改进U-Net的新冠肺炎图像分割方法
2021-10-14宋瑶,刘俊
宋 瑶,刘 俊
1.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065
2.武汉科技大学 计算机科学与技术学院,武汉 430065
2019年12月,新型冠状病毒肺炎(简称“新冠肺炎”)疫情出现,随后新冠肺炎在局部地区扩散并迅速蔓延至全世界,引起了全球的密切关注[1]。世卫组织将此新疾病命名为“2019年冠状病毒病”,简称:COVID-19。被病毒感染的人数正在全球急剧增加,截至2020 年10 月11日,美国约翰·霍普金斯大学实时统计数据显示,全球报告的新型冠状病毒病例已超过3 800 万例,死亡病例超过100万例。世界卫生组织(World Health Organization,WHO)宣布疫情为国际关注的突发公共卫生事件,于2020年3月11日确认为大流行病,这在国际社会引起了极大的公共卫生关注[2]。因此,快速检测和隔离感染者对于限制病毒的传播至关重要。
逆转录聚合酶链反应(RT-PCR)被确立为COVID-19筛选的金标准[3]。RT-PCR能够检测通过鼻咽拭子、口咽拭子,支气管肺泡灌洗液或气管抽吸物获得的标本中的病毒RNA。但是,最近的各种研究表明,RT-PCR 检测的灵敏度较低,约为71%,因此需要重复检测才能准确诊断。此外,由于缺少所需的材料,RT-PCR筛查非常耗时又增加了可用性限制[4]。
用于COVID-19筛查的RT-PCR的替代解决方案是医学成像,例如X 射线或计算机断层扫描(Computed Tomography,CT)。近年来,医学成像技术取得了长足的进步,现已成为诊断和多种疾病定量评估的常用方法。特别是,胸部CT 筛查已成为肺炎的常规诊断工具。此外,CT成像在COVID-19定量评估以及疾病监测中也起着重要作用。在CT图像上,感染初期COVID-19感染区域可通过肺部玻璃结节(Ground Glass Opacity,GGO)区分,感染后期可通过肺实变来区分[5]。与RT-PCR相比,多项研究表明,CT 对COVID-19 筛查更为敏感和有效,即使没有临床症状,胸部CT成像对COVID-19检测也更加敏感。一般情况下,医生通过观看患者的CT影像图,诊断患者肺部是否已感染新冠肺炎。
但感染初期的肺部玻璃结节在CT影像图中特征不明显,需要经验丰富的医生才能准确识别并标定出感染区域。如果医生经验不足或者诊断不够认真仔细都可能导致对COVID-19的误诊。因此,自动分割技术可以辅助医生诊断,降低医生的劳动强度,提高COVID-19诊断准确率,为患者治疗争取宝贵时间。
1 相关工作
近年来,随着人工智能技术的发展,图像分割越来越多地采用深度学习技术,取得了优于传统分割技术的分割效果。特别是卷积神经网络(Convolutional Neural Network,CNN)[6]的出现,为图像特征提取带来全新的解决方法。2015年,Long等[7]在CNN的基础上,创造性地提出了一种全卷积神经网络(Fully Convolutional Network,FCN)。他们将传统CNN 中的全连接层转化成一个个的卷积层,对图像进行像素级的分类,从而解决了语义级别的图像分割问题。Ronneberger 等[8]提出的U-Net网络模型采用编码器-解码器结构,编码器部分通过卷积和逐级下采样提取图像层级的特征对输入图像进行编码;解码器通过卷积和逐级上采样将编码信号映射成相应的二值分割掩模,得到较好的分割结果。与FCN相比,U-Net能够在较少样本量的情况下完成模型训练并实现图像分割。