基于金字塔场景分析网络改进的语义分割算法
2021-10-14孟凡云王金鹤
王 嘉,张 楠,孟凡云,王金鹤
青岛理工大学 信息与控制工程学院,山东 青岛 266000
语义分割是计算机视觉中一个重要的分支领域,其目的是为图像当中每个像素标记类别标签,从而表示该像素的语义信息,采用学习到的算法模型预测同分布新图像的每个像素标签,将不同类别的对象分割出来。语义分割在自动驾驶、遥感图像分析、机器人传感、医疗图像等方面有着广泛的应用[1-2]。对于这一类问题,如何在预测图像中具有良好的推理精度,有效区分易混淆的类别,以及图像中边缘轮廓的细化是要解决的问题关键。
在早期,传统分割任务由于计算能力有限,只能处理一些灰度图,经历了一段时间的发展之后开始能够处理RGB 三通道图,此时主要通过提取图片的低级特征来进行分割,出现了Ostu[3]、N-Cut[4]等方法,但是它们分割出来的结果并没有语义的标注。伴随着计算机计算能力的提高,图像的语义分割成为了研究的重要课题之一。全卷积神经网络(Fully Convolutional Networks,FCN)[5]的出现,使得图像语义分割领域取得了巨大的进步,当前最先进的语义分割框架大多数是基于FCN 实现的,如PSPNet[6]、Deeplabv2[7]、Deeplabv3[8]等。PSPNet引入金字塔池化模块,加强了对局部信息的利用,Deeplabv2 通过使用不同空洞率的空洞卷积进行采样,多尺度的捕捉图像上下文,并采用条件随机场增强细节捕获的能力,Deeplabv3 在Deeplabv2 基础上继续改进了空洞卷积部分结构。这三个结构识别精度较FCN均有明显提升,但对图像中对象边界轮廓的处理仍是要关注的问题。
目前,提升语义分割表现力主要有五种基本思路。第一种是使用编码-解码结构来融合多级语义特征,如SegNet[9],能够有效改善对边界的处理,但像素语义类别分类准确度较低。第二种是使用分解结构来增大卷积核尺寸,可将7×7 的卷积核转换成3 个3×3 的卷积核实现更轻量级运算;或者使用空洞卷积在相同卷积核大小条件下通过增加空洞率来拓宽感受野[10]。第三种是使用递归神经网络来挖掘特征长程依赖关系,如LSTM网络[11]。加入了时间特征,将时空信息结合,更适合应用于视频流的语义分割任务中。第四种是基于空间与通道的自注意机制来捕获上下文依赖关系,如DANet[12],在空间中,无论距离如何,认为类似的特征都将彼此相关,同时也强调通道中的相互依赖关系。第五种即利用多尺度上下文信息融合,把全局信息与局部信息结合,如PSPNet、Deeplabv2、Deeplabv3。
PSPNet在当前语义分割各项排行榜中均取得了良好的结果,在使用MS-COCO数据集[13]预训练与ResNet101[14]构建的结构中,MIoU可达到85.4%,处于先进水平。众所周知,随着网络层数的加深,越高的层次能够提取更丰富的语义信息,而较低的层次具有的语义信息较少但具有较准确的空间位置信息。基于此,本文认为PSPNet原本由ResNet[14]网络产生的特征图包含位置空间信息相对较少,需考虑在高层次特征图中纳入低层次的特征信息,将二者融合得到更丰富的特征图。因此本文提出了一种基于PSPNet结构改进的网络结构:首先,在特征提取方面将输入图以ResNet50[14]的基础上通过内部增加卷积、池化操作进一步学习低层次的特征;其次,将学习的多个低层次特征图与高层次特征图相加,得到新的包含更多信息的特征图;最后,沿用了PSPNet的金字塔池化结构,将特征图中全局上下文信息与不同尺度局部上下文信息相结合,并卷积、上采样至与输入图像相同大小得到最终预测图。
1 金字塔场景分析网络
在深度学习中,感受野的大小间接的决定了使用图像上下文信息的程度,ResNet 通过空洞卷积与跨层连接使得感受野有效扩大,但是随着网络深度的增加,实际感受野仍比理论的感受野要小。PSPNet中金字塔池化模块使用不同尺度的池化有效缓解了网络中实际感受野不及理论感受野的情形,PSPNet 网络结构如图1所示。

