全球科学数据出版发展态势分析
——基于Web of Science 数据库的调研
2021-10-13王卫军李成赞郑晓欢褚大伟姜璐璐陈昕杜一周园春
王卫军,李成赞,郑晓欢,褚大伟,姜璐璐,陈昕,杜一,周园春*
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
3.中国科学院办公厅,北京 100864
1 科学数据出版概述
数据密集型知识作为科学研究的第四范式,科学数据出版逐渐成为数据密集型科学发现的重要学术传播方式[1]。2010 年国际科技数据委员会在年会上对数据出版的概念进行讨论[2]。欧盟在2014 年开始启动的地平线2020 计划中,提出在欧洲的公共资助研究中,要确保科学出版物的开放获取,并促进科学数据的开放获取[3,4]。在我国,2017 年12 月,中国科学院计算机网络信息中心主持编制的《信息技术科学数据引用》GB/T 35294-2017 准,规定了科学数据引用元素描述方法、引用元素详细说明、引用格式等方面的内容[5]。2018 年3 月,国务院办公厅印发《科学数据管理办法》,明确主管部门和法人单位应积极推动科学数据出版和传播工作,支持科研人员整理发表产权清晰、准确完整、共享价值高的科学数据[6]。2019 年2 月,中国科学院印发了《中国科学院科学数据管理与开放共享办法(试行)》[7],该办法以中科院数据工作问题和需求为导向,聚焦科学数据管理与开放共享的突破点与保障机制。2019 年11 月,国际科学理事会数据委员会(CODATA)发布《科研数据北京宣言》[8],肯定了世界各地已发布的数据政策和实施进展,并在此基础上阐明了推进相关领域多边合作的核心原则。随着政府、组织或机构在政策、制度等层面对科学数据管理工作的引导与扶持,科学数据出版工作蓬勃发展,同时科学数据出版的相关学术理论及实践研究不断丰富。
科学数据是科研成果的重要组成部分,科学数据出版作为一种新的科学数据共享模式,是推动科学数据共享,实现科学数据价值最大化,加速科技创新与经济发展的重要方式。在学术研究领域,相关学者对科学数据出版的定义[9-11]、科学数据的出版模式[12-14]、科学数据的出版平台[3,15]、科学数据的质量控制[1,5,9,11,12,16-21]、科学数据的影响力评价[22,23]、科学数据的共享问题[24-26]等理论及实践问题进行研究。其中,文献[12]在关于科学数据出版模式的研究中将其归纳为3 种:独立的数据出版、论文附件形式数据出版、数据论文出版。在上述出版模式中,独立的数据出版是指将数据作为独立的对象存储在数据仓储中[24];论文附件形式出版指的是一些学术期刊与数据仓储合作,期刊负责论文出版,数据仓储平台负责数据存储的形式;数据论文的出版指数据生产者按照一定科学规范形成的观察、实验、计算分析等原始数据或集成数据库(集)通过专门的数据论文进行描述,以促进数据的可发现、可获取、可理解和再利用[1]。目前,已有越来越多的期刊专注于科学数据出版,如《Data in Brief》、《Scientific Data》、《Earth System Science Data》以及国内的《中国科学数据》、《全球变化数据学报》等。同时用于存储科学数据的数据存储平台也不断涌现,如Gene Expression Omnibus、Figshare、Zenodo 以及国内的ScienceDB 存储库等。科学数据出版的蓬勃发展也吸引了越来越多的商业性数据库和搜索引擎的关注,如2012 年科睿唯安(Clarivate)发布的数据引文索引(Data Citation Index,DCI)服务平台,以及2018 年Google 推出的专用数据集搜索引擎Dataset Search。
目前,科学数据出版主要包括数据集的独立出版、数据集作为论文附件形式出版、数据论文的出版等模式,因此科学数据出版在数据库中涉及的文献类型主要为数据集和数据论文。在本文的研究中,为更好地获取全球范围内的科学数据出版数据,论文选择Web of Science 数据库产品,通过检索数据论文(Data Paper)、数据集(Data Set、Data Study)记录,从多个维度进行科学数据发展态势分析。