受U-Net模型启发,许多研究者对U-Net 网络进行了改进。文献[9]中提出了U-Net++模型,通过增加编码器和解码器之间的细粒度信息来重新设计跳跃连接;文献[10]中提出的3D-UNet 把U-Net中所有的2D卷积替换成3D卷积块,还用了Batch Normalization 防止梯度爆炸;文献[11]中以U-net 为基础提出Attention-Unet,在解码器部分使用了注意力机制,可以将注意力集中在感兴趣区域;文献[12]中提出R2U-Net,将循环卷积神经网络和循环残差卷积神经网络结合,使网络提取到更好的特征;文献[13]中将DAC模块和RMP模块与编码器-解码器结构相结合以捕获更高级的抽象特征和保留更多的空间信息。这些基于U-Net 模型的改进,都在一定程度上提升了对特定图像的分割性能。
最近有一些针对肺部的CT 图像分割的方法。文献[14]中提出Inf-Net 从肺部CT 图片中自动分割感染区域。利用并行部分解码器(Parallel Partial Decoder,PPD)用于聚合高级特征(结合上下文信息)并生成全局图。然后,利用隐式逆向注意力(Reverse Attention,RA)和显示边缘注意力对边界进行建模和增强表征。此外,为了缓解标记数据不足的问题,提出了一种基于随机选择传播策略的半监督分割框架。在文献[15]中,准备了包含20 个案例的3D CT 数据的新数据集,其中包含1 800+个带注释的切片,并提供了一些预先训练的base模型,可以作为现成的3D分割方法。文献[16]中提出了一种编/解码模式的肺分割算法,向网络模型中输入多尺度图像,使用残差网络结构作为编码模块,在编码和解码之间利用空洞空间金字塔池化(ASPP)充分提取上文多尺度信息;最后利用级联操作,将捕捉到的信息与编码层信息级联,结合注意力机制从而提高分割精度。文献[17]中提出了一种基于改进的U-Net网络的肺结节分割方法。该方法通过引入密集连接,加强网络对特征的传递与利用,同时采用改进的混合损失函数以缓解类不平衡问题。
尽管已经有一些深度学习方法为诊断肺炎和肺部分割提供帮助,但是在新冠肺炎CT 切片中与感染分割相关的工作仍然很少。因为存在以下几个问题:新冠肺炎CT 切片中感染病灶的大小和位置时刻变化,目标病灶区域小,边界模糊,磨玻璃区域边界通常对比度低且外观模糊,难以识别。而且由于在短时间内很难获取CT切片中肺部感染的高质量像素级分割注释,所以很难收集足够的数据集来训练深度模型。大部分COVID-19 公开数据集中在诊断上,只有极少数据集提供了分割标签[14]。
仅仅使用原始U-Net 对其训练,存在梯度消失、特征利用率低等问题,最终导致模型的分割准确率难以提高。为了解决上述问题,本文提出了一种改进的U-Net网络的新冠肺炎病灶区域分割算法。
本文根据基本的编码器-解码器结构并结合EfficientNet[18]模型设计了一种改进的深度卷积神经网络模型模型,其网络结构如图1 所示,由编码器、解码器和跳跃连接(Skip Connection)组成。编码器部分使用了EfficientNet-B0 作为特征提取器,EfficientNet 网络通过优化网络宽度、网络深度和增大分辨率来达到提升指标的优点,大幅度地减少模型参数量和计算量,提高了模型的泛化能力。使用DUsampling结构代替解码层路径中的传统上采样方法,利用了分割标签空间中的冗余优势恢复编码路径中丢失的细粒度信息,加快网络收敛速度,增大特征图的分辨率。传统的分割网络仅仅在最后的Softmax层计算预测结果GroundTruth之间的损失,再通过反向传播更新优化网络。但DUpsampling 结构在上采样部分就提前计算特征图与GroundTruth之间的损失,再通过反向传播使解码层中的低分辨率特征图融入高层次语义特征,通过跳跃链接融合更好的中级和高级语义特征,更好地恢复细节。

