基于LSTM-BLS的突发气象灾害事件中公众情感倾向分析
2021-10-14罗嘉王乐豪涂姗姗宋鸽韩莹
罗嘉 王乐豪 涂姗姗 宋鸽 韩莹
0 引言
我国作为气象灾害[1-2]发生频率较高的国家之一,各种极端天气的频繁发生,给人们带来了严重的经济损失,甚至会诱发灾难造成人员伤亡.气象灾害的发生不仅是对国家应急治理体制的重大考验,影响人们的日常生活,还会在网络上引起社会舆论的爆发[3],使人产生负面焦虑的情绪[4].对于灾害引起的舆论[5],若不加以干预引导,容易在网络上演变成新的突发事件,加剧危机事件本身的负面影响.
网络用户数量在近几年呈几何趋势增长,大大提升了舆论的产生和传播速度,网络舆论本身带有的情感指向性和其内在包含的应用价值也逐渐成为专家们关注的热点.传统的机器学习算法诸如支持向量机(Support Vector Machines,SVM)[6]、K-means算法[7]等方法已被提出用于英语和汉语的情感极性分析,且取得了很大的进展.但是面对大量数据时,传统算法的训练力不从心.深度学习的发展减轻了机器学习模型手动提取特征的负担.长短期记忆网络(Long Short-Term Memory,LSTM)[8]具有长时记忆功能并且实现起来简单的优势,解决了训练过程中存在的梯度消失和梯度爆炸的问题.文献[9]将LSTM模型与SVM模型在相同数据集上进行对比,在情感分类方面LSTM模型的准确率远高于基线模型.舆情文本分析[10-11]是通过度量向量空间中单词向量之间的关系进行的,因此单词嵌入的质量直接影响到分类结果.虽然LSTM能够从训练数据中挖掘出更抽象的特征,使其具有很好的泛化能力,但它的拟合能力并不理想,而且LSTM提取特征时存在语义不完整、精度不高等问题.
研究者通过引入卷积神经网络(Convolutional Neural Networks,CNN)来弥补上述缺陷,CNN-LSTM模型[12]的提出使得处理高维数据更加轻松、精度更高.自然语言包含结合词和短语的句法特性使得底层模型不满足应用需求.短文包含的上下文信息往往有限,对其进行情感分类具有一定的挑战性.文献[13]将10层CNN和10层LSTM结合起来,使用不同的超参数和不同的预训练策略训练,其产生的模型比单独使用模型的历史最高精度更胜一筹.许杰等[14]考虑到CNN并行计算能力强的优点而将其作为特征提取器,提取到的高层次特征输入到LSTM中得到最终结果.较之以往模型,该模型能够在提取局部特征的同时获取句子的时态语义,提高了情感文本分类的精度.但CNN-LSTM模型存在性能过度依赖于标记数据的数量和质量,且未考虑到单词之间的句法依存的问题,情感文本分类的精度仍有提升的空间.
注意到宽度学习(Broad Learning System,BLS)作为一种简单的新型快速增量学习神经网络[15],是基于随机向量函数连接网络RVFL(Random Vector Functional Link Network),将原始的输入先通过特征节点学习稀疏的映射特征,然后经由增强节点非线性扩展得到增强特征,并联两种特征表达作为最后的总输入送到输出层进行分类识别,由此可以从训练数据中学习到重要的特征,对训练数据达到高度拟合.
本文爬取了2020年末断崖式降温舆情文本并对其进行数据预处理之后,发现文本中大多是短句文本,其包含的上下文信息有限,因此底层模型不满足应用需求.将数据集使用LSTM模型进行训练,得到的实验结果在拟合度方面没有达到预期的效果,精确度不高.
考虑到深度学习模型能够从训练数据中挖掘出更抽象的特征,这使得它具有很好的泛化能力,而BLS具有能够从训练数据中学习到重要的特征,对训练数据达到高度拟合的特点,因此使用LSTM作为本文模型的特征提取层,将文本进行初步分类,再将初步分类的文本输入到BLS层中进一步提取重要特征,最终获取高精度分类结果.本文提出的LSTM-BLS模型,将不同级别的特征层信息进行融合使用,既有低级纹理信息又有高级语义信息,弥补了LSTM、CNN-LSTM模型在舆情文本分析方面提取特征时存在语义不完整、精度不高和未考虑到单词之间的句法依存等问题.实验结果表明,本文提出的模型较之于K-means、SVM模型精度分别提高了17.23和13.46个百分点,与LSTM与CNN-LSTM模型相比精度分别提高了7.13和4.17个百分点.文中模型在经过数据集测试后取得良好的效果,并且不依赖特定领域的自然语言库,也可以应用在其他中文文本分析验证上,具有广泛的适用性.
