基于InVEST 模型的北京市延庆区生态系统服务功能评价研究数据集
2021-10-13李敏刘婷婷樊景超孙伟曹珊珊满芮高飞
李敏,刘婷婷,3*,樊景超,3,孙伟,3,曹珊珊,3,满芮,3*,高飞
1.中国农业科学院农业信息研究所,北京 100081
2.农业农村部农业大数据重点实验室,北京 100081
3.国家农业科学数据中心,北京 100081
4.中国农业科学院作物科学研究所,北京 100081
引 言
生态系统是人类生存发展的自然环境和必然条件,其健康与否在自然资源开发过度、生境水平退化严重的当下显得至关重要。国内外学者将人类从生态系统中获得的效益定义为生态系统服务功能,主要包括供给功能、调节功能、文化功能以及支持功能等[1]。对生态系统服务功能的客观监测与评价是生态环境科学管理与实现可持续发展的先决条件,也是近年来生态与环境科学的研究重点。
延庆作为北京生态涵养的重要承载主体,在固碳增汇、涵养水源、土壤保育等方面发挥着举足轻重的作用。为科学评估延庆区生态系统服务功能,本研究采用InVEST 模型,以土地利用/覆被数据为基础,对2004 年、2009 年、2014 年延庆区碳储存、水源供给、土壤保持这三大关键生态系统服务功能的数量变化、空间分布和时空变化情况进行定量分析评估,以期为当地土地利用规划及生态管理提供科学指导及支撑[2]。
本研究采用的InVEST 模型通常利用生产函数的方法来量化和评估生态系统服务,并由一系列特定功能的子模型组成。不同子模型的生产函数需要对应的生态环境参数作为模型输入,因此本研究的数据集由延庆区遥感数据、气候数据、土地数据、土壤数据、农业专业数据等多源数据组成。本数据集具有四方面特点及优势:一是可用于生态系统服务功能的定量评估,二是适用于大尺度生态系统服务功能评估,三是补充了延庆这一特定区域相关研究的数据空白,四是数据种类全面丰富,数据源权威科学。本数据集既可为研究区生态系统服务功能评估提供数据基础,同时对于其他生态环境领域的科学研究也具有一定价值。
1 数据采集和处理方法
1.1 数据集构成及分类
