较大时,仍然给出一定的损失,确保能够不断优化训练模型。本文的损失函数如式(4)所示。 (4) 其中:n为一个批次中的三元组个数,ai,pi为正样本的描述子向量,ci为负样本的描述子。 实验选用Brown数据集进行模型的训练,选用Hpatches数据集及其评测方法进行模型效果的评测。 4.1.1数据集 Brown[23]数据集是在2007年由Matt Brown等人提出的,包含liberty,notredame和yosemite 3个子图像集,每个子集包含近2 000张图片,每个图片包含16*16共256个64*64像素的特征点图像块补丁,并且还提供了图像间的变化关系矩阵。 Hpatches[24]数据集是在2017年由Vassileios Balntas等人在总结Photo Tourism、DTU、Oxford-Affine、CVDS、RomePatches等数据集及评测方法的基础上提出的。 此数据集包含116个场景,每个场景包括参考图像、光照或视点变化图像共6张图像,其中57个光照变化序列,59个视点变化序列,同时也定义了每个图像序列中图像间的变化关系矩阵。此数据集还根据DoG、Hessian-Hessian和Harris-Laplace检测上述图像序列中关键点后提取其周围65*65像素的图像补丁集,并对每个图像补丁加入了EASY、HARD和TOUGH 3种级别的旋转、平移、尺度噪声干扰,来模拟实际应用中从不同图像中检测特征点时的噪声,极大地提高了数据集的丰富性和实际性。 4.1.2评价指标 Hpatches[24]评测标准是基于传统的平均精度评价指标进行的,不同的是它结合了图像块验证、图像块匹配、图像块检索3个计算机视觉中常用的子任务进行评估,充分地证明了此评价标准的实际有效性,是近年来评测局部特征描述子的首要选择。 本文是在基于Pytorch的深度学习框架下对提出的深度网络模型进行实验的,优化器选择随机梯度下降法进行训练,网络整体采用周期学习率,频率为10,初始学习率设置为10,学习率衰减率为0.000 001,L2正则化权重衰减设置0.000 1。每个批次随机选择5 000 000组数据参与训练。本文的实验环境为Ubuntu16.04和NVIDIA GeForce RTX2080ti。 在训练批次epoch与batch-size的大小设置上本文进行了对比实验,最终确定epochs=10,batch_size=1 024。实验选用liberty作为训练集,notredame作为测试集,FRP95作为精度评价指标,FRP95值越低描述子效果越好。实验结果如图5和图6所示,其中图5是epochs和batch_size对精度(FRP95)的影响,图6是epochs对精度(FRP95)的影响。图5实验结果表明:随着batch_size值的增加,FRP95值越来越小,即网络模型的效果越来越好,当batch_size值增加到1 024后,batch_size扩大1倍,FRP95值变化极小,即batch_size对模型效果的影响越来越小,而batch_size的增加对实验的GPU要求较高,所以综合考虑,本文选择batch_size=1 024进行后续的实验。 