1 模型
1.1 LSTM
LSTM的核心概念在于细胞状态以及“门”结构.
图1展示了LSTM的基本架构,其包含的三个门:输入门、遗忘门和输出门.通过三个门的函数和细胞状态,LSTM可以捕获短期和长期时间序列中的复杂相关性.其中,xt是输入向量,it是时间步长t中的输入状态,ft是时间步长t中的遗忘状态,ot是时间步长t中的输出状态,ht(ht-1)是时间步长t(t-1)中的隐藏状态,ct(ct-1)是时间步长t(t-1)中的单元状态.以tanh和sigmoid激活函数σ的形式在三个门的顶部添加非线性.
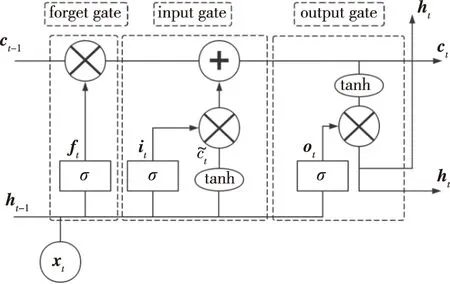
图1 LSTM的基本架构Fig.1 Basic architecture of LSTM
LSTM的数学原理在式(1)—(6)中给出:
ft=σ(Wxfxt+Whfht-1+bf),
(1)
it=σ(Wxixt+Whiht-1+bi),
(2)
ot=σ(Wxoxt+Whoht-1+bo),
(3)
(4)
(5)
ht=ot⊗tanh(ct),
(6)
其中,Wxf,Whf,Wxi,Whi,Wxo,Who,Wxc,Whc代表了输入向量与输入门、输出门、记忆单元之间对应的权向量,bf,bi,bo,bc是偏置变量,⊗是矩阵的Hadamard积.
1.2 BLS
BLS网络结构如图2所示.

图2 BLS网络结构Fig.2 Network structure of BLS
假设输入数据集X包含N个样本,每个样本有M个维度,Y是属于RN×C的输出矩阵.对于n个特征通过式(7)映射后生成k个节点:
Zi=φ(XWei+βei),i=1,…,n.
(7)
将所有特征节点表示为Zn≡[Z1,…,Zn],第m组增强节点表示为
Hm≡ξ(ZnWhj+βhj),j=1,…,m,
(8)
其中Wei,Whj和βei,βhj分别是随机生成的连接权重和偏置值.
因此,BLS模型可以表示为
Y=[Z1,…,Zn|ξ(ZnWh1+βh1),…,ξ(ZnWhm+βhm)]Wm=
[Z1,…,Zn|H1,…,Hm]Wm=
[Zn|Hm]Wm.
(9)
1.3 LSTM-BLS舆情文本情感分类模块
针对舆情文本的歧义性或多义性的问题,考虑到深度学习能够对每个分量进行数据特征识别与特征提取,从而实现分量的单步向前预测,达到获取最终分类的效果的特点,本文在上述基础模型上通过融合BLS提出了一种新的的文本情感分析模型.该模型整体结构如图3所示.
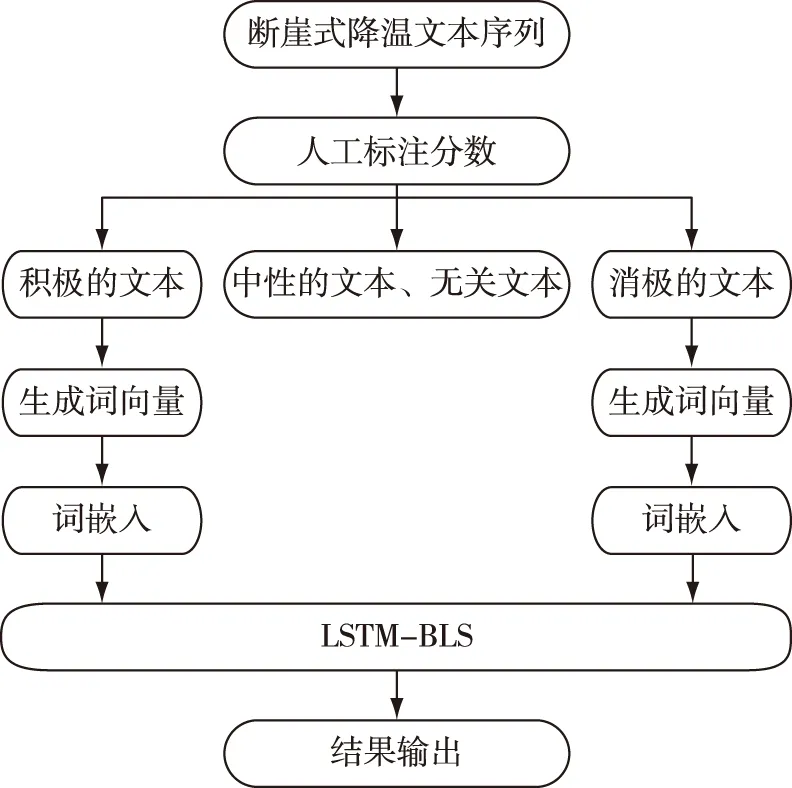
图3 LSTM-BLS的文本情感分析流程Fig.3 Flow chart of text sentiment analysis based on LSTM-BLS
LSTM-BLS模型(图4)的主体是3个拼接的LSTM层、2个全连接层(Dense)和1个BLS模型通道,3层LSTM通道主要用来提取句子特征,而加入的BLS层可以和别的机器学习算法灵活地结合,即利用LSTM提取到的特征来训练.并且,其加入的增量学习算法,允许在网络结构中加入新的节点时,以很小的计算开销来更新网络权重.