数据集由延庆区遥感数据、气候数据、土地数据、土壤数据、农业专业数据等19 类多源数据组成,考虑到本研究涉及数据类型较多,可按照数据用途及对应的子模型对数据进行分类整理,具体分类及数据集构成如图1 所示。
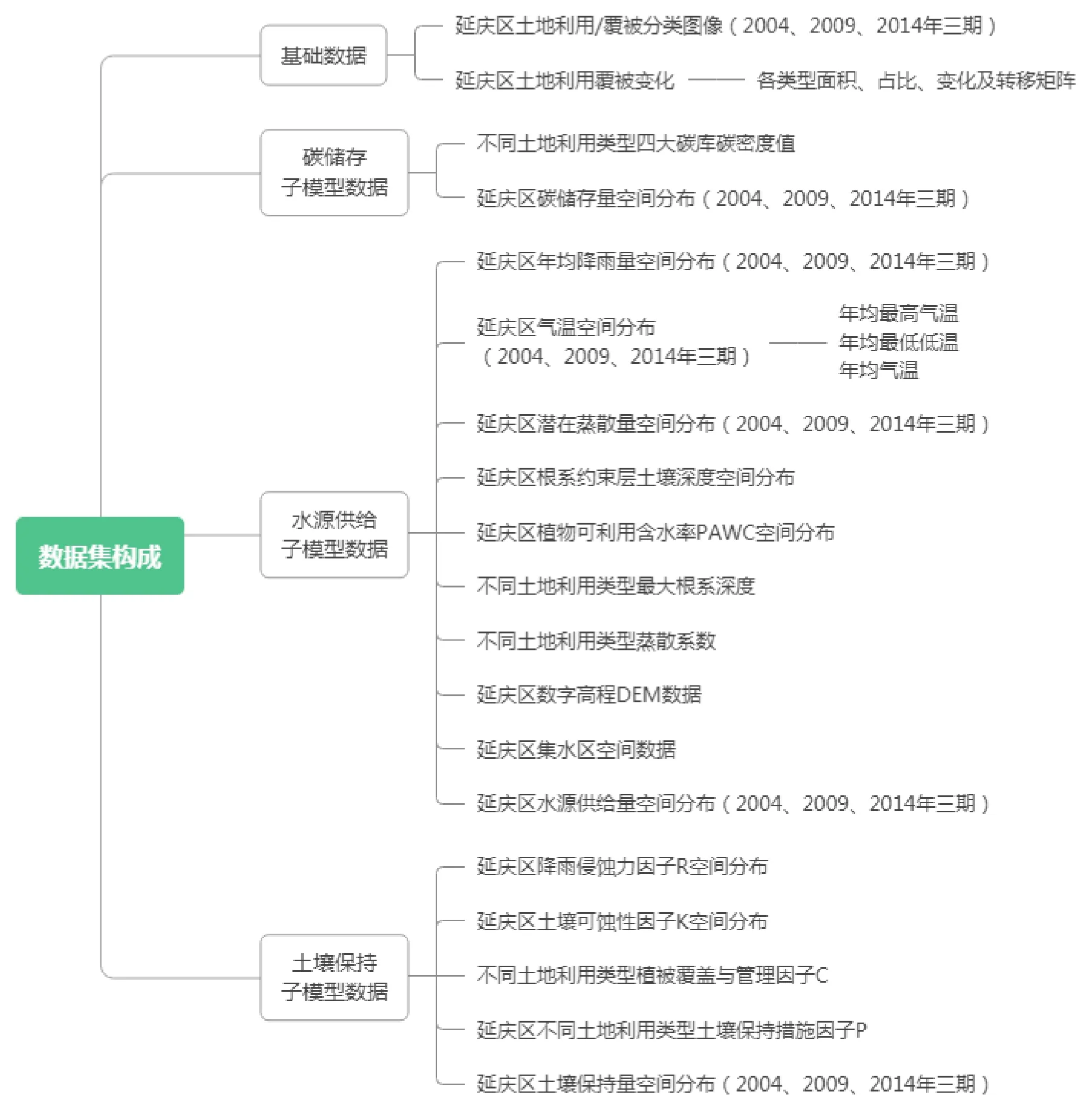
图1 数据集构成示意图
1.2 土地利用/覆被分类图像采集与处理
1.2.1 数据源与数据采集
土地利用/覆被分类数据是本研究的基础数据,数据集中包括2004、2009、2014 年三期的延庆区土地利用/覆被分类图像。原始数据为来自中国地理空间数据云(http://www.gscloud.cn/)landsat 系列数据的遥感影像,空间分辨率30 m,时间分辨率16 天。根据延庆县的地理位置,将经纬度分别定义为116°E 和40°N,从而确定覆盖延庆区的遥感影像数据范围。数据筛选的原则主要有3 方面:(1)云量小于10%的遥感影像,减少云层覆盖对后期解译处理的影响;(2)成像时间在6–9 月生长季节之间;(3)三期遥感影像月度时间尽可能保持统一。综合以上因素,最终选取Landsat 5 TM 数据两幅,成像时间分别为2004-09-08 和2009-09-22,Landsat 8 OLI 数据一幅,成像时间为2014-09-04。三期遥感影像数据的轨道号均为123/32。
1.2.2 数据处理
土地利用/覆被分类图像是在原始遥感影像解译的基础上得到的,具体处理过程分为数据预处理和非监督分类两个阶段。预处理主要包括波段叠加、辐射定标、大气校正、影像裁剪等步骤,均利用ENVI 5.1 软件操作实现。其中,波段叠加选用741 波段组合,其特点是兼容中红外、近红外及可见光波段信息的优势,图面色彩丰富,层次感好,能提高解译的精度与速度。之后利用ENVI 软件的Calibration Utilities 工具对叠加后的假彩色图进行辐射定标,再利用Flaash 模块完成大气校正过程,从而消除遥感传感器本身的误差以及大气散射引起的辐射误差。预处理结束后,利用ENVI 非监督分类法对遥感影像进行解译分类,参照全国土地分类的Ⅰ级分类标准及研究区的实际情况,将延庆区划分为城镇、农田、林地、草地、水体、裸地6 大土地利用类型,并最终生成2004–2014 年间的三期土地利用/覆被图像。
