基于网络度量的三分支孪生网络调制识别算法
2021-10-14苟泽中
冯 磊,蒋 磊,许 华,苟泽中
空军工程大学 信息与导航学院,西安 710000
近年来,深度学习技术在图像分类[1]、目标检测[2]和机器翻译[3]等智能任务上取得优异效果。因此,基于深度学习的通信信号调制样式识别也迅速成为国内外的研究热点。文献[4]直接利用卷积神经网络对时域的I、Q两路信号进行特征提取,实验证明了该方法相较于传统调制识别方法具有更高的识别准确率。文献[5]将截获的通信信号进行一定的预处理后,尝试将通信信号时频图作为卷积神经网络的输入,取得了较为理想的识别效果,并且将通信信号调制识别领域与图像识别领域相融合。文献[6]和文献[7]中分别将卷积神经网络和残差网络与循环神经网络中的长短时记忆网络相结合作为语音信号和通信调制信号的特征提取模块,实验表明这种组合模块相较于单一模块提取的通信信号特征具有更强的表征能力。然而这些基于深度学习的调制识别方法在训练过程中需要依赖大量的训练样本,否则会使网络发生严重的过拟合问题。在通信对抗领域获取通信信号样本“代价”太大,上述的深度学习方法难以得到广泛应用,而小样本学习可以在小样本训练集中使得特征提取网络收敛。
现阶段用于解决小样本问题的方案主要包括:数据增强、元学习和度量学习。数据增强技术[8-9]从特征和属性层面实现对训练样本的扩充,在一定程度上可以缓解过拟合问题。但是由于小样本数据空间过小、变换模式有限以及生成的训练样本相似于原始训练样本,使得数据增强技术无法完全解决过拟合问题。元学习技术[10-12]通过学习器学习跨任务领域的梯度更新策略与初始化条件以实现在小样本训练过程中实现快速收敛。通过添加循环神经网络(Recurrent Neural Network,RNN)搭建的外部存储器[11]记忆学习过程,并将其迁移至小样本训练过程中以实现在小样本新任务中的快速学习。这些元学习方法均取得较为优异的识别分类效果,但是基于RNN结构的外部存储器单元会使得算法复杂度增大,训练效率低下。度量学习方法的思想是学习一个特征嵌入空间,在特征嵌入空间中根据样本类别进行度量,并利用最近邻分类器进行分类识别。常用方法包括原型网络[13]、孪生网络[14]以及关系网络[15]等。原型网络认为每个类均存在一个类原型,数据集均匀分布在类原型的周围,通过学习类原型的表达并基于类原型通过最近邻分类器即可准确进行分类识别。但是原型网络没有考虑到类内样本存在偏差时会导致类原型学习不准确进而导致分类偏差。孪生网络通过使用权值共享、完全对称的特征提取网络学习训练集的特征嵌入空间,通过距离度量寻找最近邻分类作为测试集的分类结果。实验表明孪生网络在小样本训练集中识别效果较为理想,但是当训练集中存在相似类别时会出现相似类别分类混淆的问题。
