基于动物志的鸟类形态特征数据集
2021-10-13薛延韬王江宁林聪田韩艳丁晓庆纪力强
薛延韬,王江宁,林聪田,韩艳,丁晓庆,纪力强*
1.中国科学院动物研究所,北京 100101
2.中国科学院大学,北京 100049
3.国家基础学科公共科学数据中心,北京 100190
引 言
生物形态特征提取工作是将志书、图谱、论文等文献资料中有关物种特点的文字描述进行信息抽取,形成结构化数据的过程。结构化数据具有可量化或可类化的特点,便于计算机处理。可量化的数据指的是能以数值衡量的数据,可进行数值计算;可类化的数据指的是离散的定性描述型数据,一般都有明确的取值类型,类似枚举型数据结构的概念。另外还有一些特殊类型的数据:时间型数据是在时间维度上的数据,通常和日期、季节、时间、发育阶段等有关,作为描述的状语或限定词出现;比较型数据是针对两个以上描述对象进行特征比较的特殊数据类型,这类数据主要是针对同一个性状或特征在不同的时间或类群之间进行比较的结果,是相对值。
形态特征对于生物学研究非常重要,是生物地理、系统进化等许多生物学科的基础;此外,它也是生物学和计算机方法交流的基础[1]。在当前生物学各分支学科逐渐由定性向定量研究发展的时代,形态特征数据也逐渐从记录走向应用。提取中文形态特征数据,不仅是对全球生物性状数据的补充完善,还能对与计算机、人工智能等学科融合起一定推波助澜作用。
由于我国的生物学起步较迟,许多基础生物学数据,尤其是形态特征,常以中文文字描述的自由文本的形式记录于各类志书、图谱、论文等文献资料中,数据数字化程度不高,可用的数据库则更少。为此,我们以动物志中鸟类相关资料为对象,尝试从历史文献中提取形态特征描述信息,构建鸟类形态特征数据库。
1 数据采集和处理方法
1.1 原始语料数据收集和处理
原始语料数据来自对《中国动物志 鸟纲 第七卷》[2]的扫描和文字部分识别,将包含有形态、生物学、分布、量衡度等内容的文本信息进行数字化处理,最终抽提各物种/亚种形态学的描述部分,形成原始语料库。这些数字化的原始描述数据可以从《中国动物主题数据库》中的“中国动物志数据库”(http://www.zoology.csdb.cn/)获得。
1.2 形态特征标记
为便于对上述语料库进行处理,我们基于C#语言设计开发了一套可用于window 平台的生物形态特征标记专用工具。其主要功能是对数字化的原始描述数据中所包含的对每个物种每个部位的特征描述进行标记,并形成特征清单。该工具的工作界面如图1 所示。标记的主要过程如下:

图1 本研究开发和使用的生物形态特征标记工具的工作界面