2 研究方法
为从全球视角对科学数据出版态势进行分析,促进科学数据出版事业的发展。文中选择Web of Science 数据库,设定出版年为1900–2020 年(年限以数据库所收录数据的出版时间确定),文献类型为Data Paper,共检出数据论文9,453 条记录(检出记录出版年份分布在2006–2020 年间),统计时间为2021 年5 月12 日。其中Web of Science 核心合集检出9,280 条记录,MEDLINE 数据库检出8,460 条记录,BIOSIS Previews 数据库检出7,771 条记录,INSPEC 数据库检出937 条记录,中国科学引文数据库检出44 条记录。上述数据中,国内的《中国科学数据》和《全球变化数据学报》期刊虽被中国科学引文数据库收录,但文献类型被标注为Article,故未被包含到上述检索结果中。针对此种情况,本文对《中国科学数据》和《全球变化数据学报》进行单独检索及处理,共获取297 条数据论文记录,其中,2017 年39 篇,2018 年45 篇,2019 年121 篇,2020 年92 篇。
选择Web of Science 数据库下的Data Citation Index 数据库,设定出版年为1700–2020 年(年限以数据库所收录数据的出版时间确定),共检出12,401,617 条记录(检出记录出版年份分布在1800–2020 年),统计时间为2021 年5 月8 日。Data Citation Index 数据库包括Repository(知识库)、Data Study(数据研究)、Data Set(数据集)、Software(软件)4 种记录[27]。其中Repository 是数据库或者数据记录的集合,用于存储并提供对Data Study、Data Set 数据的访问;Data Study 是存储在知识库中的关于研究或实验的描述信息,以及与该Data Study 相关的数据;Data Set 是知识库收集的与数据研究或实验等相关的数据文件,文件格式包括电子表格、音频、视频等;Software 是知识库存储的软件,可以是一段源代码、一个模型或一个完整的程序。由于Data Study 包含一些实验或调查相关的数据,研究中将Data Study、Data Set 统称为“数据集”进行相关分析研究。数据检索中,通过将数据类型限定为Data Study、Data Set,共获取12,218,549 条记录。
为从不同角度解析全球科学数据的出版情况及发展态势,研究中设定时间、国家/地区、研究方向、出版来源、影响力等5 个维度。基于各个维度分别对数据论文及数据集的出版数据进行检索,探析全球科学数据出版发展态势,特别是我国科学数据的发展态势,以期为我国科学数据出版政策制定及开展相关研究提供参考。
3 全球科学数据出版发展态势
3.1 时间维度
数据论文全球及TOP 5 国家从时间维度(年份)呈现的数量分布情况中,数据库中检索出Data Paper 类型文献9453 条记录。另外,检索《中国科学数据》和《全球变化数据学报》期刊获取记录297 条,其中66 条记录缺少国家字段信息。鉴于两份期刊数据绝大部分为中国科研人员发表的数据论文,因此对其数据通过人工方式进行简单处理。将297 条记录按照年份合并到全球的出版数据中,其中的295 条记录按照年份合并到中国的出版数据中。数据论文的全球出版数据中,2006 年为1 篇,2007–2010 年均为0 篇,图1 选取2011–2020 年数据论文出版数据进行呈现出版趋势。从全球数据论文出版数量以及趋势线可知,数据论文出版从2011–2020 年整体呈现快速上涨态势。另外,从出版数量排名前5 的国家看,其数量也基本保持逐年增长的态势。