鉴于此,本文在度量学习的基础上提出一种基于网络度量的三分支孪生网络调制识别算法,可有效缓解孪生网络在相似类别上识别混淆问题。同时为进一步提升算法的识别性能,使用网络度量代替固定度量函数,降低对特征提取模块提取特征的深度依赖;使用局部异常因子检测算法(Local Outlier Factor,LOF)[16]剔除训练样本中偏差数据,有效解决通信调制信号在接收过程中受到信道噪声和接收机噪声的影响,确保类原型生成更加准确。在公开的调制数据集DeepSig[17]上进行仿真,结果表明,本文算法可以有效降低训练特征提取网络所需样本量,并且相较于固定的距离度量方法具有更高的识别准确率。
1 TSN-RN-LOF算法模型
1.1 算法框架
本文算法具体实现分为训练过程与测试过程,总体框架是在三分支孪生网络的基础上级联一个非线性度量学习的关系网络。在训练过程中通过联合损失函数约束进行训练,算法训练框架如图1所示。
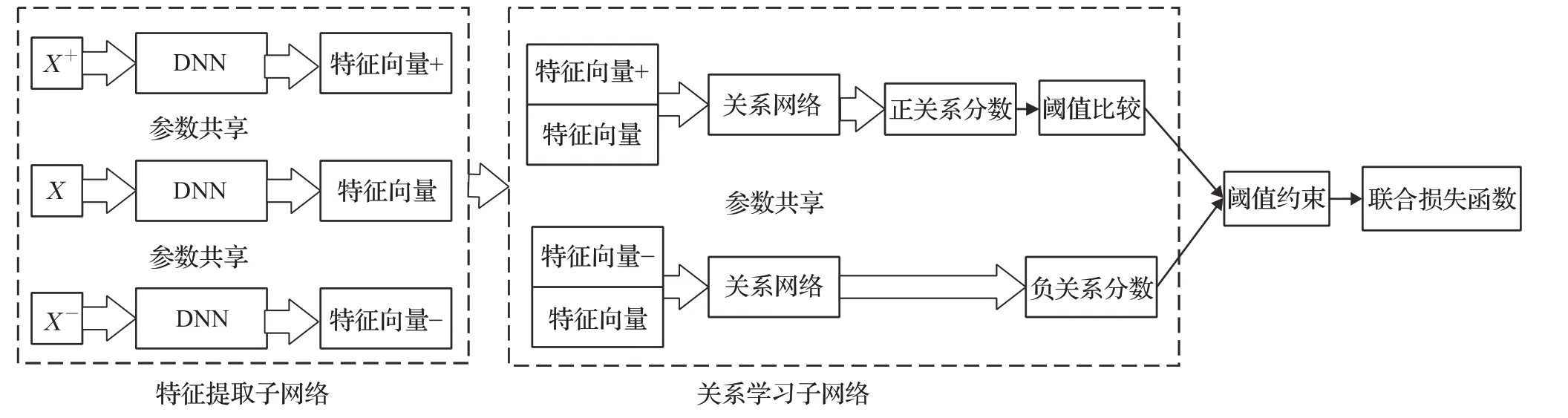
图1 算法训练框架图Fig.1 Algorithm training frame diagram
其中,特征提取子网络中采用三个参数共享的残差网络模块组成,提取最后一层输出作为输入样本的特征表达;然后将正样本对与负样本对作为共享权值参数的关系网络的输入,以学习一个用于分类的非线性度量函数;通过阈值约束解决三元约束组组合后训练量指数级增加而引起训练时间长的问题;最后通过联合损失函数约束整个网络的训练。
为降低算法的运算量和提升测试精度,在测试过程中通过原始标签生成每个调制样式的均值类原型表达作为关系子网络的输入,考虑到通信调制信号由于信噪比和接收机的误差而引起的偏差,采用LOF算法剔除偏差较大的数据。算法测试框架如图2所示。
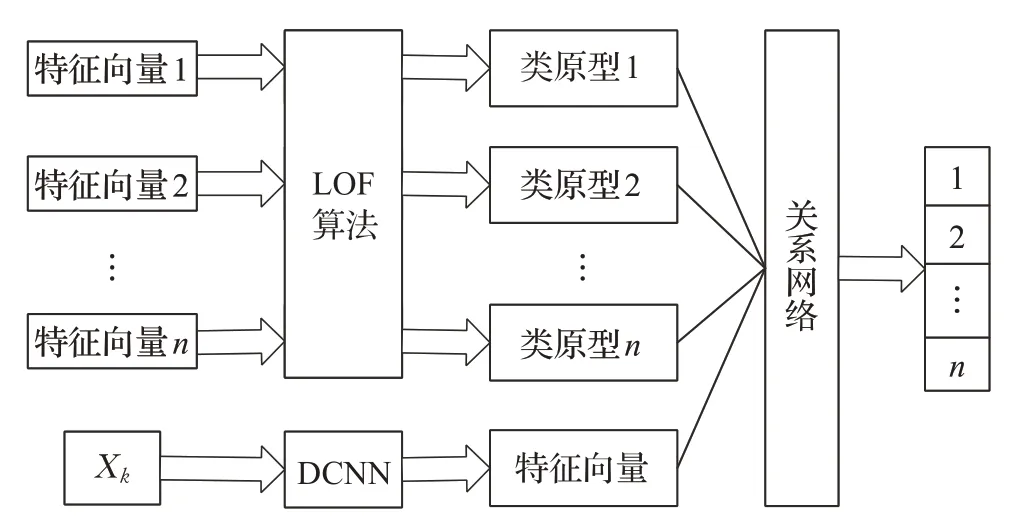
图2 算法测试框架图Fig.2 Algorithm testing frame diagram
1.1.1 特征提取子网络