图1 PSPNet结构Fig.1 PSPNet structure
PSPNet 总体结构:首先,通过卷积神经网络(Convolutional Neural Network,CNN)从输入图像中提取特征获得特征图;其次,对所得特征图通过结合金字塔自适应平均池化模块捕获不同子区域的特征,将子区域特征上采样并与先前全局特征CONCAT,使得当前特征包括了全局特征和局部特征;最后,通过卷积与上采样操作得到最终预测结果。
图1 中以蓝色虚线所框出部分是PSPNet 网络中的核心部分,即金字塔池化模块。在金字塔池化模块中对所得特征图分别使用1×1(红色)、2×2(黄色)、3×3(蓝色)、6×6(绿色)4 个尺度自适应平均池化,以此作为先验信息并进一步依次做卷积、batch normalization、Relu操作学习局部的特征信息并进行特征图降维,将所学不同尺度的特征图上采样与应用金字塔池化结构前的原始特征图融合。
PSPNet 在语义分割中引入了更多的上下文信息,取得背景先验,与FCN方法相比,它的语义分割的误分割率显著降低。举例说明:FCN中会将船的类别误分割为车,而一辆车在水上的可能性极低,由背景先验(水)可以知道这是明显的不匹配,因此,PSPNet分割可以做到更精准[6]。
尽管PSPNet 取得较好的精度结果,但仍存在问题值得关注。如图2所示,使用ResNet50网络特征提取复现PSPNet结构,图2(a)是需预测的输入图像,图2(b)为Ground Truth,图2(c)是PSPNet方法对输入图像的分割结果。按行来看,第一行人物的衣服与胳膊及背景之间分割不准确;第二行总体类别区分正确,但所分割对象(飞机)与背景图像(黑色部分)在衔接部分存在较大损失;第三行对牛的类别分割具有较大语义误匹配现象。

图2 PSPNet的局限性Fig.2 Limitations of PSPNet
2 改进的金字塔场景分析网络
通过实验观察并分析FCN与PSPNet方法应用于语义分割的实际表现,本文采用PSPNet 作为主要结构有效结合全局上下文与局部上下文信息。针对由图2 观察到的PSPNet结构边缘轮廓和衔接部位语义分割不准确以及语义误匹配问题,通过改动PSPNet 结构中特征提取模块,以此构造一个新的网络,命名为PSPNet+。
2.1 卷积层与池化层
卷积层的主要作用是特征提取以及修改特征图通道数。在进行卷积运算时,卷积核以核的大小为局部区域按照相应的步长对特征图扫描,每一次扫描将特征图中局部特征与卷积核中参数执行对应元素矩阵乘法运算与累加操作并通过广播机制与偏置相加。全连接层某一层中计算如式(1)所示:

其中,N为本层输入图像的值的集合,xi代表第i个像素的像素值,wi为与xi对应的权重,b为偏置。此方法需将图像先变平(flatten)为一维数组,损失了原有图像形状信息,而卷积层可以保留原有形状。
池化层是统计一定区域内最具代表性特征,有效降低输入特征尺度,起降维作用。常见的两种池化操作分别是最大池化(max pool)和平均池化(average pool)。最大池化操作选择区域内所有数值中的最大值,平均池化操作选择区域内所有数值的平均值。
2.2 特征图融合
特征图融合能够将不同层次的特征图结合,是提升特征图表现力的有效途径之一。对应元素相加(element-wise add)是一种高效的特征融合方式。基于element-wise add 操作,增强了描述图像的特征的信息表达,但图像本身的维度却没有增加。具体如式(2)所示:

其中,C表示通道总数,Xi与Yi分别表示特征图X和特征图Y分别在第i个通道的特征图,Ki为卷积核中在第i个通道的卷积核,⊗表示卷积操作。Hadd为特征图融合后单卷积核卷积输出结果。
2.3 改进结构具体参数
如图3 体现了ResNet 中bottleneck 结构细节:先使用一个1×1的卷积,其作用是减少通道数,中间使用3×3卷积并使输出通道数等于输入通道数,最后一个卷积使用1×1使当前通道数恢复至最初通道数,此时bottleneck的输出通道数等于bottleneck 的输入通道数,并在其中附加一个支路传递低层的信息。

图3 bottleneck结构示意图Fig.3 Schematic diagram of bottleneck structure
受此启发,为保留低层次特征图中的空间信息以细化边缘轮廓以及衔接部位的分割,提出了PSPNet+网络结构,如图4、5所示,图5即为图4中增加的Proposed部分详细结构。