1.3 碳储存子模型数据采集与处理
InVEST 模型中碳储存子模型可以估算一段时间内某一地块碳的净储存量。由于环境中已有的碳储存大部分依靠四种基本的碳库,即地上生物量、地下生物量、枯落物和土壤有机质,因此碳储存模型的基本原理即用各地类的面积与四大碳库碳密度值进行相乘,从而得到不同地类碳储存总值,再累计得到研究区总的碳储存量。本数据集中四大碳库碳密度数据自政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC),IPCC 于2006 年制定了《2006 年国家温室气体清单指南》,其中第四卷则是专门针对确定农田、林地及其他类型土地温室气体的目录方法学[3]。该指南为估算碳储存提供了全面的碳密度数据,但使用时必须明确研究区所在的气候域和气候分区。通过查阅整理指南有关数据,最终形成本研究所需的不同土地利用类型(6 类)四大碳库碳密度值数据(表),包括地上碳密度、地下碳密度、土壤碳密度、枯落物碳密度,数据单位t/hm2。
1.4 水源供给子模型数据采集与处理
水源供给子模型用于模拟一定区域内的地表水源供给量,水源供给量越多则说明该生态系统水源供给服务功能越强。该模型是一个忽略地下水影响的简化水文循环模型,利用水量平衡原理,基于Budyko 曲线和区域年降雨量来计算水源供给量(具体公式见《InVEST 2.6.0 模型用户指南》)[4],即各栅格的降雨量减去实际蒸散量即等于该栅格水源供给量。因此,此模型中的水源供给量不仅包括地表产流,还包含了土壤含水量、枯落物持水量和冠层截留量。与模型对应的数据包括:(1)年均降雨量;(2)年均最高气温、年均最低气温、年均气温;(3)潜在蒸散量;(4)根系约束层土壤深度;(5)植物可利用含水率PAWC,以上均为空间分布tiff 数据;(6)不同土地利用类型的最大根系深度和(7)蒸散系数,以上数据为Excel 格式;以及(8)研究区数字高程DEM 和集水区shp数据。各类数据的来源、采集及处理方法具体如下。