现有的度量学习方法的特征提取模块设置相对较为简单,多为卷积层简单堆叠而成,导致提取到的特征不够完善。而且为避免在小样本条件下训练网络由于训练参数过大出现过拟合问题,CNN 结构设置也不宜过深。进而导致常规度量学习提取的特征无法较为准确的表达原始训练样本。本文借鉴残差网络的设计原理[18],使用改进型残差网络作为特征提取网络基础网络,利用多个小卷积核连续卷积代替大卷积核,有效减少网络的训练参数。同时还考虑到通信信号的I、Q 序列在网络中同时具有图像的空间特性和信号的时序特性,本文还在改进型残差网络后级联长短时记忆网络,以提取其时序特征。改进型残差块结构和整个特征提取模块结构如图3 所示,图(a)为改进型n级残差块结构,图(b)为特征提取模块结构图。

图3 特征提取模块结构图Fig.3 Feature extraction module structure diagram
残差网络先进的思想在于对卷积层实现跳层连接技术,可有效缓解网络深度加深在训练过程中出现的梯度消散和梯度爆炸问题。具体实现是通过在标准卷积结构上增加一个恒等映射,即

其中x表示模块的输入,y是模块的输出,F(x)=y-x即为网络训练需要学习的映射。当网络训练最优解时残差映射F(x)直接置零,输出和输入一致,不会改变网络参数。
而使用小卷积核级联代替大卷积核的操作,可以使得在不改变感受野的情况下有效减少网络参数,同时还将使用更多的激活函数,使得神经网络学习到更具判别性的映射函数。
1.1.2 关系学习子网络
如图4 所示,本文关系网络gφ由两个卷积模块和两个全连接层模块组成。其中每个卷积模块由64 个1×3 的卷积核构成的卷积层和1 个1×2 的最大池化层组成,并使用ReLU函数作为激活函数。两个全连接层分别使用ReLU 函数与Sigmoid 函数作为激活函数,使其归一化至(0,1)区间中。
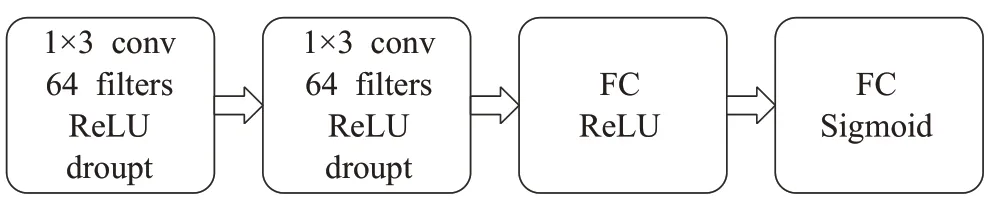
图4 关系网络模块结构图Fig.4 Relational network module structure diagram
为利于关系网络的输入,引入算子τ作为特征提取子网络输出特征向量的融合并接,得到三元组的特征表示为:

将深度特征融合后的正负样本对特征组输入至两个参数共享的关系网络中,得到两个(0,1)之间的关系值作为正负样本对之间的相似度得分。最终正负样本对相似关系得分表示为:

其中,R为正负样本对的相似度得分,gφ(·)为关系网络,φ为关系网络的参数。
1.1.3 LOF算法
在模型完成训练后,从特征提取子网络后端提取出每个类各样本的特征映射为使在各类别生成的类原型中更加准确,本文使用LOF算法检测并剔除掉样本数据中偏差较大的训练数据。针对每个样本的特征表达,寻找距离其最近的k个样本点,并记低K个最近样本点为其的k-近邻距离,表示为而对于该样本点的第k距离邻域为该样本点中第k距离以内的所有点,记为样本点到之间的可达距离为样本点的K近邻距离和两点之间距离的最大值,记为