图4 PSPNet+整体结构Fig.4 PSPNet+overall structure

图5 Proposed中细节部分Fig.5 Proposed details
对PSPNet 里CNN 获取特征图的步骤,将其中ResNet 结构进行改动,并以红色进行标注,其中CONV表示卷积操作,max pool与avg pool表示最大池化操作与平均池化操作。分别在LAYER1、LAYER2、LAYER3后使用了卷积、池化操作,从而得到特征图y1、y2、以及y3。在LAYER1后使用卷积核大小为3×3、填充为1、步长为2 的卷积核,并将通道大小由256 转化成2 048,其后使用max pool 来获取特征图中较多的纹理信息;在LAYER2 中,使用大小为1×1 的卷积核,将通道大小由512转化成2 048,仍使用max pool进行池化;在使用空洞卷积空洞率为2(Dila=2)的LAYER3 层,使用大小为1×1 的卷积核,将通道大小由1 024 转化成2 048,使用avg pool 来获得此时特征图中较多的背景信息;LAYER4 同PSPNet 一致,输出原始特征图,最后将y1、y2、y3与原始特征图通过element-wise add特征融合操作得到位置、纹理更加精确新的特征图。具体各层间信息如表1所示,其中操作一栏中3×3、1×1表示不同的卷积核大小,s代表步长,p代表填充,括号结构乘上具体的数字表示有几个这样的结构堆叠,输出图像大小格式为batchsize×channel×height×width,其中batchsize表示批量大小,channel表示通道数目,height表示图像高度,width表示图像宽度。

表1 Proposed中具体参数Table 1 Specific parameters in Proposed
3 实验与评估
在本文实验中,模型的训练、验证以及测试均采用Pytorch深度学习框架,操作系统为Ubuntu16.04,网络训练及性能测试的GPU 服务器为单块NVIDIA GeForce GTX TITAN X。使用PASCAL VOC 2012[15]训练集进行模型训练,PASCAL VOC 2012测试集评估算法泛化能力,以及验证集进行预测分割效果可视化。采用随机梯度下降法,动量参数设置为0.9,权重衰减值为0.000 1。并应用“Poly”学习率策略,“Poly”具体算法如式(3)所示。其中初始学习率initial_lr为0.01,指数power设置为0.9,current_lr表示当前学习率,iter表示当前迭代次数,max_iter表示最大迭代次数。

3.1 数据集介绍
本文在PASCAL VOC 2012数据集上进行了实验,该数据集共包含20 个对象类别和1 个背景类。在原始PASCAL VOC 2012 数据集基础上使用逆检测器的语义轮廓[16]提供的附加注释来扩充数据集,并通过旋转、随机缩放等操作进行数据增强。PASCAL VOC 2012测试数据集的Ground Truth为非公开数据集,要评估模型在测试数据集上的表现,需提交至官网在线评估模型性能。特别说明:在此数据集中与其他视觉任务不同的是,对于语义分割任务,PASCAL VOC 2012 数据集中训练集与验证集中包含2007 至2011 年间的所有数据集,测试集则包含2008 至2011 年间的数据。2007 年的测试集图像因其公开则根据分配的不同包含于2012年的训练集与验证集中。
3.2 FCN与PSPNet局限性
使用PASCAL VOC 2012训练集进行训练,并运用PASCAL VOC 2012验证集预测结果便于可视化,分别以FCN、PSPNet以及PSPNet+三个网络结构进行实验,结果如图6所示。由图6可知FCN与PSPNet存在以下局限性。

图6 FCN、PSPNet与PSPNet+实验结果比对Fig.6 Comparison of FCN,PSPNet and PSPNet+experimental results
语义类别分类错误:第一行图像中,FCN 方法对牛对象的分割产生的语义类别差异较大,部分像素分类为马,PSPNet对此有效作出改进,但与腿部衔接部分不平滑。
细节区域分割不精:第二行图像中,对于自行车的类别分割准确,但车轮的细节部分体现较粗糙,PSPNet较FCN能分割出更多细节。
边缘形状不准确:第三、四、五行图像出现问题可归为一类,FCN与PSPNet的预测同Ground Truth作比较,对象的边缘轮廓刻画不准确。
总结以上观察,许多错误部分基本与上下文关系和特征图中的位置信息有关。因此,本文借鉴PSPNet 把全局信息与多尺度局部信息结合,增强上下文关系衔接;并将低层次特征图学习到的位置信息与高层次特征图学习到的语义信息整合,以提高语义分割的表现力。在图6 最后一列中,PSPNet+方法对如上所述FCN 与PSPNet的局限性做出了一定的改善。
3.3 改进实验结果评估
PSPNet+模型是在基于ResNet50 网络进行特征学习的PSPNet 模型上所改进,两个模型均在扩展后的PASCAL VOC 2012训练集与验证集中训练、验证。从验证集中选取个别图像使用得到的最佳模型权重参数验证时,像素准确率(pixel accuracy)与MIoU 的值如表2所示。从表中可以看出所改进算法PSPNet+相对于基准算法PSPNet在验证集精度方面取得了相应的增强。
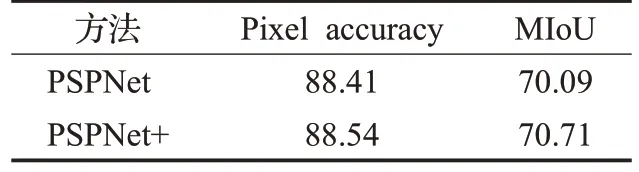
表2 验证集中的表现比较Table 2 Performance comparison in validation set %
表2只表示了在部分验证集中的表现,而真正评估一个学习算法的泛化能力优劣要以测试集中的结果为准。如表3 所示[5,17-19],将PSPNet 与PSPNet+在PASCAL VOC 2012非公开测试集中进行测试,并送入线上平台进行评估,PSPNet+得到了较好的实验结果。可以看到除bike、train 两类,在其余类别中均实现了精度方面的改进。总体的MIoU 值同PSPNet 的MIoU 值相比增加了1.7%。并且与其他当下流行方法相比,精度结果较好。