(1)年降雨量的原始数据来自戈达德地球科学数据和信息服务中心(GES DISC)TRMM_3B43_V6 月降雨数据集,空间精度0.25°,数据格式为NetCDF,分别下载2004、2009、2014 年1–12 月的月降雨量NC 文件。由原始数据生成最终所需年降雨量数据,需要经过如下步骤:利用ArcGIS10.2 软件的Multidimension Tools 将原始NetCDF 导出为TIFF 格式并定义投影;对12个月的月降雨数据进行叠加并计算求得年平均降雨量;此时得到的年降雨量数据由于空间分辨率较差,所以需要利用ArcGIS 10.2 的Raster to Point 功能将栅格数据转换为点要素shp 数据,之后再利用ArcGIS 10.2 Geostatistical Analyst 功能中的Kriging 插值法进行空间插值,并完成重采样、裁剪、空间单位换算等操作,最终生成研究所需的空间分辨率为30 m、单位为mm 的年均降雨量空间数据。
(2)年均最高气温和最低气温原始数据来自美国国家气候数据中心(National Climatic Data Center,NCDC),在空间插值的基础上计算得到年平均气温和气温温差数据。通过空间计算便可得到延庆地区三期年潜在蒸散量的空间数据。
(3)潜在蒸散量主要指土壤蒸发和植物蒸腾的总耗水量。在本研究中,该数据是通过InVEST模型选用的Modified-Hargreaves 方法,利用年均气温、年度最高气温与年均最低气温的差值等数据计算生成的。
(4)根系约束层土壤深度,又可理解为土壤根系最高埋藏深度。数据来源于世界土壤数据库(Harmonized World Soil Database version 1.2,HWSD)。该数据库由联合国粮农组织(FAO)和维也纳国际应用系统研究所(IIASA)共同构建完成,可提供全球土壤数据。HWSD 由栅格图像文件及属性数据库组成,每个网格单元都能与常用的土壤参数相关联(如有机碳、PH 值、土壤深度等),因此本研究仅需利用研究区边界图对原始数据进行裁剪便可得到对应的根系约束层土壤深度空间分布数据。