全球数据集及TOP5 国家从时间维度(年份)呈现的出版数量分布情况,如图2 所示。从全球数据集的发布数量及趋势线可知,2001年以来,全球数据集从年发布数量4 万左右,到2019 年达到年发布量137 万之多的峰值。2001–2019年数据集的数量虽然出现波动(数据库中2020 年数据集的数量处于不断更新状态),但整体上呈现上涨趋势。在时间维度上融入国家维度信息时,Data Citation Index 数据库中的数据集(Data Set、Data Study 类型数据)记录中有9,582,355 条记录(约占78%)不包含国家字段。但通过对部分国家最早出现数据集的时间进行检索,可知美国为1837 年,中国(不含台湾)为1989 年,加拿大为1974年,德国为1971 年,日本为1972 年,英国为1837 年,挪威为1974 年,荷兰为1960 年,法国为1922 年。虽然各个国家数据集的发布起始时间会受到数据库收录数据全面性、完整性等因素的影响,而存在一定误差,但是结合历史等因素,基本可以认为我国发布数据集的最早时间均要晚于上述几个国家。
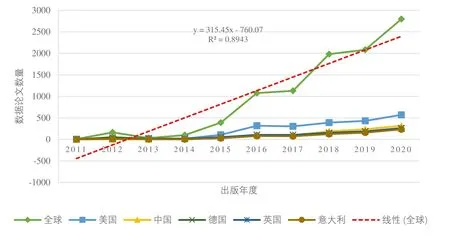
图1 数据论文年度分布情况

图2 数据集年度分布情况
综合上述时间维度数据,从数据库中收录的自1800 年以来出版的数据集,到21 世纪初期开始出版的数据论文,都可以看作是科学数据出版的不同形式或延续。从时间及数量规模上看,数据集出版历史悠久,已经形成庞大的出版规模。数据论文出版的出现时间较短,在年度出版数量上虽然增加迅速,但是从规模上可以认为其尚处于初期发展阶段。同时上述数据也可以在一定程度上反映出,欧美国家特别是美国,在科学数据共享工作中从数据集出版到数据论文出版,均在数量上占据优势。在我国,中国科学院为实现科学数据的管理与共享,于1983 年提出了“科学数据库及其信息系统”项目,先后经历了信息化建设、科学数据资源整合、科学大数据工程等发展历程,该项目涵盖化学、生物等多个学科数据,并取得了显著的社会效益及一定的经济效益[28]。结合上述检索数据,对于数据论文的出版,我国无论是从数量还是起始时间,基本能与欧美等发达国家基本保持同步。对于数据集的出版,在数据库中收录的最早时间为1989 年,到2020 年,在有国家字段的记录中我国共有16 万多条。结合中国科学院的科学数据库建设时间,基本可以认为我国在上世纪80 年代初开始科学数据相关管理与共享建设工作,因此,从数量上我国科学数据出版事业在较短时期内已经取得了很大发展与成就。
3.2 国家/地区维度
在对文献类型为Data Paper 的数据论文进行国家维度的统计时,由于数据论文出版中存在不同国家间研究人员合作的情况,同一论文会被多次统计,划分到多个国家,所以基于国家维度的记录总数要远远多于9,453 条。数据论文最终进行国家维度信息统计时,将中国数据增加295 条记录(增加《中国科学数据》、《全球变化数据学报》出版的数据论文)。在对数据集进行国家维度的统计时,78%的记录缺少国家字段信息,但从特定国家的数据集最早出版时间、已有的特定国家的数据记录出版来源分布等角度,也能获取一些有效信息。表1 是排名前20 的数据论文国家分布情况,其中,美国数据论文出版数量为2,165 篇,紧跟其后的国家是中国(不含台湾)1284 篇,德国897 篇,英国895 篇,意大利710 篇,法国553 篇,日本545 篇,印度474 篇,西班牙469 篇,加拿大466 篇等。科学数据论文的数量上,美国作者参与的论文占据绝对优势,排名前10 的国家也基本上为发达国家,作为发展中国家的中国、印度分别排名第2 和第8,可以反映出中印两国在数据论文出版方面取得的成就。表2 是排名前20 的数据集国家分布情况,虽然受限于大部分记录缺少国家信息,但是依旧能从数据中看出,美国以132 万之多的数据集记录数量在1221 万多总记录数量中占据重要地位,也在一定程度上反映了美国科学研究工作中的数据开放共享理念及成就。