为衡量样本点的异常程度,基于局部可达距离定义局部可达密度为:
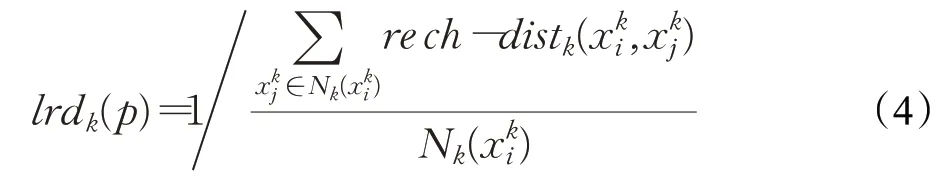
为进一步衡量样本点的异常程度,通过比较其与周围近邻样本点之间的相对密度。定义样本点的近邻样本点的平均局部可达密度与样本点的局部可达密度比值为局部异常因子,表达式为:
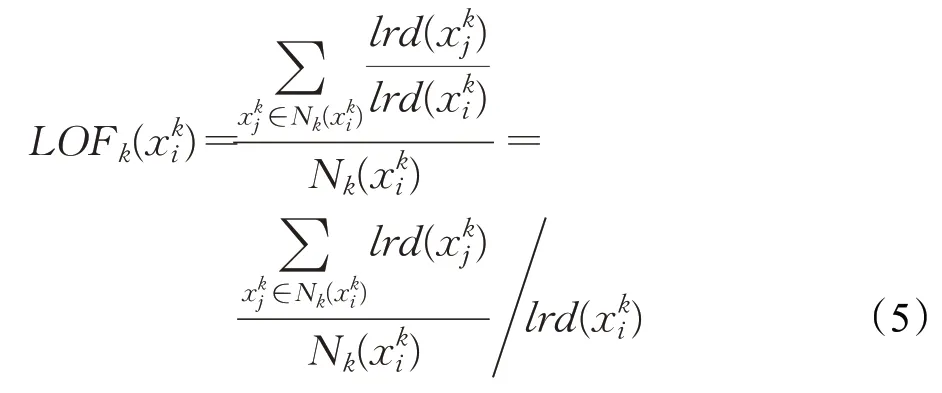
1.2 联合损失函数
针对算法的三元输入特性,本文选择可以学习三元输入样本间的区分信息的铰链损失函数。该损失函数通过对正负样本对的输出相似关系值进行约束使得算法模型可以学习到更具辨识度的特征表达。具体而言,针对关系网络后端输出正负样本对相似关系得分进行约束,得到铰链损失函数为:

式中m为阈值,该约束使得正样本对之间的相似度关系得分需大于负样本对之间的关系相似度得分。
为使三元组的训练过程更加高效,Hermans 等人[19]在行人重识别算法中提出一种三元组的挑选方法,称为“batch hard”。具体来说就是在每个训练批次中,随机选取P个类别,每个类别选取K个训练样本组成PK个训练数据。对于每个参考样本从相同类别中选取最为不相似的样本作为正样本,从不同类别中选取最为相似的作为负样本,选出PK个三元训练样本组。因此上式中损失函数变换为:
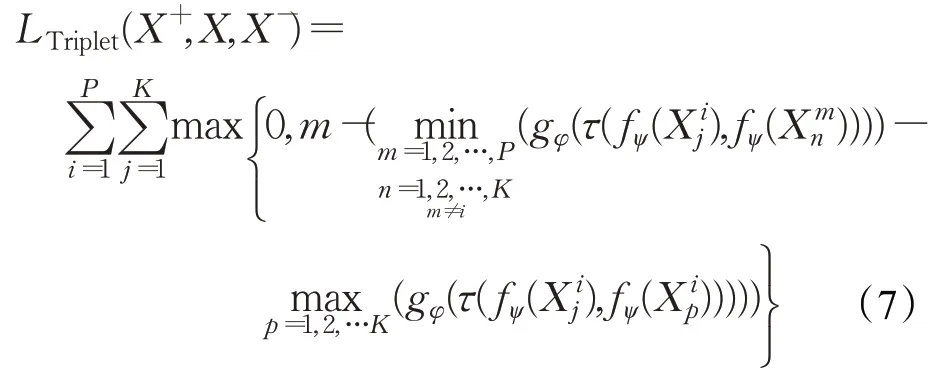
但是,基于“batch hard”的挑选方法没有考虑到类内样本相似得分远低于类间样本相似得分时会造成网络收敛慢的问题。而通信调制信号类内样本数据由于信道误差等情况会出现偏差过大的问题。因此,本文采取阈值约束解决此问题,通过对类内样本相似度设置阈值,在训练过程中剔除掉偏差较大的正样本训练数据。最终损失函数定义为:

其中α为正样本对相似度关系值约束阈值。
1.3 算法实现过程
本文算法实现过程分为训练过程和测试过程,具体步骤如下:
1.训练过程
1.1.训练样本的特征映射
将输入的训练样本三元组通过三个权值参数共享的特征提取网络中,提取最后一层LSTM 的输出作为样本的特征映射,记为fψ(X+)、fψ(X)、fψ(X-)。
1.2.正负样本对特征融合
通过算子τ将正负样本特征与参考样本特征融合,得到正负样本对的特征融合表示为(τ(fψ(X),fψ(X+)))、(τ(fψ(X),fψ(X-)))。其中算子τ表示为特征的级联。
1.3.正负样本对相似度计算