(5)植物可利用含水率PAWC用以表征土壤中可以被植物吸收利用的水量占比,一般无法直接获取。本研究采用周文佐等定义的非线性拟合土壤PAWC估算模型进行计算,相关参数包括土壤中沙粒(SAN)、粉利(SIL)、粘粒(CLA)、有机碳(C)的含量(%)。以上数据同样来自HWSD,并通过ArcGIS 空间计算最终得到植物可利用含水率PAWC空间分布数据。
(6)最大根系深度指植被根系生物量达到95%时的根系深度。对于水体、城镇、裸地等没有植被覆盖的土地利用/覆被类型,最大根系深度则定义为0。本研究中最大根系深度数据同样来自世界土壤数据库,并整理形成相关数据表(Excel)。
(7)蒸散系数在本研究中是表征不同地面水分蒸发程度的参数,反映自然蒸发和植物蒸腾的综合情况,因此蒸散系数不仅要取决于大气干燥程度、辐射条件、风力强弱,还受到土壤导水能力、植被状况(植被水分输导组织、叶片气孔数量等)等因素的影响。本研究中蒸腾系数由InVEST 模型本身指定,无需单独采集处理。
(8)集水区是一个雨水汇合和集中排出的地形单位,也用于区分不同流域及其供应水源地区的界限。本研究的集水区shp 数据主要是基于DEM 数据进行水文分析生成的。延庆区DEM 数据来自美国地质勘探局(United States Geological Survey,USGS)的ASTGTM V002 数据集,下载涵盖研究区地面的DEM 数据影像共两幅,序号为ASTGTM2_N40E115 和ASTGTM2_N40E116。用DEM 生成集水区数据则需要利用ArcGIS 10.2 软件的hydrology 模型,经过提取水流方向,计算汇流累积量、水流长度,提取河流网络[5],最后进行流域分割分析等若干步骤完成。
1.5 土壤保持子模型数据采集与处理
土壤保持子模型主要用于对生态系统的土壤保持量进行量化评估,模型的基本原理是利用土壤潜在侵蚀量减去土壤实际侵蚀量从而得到土壤保持量。模型数据需求包括:(1)降雨侵蚀力因子R;(2)土壤可蚀性因子K;(3)植被覆盖与管理因子C;(4)土壤保持措施因子P。其中(1)(2)为空间分布tiff 数据,(3)(4)为excel 文件。各类数据的来源、采集及处理方法具体如下。
