融合物品信息的社会化推荐算法
2021-10-14卫鼎峰
卫鼎峰,李 梁,柴 晶
1.太原理工大学 信息与计算机学院,太原 030600
2.太原师范学院 城市与旅游学院,太原 030619
互联网的高速发展极大地便利了人们的生活,然而各种各样的信息充斥着人们的生活,但人的精力是有限的,一些杂乱的冗余信息显然并不值得关注,为此,推荐系统的应用而生让人们对感兴趣的事物更加专注。数据稀疏性问题是限制传统推荐算法性能的重要因素,社交网络的引入可以缓解了这一问题,使推荐算法更加优化。由生活经验可知,人们判断某些事物时,往往会征求他信任朋友的意见[1-2],因此,社交朋友对产品的推荐上有很大的推动作用。大量融合社交网络的推荐实验表明,引入社交网络会改善推荐算法的性能,提高冷启动用户推荐的准确性。然而在大量的社交推荐算法中,仅仅只是对用户和其好友之间的特征向量的限制,并未对物品与其相似性物品的特征向量进行限制,阻碍了社交推荐算法的性能。
为解决上述问题,本文通过用户与物品的交互图构建物品相似性网络,在物品相似性网络上通过随机游走的方法得到物品节点序列,并将其输入到SkipGram 中得到物品的特征向量,依靠余弦相似度构建出Top-K个相似物品,从而构建物品隐性相似性网络。同时,融合隐性物品相似性网络和社交网络,利用图神经网络编码用户和物品的嵌入表示,并通过正则化迫使该物品与相似物品的特征接近,用户与社交好友的偏好接近,实现了物品相似性传播和用户的信任传播。在三个公开的数据集上进行测试,结果表明:本文所提出的改进算法优于同类的社交推荐算法,并在一定程度上提升了冷启动用户的推荐性能。
1 相关工作
随着深度学习的兴起,基于神经网络的推荐算法改善了传统推荐算法的性能。文献[3]提出了神经矩阵分解模型即利用多层感知机学习用户和物品之间的交互函数,提升其非线性建模的能力。文献[4]提出了使用外积来显式地对嵌入维度之间成对的相关性进行建模,即利用用户和物品的外积建立成二维交互作用图,并使用卷积神经网络来学习特征向量维度之间的高阶相关性,进而改善推荐性能。而编码器的研究在神经网络中也占有一席之地,为此,文献[5]提出了协作降噪自动编码器(CDAE),即用于利用降噪自动编码器对物品推荐。文献[6]将变分自动编码器扩展到用于隐式反馈的协作过滤,这种非线性概率模型能够超越线性因子模型的有限建模能力。文献[7]提出了一个联合协作自动编码器框架,该框架可同时学习用户与用户之间和物品与物品之间的相关性,从而产生更强大的模型并提高推荐性能。但是,在深度学习领域中,图神经网络天然地适用于物品推荐,产生更好的推荐性能。因此,本文利用图神经网络获取用户和物品的特征向量。
在实际生活中,人们购买商品时更习惯倾听朋友的意见,依据这一现象,社交推荐算法应运而生。文献[8]利用概率矩阵分解模型进行社交推荐即SoRec模型,将评分矩阵分解为用户特征矩阵和物品特征矩阵,社交矩阵分解为用户特征矩阵和好友特征矩阵,其中,用户特征矩阵的共享将评分矩阵和好友矩阵联系起来。为了更具有可解释性,文献[9]提出了RSTE 模型,即用户最终对物品的预测来源于两方面,一方面是用户本身对物品的预测,另一方面是该用户社交朋友对该物品的预测,为此,加权两方面的预测提升了推荐的性能,但是该模型并未包含信任传播。文献[10]提出SocialMF模型,认为用户的偏好更为接近其社交朋友的平均偏好。而在实际生活中,用户的偏好与其不同的社交朋友的偏好略有不同,为此,文献[11]提出SocialReg模型,该模型是社交正则化模型,通过用户之间的相似度表示社交好友之间的信任强度,该模型有两种正则化:一种是基于平均的正则化,即用户的偏好接近为不同信任强度的社交朋友的加权平均偏好;另一种是基于个人的正则化,即在不同的信任强度下,用户的偏好接近其社交朋友的偏好。显然,后者可以间接传播用户偏好,有利于推荐性能的提升。文献[12]提出的TrustSVD 模型是通过引入隐式社交信息和对社交矩阵的分解来改进SVD++模型。实际中,用户的偏好与社交朋友的偏好会有很大的不同,为此,显式社交网络可能会误导推荐性能。文献[13]提出了CUNE 模型,该模型在评分矩阵上获得与用户有相同偏好的前k个可靠的语义朋友,并采用矩阵分解的方法传播用户偏好。
社交网络的引入,提高了推荐算法的性能,但以上的社交推荐算法并未进行物品相似性的传播[14-15]。在实际中,物品与物品之间有直接或间接的联系,配套的物品往往会发挥一加一大于二的效果,因此融入物品隐性相似性网络对推荐算法具有重要意义。
2 本文ISGCF算法原理
2.1 构建隐性物品相似性网络
2.1.1 构建物品相似性网络
在用户与物品的交互图上,有两个集合,分别是用户集合和物品集合,用户和物品交互的实际意义是用户曾经购买或点击过该物品,即该物品可能被多个用户点击或者购买过,如图1所示。为此可以在物体交互图上构建仅有物品的网络,即将物品作为节点,物品之间的连线表示为物品被共有的用户点击或者购买过,连线的权重为共有用户的个数。如图2 所示的物品相似性网络中,物品1和物品2共同被一个用户b点击或购买,则这两物品之间的权重为1。该物品相似性网络不仅可以表示相邻物品之间的相似性还可以传递间接物品的相似性,即图2中,物品1和物品2相似,物品2和物品4相似,则物品1和物品4间接相似,事实上,物品1和物品4是相连接的,其本身相似。这也符合实际生活,当用户购买了电脑和鼠标,另一用户购买了该鼠标和U 盘,显而易见,电脑和U盘都是使用电脑者所必备的,为此,两者之间有相似性,电脑和U盘的相似性通过用户购买鼠标间接进行传递。