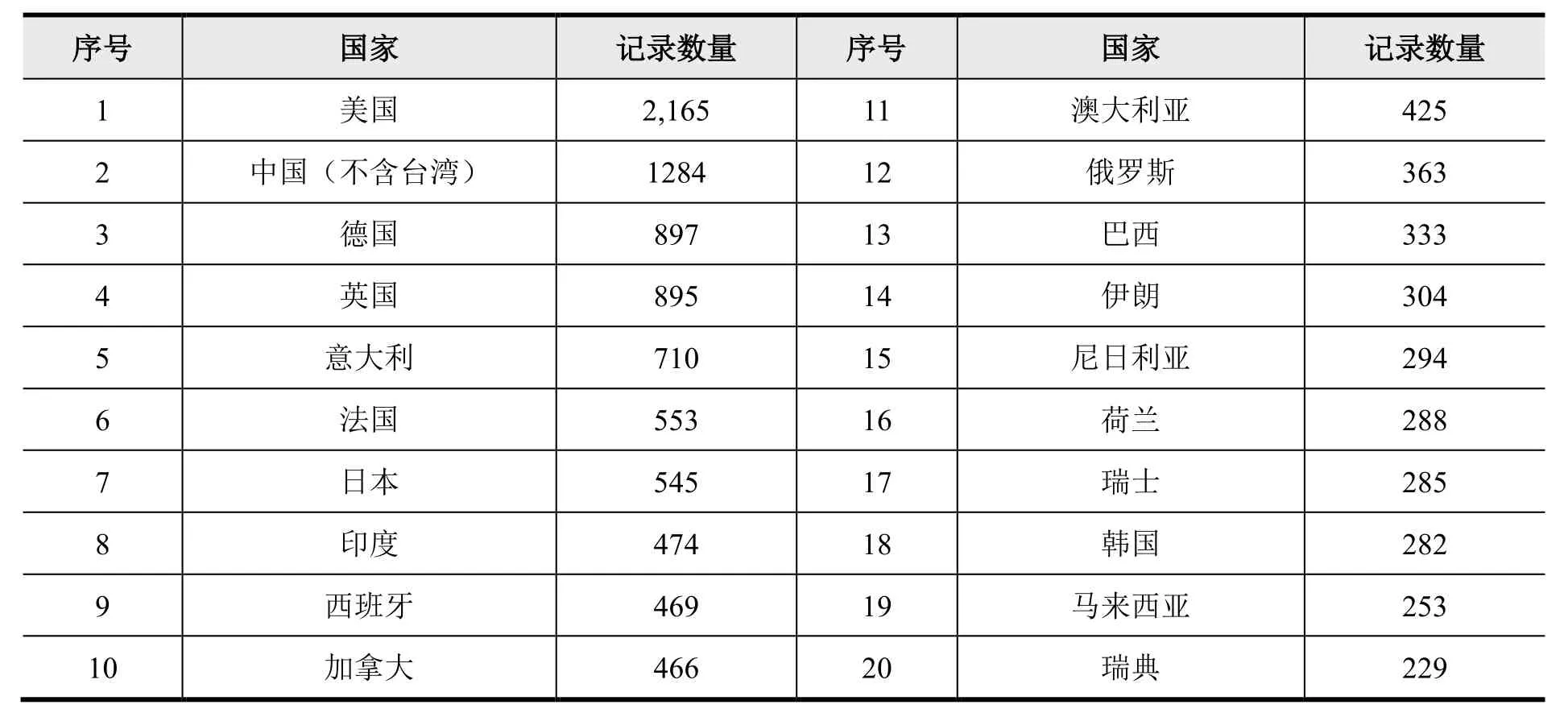
表1 数据论文国家/地区分布数量TOP 20

表2 数据集国家/地区分布数量TOP 20
综合上述国家维度数据,科学数据出版作为科学数据价值最大化,推动科技创新的重要途径,均受到发达国家和发展中国家及科研群体的关注与推动。从全球层面,在数据论文和数据集的出版数量上,发达国家整体呈现出了较大优势,基本可以反映出国家的经济和科技实力与科学数据出版规模间的影响关系。作为新兴经济体的中国、印度等在科学数据出版数量上的表现,反映出国家经济发展的过程中,科学数据共享作为国家科技实力提升的重要组成部分而受到关注与推动。结合上述科学数据出版数量数据,目前我国科学数据出版数量与美国虽存在差距,但我国是在相对较短的时期内取得的成绩,这也反映出我国科学数据开放共享事业的快速发展趋势,以及未来的巨大发展潜力。
3.3 研究方向维度
从研究方向维度分析,论文采用数据库中提供的基于研究方向的数据记录分类,其中表3 为数据论文的研究方向分布情况(不包括《中国科学数据》、《全球变化数据学报》数据),表4 为数据集的研究方向分布情况。对数据论文和数据集的各个研究方向的总量进行统计,最终数据记录总量均大于实际记录总量,可见存在同一数据论文或数据集划分到多个研究方向的现象,可视为存在学科交叉。
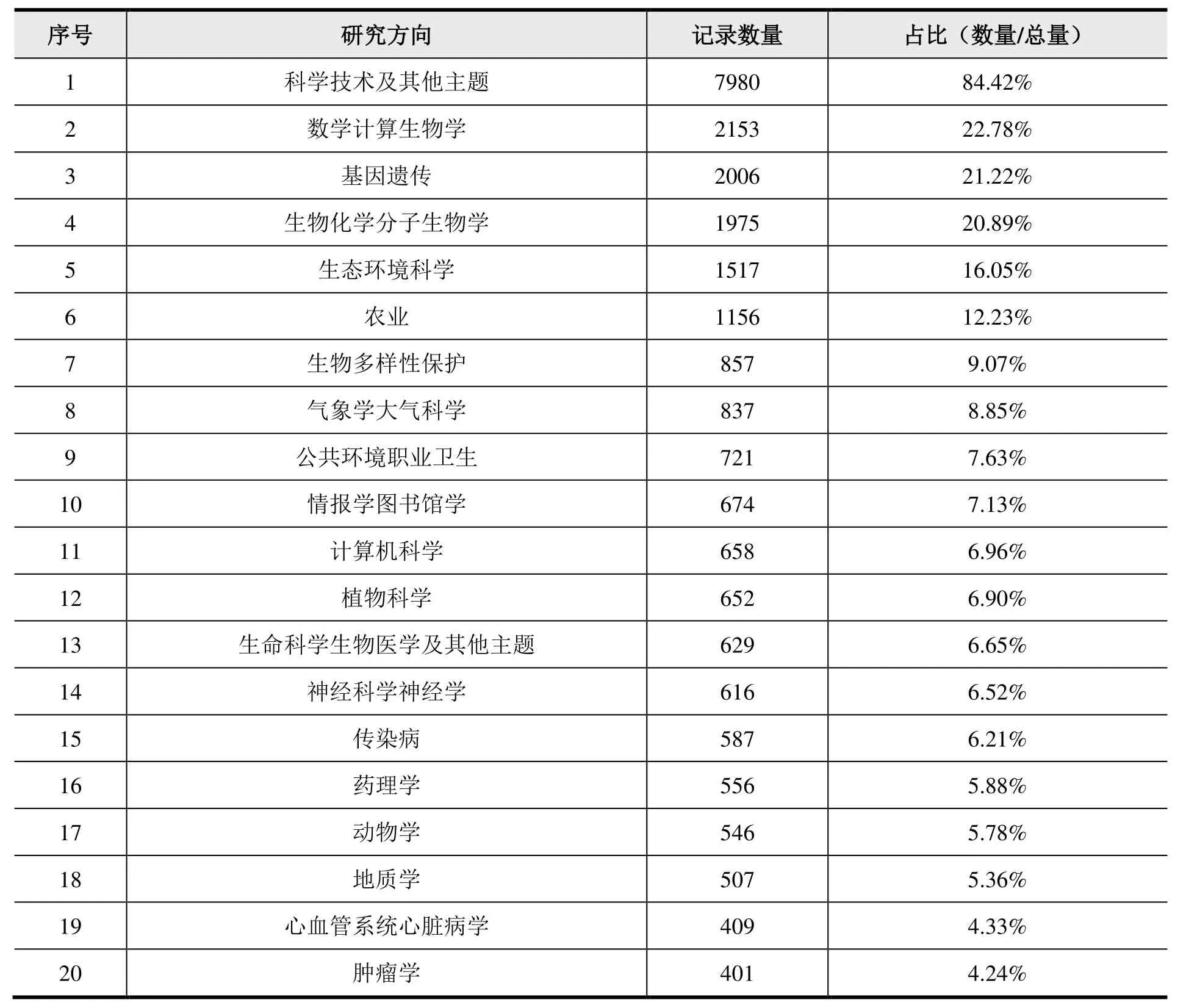
表3 数据论文研究方向TOP 20
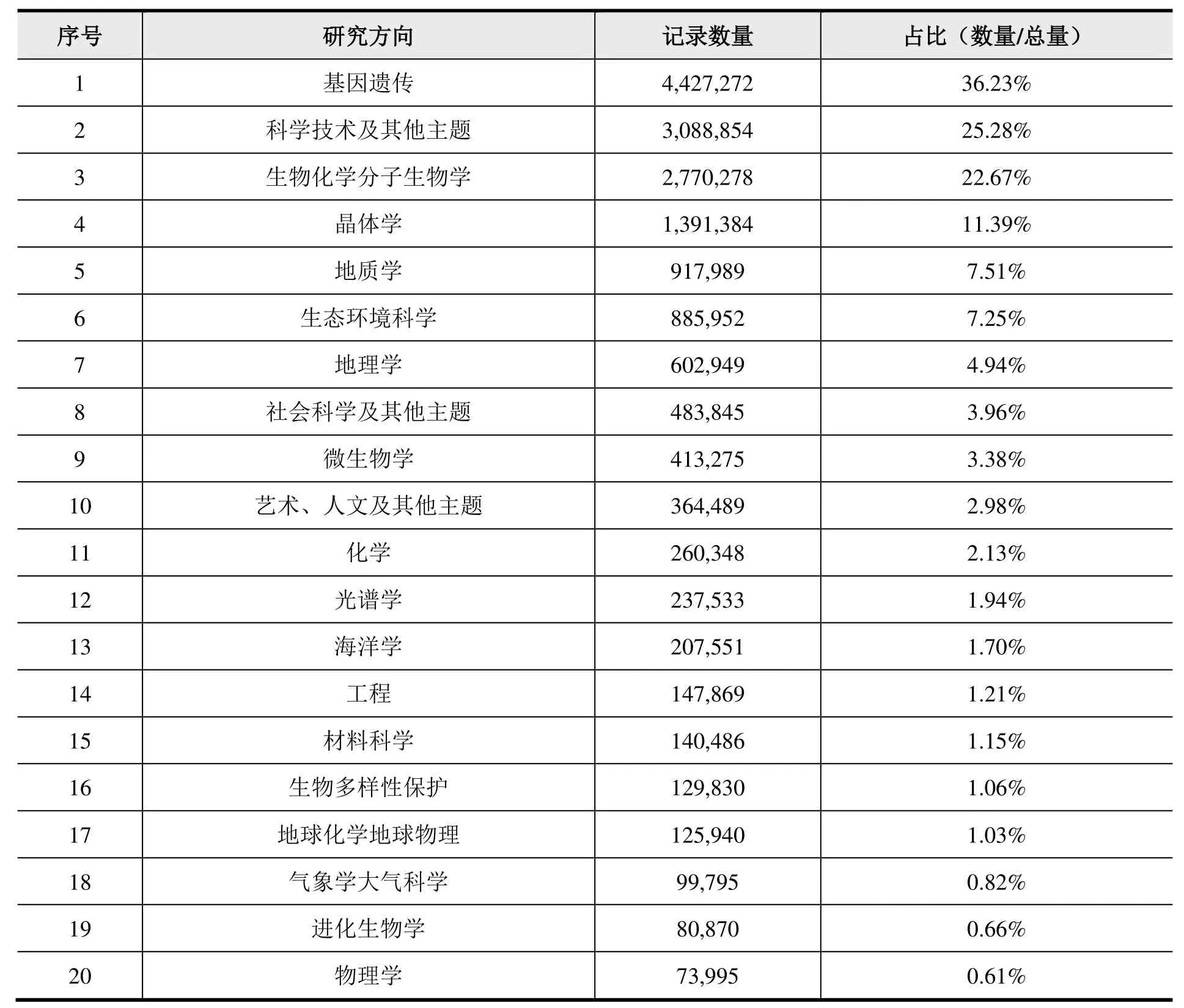
表4 数据集研究方向TOP 20
在数据论文的研究方向中,数量居于第1 位的科学技术及其他主题占记录总数量的84.42%。如果在统计时剔除科学技术及其他主题研究方向,可检索出8895 条记录,约占记录总量的94%。因此可以认为直接使用数据库中的研究方向划分体系能够合理体现数据论文的分类,同时也反映出科学技术及其他主题研究方向过于宏观。数据论文其他研究方向的数据分布中,数学计算生物学记录数量为2,153 篇,占据总量的22.78%;基因遗传记录数量为2,006,占据总量的21.22%;生物化学分子生物学记录数量为1,975,占据总量的20.89%;生态环境科学记录数量为1,517,占据总量的16.05%;农业记录数量为1,156,占据总量的12.23%;生物多样性保护记录数量为857,占据总量的9.07%;气象大气科学记录数量为837,占据总量的8.85%;公共环境职业卫生记录数量为721,占据总量的7.63%;情报学图书馆学记录数量为674,占据总量的7.13%。对《中国科学数据》和《全球变化数据学报》的数据论文研究方向单独进行统计,其研究方向主要分布于科学技术及其他主题208 条、地质学16 条、生态环境科学11 条、植物科学10 条、农业9 条、林业7 条、矿物学7 条、情报学图书馆学6 条等。
数据集的研究方向中,基因遗传记录数量为4,427,272,占据总量的36.23%;科学技术及其他主题记录数量为3,088,854,占据总量的25.28%;生物化学分子生物学记录数量为2,770,278,占据总量的22.67%;晶体学记录数量为1,391,384,占据总量的11.39%;地质学记录数量为917,989,占据总量的7.51%;生态环境科学记录数量为885,952,占据总量的7.25%;地理学记录数量为602,949,占据总量的4.94%;社会科学及其他主题记录数量为483,845,占据总量的3.96%;微生物学记录数量为413,275,占据总量的3.38%;艺术人文及其他主题记录数量为364,489,占据总量的2.98%。
从研究方向上看,数据论文和数据集的研究方向分布具有一定的相似性,主要分布于自然科学等侧重于实验数据支撑的研究方向。但在社会科学领域也有分布,如数据论文的情报学图书馆学研究方向,数据集的社科科学、艺术人文等研究方向。综上所述,科学数据作为相应研究方向的数据支撑,无论是对自然科学的实验分析,还是对社会科学的实证研究都具有重要的价值。