第一步:选择标记语料。选择区域A 中的清单后,对应的具体语料会在区域B 中完整展示。这些语料已经完成数字化,附有物种对应的描述类型信息。后续标记工作都基于区域B 中的语料开展。
第二步:标记每个形态描述。在区域B 中选择文字描述内容的“标注短语”,点击“+W”按钮自动识别特征原文,此时识别内容会自动填入区域C 中。
第三步:编辑语料信息。在区域C 中对识别后的特征名词/术语/主语、特征/属性值/宾语、特征/属性、属性单位等项目进行编辑。若“特征名词/术语/主语”识别不准确,可在“特征/原文”处选择特征名,单击“+T”即可重新识别;若“特征/属性值/宾语”识别不准确,可在“特征/原文”处选择特征属性值,单击“+D”即可重新识别,同时手动修正其他数据。
第四步:特征数据编辑确认无误后,点击“+Trait”按钮即可成功添加一条特征清单,显示在区域D 中。
此外,对于个体形态特征描述比较简洁明了的内容,在第二步时可选择自动提取整段内容的快捷方式,即可快速完成对该物种特征清单的添加。此操作结束后仍需对特征清单进行逐条审核,如有误则在右侧进行逐条编辑修改,最后点击“更新Trait”按钮即可。
1.3 数据抽取原则
在生物形态特征的抽取过程中,依照如下操作原则进行:
原则1:追寻本意。基于作者表达的真实意思进行提取,提取出的量化特征不与原文表达的意义相悖。
原则2:原子提取。对语料中出现的性状描述尽可能进行量/类化和细化,每一条清单内容是对该物种某一形态的单一特征描述,即能抽象成“1 特征取1 值”的形式。
原则3:体现核心。形态和描述是一条数据的关键两部分组成,需要按描述重点对语料划分,通常位置、部位、方位等定位描述用于修饰性状的细节结构,一般归置到形态主语部分;其他如颜色、形状、数量等记录作为描述部分。
原则4:保存原样。对于表达复杂且无法简单拆分的语句,则保留原始描述,待后续分析。
1.4 数据集设计方案
综上所述,本数据集包括原始语料数据和标记后的形态特征数据两类核心实体。按照数据库设计的一般性原则和实际使用情况,我们将原始语料数据设计成两张数据表,一张用于记录物种及其分类系统关系,另一张用于记录形态学的原始语料数据;而形态特征数据被设计成另一张表。各实体在Excel 中分别用tSpecies、tText 和tTrait 表记录,实体之间的关系如图2 所示。

图2 数据实体之间的关系示意图
2 数据样本描述