图1 用户物品交互图Fig.1 User item interaction diagram

图2 物品相似性网络Fig.2 Item similarity network
2.1.2 构建物品隐性相似性网络
为了进一步探究物体之间的相似性,在物品相似性网络上需要构建物品隐性相似性网络。在物品相似网络中的某一特定节点上采用随机游走的方法得到特定长度的节点序列,即从前一个物品节点的邻居节点中随机选择一个节点作为下一个物品节点,而在每个节点上通过n次随机游走得到n个节点序列。如图2所示,物体1作为特定节点,当节点序列的长度为4时,其中一种节点序列为1 →2 →4 →3 其采取的随机游走方式受两方面的限制,一方面选择节点之间权重大的节点作为下一个节点;另一方面从未被游走过的节点中选择节点作为下一个节点。将每个节点得到的节点序列输入到SkipGram中,可得到物品相似网络中物品的向量表示,通过余弦相似度计算出物品相似网上与该物体相似程度最大的Top-K个物品,从而得到该物品的隐性相似性网络。
余弦相似度的公式如下:

其中,Qj和Qt分别为SkipGram得到的物品j和t的向量,cos(j,t)为物品j和t相似的程度。
由于通过随机游走的方式得到的物品节点序列相似于文本中的单词序列,因此将节点序列输入到SkipGram中具有合理性。使用该方法得到的物品隐性相似性网络可以更加高效地传递相邻物品的相似性。
2.2 社交正则化模型
社交正则化模型是概率矩阵分解模型在社交网络上的拓展,数学意义为用户的特征向量与其相连用户的特征向量的距离尽可能小,实际的表示含义为用户的偏好与其社交用户的偏好接近,该模型的作用在于可以间接传播用户之间的信任程度。其损失函数为:

公式(2)中,右侧的第一项是预测分数和实际分数的总误差,第二项是用户和物品的正则项,第三项是用户和其邻居用户的正则项,其中Iij为指示函数,指当用户i对物品j有历史交互时为1,否则为0。pi和qj分别表示用户i和物品j的特征向量。rij为用户i对物品j的评分,‖· ‖F为f范数,P∈Rl×m,Q∈Rl×n分别为用户和物品的特征矩阵,l为特征向量的维度,m和n分别为用户和物品的个数,H(i)为用户i直接邻居的集合,f表示用户i的其中一个直接邻居,Sim(i,f)为用户i和用户f的相似程度,其公式如下:

其中,I(i)为用户i购买物品的集合,为用户i对物品的平均评分,j为用户i和用户f共同购买过的物品。
2.3 融合物品相关性和社交网络的图神经网络
最新研究的图神经网络为图结构开辟了新的思路,通过传递和收集领域节点的信息以编码节点的特征信息,既在特征表示中嵌入结构信息,又可捕捉全局信息。本文通过物品的隐性相似性网络、社交网络和用户与物品的交互网络编码用户和物品的结构信息,其公式如下:
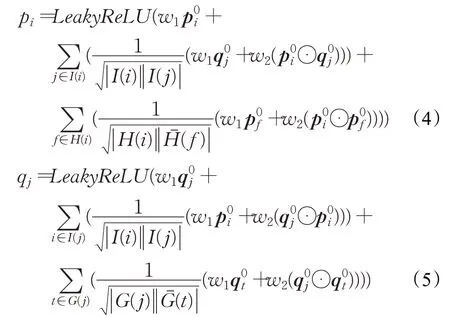
2.4 融合物品相似性传播的社交推荐
以往的算法中,通常引入社交网络来改进社交网络中用户与其直接邻居的正则化项,实现信任传播,并未考虑引入隐性物品相似性网络来实现物品与其相似性物品的相似性传播,即将物品与其相似性物品的距离加以约束。本文提出基于物品相似性传播的社交推荐算法,该算法会对物品的特征向量进行进一步的正则化,以增加算法的精确度,其损失函数为:
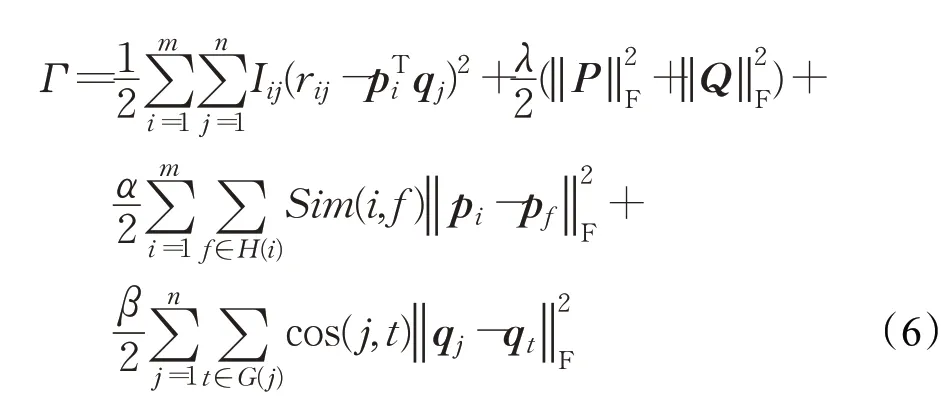
在公式(6)中,用户的偏好会尽可能接近社交网络中相邻用户的偏好,物品的特征也尽可能与隐性物品相似性网络中的物品特征接近,具有很好的现实意义。
若仅考虑隐性物品相似性网络未引入社交网络,可得本文的一种变体算法,其损失函数为:

为有效地学习该模型,本文采用梯度下降法,即分别对向量pi和qj求导:

通过梯度下降法迭代更新用户和物体的特征向量。将用户的特征向量和物品的特征向量内积可得该用户对物品的评分,以达到很好的预测效果。
2.5 ISGCF算法的描述
ISGCF算法描述如下。
输入:社交网络和用户物品交互图。
输出:目标用户对测试物品的预测评分。
步骤1在用户物品交互图上通过随机游走和Skip-Gram方法构建物品隐性相似性网络。
步骤2通过图神经网络的方法学习物品隐性相似性网络、社交网络和用户物品交互图,通过公式(4)(5)得到用户和物品编码的特征向量。
步骤3通过公式(6)(8)(9)迭代更新得到最终的用户和物品的特征向量。
3 实验分析
在3 个公共数据集上验证基于物品相似性传播的社交推荐算法的推荐效果,并采用两个经典的评价指标即均方根误差和平均绝对误差来评价实验结果。
3.1 数据集的描述
为了验证提出算法的有效性,本文在3个公共的数据集上进行实验,即film-trust、Ciao 和Douban。3 个公共数据集都包含了评分矩阵和信任矩阵。作为电影评分数据集,film-trust 的评分在0.5 到4.0 之间,用户之间的社交关系在信任矩阵中,此数据集的用户数目少于电影数目。作为物品评分数据集,Ciao和Douban的评分在1.0 到5.0 之间,Ciao 中用户的数目略多于物品的数目,Douban 中用户的数目远小于物品的数目,而film-trust数据集的评分矩阵稀疏度低于Douban 数据集,高于Ciao数据集。两个数据集的具体统计情况如表1所示。

表1 数据集分析Table 1 Data set analysis
3.2 推荐算法评价指标
本文采用平均绝对误差(MAE)和均方根误差(RMSE)作为推荐算法的评价指标。公式如下:

其中,N为测试集的评分数目,为测试集中用户i对物品j的预测分数,评价指标的值越小,推荐算法的效果越好。
3.3 实验对比与参数
为了有效地评估本文模型的推荐性能,选取了4种经典的社交推荐算法和本文的一个变体推荐算法进行对比。
(1)SoRec:通过共享用户特征矩阵的方式将评分矩阵与社交矩阵联系的一种社交推荐算法模型。
(2)SocialMF:可实现信任传播的一种社交推荐算法。
(3)SocialReg:通过正则化的方式来间接传播偏好的一种社交推荐算法。
(4)NGCF[16]:在用户物品交互图上高阶传播用户和物品信息的推荐算法。
(5)IGCF:本文推荐算法的一种变体,只进行物品相似性传播的推荐算法。
在所有的算法中,用户和物品的特征维数都是10,λ设置为0.001,为了设计方便,α=β=0.01,在film-trust和Douban数据集中,学习率设置为0.01,迭代数为100,在Ciao数据集中,为了避免梯度爆炸,将学习率设置为0.001,迭代数为200。本文中所有的实验结果都采用五折交叉验证的方法,其中80%的数据集作为训练集,20%的数据集作为测试集,将测试结果的均值作为最终的评价结果,其中设置每个物品有30个节点序列,长度为20 个物品节点。在film-trust 和Ciao 数据集中Top-K设置为50,在Douban数据集中Top-K设置为10,随后进一步探讨Top-K对推荐效果的影响。
3.4 实验结果分析
本文设计了3 个实验,在第一个实验中,记录了不同算法下普通用户的评价指标,实验结果如图3所示。

