基于GBDT和LR算法的用户流失监控技术研究
2021-10-13梁家富邱新泳
梁家富,邱新泳
(广州科技职业技术大学,广州510550)
0 引言
在一个稳定的电信领域中,用户流失监控是企业的研究焦点之一,主要是因为开发新用户的消耗比维持已有用户的消耗成本高出约5~6倍[1]。现有资料显示,移动用户每个月的平均流失率为2%~5%[2]。为了巩固用户人数,避免用户流失,电信运营商需要准确计算出易流失的用户群体。这就需要创建用户流失预警系统来预测,通过分析用户行为数据对用户的流失几率进行分类。目前有很多算法被运用在用户流失模型中,如GA_BP、逻辑回归、朴素贝叶斯、SVM和神经网络等。用户流失监控模型预测能计算出潜在离网用户,便于运营商及时制定出挽留用户的方案,有效预防用户的流失,为运营商节省资金,保证收益。
针对用户流失的问题,本文利用LR算法容易并行化、运算速度快等优点,结合GBDT容易计算特征组合的特性,提出一种基于GBDT-LR混合算法的用户流失监控技术。
1 GBDT和LR算法描述
1.1 GBDT算法描述
1999年,Friedman提出一种基于AdaBoost类集成学习算法的改进算法——梯度提升决策树GBDT(Gradient Boosting Decision Tree),也称MART(Multiple Additive Regression Tree),属于迭代决策树算法。GBDT算法以CART回归树作为基分类器,创建数百棵树,所有分学习器的预测结果的残差作为下一轮分类器的训练值,并以顺序串行沿着残差减少的角度开展梯度迭代,通过对所有基学习器的训练结果进行加权求和,获得最后的分类器。这种方式分类器设计简单,训练速度也大大加快。GBDT模型工作流程如下:
(1)把训练集{(x1,y1),(x2,y2),…,(xn,yn)},损失函数L(x1,γ),yi={-1,1}和迭代次数M,进行基分类器初始化,公式为


关于GBDT分类问题,可直接应用负二项对数似然函数计算损失函数,它的负梯度值就是残差的近似值。DBDT的负二项对数似然函数的公式为

1.2 LR算法描述
逻辑回归算法(Logistics Regression,LR)是一种广义的线性回归模型,应用广泛。依据因变量类型分类,LR算法可以分成二分类LR和多分类LR算法。线性回归算法分析的是数值,而LR算法在线性回归计算结果的基础上,采用sigmoid函数将其转换成概率值,就是把自变量映射成[0,1]的范围之间,这样可以为后续训练提供输出类的概率。
设x为一组连续的随机变量,遵循Logistic分布,x的积累分布函数和密度函数为:

接着使用梯度下降法求出w的估计值,最后得到预测概率:
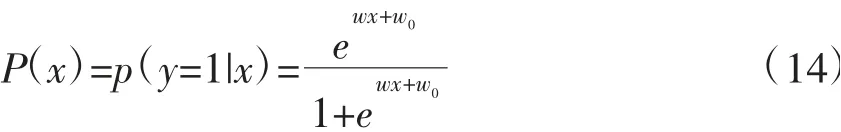
2 GBDT-LR混合模型
逻辑回归模型计算便捷,训练消耗小,对大数据处理能力好,但是其学习能力不足,训练特征的选取要求高,预测结果欠拟合。GBDT算法训练的特征值能有效解决LR的特征要求高问题,得到良好的分类效果。GBDT模型建立在Boost算法之上,通过迭代生成新的回归树,其特点适合作为新特征,便于挖掘其区分度,减少人工操作。
GBDT-LR混合模型是特征交叉的运算过程,GBDT的运算结果能够被LR作为输入特征直接采用,减少了人工处理交叉特征[3],其模型结构如图1所示。
由图1可知,Tree-1和Tree-2两棵树都是GBDT算法输出的回归树。样本数据集通过树的路径送达到子节点,所有子节点的输出结果集就是LR算法的输入特征,最后进行分类分析。

图1 GBDT-LR算法构造特征示意图
GBDT-LR算法的训练流程[4]如图2所示,其具体的模型训练步骤如下:

图2 GBDT和LR算法训练过程
步骤一:把原始数据集一分为二,将数据集A采用GBDT模型进行训练,构造Tn决策树组,得到强分类器。
步骤二:采用GBDT算法对数据集A进行训练预测,形成新的决策树Tn。
步骤三:对每一棵决策树Tn进行特征编码或者One-hot编码,输出向量Wn,把Wn进行重构,形成新特征供LR模型使用。
步骤四:把Wn和数据集B提供给LR算法训练,输出结果进行二分类统计,预测该数据集的用户流失情况。
3 实验
3.1 数据集
实验采用的数据集来自于电信领域真实用户的脱敏数据信息,数据集包含客户的个人信息和客户流失特征属性数据,MaxCompute Table有customer_id、Device_Protection、churn、Online_Backup等21个字段,都是String类型,包括7043条记录。其中,churn(用户流失)字段是本实验的目标字段。
3.2 构建实验
本实验在阿里云人工智能PAI-Studio实验室中进行,根据系统的预置模板构建流失用户监控系统,实验组件使用默认参数。GBDT-LR模型特征寻找和特征组合的功能强大,适合特征存在关联、特征呈非线性、特征指标多等应用范围,具有分类准确率高的特点。GBDT-LR分类器构建数据采集、数据特征提取、数据预处理、GBDT模型训练、构建新特征、LR模型训练、GBDT-LR模型二分类评估、模型保存等阶段。
3.3 GBDT-LR算法运算结果
3.3.1 GBDT二分类结果分析
在进行GBDT-LR算法的用户流失预警监控实验中,进行第一阶段的GBDT算法实验时,在指标数据经过GBDT二分类运算后得到阶段评估报告。模型评估指标数据包括序号、customerid、citizen、tenure、monthlycharges、totalcharges、KV和churn等8个字段,其中特征编码后的KV字段是关键数据,KV表的格式结构是Key:Value(Key表示index,Value表示特征值)。KV表支持多种算法,为节省存储空间只保留非零数据,所以表示特征量大,可以达到上百亿。GBDT-LR算法第一阶段前10条实验结果如表1所示。
在表1中,GBDT算法实验包括了KV字段,其 中,KV字 段 的 第 一 行 数 据 是“4:1,9:1,13:1,18:1,23:1,26:1”,这表示第一行数据4、9、13、18、23、26索引的值都是1,其它索引的值都是0,所以省略不计。