3.4 出版来源维度
从出版物来源维度分析,数据论文(不包括《中国科学数据》和《全球变化数据学报》数据)绝大部分来源于《Data in Brief》、《Scientific Data》,数量约占到79%左右,如图3 所示。其中,《Data in Brief》是Elsevier 公司以数据存储、共享为导向的学术期刊,接受所有学科的开放投稿,由于Elsevier收录论文后,通常会给论文作者发送邮件建议作者将科学数据进行出版,可以认为是《Data in Brief》出版数据论文数量占据重要地位的原因之一。《Scientific Data》是Nature 出版集团的开放获取在线期刊,接收自然科学和社会科学领域论文,旨在帮助科研人员发布、发现和重用研究数据,该期刊对研究数据的开放起到了里程碑性质的推动作用[4]。论文通过对来自中国的数据论文出版来源进行检索,可以发现中国的数据论文在国外刊物上出版排名前4 的出版物中,《Data in Brief》(国外出版物)涉及509 篇,《Scientific Data》(国外出版物)涉及214 篇,《Gigascience》(国外出版物)涉及77 篇,《Earth System Science Data》(国外出版物)涉及44 篇等。通过检索《中国科学数据》、《全球变化数据学报》的出版数据可知,《中国科学数据》和《全球变化数据学报》出版中国数据论文记录共有295 条,由此基本可以推断中国学者比较倾向于通过国外出版物发表数据论文。
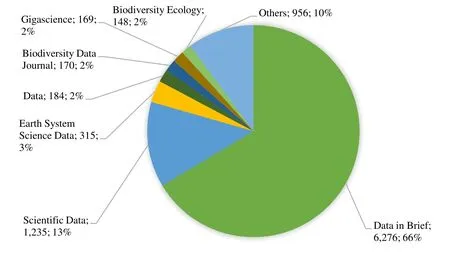
图3 数据论文出版来源分布情况
数据集在存储平台的分布情况如图4 所示,数据集相对于数据论文在各出版途径的数量分布上相对比较分散,可以看出数据集存储平台在全球的多样化发展态势。其中,Figshare(https://figshare.com/)是一个在线数据知识库,用于存储、分享和发现科研数据;Gene Expression Omnibus[29]是一个基因表达数据仓库,用于从任何物种或人造的来源检索基因表达数据;Cambridge Structural Database(https://www.ccdc.cam.ac.uk/solutions/csd-core/components/csd/)是世界上小分子有机和金属有机晶体结构的储存库,收录了全世界范围内所有已认可的有机及金属有机化合物的晶体结构;Zenodo(https://www.zenodo.org/)与Figshare 一样,都是知名的多学科数据分享平台,用于存储、分享和发现科研数据;US Census Bureau TIGER/Line Shapefiles(https://www.census.gov/geographies/mapping-files/time-series/geo/tiger-line-file.2018.html)提供了人口普查的地理和制图信息;Pangaea(https://www.pangaea.de/about/)作为开放访问库运行,旨在归档、发布和分发来自地球系统研究的地理参考数据;UniProt Knowledgebase(https://www.uniprot.org/)包括蛋白质序列数据以及大量注释信息;ArrayExpress Archive(https://www.ebi.ac.uk/arrayexpress/about.html)是主要科学期刊推荐的存储库之一,用于存储来自微阵列和测序平台的功能基因组学数据,以支持可重复的研究。