图3 不同算法对普通用户评价指标的比较Fig.3 Comparison of evaluation indexes of different algorithms on ordinary users
由图3 可知,在3 个数据集中,NGCF 效果最差,因为该算法仅在用户物品交互图上进行推荐算法的改良,未进行社会化推荐。SoRec 效果次之,因为SoRec 算法仅共享用户特征向量,并未进行用户之间的信任传播和物品之间的相似性传播。在film-trust 和Ciao 数据集中,本文算法ISGCF 明显优于其他算法,分析原因是本文算法不仅间接传播用户的偏好而且间接传递物品的相似性。在filmtrust数据集中,ISGCF算法略优于IGCF算法,在Ciao 数据集中,算法ISGCF 明显优于算法IGCF,说明引入社交网络会提高推荐算法的准确性。在film-trust 和Ciao 数据集中,算法ISGCF 明显优于算法SocialReg,说明物品隐性相似性网络可有效提高推荐算法的性能。在Douban数据集中,算法IGCF产生最优的推荐性能,但与算法SocialReg相差不大,因为相比前两个数据集,Douban数据集中社交矩阵稀疏度更高,社交网络发挥着更为重要的作用。综合实验结果可知,我们的算法在不同的数据集中均可对普通用户达到最优的推荐结果。
在第二个实验中,探究不同算法对冷启动用户的推荐效果。本实验将对物品的评分数小于等于5 的用户视为冷启动用户,实验结果如图4所示。

图4 不同算法对冷启动用户评价指标的比较Fig.4 Comparison of evaluation indexes of different algorithms on cold start users
由图4 可知,在filmtrust 和Douban 数据集中,算法ISGCF中优于其他算法,其中ISGCF算法明显优于算法SocialReg 和算法IGCF,说明结合社交网络和物品隐性相似性网络会提高冷启动用户的推荐性能。在数据集Ciao 中,算法IGCF 产生最优的推荐性能,算法Social-Reg 的推荐性能次之,算法ISGCF 的推荐效果不优,说明单独使用社交网络和物品隐性相似性网络会提高冷启动用户的推荐性能,同时结合社交网络和物品隐性相似性网络则会产生过拟合使得推荐性能下降。综合实验结果可知,本文的算法在在社交稀疏度较大的filmtrust 和Douban 数据集中实现了最优的推荐性能,在社交稀疏度较小的Ciao数据集中,本文变体算法对冷启动用户实现最优的推荐效果。
在第三个实验中,探究参数Top-K 对实验的影响。在数据集filmtrust 中,Top-K 设置在0 到500 之间,其中每隔50 做一次记录;在数据集Ciao 中,设置在0 到100之间,每隔10 做一次记录;在数据集Douban 中,Top-K设置在0到20之间,并进行记录,如图5所示。
由图5可知,在film-trust数据集中,当Top-K设置在0~50时,性能显著提高,设置为150时,本文算法的两个指标均达到了最优的推荐性能,Top-K超过150时,因为过拟合的产生,两个指标极为缓慢地上升。在Ciao 数据集中,当Top-K 设置为50 时,RMSE 的值最小,超过50 时,该指标上升比较明显,该数据集MAE 指标是在Top-K 设置为20 时最小,超过20 时,该指标显著上升,甚至超过70时,该指标已经超过Top-K为0时的值。在Douban 数据集中,当Top-K 设置为5 时,MAE 的值最小,当Top-K 设置为10 时,RMSE 的值最小。该实验结果表明,Top-K对实验性能有明显的影响。

图5 Top-K对评价指标的影响Fig.5 Impact of Top-K on evaluation indexes
4 结束语
本文融合图神经网络提出了一个传递物品相似性的社会化推荐模型,该模型分别通过物品隐性相似性网络和社交网络对物品和用户的特征进行约束,既能间接传播用户的偏好,又能间接传递物品的相似性。在3个数据集上与当前经典算法进行对比实验,实验结果证明:该模型提高了推荐性能,在一定程度上为冷启动用户提供很好的物品推荐。下一步的工作,将重点利用神经网络来解决物品排序的问题。