表1 GBDT算法实验结果
3.3.2 GBDT-LR与其他算法二分类评估结果比较
本实验场景比较了GBDT-LR分类器与其他6种分类器对用户流失风险预警的预测结果,其中包括SVM、GBDT、LR、KNN、PS-SMART和GBDTKNN,使用的分类性能指标为AUC、KS和F1-score(F1值)。实验结果如表2所示。
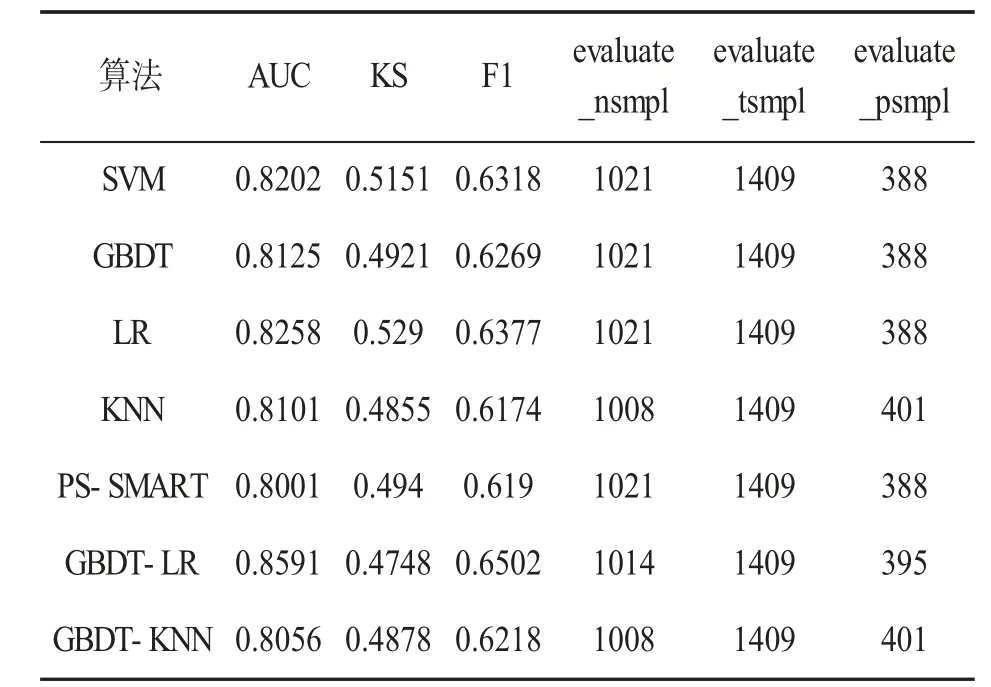
表2 用户流失预警预测结果
由表2可知,使用SVM、GBDT、LR、KNN、PSSMART、GBDT-LR、GBDT-KNN等7种算法进行用户流失风险预警预测,AUC面积数值均高于80%,其中,GBDT-LR模型的AUC面积数值最高,达到85.91%。特别地,单个LR算法预测AUC结果约为82.58%,而GBDT算法的预测AUC结果约为81.25%,都低于GBDT-LR模型的85.91%。复合PS-SMART、GBDT-KNN算法的预测AUC结果没有提高,反而弱于单个GBDT算法,主要影响因素是KNN算法是高度依赖距离的模型,数据维度的加大会导致两个目标点的距离增大,特别是稀疏矩阵中,会导致复合算法的预测面积数值下降。GBDT+LR算法的AUC面积数值排在榜首,主要原因是LR算法可以在矩阵数据高维度稀疏特征下进行预测,能弥补GBDT的拟合问题,从而提高整体预测效果。综上所述,GBDT-LR算法在用户流失监控预测系统中效果更优,符合用户流失监控预测系统的设计要求。
4 结语
本文提出了将学习算法GBDT与LR算法相结合,设计并实现了一个可以监控用户流失的预测模型,该模型可以处理数据在高纬度稀疏特征下进行较高面积数值的预测。实验证明,相对于SVM、GBDT、LR、KNN、PS-SMART、GBDT-KNN等预测算法,本文模型具有较好的AUC面积数值,利用LR算法弥补了GBDT的拟合问题,提高了预测速度,具有85.91%的AUC值。此外,该模型在面对大数据的预测服务时,具备较快的预测速度和较大的AUC面积数值。对于不同版本号、不同服务器的请求下本模型的准确度未知,仍需要后续的深入研究。