同样,通过对来自中国的数据集的出版途径进行检索后可知,Plant Transcription Factor Database 存储库(中国)涉及65,535 个,Gene Expression Omnibus 存储库(美国)涉及52,981 个,Animal QTL Database 存储库(美国)涉及12,398个,European Nucleotide Archive 存储库(英国)涉及11,592 个,Genbank 存储库(美国)涉及7,182个,Zenodo 存储库(瑞士)涉及6,328 个,Compendium Of Protein Lysine Acetylation 存储库(中国)涉及3,311 个,Harvard Dataverse 存储库(美国)涉及444 个,IEEE Dataport 存储库(美国)涉及269 个,Mass Spectrometry Interactive Virtual Environment 存储库(美国)涉及263 个,World Data Centre For Climate 存储库(德国)涉及225 个,Peking University Open Research Data Platform 存储库(中国)涉及113 个。虽然数据集缺少国家字段的记录较多,但是上述信息也基本可以反映出:在数据集的出版上,中国的数据集虽同样存在倾向于国外数据集平台出版的问题。但相对于数据论文的出版,国内的数据集出版平台也为其提供了重要的出版途径。

图4 数据集存储平台分布情况
综上所述,全球范围内,数据集相对于数据论文的出现时间要早很多,其出版途径也相对更加多样化。研究中对Data Citation Index 数据库中出版年为2020 年之前的Repository(知识库)数据记录进行检索,共获取9 个来自中国(不包括台湾)的知识库,如表5 所示。Data Citation Index 数据库收录的我国建设的知识库主要为2000 年以后,其囊括的数据集的数量约7 万余条(在数据库中检出国家信息为中国的数据集的总数量约16 万余条),可知通过国外出版途径发布数据集的现象要弱于数据论文。在相关研究中,将出版途径却侧重于国外出版平台的现象称为“科学数据外流”[30],其原因归纳为:国外科学数据出版平台的影响力及吸引力显著优于国内;国内科技评价体系推动数据出版偏重国外途径;国外学术出版机构要求提交科学数据等。其中,科研人员出版倾向可以认为是数据主动外流,科技评价体系的影响及国外期刊数据存储政策要求可以认为是数据的被动外流。针对上述现象,除了制定相应政策法规引导相关出版机构组织投入更多资金推动科学数据出版平台的发展,提升对科研人员的吸引力外,还需改变人才评价机制,鼓励科研人员通过国内科学数据平台发布数据,推动我国科学数据出版事业的发展。

表5 Data Citation Index 数据库中收录的中国科学数据存储平台
3.5 影响力维度
在Web of Science 数据库中,科学数据出版的影响力评价方法主要采用数据论文或数据集被引用频次作为衡量指标。目前也有研究[23]将数据论文的被引次数与出版物的影响因子结合进行数据论文影响力的评价。通过将检索出的Data Paper 文献类型的影响力数据与《中国科学数据》和《全球变化数据学报》的影响力数据进行整合,绘制图5 所示的全球范围每年数据论文出版数量与每年度数据论文被引频次绘制图表,可发现数据论文的年度被引用频次整体上呈现上升趋势,这在一定程度上代表数据论文的出版模式引起越来越多的科研人员的关注。表6 对全球范围年均被引用频次最大的前30 篇数据论文进行统计,可知欧美国家的数据论文占据很大部分,其出版途径中《Scientific Data》期刊占据一半左右,这在一定程度上反映《Scientific Data》期刊在科学数据出版中的重要影响力。同时,在前30 的数据论文中,中国科学家作为第一作者在2020 年的《Scientific Data》期刊上发表的2 篇数据论文也快速获得了很高的影响力,这也反映出我国科学家参与的科学数据论文在影响力上取得的成绩。由于Data Citation Index 数据库中收录数据量大,且未提供年均被引频次指标,论文对数据集中被引频次排名前25 的数据集进行统计(表7),可以发现美国在数据集的共享工作中获得了很大的影响力。同时从数据集最早出现的时间看,全球最早为19 世纪初,主要开始于欧美国家,文献[31]认为学术文献之间的引用存在马太效应,即文献的被引用概率与其已有的引用数据成正比,可以在一定程度上将马太效应理论用于解释欧美国家数据集影响力高的原因之一。但在表7中1984 年、2017 年出版的数据集均获得了较高的引用次数,可以在一定程度上反映出数据集的质量和价值也是吸引相关科研人员进行引用的重要因素。