图1 Efficient-Unet网络结构Fig.1 Efficient-Unet network structure
该算法加强了网络对特征的传递与利用,能够有效缓解新冠肺炎病灶中感染区域小,磨玻璃边界模糊,难以识别和漏检等问题。本文利用COVID-19 公开数据集对改进网络的有效性进行验证,结果表明该网络能够显著提高CT图像下新冠肺炎肺部病灶分割的准确率。
2 本文方法
2.1 编码器-解码器结构
编码-解码器结构是语义分割领域最流行的框架之一,其能够端到端地分割整幅图片。编码器-解码器体系结构将主干CNN 视为编码器,负责将原始输入图像编码为较低分辨率的特征图,之后,使用解码器从较低分辨率的特征图中恢复逐像素预测。
2.1.1 编码模块
EfficientNets是一系列模型(即EfficientNet-B0到B7),它们是通过按比例放大的基础网络(通常称为EfficientNet-B0)得到的,即在网络的所有维度,即宽度(Width)、深度(Depth)和分辨率(Resolution)中采用复合缩放方法。EfficientNets由于其在性能上的优势而备受关注。该系列模型在效率和准确性上超越了之前所有的卷积神经网络模型。宽度是指任何一层中的通道数,深度是指CNN 中的层数,而分辨率与图像的大小相关。使用复合缩放的直觉是缩放网络的任何尺寸(例如宽度、深度或图像分辨率)都可以提高精度,但是对于较大的模型,精度增益将降低。为了系统地扩展网络的规模,复合缩放使用复合系数,该系数控制有多少资源可用于模型缩放,并且通过复合系数按以下方式缩放维度:

其中φ是复合系数,而α、β和γ是可以通过网格搜索固定的每个维度的缩放系数。确定缩放系数后,将这些系数应用于基准网络(EfficientNet-B0),以进行缩放以获得所需的目标模型大小。例如,在EfficientNet-B0 的情况下,设置φ=1 时,在α·β2·γ2的约束下,用网格搜索得出最优值,即α=1.2,β=1.1和γ=1.15。通过更改公式(1)中的φ值,可以放大EfficientNet-B0以获得EfficientNet-B1 至B7。EfficientNet-B0 基线体系结构的特征提取由几个移动翻转瓶颈卷积(MBConv)块,内置的压缩和激发(SE),批处理归一化和Swish激活组成,表1为EfficientNet-B0模型中各层的参数设置。

表1 EfficientNet-B0网络层Table 1 EfficientNet-B0 network layers
MBConv是通过神经网络架构搜索得到的,如图2所示,该模块结构与深度分离卷积(Depth Wise Separable Convolution)[19]相似,由深度可分离卷积和SENet构成。
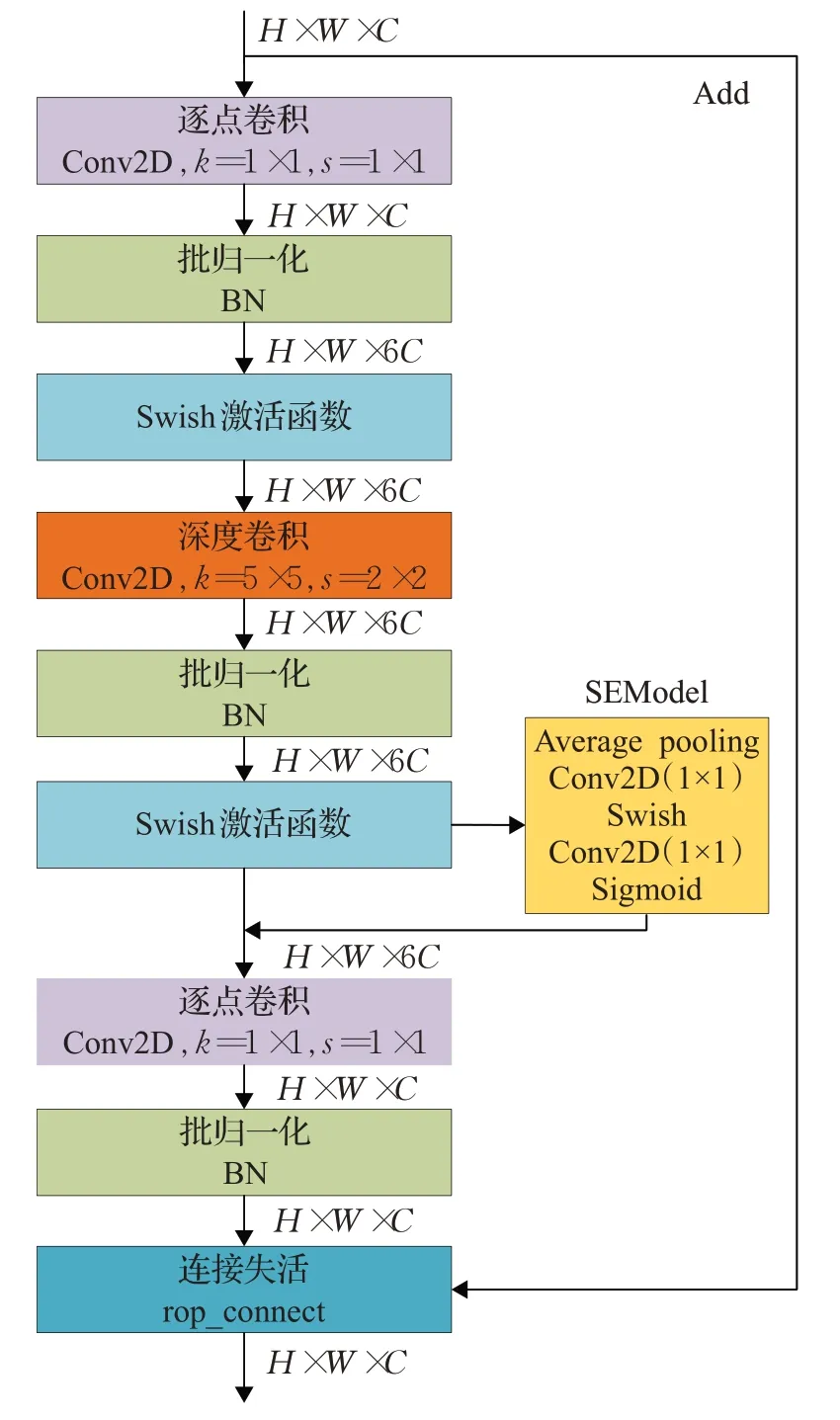
图2 MBConv结构Fig.2 MBConv structure
MBConv 中的压缩和激励操作(称为SE 模块[20])是基于注意力的特征图操作。如图3所示,SE模块首先对特征图执行压缩操作,然后在通道维度方向上执行全局平均池化操作(Global Average Pooling),获取特征图通道维度方向的全局特征。然后对全局特征执行激发操作,使用激活比率(R)乘以全局特征维度(C)个1×1的卷积使其卷积,学习各个通道间的关系,然后通过Sigmoid激活函数获得不同通道的权重,最后将其乘以原始特征图得到最终特征。本质上,SE 模块是在通道维度上做注意力操作或者门操作,这种注意力机制使得模型可以更多的关注更多信息的信息通道特征,同时抑制那些不重要的通道特征。