表3 各算法分类精度评估Table 3 Classification accuracy evaluation of each algorithms %
针对所改进结构进行了逐层的消融实验,分别对基准PSPNet 结构预测结果,在LAYER3 层后进行卷积池化得到的特征图y3与原特征图相加,再金字塔池化所得的预测结果,LAYER2层后与LAYER3层后分别得到的特征图y2、y3与原特征图相加,再金字塔池化所得预测结果与所提出的PSPNet+结构得到预测结果相比较,如表4所示。可以看出随着所附加的低层次信息越多,MIoU数值越来越高,这证实了将低层次的特征信息纳入至高层次特征信息,能够捕捉到更丰富信息,如图7为消融实验中各个方法的可视化结果。

图7 消融实验可视化结果Fig.7 Visualization results of ablation experiments

表4 特征图消融实验Table 4 Feature map ablation experiments %
PSPNet、PSPNet+模型在验证集分别得到的预测结果如图8所示,黄色方框框出了重点改善的部位。第一行可以看出PSPNet模型对于飞机的分割在机身与机尾之间衔接处出现部分损失,将此处误分割为背景类,对对象的分割缺乏了整体平滑性,而PSPNet+则对此部位有效做出了衔接,改善了分割效果。第二行图像中应用PSPNet方法时,自行车车轮边缘分割较粗糙,将背景类误分割为自行车类别,本文所提出的PSPNet+所得结果相对较优。第三行对飞机机翼与后方小飞机语义分割可看出比起PSPNet方法,PSPNet+对轮廓边缘的分割更接近Ground Truth。第四行中,PSPNet模型仅能分割出小部分人物类别,PSPNet+有效作出改进。
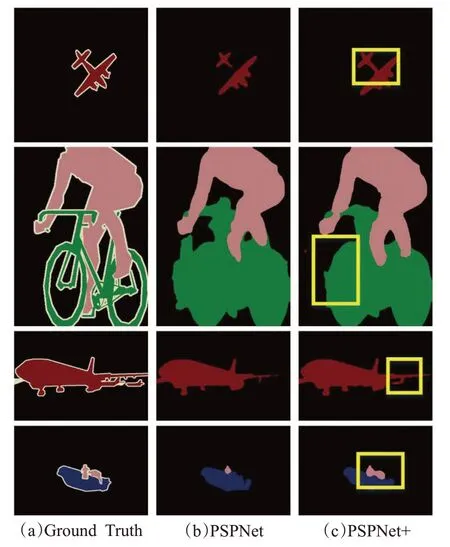
图8 PSPNet与本文PSPNet+结果可视化比较Fig.8 Visual comparison of results between PSPNet and proposed PSPNet+
综上所述,依据线上评测数据结果与可视化体现,所提PSPNet+方法考虑纳入更多低层特征信息的特征提取方式与金字塔池化结构相结合,切实有效地对对象的边缘、内部衔接部位以及个别细节方面作出改善,一定程度上缓解了基准算法的局限性。
4 结束语
针对现有的语义分割网络结构中存在的边缘轮廓信息描述不准确、部分细节信息较大缺失问题,结合现有的精度较高网络PSPNet及卷积、池化、特征图融合操作,对原有的PSPNet方法进行了改进,提出新的PSPNet+网络架构。实验结果表明,与FCN、PSPNet网络结构相比较,改进后的网络结构不仅能够对边缘、轮廓的语义类别刻画较准确,且更加关注低层次特征的位置信息与纹理信息的提取,提升了整体结构的精度,改善了最终预测图的效果。本文没有采用任何后处理操作,但使用的是较浅层的ResNet 网络学习特征,后期工作会继续实验较深的ResNet网络,与更高层次的语义信息结合,且适当调整参数的数量。