数据集以Excel 表格形式进行存储,包含3 个数据表单:第1 个为tSpecies 数据表,用于记录物种及其分类系统关系;第2 个为tText 数据表,用于记录形态学的原始语料数据;第3 个为tTrait 数据表,用于记录形态特征数据。3 张数据表中实体对应的元数据描述和示范数据分别见表1–3。本数据集结构较简单,此设计便于模式识别研究人员直接使用或者稍作调整后使用。需要说明的是,tTrait数据表中一些字段由默认值0 填充,这些默认值一般是在原始语境中作为一种默认的上下文情景,文中没有加以说明,反而是有特定取值的情况会进行特殊说明,因此在数据表设计时候采用了大量默认值设计。各字段默认值含义在“取值说明”栏都加以说明。
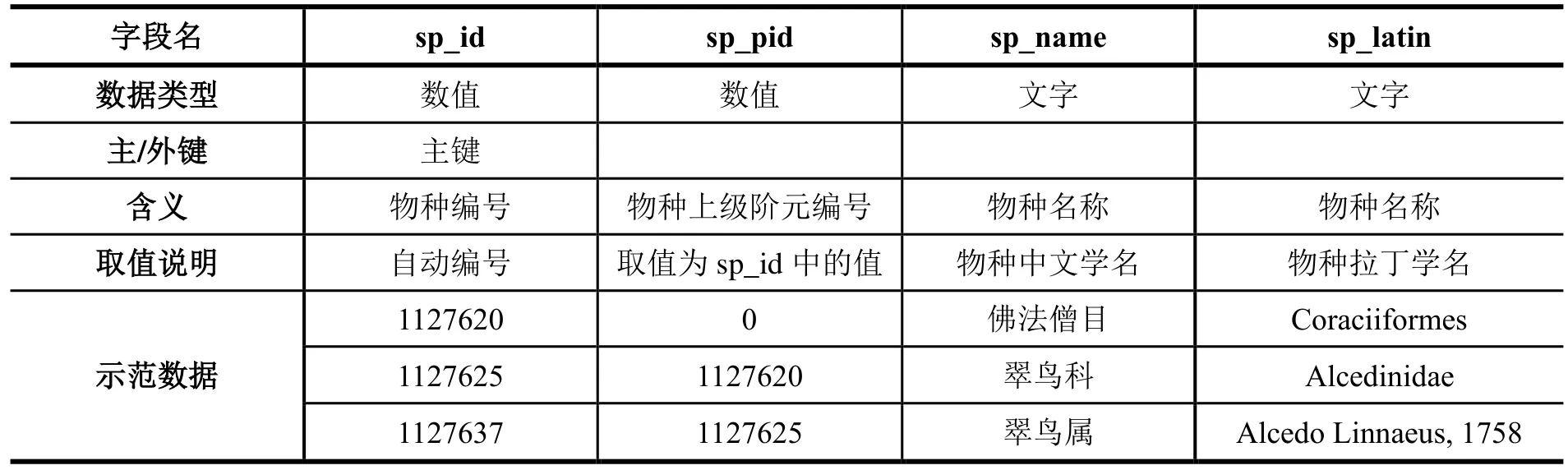
表1 tSpecies 数据表中字段的元数据描述和示范数据

表2 tText 数据表中字段的元数据描述和的示范数据
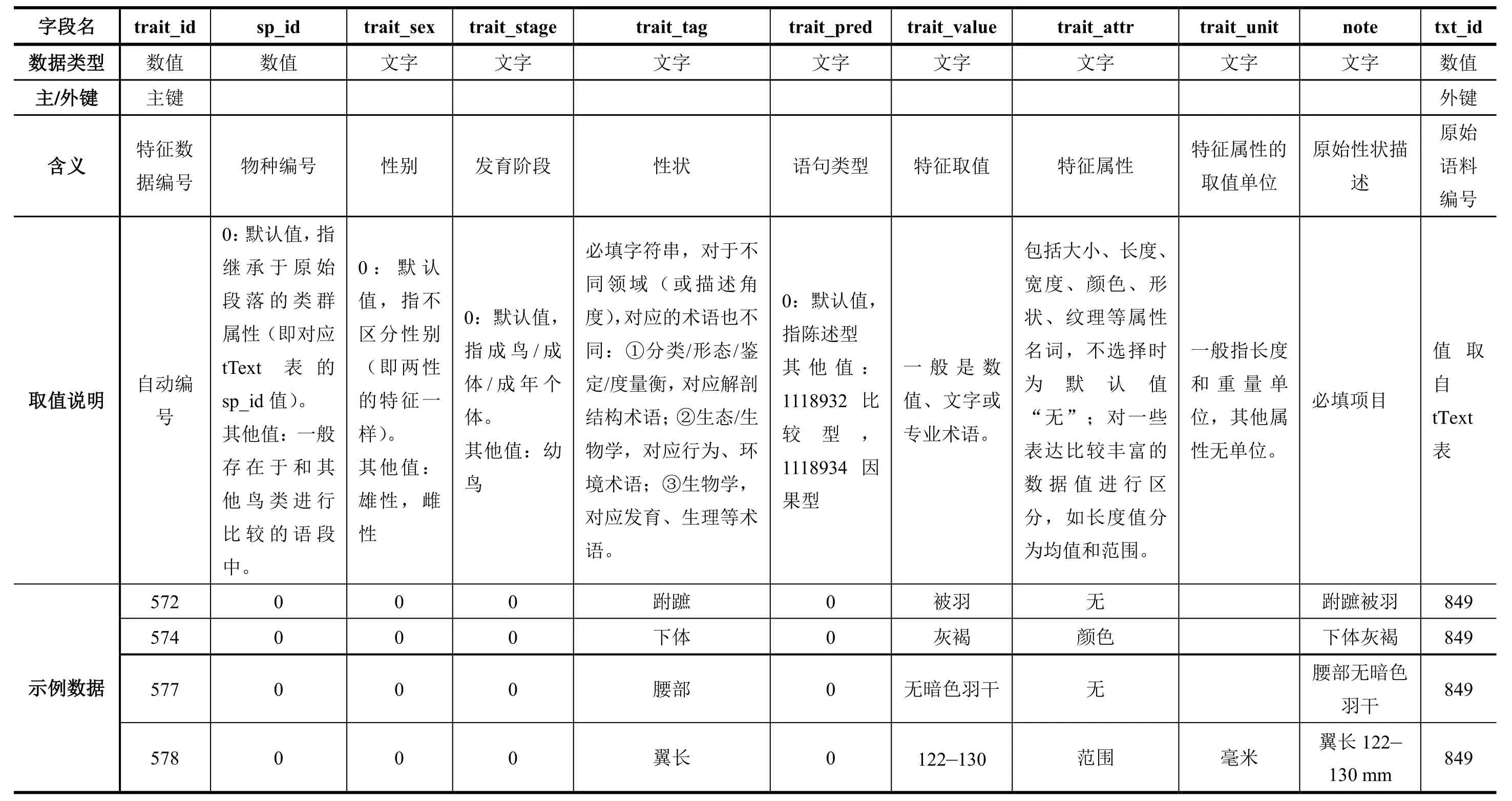
表3 tTrait 数据表中字段的元数据描述和的示范数据
3 数据质量控制和评估
本数据集采用的生物形态特征提取方法经过了长期的探索和实践,开发并逐步完善了专用标记工具(如图1 所示),用于在特征提取中的规范化和简洁化操作。在提取形态特征的过程中,所面临的描述语段往往非常复杂,存在诸如无关语句、比较句型、倒置句型等语句层问题,以及多主语、主语指代不明、细微结构词、复杂限定状语等句式问题,且内容与作者的写作风格、描述对象的特征、写作时的文化环境有紧密相关性。因此,在长期探索和实践的过程中,我们提出了形态特征提取原则以及问题解决方案,形成了一套独特的形态特征提取方法,最大程度保证数据库的准确性和实用性。同时,我们还设计开发并逐步完善了生物形态特征提取工具,使数据提取过程标准化、程序化和规范化,且该工具经过多人验证使用,运行稳定可靠。此外,对于提取后的形态特征值,我们仍然进行了多次人工抽样核查,以保证标记结果的准确性。
4 数据使用方法和建议
本数据集用途较多,可以:
(1)作为相关鸟类的形态特征数据集使用,用于相关物种的谱系关系分析等研究。
(2)用作自然语言处理研究中的语料,作为训练集和验证集使用。
本数据集数据形式简单,在使用时注意:
(1)形态特征数据应与文本编码和物种/类群编码结合使用。
(2)目前对于形态特征的提取尚无统一标准,本数据集所使用的原则和方法已在本文中说明。如有异议请参考原文,以原文表述为准。
(3)本表数据集的原始数据采集自谭耀匡和关贯勋于2003 年编著的《中国动物志 鸟纲 第七卷》[2],书中的分类体系和当前《中国生物物种名录》[3]中的新分类体系有差异,因此在使用物种数据表(即tSpecies 数据表)中的数据时,请根据物种的中文名或者拉丁名自行校对。
致 谢
感谢中国科学院软件研究所马龙龙在数据审核校准中所做的工作。