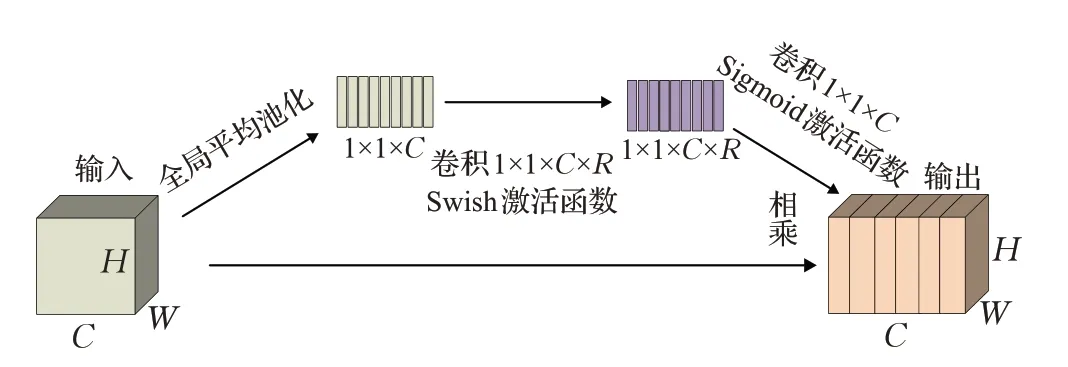
图3 SE结构Fig.3 SE sturcture
对肺炎图像进行预处理后,利用卷积神经网络对预处理图像进行训练。增大网络深度是训练许多神经网络经常使用的方法,这样能捕捉更丰富、更复杂的特征并且适应新任务来进行学习。然而,增加网络的深度会带来梯度消失的问题。增加网络宽度,即特征图通道数增多,更多的卷积核可以得到更多丰富的特征,增强了网络的表征能力,更宽的网络往往能够学习到更加丰富的特征,并且很容易训练。但是对于网络结构过宽且深度较浅的网络,在特征提取过程中很难学习到更高层次的特征。卷积神经网络对于具有高分辨率的输入图像也可以捕捉细粒度特征,这样能丰富网络的感受野来提升网络。上述网络的宽度、深度及图像的分辨率3个指标都可以提高精度,但对于较大的模型,精确度会降低,所以需要协调和平衡不同维度之间的关系,而不是常规的单维度缩放。EfficientNet成功地将网络宽度、深度及提高图像的分辨率通过缩放系数对分类模型进行3 个维度的缩放,自适应地优化网络结构。EfficientNet模型包含从B0 到B7 的8 个模型,每个后续模型编号均指代具有更多参数和更高准确性的变量。EfficientNet 体系结构使用迁移学习来节省时间和计算能力,因此,它提供了比已知模型更高的精度值。这是由于在深度、宽度和分辨率上使用了巧妙的缩放比例。本文使用了B0模型,因为它包含5.3 m参数,使用B1之后的模型,模型的参数会增加,但已经饱和,效率不高。
本文并未网络权重上进行随机初始化,而是在EfficientNet 模型中实例化了ImageNet[21]的预训练权重,从而加快了训练过程。ImageNet 的预训练权重在图像分析领域表现出了非凡的成就,因为它包含超过1 400 万幅涵盖折衷类的图像。优化过程将在新的训练阶段微调初始训练前权重,以便可以将训练前的模型拟合到特定的感兴趣区域。
2.1.2 解码模块
在解码器还原图像尺寸的过程中,将传统的上采样操作换成DUpsampling 结构[22],一种基于数据依赖的新型上采样结构。如图4所示,上采样结构通常存在于分割网络的解码层中,其功能是将特征图恢复至原始图像的尺寸。尽管双线性插值和最近邻插值的上采样操作可以在一定程度上捕获和恢复卷积层提取的特征,缺点是其在准确恢复逐像素预测中的能力有限。双线性上采样不考虑每个像素的预测之间的相关性,因为它与数据无关,这种弱数据的卷积解码器无法生成相对高质量的特征图。DUpsampling 利用了分割标签空间中的冗余优势,能够从相对粗糙的CNN 输出中准确地恢复逐像素预测,从而减轻了卷积解码器对精确响应的需求。更重要的是,它使融合特征的分辨率与最终预测的分辨率解耦。这种解耦使解码器可以利用任意特征聚合,因此可以利用更好的特征聚合,从而尽可能提高分割性能。
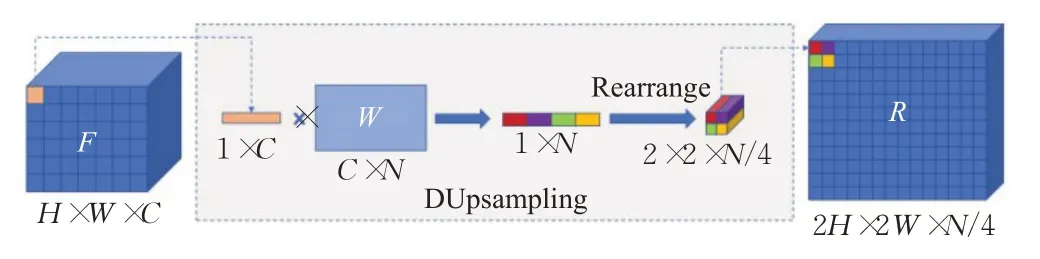
图4 DUpsampling结构Fig.4 DUpsampling structure