将特征融合后的正负样本对输入至参数共享的关系网络中,计算正负样本对的相似度关系分值分别为gφ(τ(fψ(X),fψ(X+)))、gφ(τ(fψ(X),fψ(X-)))。
1.4.网络训练与参数更新
通过设置阈值选取合适的三元组样本输入,然后利用正负样本对的相似度关系计算出损失函数,通过损失函数对模型的训练进行约束。
2.测试过程
2.1.各个类别的类原型表达
首先从训练好的特征提取子网络后端提取每个类别的特征表达,通过LOF算法剔除偏差较大的样本数据,然后确定每个类别的特征中心作为该类的类原型。
2.2.测试样本的类别确定
将测试样本与每个类原型输入至关系网络中,选取相似度最大的类别作为测试样本的类别识别。
2 算法性能仿真与分析
2.1 数据集与仿真环境
实验中数据集采用DeepSig 的调制识别公开数据集,将数据集中的8PSK、AM-DSB、AM-SSB、BPSK、CPFSK、GFSK、PAM4、QAM16、QAM64、QPSK、WBFM 11种调制方式,在-4 dB、18 dB信噪比的条件下,对每个调制样式分别取240、360、480、600、720、840、1 200、1 800的训练样本数量和100的测试样本数量。
实验硬件平台基于Windows7,32 GB 内存,NVDIA P4000显卡的计算机。通过python中的Keras开源人工神经网络库完成网络的搭建、训练与测试的。
2.2 实验参数设置
在模型优化过程中选取Adam优化算法,相较于随机梯度下降算法,其具有更快的收敛速度和更高的算法稳定性。实验中使用优化算法默认超参数设置,并设置初始学习率为10-3和最小学习率为10-5,当验证损失值增加10%以上,学习率降低一半,选取验证损失最低模型作为最终训练模型。
针对实验过程每批次三元组训练集的构造,每个类别随机挑选与类别总数相同的11 个训练样本组成121个三元组训练集。而对于实验过程中其他参数设置则采用对比实验,挑选算法达到最优时个参数设置,其中联合损失函数阈值约束设置为0.9,LOF 算法选取11 近邻距离进行计算,正样本对相似度约束设置为0.5。
同时在训练过程中为避免出现过拟合的问题,本文还采用提前终止迭代算法(Early Stop Iteration,ESI)[20]使模型收敛至验证集损失值最低点。
2.3 算法性能分析
2.3.1 三元组约束对算法性能提升
为验证三分支孪生网络作为特征提取子网络对小样本调制识别的性能影响,通过设置具有相同特征提取模块的孪生网络(Siamese Network,SN)作为基准方法进行多方面的对比实验。首先对比二者训练过程中在相同训练样本数量上的平均识别精度,得到实验结果如表1所示。