(1)降雨侵蚀力因子R是表征降雨导致的土壤流失或损失发生的能力大小的指标,本研究中采用Wischmeier 公式[6]、利用月平均降雨量和年平均降雨量计算因子数值。降雨数据的数据来源及采集处理方式与第1.4 节水源供给子模型中相同,此处省略。
(2)土壤可蚀性因子K被定义为标准小区内单位降雨侵蚀力引起的土壤侵蚀量[7],是衡量土壤抗蚀性的指标。本研究采用EPIC 模型,利用沙粒(SAN)、粉利(SIL)、粘粒(CLA)、有机碳(C)含量(%)等土壤属性数据计算土壤可蚀性因子。土壤属性数据来源及采集处理方式与第1.4 节水源供给子模型中相同,此处省略。
(3)植被覆盖与管理因子C反映植被覆盖及相应的管理措施对土壤流失的影响,因此不同土地利用/覆被类型、不同的植被覆盖度会形成不同的植被覆盖与管理因子值。规定因子取值介于0–1 之间。值越小,表明植被覆盖与管理措施对土壤保持作用越强;相反取值为1,则表明未采取植被覆盖与管理措施。本研究查阅整理路炳军等学者[8]完成的相关研究资料与文献,最终形成不同地类植被覆盖与管理因子C数据表(Excel)。
(4)土壤保持措施因子P是指采取水土保持措施后,土壤流失量与顺坡种植时的土壤流失量的比值。取值范围为0–1[9]。值越小,表明保持措施的作用越强。取值为1 时,表示未采取任何水土保持措施;相反,取值为0,则代表无侵蚀发生。本研究中土壤保持措施因子P的取值查阅联合国粮农组织《土地管理》[10]公开目录后整理而成。
2 数据样本描述
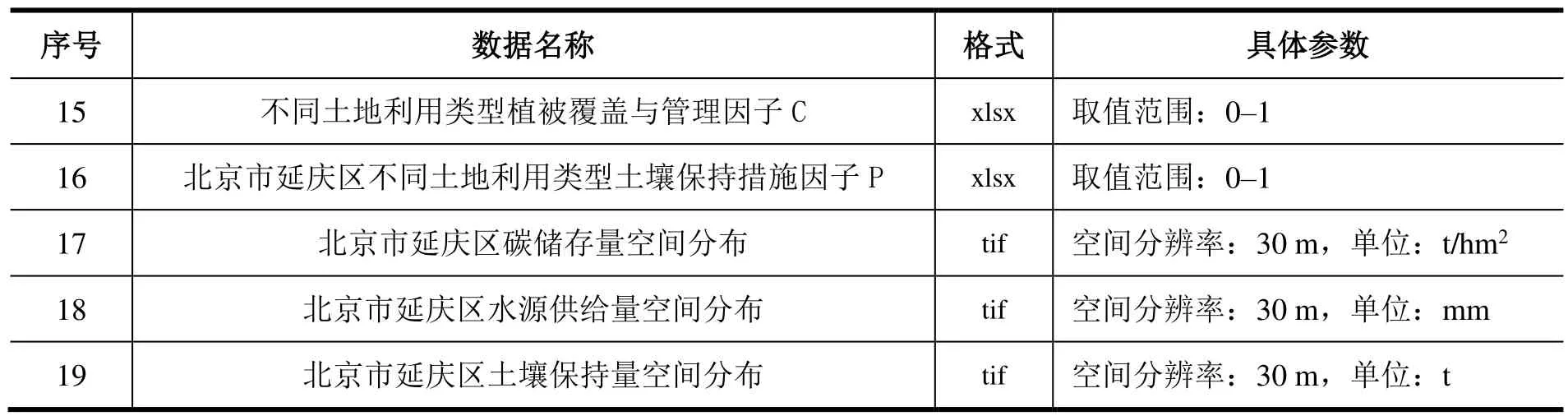
本研究数据集包含数据类型较多,数据集构成及各类数据基本信息如表1 所示。本数据集是在InVEST 模型原理下对研究区进行生态系统服务功能评价研究的数据基础。按照InVEST 模型中各子模型生产函数的规定,1–16 号数据(除2 号以外)是生产函数所需的输入数据,17–19 号数据是生产函数计算的结果数据。另外,本研究主要利用InVEST 模型对延庆区碳储存、水源供给、土壤保持这三大关键生态系统服务功能进行量化评估,因此也可按不同评估子模型对数据进行分类。其中:1号数据为三个子模型共同的基础输入数据之一;碳储存模型输入数据为3 号,输出数据为17 号;水源供给模型输入数据为4–12 号,输出数据为18 号;土壤保持模型输入数据为13–16 号,输出数据为19 号。数据集共计60.8 MB,部分数据样本示例如图2 所示。