图4 LSTM-BLS模型Fig.4 LSTM-BLS public opinion analysis model
1)第1层是输入层(input layer),将爬取到的文本进行人工数据集标注后生成的文本导入程序.
2)第2层是嵌入层(embedding layer),作用是把输入的每个词语映射成一个向量表示.
3)第3~5层是LSTM层,主要是为了提取句子的特征.本文词向量维度选取300维,选择的过滤器分别为256、128、64个,训练次数(epochs)=50,并在LSTM的每一层都加入了dropout机制,该机制可以在训练过程中通过让部分神经元停止工作,而达到防止过拟合的效果.
4)第6层是Dense层,将LSTM层输出端融合的特征作为全连接层的输入,应用Sigmoid激活函数后的值是介于0到1之间的浮点数,表示概率或者置信度,并加入L2正则化,防止过拟合.
5)第7层为BLS层,利用前面提取到的特征进行计算,调用Softmax进行分类,其中每个映射特征点的个数N1=10、映射特征个数N2=30、增强节点个数N3=280以及正则化参数C=0.000 1.
2 实证分析
2.1 数据来源
本文主要以2020年末两次断崖式降温舆情数据为例.2020年12月28—30日我国中东部大部地区迎来大风降温天气,局部地区遭遇了16 ℃以上的断崖式降温.中央气象台迅速发布了最高级别的寒潮橙色预警.此次寒潮影响范围广,以及其伴随而来的剧烈降温、长时间持续性大风,给各行各业,甚至人们日常的穿衣出行都带来了极大的影响,并迅速在网络上掀起了舆论风暴.本文基于Python的Scrapy模块,爬取微博大V及相关媒体共计37 852条数据,包括发表评论的用户名称、评论内容、发表时间、转发量、点赞量等多极化数据信息.
在对文本进行训练前,先对爬取到的信息进行了一系列的数据清洗工作,包括繁体字简化、删除垃圾广告、无效评论等,最终得到32 358条有效数据.预处理包括以下内容:
1) 去除含HTML标签的内容;
2) 删除纯标点评论;
3) 去除表情评论;
4) 单词词形还原;
5) 删除停用词.
2.2 超参数设置
社交网络的快速发展使得媒体信息在社交平台的传播更加迅速.灾害相关信息会在事件发生短期内迅速传播发酵,在网络上引起舆论风波.舆情结果往往会形成两极分化,积极的舆论引导事件朝好的方向发展,而消极的舆论将会在网络上引发二次灾害.因此,舆情文本分析的准确性,大大影响着舆情引导的走向.有鉴于此,本文将数据集分为两个类别:积极的、消极的.
将分类结果生成词云可以直观地反映正面和负面评论中出现频率最高的词语,可以看到图5、6中,部分词汇可以清楚地反映用户的积极和消极情绪.然而,网络评论中时常包含褒义贬用以及贬义褒用的词汇,此类词汇经常包含在具有完全相反含义的评论中.因此,仅仅根据是否出现代表积极或者消极情绪的词语而对评论进行简单的分类已经达不到预想的结果时,便需要深度学习技术来分析词语之间的关系,获取语义从而进行分类.

图5 积极的词汇Fig.5 Examples of positive word

图6 消极的词汇Fig.6 Examples of negative word
本文使用人工标注的微博语料数据集正向和负向评论各14 000条,从中挑取正负向评论各8 000条作为训练集,剩下的作为测试集进行测试.实验需要通过词袋模型将语料库更改词向量,之后将训练好的词向量输入到搭建好的神经网络中.