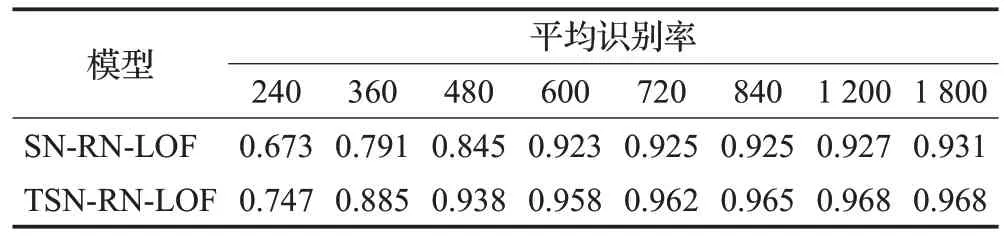
表1 不同特征提取模块对训练样本量需求Table 1 Sample size requirements of different feature extraction modules
由表中结果,选取两种模型结构均已达到理想识别精度时所需的训练样本量720,对比两种模型结构在不同信噪比条件下的平均识别率如图5 所示;而图6(a)、(b)分别显示两模型结构在信噪比为0时的混淆矩阵。

图5 不同模型的识别性能对比Fig.5 Comparison of recognition performance of different models

图6 两算法模型在信噪比为0时混淆矩阵Fig.6 Obfuscation matrix comparison of two algorithm models at SNR=0
由图5、6可以看出,孪生三分支网络作为特征提取网络时具有更优的识别效果,主要优势体现在对于相似调制类别WBFM 和AM-DSB 之间识别准确率的提升。主要原因在于孪生三分支网络相较于二分支孪生网络添加了对比约束分支结构,可以在同一批次的训练过程中对正负样本对同时进行约束,学习更具细粒度差异的类间信息差异,提取更具区分度的样本特征。
2.3.2 度量函数对识别性能的影响
为验证度量函数的选取对算法性能的影响,使用常用距离度量函数欧式距离度量函数与余弦相似度作为实验基准方法,在本文算法的整体框架下替换后续关系网络的非线性度量结构,实验结果如表2所示。
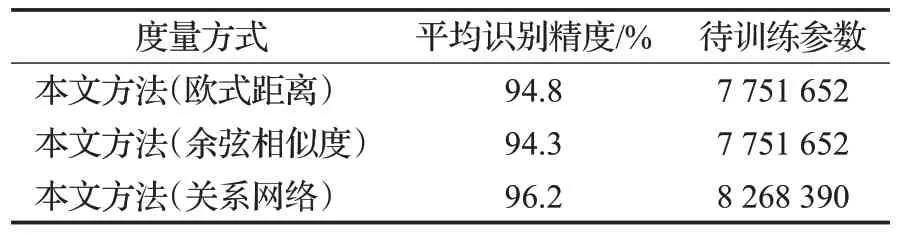
表2 不同度量方式的识别性能对比Table 2 Performance comparison between different measures
实验结果表明,在本文算法框架下相较于固定欧式距离度量和余弦相似度度量函数,采用网络进行相似度度量识别性能分别提升了1.4和1.9个百分点,但是算法的复杂度也相应有所增加。主要原因在于通过神经网络进行相似度度量,度量网络可以和特征提取网络联合训练,所提取的样本特征同时满足度量网络的约束,网络结构也更加复杂;而固定的度量函数仅仅是对提取的正负样本对特征进行简单的距离度量,识别性能过于依赖特征提取模块所提取的特征。
2.3.3 LOF算法对识别性能的提升
本节针对LOF算法对识别性能进行分析,与直接均值类原型表达的TSN-RN-AVG模型进行对比实验。实验结果如表3所示。