这种新颖上采样方法可以生成逐像素预测,消除了来自底层CNN 的计算效率低下的高分辨率特征图,这使得编码模块无需减少其步长从而使得计算时间和内存占用大幅度改善。同时由于DUpsampling的高效,使得解码器能够将融合的特征下采样至较小的分辨率,这不但减小了解码器的内存占用而且将待融合的特征与最终预测解耦,这种解耦使得解码器能够利用任意的特征聚合从而获得最优结果。
3 实验与分析
本文的模型在TensorFlow 和Keras 框架下实现,硬件环境:CPU 为I7 8700K 处理器,GPU 为NVIDIAGet-Force 1080Ti。首先通过对比实验选择最适合的损失函数、训练模型,利用快照集成得到不同的模型,将模型集成。最后,将本文的网络和其他网络结构进行性能对比测试。
3.1 数据集介绍
上采样的具体操作如下:将H×W×C的图像上采成2H×2W×N/4 的图像,图2 中,RH×W×C表示CT 图像经过编码输出的特征图,H、W、C分别表示特征图的高度、宽度、以及通道数。1×C代表针对特征图F中的每个像素维度,将其乘上一个待训练矩阵W,其维度为C×N,最终会得到一个1×N的特征表示,再将向量Rearrange为2×2×N/4 的表示,也就完成了上采样的过程,R表示经DUpsampling结构2倍上采样后得到的特征图,经过重排后就相当于对原始的每个像素进行2倍的上采样。上面的W是根据已知的训练标签得到的。在训练集中真正的分割表示是已知,对每个分割图进行一个矩阵转换,将其转化称为与Encoder 模块得到的特征图相同的维度上。其过程表达式如下:
本文采用COVID-19CT分割数据集[23],其中包含两个版本。此数据集的第一个版本包含40 例COVID-19患者的100幅轴向CT图像,所有图像均标记为COVID-19 类。该数据集具有四种类型的真实分割蒙版,称为“磨玻璃结节”(掩膜值=1),“肺实变”(掩膜值=2),“胸膜积液”(掩膜值=3)和“背景”(掩膜值=4)。原始的CT图像和所有地面真相蒙版的尺寸为512×512。数据集的第二个版本已扩展到829 张图像(来自9 位患者),其中373 张被标记为COVID-19,其余图像被标记为正常。此数据集的第二个版本中图像和掩膜的尺寸大小为630×630。将这两个版本合并在一起,总共包含49 个人,一共929张样本。
如图5 中显示了来自此数据集的两个样本图像。第一列的图像表示原始图像,后四列分别代表及对应的4种类型的COVID-19蒙版。图(a)和图(b)的图像表示一个COVID-19 患者样本图像和一个正常人的样本图像。真实分割掩膜中的磨玻璃混浊和肺实变为黄色,而黑色像素表示健康区域(请注意,如果磨玻璃混浊和肺实变掩膜是完全黑色的,则表示给定的CT 图像属于健

图5 数据集样本Fig.5 Dataset sample

矩阵P是矩阵W的反变换,其中v表示的是真正的分割结果中的区域表示,是重新构建的v,神经网络以标准随机梯度下降(SGD)迭代地优化其目标,矩阵P和W可以通过最小化v和之间的误差得到,形式化定义如公式(3):康人)。绘制红色和黑色边界轮廓是为了更好地显示包含COVID-19中的磨玻璃混浊和肺实变的部分,而不是原始图像的一部分。

在对上述几种类型的掩膜进行了仔细检查和分析之后,本文决定只专注于真实磨玻璃掩膜,因为:一方面,后面两种掩膜对疾病的诊断和病灶分割来说并没有太大作用,肺实变掩膜有大量缺失;另一方面,仅仅通过磨玻璃区域也是可以作为辅助诊断COVID-19。
3.1.1 预处理