在本文搭建的舆情文本分析模型中,输入的词向量的效果很大程度上影响着最终训练结果,多次实验结果表明,将词向量进行预训练可以有效地提高模型的准确率.经过不断调试模型参数,本文最终采用词向量维度为300.数据训练前,利用Jieba分词工具将原文本进行分词、去除停用词后,将得到的词语转换为词向量并进行预训练,得到的结果将作为本文模型的输入.
为了得到更加丰富的情感特征信息,本文在LSTM-BLS模型上进行了一系列实验.为了防止过拟合现象,本文使用了dropout机制和L2正则化.详细超参数设置如表1所示.

表1 模型超参数设置
2.3 结果讨论
为了验证本文提出的模型的有效性,本文使用准确率(A)、召回率(R)、F1值(F1)作为评估指标.
准确率计算公式:
(10)
召回率计算公式:
(11)
F1值计算公式:
(12)
其中:ηTP为正确的匹配数目;ηFP为匹配不正确的数目;ηFN为没有找到正确匹配的数目;ηTN为正确的非匹配数目.
将本文使用的LSTM-BLS模型分别与另外的4种模型方法在准确率上进行实验对比:
1) K-means.K-means算法是无监督的聚类算法,因其实现简单、聚类效果好,被广泛应用.本文设置算法模型最大迭代次数为300,k值为2,容忍度为0.000 1.
2) SVM.SVM是机器学习中最好的现成的分类器,可以不加修改直接使用,并且能够得到较低的错误率.本次试验将句子中的单词转换为词向量,再将这些向量进行加权平均作为模型的输入进行分类.
3)LSTM.本文使用的是三层LSTM的单通道模型,将词向量作为输入,最后通过全连接层和Softmax层输出分类结果.
4)CNN-LSTM.该模型由CNN和LSTM组合而成,在上述LSTM模型的基础上,使用CNN提取特征,作为LSTM模型的输入.
5)LSTM-BLS.本文提出的模型,是在上述三层LSTM的基础上拼接了BLS层.将爬取到的微博评论经过预处理,分词后经过词嵌入生成词向量,作为本文模型的输入得到最终准确率结果.
实验结果对比如表2、3所示.

表2 基线模型在断崖式降温数据集上的性能对比
由表2和表3可知,在断崖式降温数据集上,LSTM-BLS模型的网络舆情分析准确率相比基础的机器学习模型K-means和SVM,分别提高了17.23和13.46个百分点,比LSTM模型提高7.13个百分点,比CNN-LSTM复合模型提高4.17个百分点.准确率和召回率在实践中会出现矛盾的情况,而F1值作为准确率和召回率的调和平均值,往往成为实验最有效的综合评价指标.由表2、3可知,本文提出的新模型在综合评价方面表现最优,效果最好.综上,LSTM-BLS模型在文本情感分析方面具有良好的性能,可以更加准确地对舆情文本进行正负向情感分类,弥补了现有的机器学习模型面对大量数据集时训练吃力的缺陷,解决了深度学习模型拟合能力欠佳、精度不高的问题.
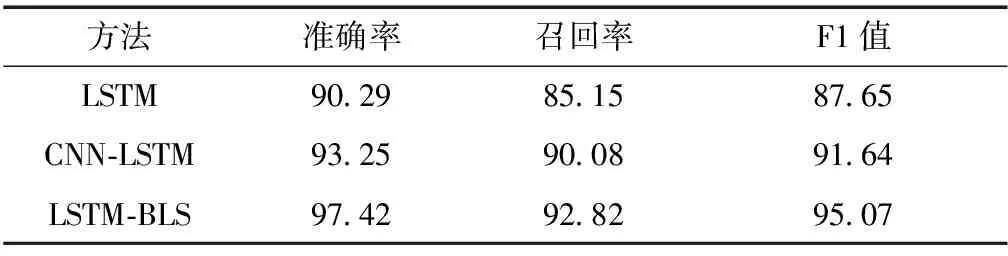
表3 本文模型和其他深度学习模型在断崖式降温数据集上的性能对比
3 结论
气象舆情分析的主要任务是为了更加精准地掌握网络舆情动态,避免灾害事件在网络舆情方面形成二次灾害.本文提出的LSTM-BLS算法模型一方面考虑到单词之间的句法依存问题,另一方面在此次舆情文本分析经过爬取到的数据集验证测试后,准确率、F1值均超过K-means、SVM、LSTM和CNN-LSTM模型,在短文本情感分类方面效果优异,经公开数据集验证也同样具有适用性.将宽度学习与深度学习相结合,对纷繁复杂的网络舆情文本进行准确的分类,对短文本数据信息的有效分析和挖掘,提高了对网络舆论的监管能力,有利于开展后续引导工作.