表3 LOF算法的识别效果Table 3 Recognition effect of LOF algorithm
由表3可以得出,使用LOF算法剔除偏差的样本数据后生成的类原型表达,相较于直接均值生成的类原型表达更加准确、识别精度更高。虽然在本文实验中识别精度提升有限,但是主要原因在于实验中的调制识别数据集是在实验室环境中采集的,环境噪声与接收机噪声相对于实际的环境中较低、偏差数据较少,对实验影响有限。但是,基于LOF算法剔除偏差样本对于实际电磁环境中的通信数据的识别有较大的实用性与性能提升。
2.3.4 不同小样本模型对比分析
为验证本文所提算法模型的性能,选取现阶段较为流行的基于度量学习的小样本识别模型Prototypical network[13]、Siamese network[14]、Relation network[15]作 为基准方法进行对比实验,由于上述算法模型结构均运用在图像识别领域,其构建的特征提取模块不适用于通信信号的调制识别,因此在实验过程中将本文特征提取模块替代原文算法中的特征提取网络结构。同时为保证所有算法均可以有效收敛,选取单类样本数量为840进行实验,对比实验结果如表4所示。
由表4可知,本文所提算法模型在识别性能上相较于目前主流的基于度量学习的小样本识别模型均有较大的提升,但是算法的复杂度也相应有所增加,主要原因在于本文算法使用了三分支孪生网络结构作为特征提取模块,极大提升了相似样本的识别准确率,但是在训练过程中针对每批次训练样本均需挑选适合网络训练的三元组样本对,耗费时间资源。同时,使用神经网络对正负样本对相似度进行度量在提升了算法识别性能的同时增加了网络参数,使得算法复杂度增加。
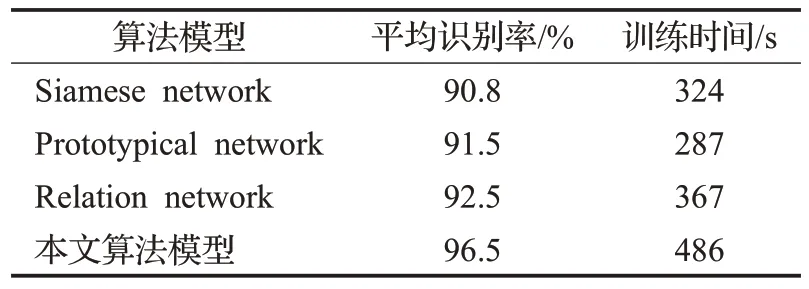
表4 不同小样本算法模型的对比Table 4 Comparison of different small sample algorithm models
3 结束语
本文针对孪生网络在小样本调制识别中相似类别混淆问题,提出一种基于网络度量的三分支孪生网络调制识别算法。该算法特征提取模块充分利用类内与类间对比差异信息和通信信号的特性,学习到更深层和更具区分度的特征,同时为避免固定度量函数对算法性能的影响,采用神经网络训练一个非线性度量函数,使得提取的特征更好的契合度量函数。最后考虑到通信信号易受干扰的特性,使用了LOF算法剔除偏差较大的训练样本,使得在测试过程中生成的类原型更加准确,提升了算法性能。计算机仿真结果也验证了本文所提算法在小样本调制识别中的可行性和有效性。