表7 数据集影响力TOP 25
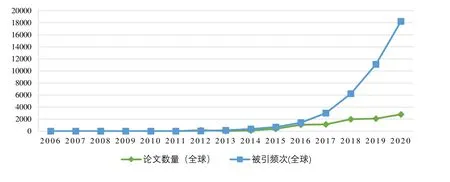
图5 全球数据论文年度数量与被引频次

表6 数据论文影响力TOP 30

备注:数据论文的被引数为2021 年5 月12 日检索时被引数据,数据论文年均被引数=总被引数/(2021 年−数据论文出版年+1)。
综上所述,具有高影响力的数据论文和数据集主要来源于欧美国家。上述数据的形成因素,如果不考虑科研人员引用行为、数据库数据收录全面性等的影响,则在某种程度上可以认为欧美发达国家科学数据共享工作的开展情况要优于国内。同时从数据论文的被引情况可知,近年来国内科学数据出版也取得了一定的影响力。
4 科学数据出版态势分析及启示
4.1 出版态势总结
科学数据出版是实现科研数据价值最大化的有效途径,也是推动国家科技创新的重要方式。文中对Web of Science 数据库中全球范围内的数据论文及数据集出版数据进行分析,并与国内出版数据进行对比,可以获取以下认知:
(1)从时间及国家/地区维度。全球科学数据出版整体呈现出蓬勃发展的态势,数据集和数据论文的出版数量都呈现出快速增长的趋势。可以预知随着人类探索未知世界的不断深入,科研人员对科学数据出版价值的认知提升,科学数据出版在数量及规模都将保持继续上升态势。从数据论文出版时间及国家的角度,中美两国发布数据论文的起始时间基本一致,但中国每年数据论文的出版数量基本上是美国的一半左右。从数据集时间及国家的角度看,由于数据集78%的记录缺少国家信息的描述,数据虽然不能准确反映国家维度出版数据集的增长趋势,但根据从数据库中获知的国家最早出版数据集的时间可知,美国始于1837 年,中国始于1989 年。结合我国中国科学院于1983 年开始建设的“科学数据库及其信息系统”项目,可以认为,我国科学数据集出版虽起步晚,但在数量上不断增加(基于已有包含国家字段的记录统计)。上述数据基本反映出了我国科学数据出版整体起步较晚,目前与美国之间依旧存在差距,但数量数据也反映出我国科学数据出版工作在很短时期内取得了很大的成绩。
(2)从研究方向维度。全球科学数据出版的研究方向主要集中于自然科学领域,也有研究方向属于社会科学领域,如图书情报、艺术等,但社会科学领域的数据论文、数据集在总体数量中并不占据主导地位。上述情况与自然科学和社会科学的研究方法密切相关,前者注重实验研究,后者注重理论研究。科学数据作为科学研究的重要组成部分,其出版共享工作不仅要关注于自然科学领域,还应在社会科学领域开展相关数据共享实践工作。
(3)从出版来源维度。从数据的分布看,数据论文的数量主要集中分布于个别期刊,而数据集的出版途径则相对分散。从更深层次看,可以认为数据集出版开始时间早,出版途径相对成熟并且多样化,而数据论文的出版还处于初步发展阶段,其出版途径主要集中于少数期刊,因此数据论文的出版还需探索更多的出版模式,丰富出版途径。同时,我国虽然在科学数据出版中占据重要地位,但是出版途径存在偏重于国外出版物和存储平台的问题。
(4)从影响力维度。全球范围具有高被引频次的数据论文和数据集,均主要分布在欧美国家。从整体上看,作为发展中国家的中国在数据论文和数据集的“量”上得到了巨大发展,在“质”上虽然取得了一定成就,但依旧与欧美国家存在差距。我国数据集的发布起始时间较晚,以及科研人员对数据共享认识的差异,高影响力数据集的出版相对不足。数据论文作为科学数据出版的新形式,其本质上也是数据集的另外一种体现形式,虽然中美近乎同时起步,也取得了一定进步,但还需要在“质”上引导与鼓励更多机构和科研人员的参与。