图5 epochs和batch_size对精度(FRP95)的影响曲线Fig.5 Effect of EPOCHS and Batch size on the accuracy (FRP95) 图6 epochs对精度(FRP95)的影响曲线Fig.6 Effect of EPOCHS on accuracy (FRP95) 图6实验结果表明:当训练批次epochs在1~10之间时,FRP95值上下波动较大,表明此阶段模型还未收敛,此阶段的训练是有效的;当epochs再逐渐增加,FRP95值呈下降趋势,第50次与第10次训练模型效果相比之下降了0.9%,下降较少,表明之后批次的训练对模型效果的提升作用较小,而训练批次数目的增加会导致训练时间的加长,综合考虑,本文选择epochs=10来进行后续的实验。 本文选择ORB、SIFT、TFeat、HardNet、本文提出的描述子在传统边界损失函数和欧式距离相似度计算方法下的训练模型Ours1以及在本文选用的余弦相似度和指数损失函数下的训练模型Ours2进行了对比实验,对其时间性能以及在3个评价任务上的精度性能进行了对比分析。 4.3.1时间性能 本文的深度描述子提取实验都是在GPU下进行的,传统的描述子提取基于OpenCV 3.2进行,对一个65*65的图像块进行100次特征描述子提取,对其耗时取平均值,平均耗时如表1所示。 表1 描述子提取消耗时间 本文提出的描述子在GPU下提取时间为15 μs,比ORB描述子慢5 μs,但比HardNet快25 μs,比SIFT要快130 μs。即本文的描述子提取1 000个特征描述子需要15 ms,每秒可完成对70张左右的图像进行每张1 000个特征描述子的提取,只比ORB少30张,在GPU下可以达到实时的速度。此实验结果充分证明了本文提出的描述子具有较好的时间性能,基本可以满足视觉SLAM实时性的要求。训练后的模型大小为393.1 KB,而HardNet原结构的训练模型大小为5.3 MB,本文的模型大小是原来模型的1/14,这也从另一方面证明了本文中提出的网络参数量少,耗时要比HardNet少。 4.3.2精度性能 图像匹配任务、图像验证任务、图像检索任务的平均精度(MAP)如图7、图8、图9所示。 1) 图像匹配 图7实验结果表明:Ours1平均精度达到了48%,Ours2达到了49.29%,超过ORB 34%,超过TFeat 21%,即使在扰动最大的touch序列,描述子也超过ORB、SIFT、TFeat 10%以上,这充分地表明了本文中提出的描述子在图像匹配任务中的良好性能,能够提高视觉SLAM中数据关联的精度。但Ours1和Ours2都比HardNet低,Ours1低4%,Ours2低3%,这也表明了耗时与精度成反相关,两者的同时兼顾是极其困难的。 图7 图像匹配任务实验结果图Fig.7 Experimental results of image matching task 2) 图像验证 图8实验结果表明:不论是在平衡变体还是非平衡变体中,在同场景中选取负样本比在不同场景中选取负样本得到的精度都低,这是由于同场景中图像的可区分性较低,较难区分,这也表明无论是Ours1、Ours2还是ORB、SIFT、TFeat、HardNet在描述子的可区分度方面都有提升空间。