预处理包括:调窗处理和灰度值标准化。调窗处理是针对不同的器官选择合适的CT 窗口,本文中将所有大于窗口CT 值修改为窗口最大值,所有小于窗口最小值的CT值修改为窗口最小值。本文针对肺炎病灶分割选择CT 值范围为[-1 500,500]。灰度值标准化是将灰度值减去灰度值的均值,再除以标准差,这样可以方便处理数据和加快模型收敛。灰度值和标准差均通过统计训练数据计算得到。如图6 中显示了预处理前后数据集一(蓝色)和数据集二(黄色)的CT值分布直方图。

图6 预处理前后对比Fig.6 Comparison of before and after pretreatment
3.1.2 数据增强
当只有少量训练样本可用时,数据增强对于训练网络所需的不变性和鲁棒性至关重要。本文应用随机旋转、随机剪裁、随机水平翻移动等图像增强方法来处理训练集中的图像和掩膜。训练集包含1 810张图和分割掩膜;验证集包含150 张图像和分割掩膜,测试集包含10 张图像,所有训练集和测试图像大小统一为256×256,并进行归一化处理。
3.2 评价指标
为了多角度充分说明本文算法的性能,本文采用了3种用于评估医疗影像分割效果的评估指标来衡量细分模型的性能,包括准确率、召回率、Dice 系数,这些度量标准也广泛用于医学领域。定义如下:

其中,TP(True Positives)表示被正确检测为正样本的像素数量;FP(False Positives)表示被错误检测为正样本的像素数量;FN(False Negatives)表示被错误检测为负样本的像素数量;TN(True Negatives)表示被正确检测为为负样本的像素数量。A是分割结果像素构成的集合,B是实际数据集标签像素构成的集合。将Dice 系数(DSC)作为主要评价指,Dice系数的取值范围是[0,1],Dice其值越大,两幅图像越相似,分割效果越准确。
3.3 参数设置及训练
采用Adam优化器进行优化,除学习速率外其余参数采用默认配置。其中,batch-size设置为12;初始学习率设置为0.001;动量参数设置为0.9。如图7 展示了在训练过程中本文算法在训练集和验证集上的损失值与训练迭代次数的关系。从图中可以看出,网络的损失值随着训练迭代次数的增加而降低,当训练迭代次数超过30时,验证集的损失值趋于稳定。因此,本文实验中的训练迭代次数设置为30。

图7 损失值与迭代次数变化Fig.7 Change in loss value and number of iterations
3.3.1 不同损失函数的对比分析
实验发现本文模型的分割性能和损失函数的选择有关,因此为了获得最合适的损失函数,得到最好的分割性能,本文针对二值交叉熵损失函数、Dice 相似系数损失函数和组合损失函数进行了对比实验。表2 列出了在3 种不同损失函数下的分割效果,实验发现,当采用组合损失函数均可以达到最优的分割结果,其原因在于肺部磨玻璃区域在图像上的占比面积较小,使用单一的损失函数进行优化时,磨玻璃区域所对应的梯度变化容易受到其他背景区域梯度的影响,导致网络训练困难,而组合损失函数综合了两种损失函数的特点,在网络反向传播过程中能够对难以学习的样本进行稳定且有针对的优化,从而能够缓解类别不平衡的问题,提升模型的分割性能。
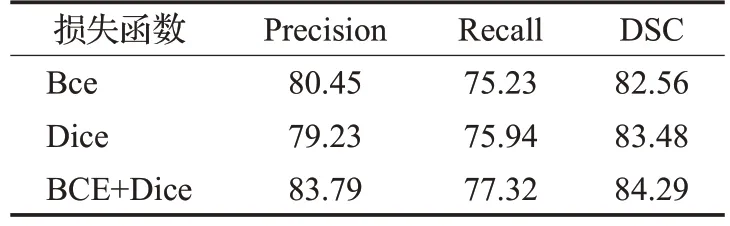
表2 损失函数对比Table 2 Loss function comparison %
3.3.2 模型快照集成