4.2 启示与建议
综合全球科学数据出版的多个维度发展态势,以及结合我国科学数据出版的发展现状,论文认为我国科学数据出版应侧重于从以下几个方面进行完善并推动我国科学数据价值最大化,服务我国科学研究工作。
(1)制定规范的科学数据出版质量控制体系。从上述检索出来的数据论文、数据集数据可以发现,78%的数据集记录的国家信息存在缺失、部分国家信息直接标注为国家下的州(省)、数据论文出版途径存在全称和简称共现等问题,数据的不完整、数据歧义等问题会直接影响对科学数据出版进行深层次分析的准确性。目前,科学数据出版尚处于探索的阶段[15],我国的《科学数据管理办法》、《信息技术科学数据引用》等都为科学数据知识产权保护和共享提供了方向,但这些工作还远远不能满足科学数据出版发展的需要,未来的工作需要从质量控制的角度,以科学数据共享为目的,从更高的层面对科学数据出版的各个流程制定规范化的科学数据分类、科学数据描述、科学数据存储与发布等相关标准、体系与框架,并形成具有约束效力的文件。
(2)打造优秀科学数据出版途径。我国的科学数据出版基本上开始于上世纪80 年代,虽然随着我国科技实力的不断上升,科学数据出版事业不断发展,但科学数据出版与国外相比依旧存在差距,在国内具有高国际影响力的优秀期刊和存储平台相对较少是这种差距的表现之一。针对此种问题,一是需要政府管理机构充分认识到科学数据出版对我国科研水平提升的重要价值。二是要从管理层面制定政策、投入资金,引导、鼓励国内相关研究机构、出版机构参与到科学数据出版工作中,并制定相应科学数据出版工作的考核评价体系,激励优秀科学数据出版物或出版平台的发展。三是制定法律规范要求国内出版机构和科研人员出版科学数据时,需在国内出版平台提交相关科学数据。四是将科学数据成果纳入到人才评价体系中,激励更多科研人员出版优秀科学数据。总之,需要政府、机构、科研人员等多方共同努力为国内科学数据出版提供更为优秀的科学数据来源,进而打造优秀科学数据出版途径。
(3)在全科学研究领域鼓励并引导科学数据共享发布。从文中数据可以获知,科学数据论文和数据集的出版涉及自然科学、社会科学等各个学科领域,科学数据无论是在自然科学领域,还是在社会科学领域都具有重要的价值。从此角度,无论是哪个学科领域,只要涉及到科学数据支撑的研究工作,都应该鼓励科研人员进行其研究数据的共享。在科学数据出版中,政府层面应该制定相应的激励政策鼓励各个学科领域的出版机构,积极参与到科学数据出版的工作中。各研究领域的出版机构要主动要求投稿人将论文数据进行公开共享。人才管理机构要将科研人员的科学数据成果纳入科研人员学术成果中。总之,需要从制度上、利益上吸引我国各个学科领域科研人员进行科学数据共享。
(4)引导科学数据出版从“量”到“质”的转变。在将我国与国外数据出版进行对比的过程中,可以发现我国科学数据出版在“量”上蓬勃发展,在“质”上与欧美发达国家存在差距。从表面上看是科研实力的差距,我国需要从政府管理层面制定政策、投入更多资金,提升整体科研水平,扶持激励高质量科学数据的出版。从内在深层原因看,是我国需要改革和完善科学评价体制,将科学数据出版纳入人才评价及激励机制,同时在对人才评价时还要注重科学数据产生的影响力及对相应学科领域的贡献、研究价值和意义。同时,还应意识到我国科学数据在量上虽已得到一定程度的发展,但还远远不够,还需要继续采取各种措施吸引更多科研人员贡献自己的科学数据。量变是质变的准备,我国的科学数据出版目前依旧有许多工作需要完善,如规范科学数据出版质量、培育高影响力科学数据出版平台、鼓励各学科科学数据出版等,为我国科学数据出版的质变提供前提和准备。
致 谢
本文得到中国科学院战略性先导科技专项(B 类)课题(XDB38030300);国家自然科学基金专项(L1924075);科技部创新方法工作专项(2019IM020100);中科院十三五信息化专项(XXH13505、XXH13514)项目资助。