但总的来说Ours1和Ours2在序列间平衡变体的精度达到了94%,比ORB在序列外的精度80%高出14%,在序列间非平衡变体的精度达到了85%,比ORB在序列外的精度58%高出27%,这充分地表明了本文中描述子的优越性,其具有较好的可区分性,能够有效地减少误匹配结果的产生,而且本文中提出的描述子在图像验证任务中对光照和视点变化序列的精度基本一致,表现出了较强的处理能力。 图8 图像验证任务实验结果图Fig.8 Experimental results of image verification task 3) 图像检索 图9实验结果表明:随着检索数目的增加,图像检索的精度会逐渐降低,当图像检索数目增加到5 000以上时,TFeat精度下降幅度大于传统描述子,在检索数目到达20 000时和SIFT基本相当,而Ours1、Ours2和HardNet始终保持在较高精度上,并且下降幅度较低,这充分地表明了本文中提出的描述子在对图像检索任务具有很好的性能,能够达到和HardNet相当的水平,能够较好地满足视觉SLAM中闭环检测模块的需求,也表明了浅层神经网络在此方面具有一定的局限性。 图9 图像检索任务实验结果图Fig.9 Experimental results of image retrieval task 总的来说,在精度方面,所有任务中深度描述子的精度性能都优于传统描述子,且从ORB、SIFT、TFeat、Ours1、Ours2、HardNet性能呈现递增的趋势,其中Ours1、Ours2与HardNet相比精度虽然有所降低,但幅度不超过5%,并且其比ORB高30%,比TFeat高20%。Ours2在所有任务中的精度都略高于Ours1,这表明了余弦相似度方法和指数损失函数对网络训练的有效性。所有描述子在尺度、旋转、平移等扰动增大的情况下,性能都会逐渐降低,其中传统描述子的降低幅度要大于深度描述子,Ours1、Ours2和HardNet在touch条件下的精度值与ORB在easy条件下的精度值相当,再次充分地表明了本文中提出的描述子具有较好的抗扰动性和精度。此外所有描述子在光照变化序列中的表现要低于在视点变化序列中的表现,这充分地证明了特征法在应对光照变化方面是存在局限性的。 针对目前面型视觉SLAM任务的描述子提取方法存在的问题,提出了基于反向残差和可分离卷积、线性瓶颈结构改进的深度描述子提取算法,并采用基于余弦距离矩阵的负样本挖掘策略和基于指数函数的损失函数进行训练,得到深度描述子模型。在Hpatches评级指标上进行评价,其精度平均高出ORB 30%,高出TFeat 20%,和HardNet基本相当,但其在GPU下的提取时间和浅层网络TFeat基本相当,比HardNet快25 μs,能够满足视觉SLAM的实时性需求。 虽然本算法的精度和实时性得到了一定程度的兼顾,但综合比较本算法的精度和实时性都未达到最高水平,因此在下一步研究中还需对模型进行进一步优化和改进,为提高计算机视觉任务的性能提供坚实基础。
3.4 损失函数构建
4 实验与分析
4.1 数据集及评价指标
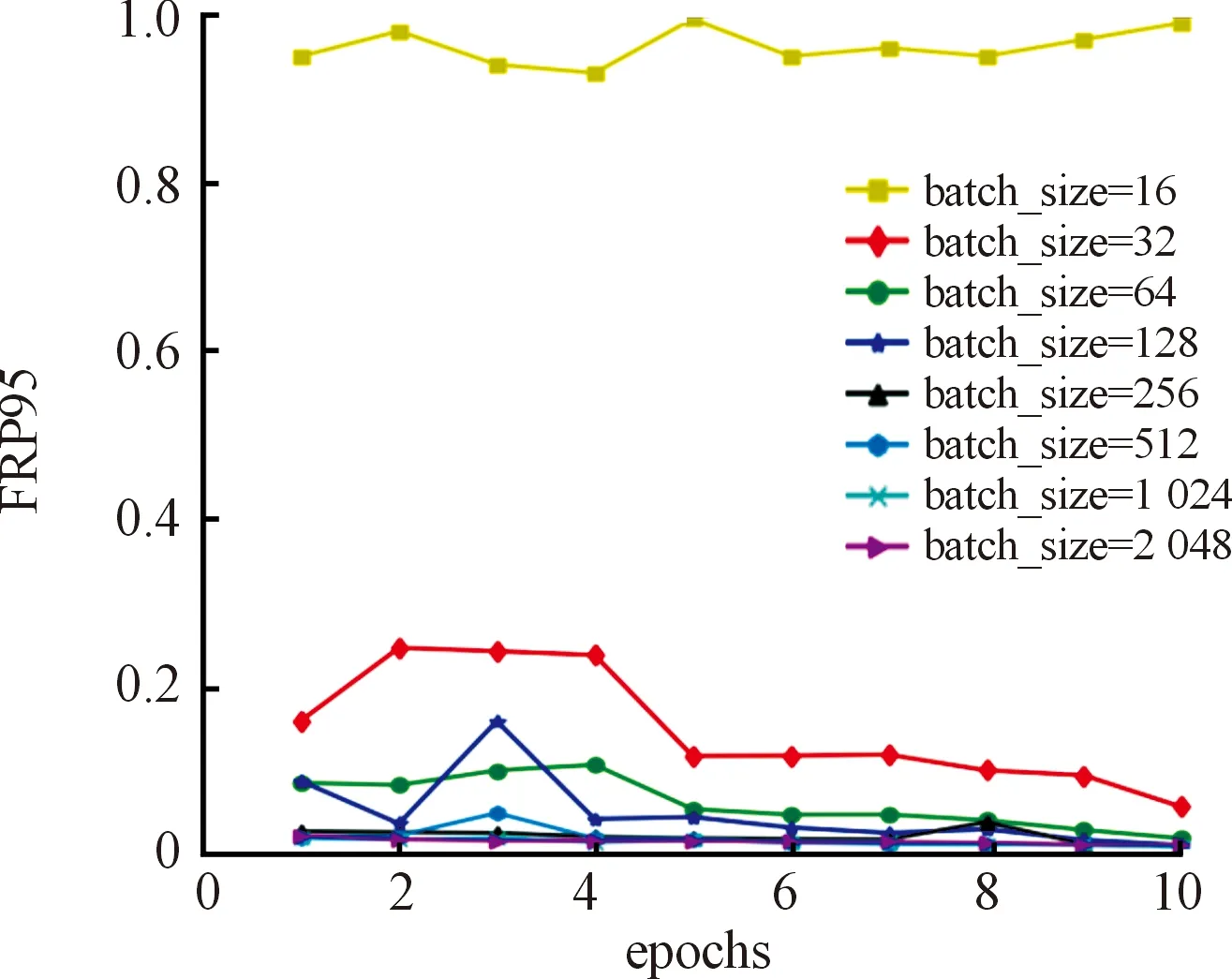
4.2 训练参数确定

4.3 实验结果及分析



5 结论