众所周知,神经网络的集成比单个网络更健壮和准确。但是,训练多个深度网络进行模型平均在计算上很费时费力。快照集成(Snapshot Ensembling)[24]这是一种无需任何额外培训成本即可获得神经网络集成的简单方法。它的主要概念是训练一个模型,不断降低学习率,利用SGD收敛到局部最小值,并保存当前模型权重的快照。然后,迅速提高学习率,逃离当前的最优点。此过程重复进行直到完成循环。余弦退火学习率是一种在训练过程中,如图8所示,调整学习率的方法,随着epoch 的增加,learning rate 先急速下降,再陡然提升。为CNN创建模型快照的主要方法之一是在单次循环余弦退火训练中收集多个模型。每个时期的循环余弦退火的学习率定义为:
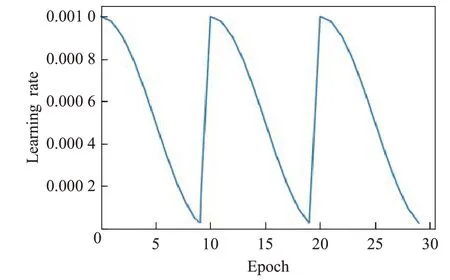
图8 学习率变化Fig.8 Learning rate change
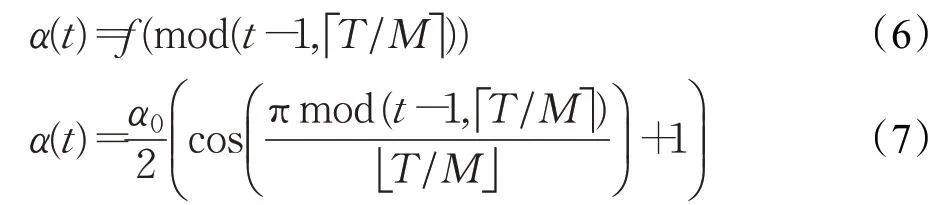
其中α(t)是在时期t的学习率,t是迭代次数,α0 是初始学习率,T是训练迭代的总数,M是循环周期。训练M个训练周期后,我们得到M个模型快照f1,f1,…,fM,每个快照都将用于集合预测中。
3.4 实验结果及分析
3.4.1 快照集成的对比分析
由于模型的分割性能和学习率的选择有关,而随着学习率的循环变化,模型的效果也是循环变化。每个集成包括一次训练中生成的总共M个模型快照,因此为了寻找最合适的模型集成循环周期M,得到最好的分割性能,本文对比实验了3种模型组成。
由表3 可见,M=3 的情况下比其他基本模型产生了更好的结果。可以看出单独模型的准确率是83.79%,召回率是77.32%,Dice值是84.29%;M=3 时准确率是84.38%,召回率是78.64%,Dice 值是85.87%;M=4 时准确率是84.24%,召回率是80.43%,Dice 值是85.12%。每个集成都包含来自以后周期的快照,因为这些快照受到了最多的训练,因此可能会收敛到更好的最小值。但是并不是集合更多的模型都可以提供更好的性能,当第4个模型添加到集合中时,观察到各指标均有下降。因此,本文实验中的M选择为3。
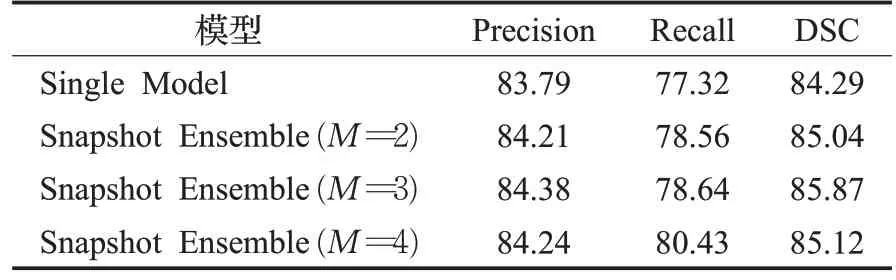
表3 模型集成周期对比Table 3 Model ensembles cycle comparison %
3.4.2 改进上采样前后对比分析
如表4 所示,用DUpsampling 替换传统上采样方法前后相比,在衡量模型分割能力的指标准确率上,DUpsampling比传统方法提高了1.04 个百分点,在召回率这一指标上,DUpsampling比传统方法提高了2.09 个百分点,在DSC 这一指标上,DUpsampling 比传统方法提高了2.39 个百分点,解码器计算量也减少了50%左右,说明了DUsampling在恢复特征图尺寸的同时,提升了分割精度,降低了计算复杂度和计算量。

表4 传统上采样方法改进前后对比Table 4 Comparison of traditional sampling method before and after improvements
3.4.3 不同分割方法的分析
为了验证改进的Efficient-UNet 模型的分割性能,将本文与FCN、U-Net、SegNet[25]和CE-Net[26]4 种分割网络进行对比。根据相同的网络参数设置,分别对以上5种网络进行训练,并利用测试集对训练好的模型性能进行测试。实验结果如表5所示。
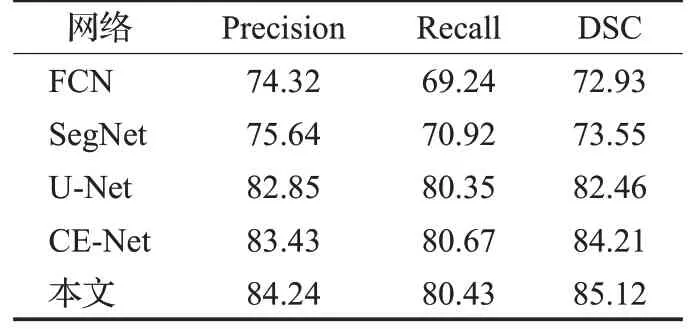
表5 Efficient-UNet与其他网络对比Table 5 Efficient-UNet compared with other networks %