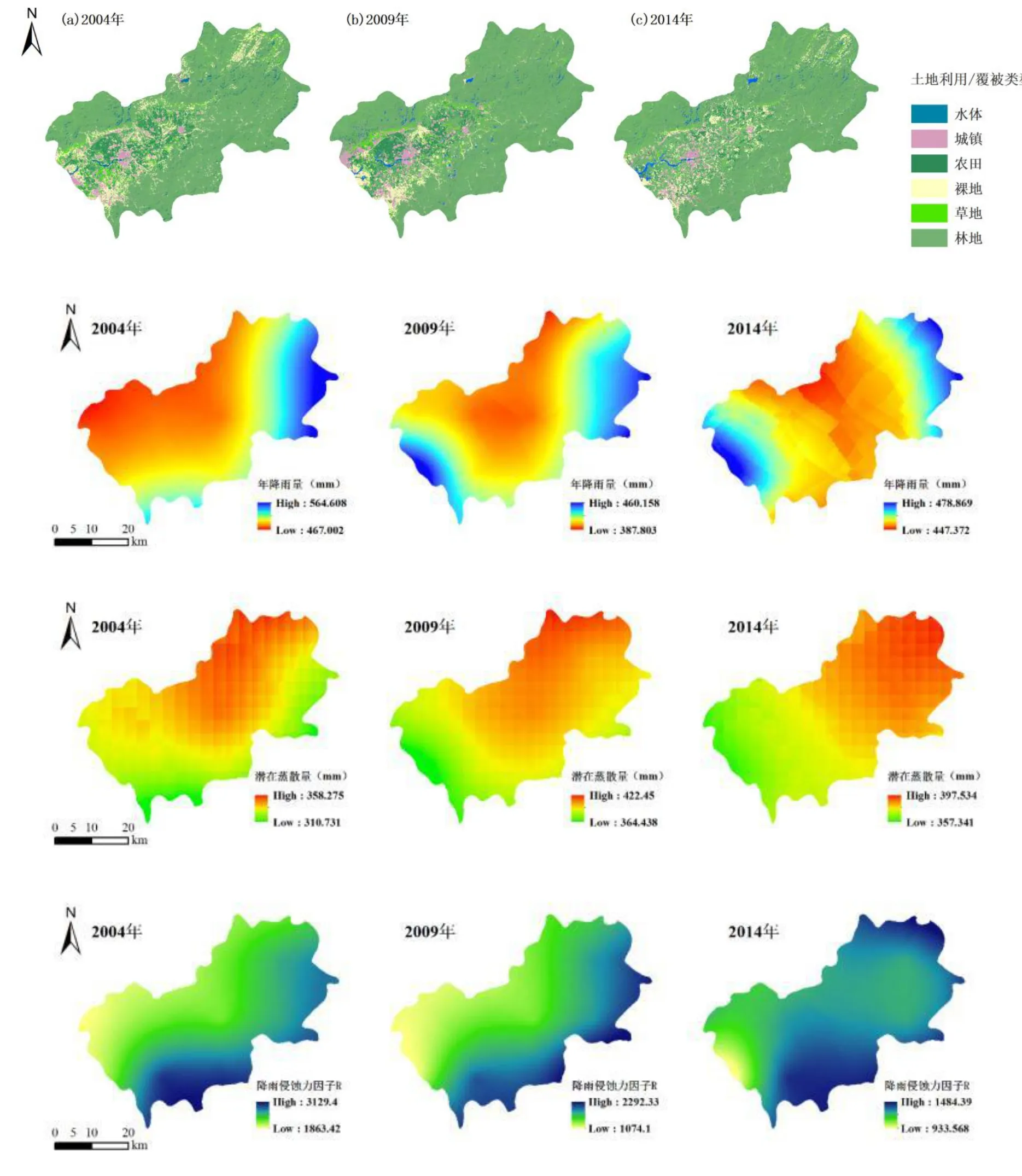
图2 部分数据样本展示
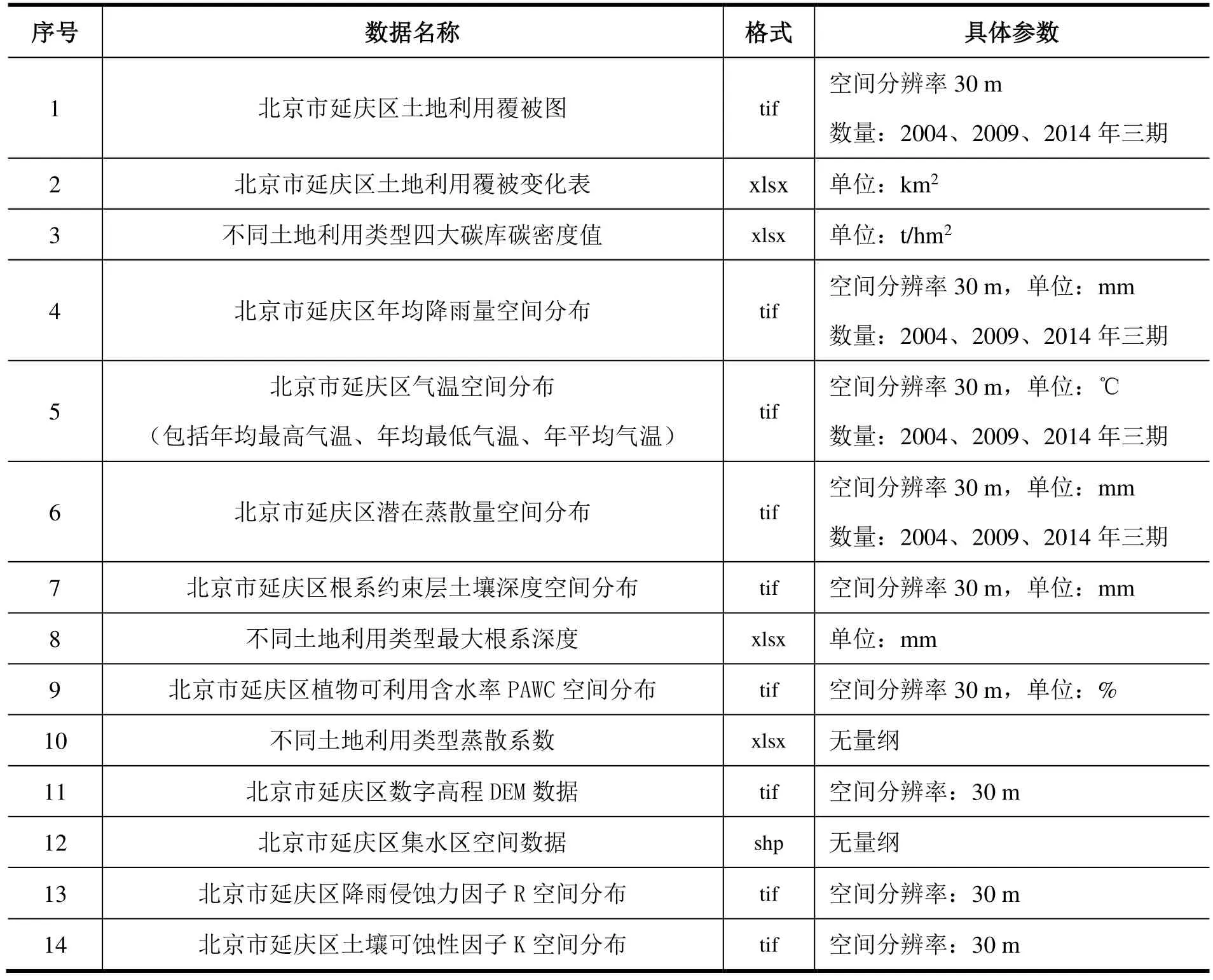
表1 数据集构成及各类数据基本信息
3 数据质量控制和评估
为保证数据质量及InVEST 模型数据格式要求,本研究所有原始数据均来自专业数据中心,如中国地理空间数据云、政府间气候变化专门委员会(Intergovernmental Panel on Climate Change,IPCC)、戈达德地球科学数据和信息服务中心(GES DISC)、美国国家气候数据中心(NCDC)、世界土壤数据库(HWSD)、美国地质勘探局(USGS)、联合国粮农组织(FAO)等,部分经查阅整理的数据也都源自领域内专业的公开手册、指南和相关科学文献等。
数据的加工及处理全部在ENVI 5.1、ArcGIS10.2 软件平台上进行,对于遥感影像解译、非监督分类、空间统计分析等数据加工过程均按照试验步骤操作完成。而模型计算是在《InVEST 2.6.0 模型用户指南》(InVEST 2.6.0 User’s Guide)[3]指导说明下完成,数据格式及质量均严格按照模型需求进行预处理。
4 数据价值
遥感技术、地理信息系统、大数据的迅猛发展,为基于大尺度空间的生态系统服务功能定量直观评估提供了便捷、精确的技术手段。本研究数据集整合了遥感数据、气候数据、土地数据、土壤数据、农业专业数据等多源数据,数据类型丰富,基本涵盖了生态环境及资源领域内的大部分关键指标数据。同时,本数据集也包含了部分专业研究中较难直接获得的创新性数据,如四大碳库碳密度值、根系约束层土壤深度、植物可利用含水率PAWC、最大根系深度、蒸散系数、降雨侵蚀力因子R、土壤可蚀性因子K、植被覆盖与管理因子C、土壤保持措施因子P 等。另外,本数据集以北京市延庆区为特定研究区,可作为补充数据为今后相关的区域研究提供科学数据基础。