本文所提方法在Precision、Recall 和DSC 上均有提升。相比于基础网络FCN,所提方法在Precision、Recall和DSC 上分别提升了9.92 个百分点、11.19 个百分点和12.19 个百分点。与网络SegNet 相比,在Precision、Recall和DSC上也分别提升了8.6个百分点、9.51个百分点和12.19 个百分点。这是由于FCN 和SegNet 没有考虑全局的上下文信息和像素与像素之间的关系,没有充分利用各层网络所提取的图像特征,网络对于编码器部分所提取到的特征,只是单纯地进行了上采样操作将其恢复到输入图像大小,忽略了空间一致性,会导致边缘模糊以及空间丢失,因此模型的分割结果比较粗糙。与网络U-Net相比,Precision提升了1.39个百分点,Recall提升了0.08个百分点,DSC提升了2.66个百分点。与FCN和SegNet 相比,U-Net 中引入了跳跃连接,网络得以将浅层的简单特征和高层的抽象特征结合起来,这有助于补充空间的细节。但是由于肺炎图像数量少,且磨玻璃区域具有边缘模糊,目标小等特点,对其提取特征较为困难,仅使用原始U-Net训练,存在梯度消失,特征利用率低等问题。CE-Net可以看出经过算法改进很大程度上改善了以上缺点,使分割精细程度大大提升。
由于本文算法在U-Net 上进行改进,故本文选取U-Net模型作为对比,在训练过程中,比较两者对于系统资源的占用情况,如表6 所示。可以看出,与U-Net 相比,改进后的模型无论在显存占用、GPU使用率还是训练时间上都更加具有优势。
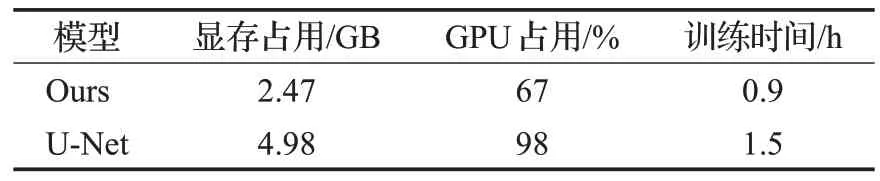
表6 Efficient-UNet与U-Net系统资源占用情况对比Table 6 Occupation of system resources of U-Net and Efficient-UNet
如图9 选择6 个不同的CT 图像分割结果的可视化。可以看出,几种方法对于磨玻璃的细节均有漏分和过多分割的现象,图(a)是输入模型的肺部图像,图(b)是医生标注的肺部磨玻璃轮廓金标准,图(c)是使用本文算法对肺部磨玻璃分割的结果。与网络CENet相比,所提方法在Precision提升0.81个百分点,DSC提升了0.91 个百分点。说明本文所提方法在新冠肺炎病灶分割上确实更精确。对比观察图中,磨玻璃在图像中所占比例较小,且其像素值与背景区域中的肺部积液和血管等组织相近,未改进的网络容易受到与病灶相似的干扰区域的影响,错误地将背景区域预测为病灶区域。相比之下,本文提出的改进后的网络能够有效地区分磨玻璃区域与其他肺部组织,对磨玻璃轮廓的分割更为精确。

图9 不同模型的磨玻璃分割结果Fig.9 Segmentation results of ground-glass in different models
4 结束语
磨玻璃是新冠肺炎早期阶段的特征,从CT 图像中准确地检测磨玻璃对新冠肺炎预防和治疗具有重要的作用。为了有效检测CT 图像中的病灶信息,本文以EfficientNet-B0 为backbone,结合编码器-解码器结构,提出了一种改进的深度卷积神经网络模型。该模型通过使用深度可分离卷积、压缩和激励操作操作和DUpsampling上采样操作改进传统编码-解码模型,对各种复杂细小的肺炎磨玻璃图像具有更强的特征提取能力,同时降低了模型的计算量。在对比实验中,本文模型在训练集和测试集上均表现出比其他已有模型更好的分割效果和泛化能力,能够有效提取CT 图像中的新冠肺炎病灶区域。下一步,将考虑到医疗图像的特殊性,在数据规模扩充、总体网络结构以及参数的优化等多个方面对模型进一步优化。
