基于改进的轻量级YOLOv3 的交通信号灯检测与识别
2021-10-13邵叶秦周昆阳郑泽斌唐宇亮
邵叶秦,周昆阳,郑泽斌,向 阳,唐宇亮,施 佺
(1.南通大学 交通与土木工程学院,江苏 南通 226019;2.南通大学 张謇学院,江苏 南通 226019)
交通信号灯是车辆驾驶过程中的重要标志信息。目前,辅助驾驶或自动驾驶的移动端对交通信号灯的识别准确率较低、实时性较差,存在很大的安全隐患。因此,准确、高效的交通信号灯识别是辅助驾驶和自动驾驶的重要研究方向。现有的交通信号灯检测与识别算法主要分为两类:基于图像处理的传统方法和基于神经网络的方法。
基于传统图像处理的方法主要利用交通信号灯的颜色(红、绿等)和形状(一般圆形)特征完成检测与识别[1-3]。这些传统的方法对于环境的敏感度较高,对于不同环境光照的鲁棒性较差,不利于实际使用。
基于神经网络的方法主要利用卷积神经网络去自主学习交通信号灯的深度特征,使得模型能够在不同场景下完成交通信号灯的检测与识别。Kim和Muller 等[4-5]使用单帧多目标检测(single shot multibox detection,SSD)[6]算法完成交通信号灯检测与识别,但SSD 算法检测准确率较低。Han 等[7]通过将Faster-RCNN[8]中的特征提取网络VGG16 的Pool4层去除,增大输出特征的尺寸,使得区域生成器能够更好地提取小物体特征;另外,引入在线难样本挖掘策略,进一步提高模型对交通信号灯识别的准确率。目前,基于经典目标识别算法(you look only once,YOLO)[9]模型的交通信号灯识别成为新的研究热点。2018 年提出的YOLOv3 算法把目标边框定位问题转化为回归问题,利用多尺度特征实现目标检测,使得算法检测速度更快、检测精度较高、且更加通用[10-14]。然而,常用的YOLO 算法模型主干网络较深,模型较大,在移动端推理速度较慢,难以实时检测和识别交通信号灯。
近几年提出的ShuffleNetv2[15]是一个轻量级的卷积神经网络,模型小、检测速度快。ShuffleNetv2 在提取特征过程中使用分组卷积(group convolution)和通道随机分配(channel shuffle)来压缩模型,大幅度减少计算量。
本文提出了一种基于改进的轻量级YOLOv3模型(Lightweight-YOLOv3,LW-YOLOv3)的交通信号灯检测和识别方法。采用轻量级的ShuffleNetv2网络代替YOLOv3 的主干网络;改进网络结构,融合ShuffleNetv2 的低、中、高层特征组成最终的高层输出特征,以获得更加丰富的交通信号灯信息;基于多尺度的检测和结果融合,完成交通信号灯的准确检测与识别。
1 改进算法
1.1 基本思路
为了实现轻量级YOLOv3,本文把YOLOv3 的主干(DarkNet53)替换为轻量级的ShuffleNetv2,并对ShuffleNetv2 输出的低、中层特征进行特征变换,拼接到高层特征上,丰富交通信号灯的特征表示,并通过上采样的方式融合多尺度的特征,利用多尺度检测和相应结果的融合,最终实现交通信号灯的快速、准确识别。本文方法的网络结构如图1 所示,Convl 表示3*3 卷积,Pool 是指最大池化,resn 中的n 表示block1 的重复次数,conv 表示1*1 卷积。
1.2 基于特征变换的特征提取网络
改进的轻量级YOLOv3 网络以ShuffuleNetv2为主干,包含stage2、stage3、stage4 的3 个不同尺度的特征图(如图1 所示)。输入图像经过stage2、stage3、stage4 多次卷积或池化操作后,特征大小仅为12×12。交通信号灯原本在输入图像(384×384)中就比较小,经过一系列处理后交通信号灯特征几乎丢失,不利于信号灯的准确预测。而在ShuffleNetv2 网络的低层特征中较好保存了尺寸较小物体的特征。因此,本文对ShuffleNetv2 低、中层的输出特征进行特征变换(见图2),然后把它们融合到高层特征上,作为ShuffleNetv2 最终的特征输出,如图3 所示。
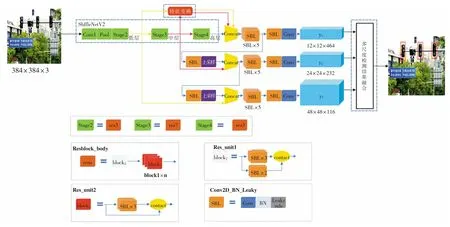
图1 本文算法的网络结构图Fig.1 Network structure of our method
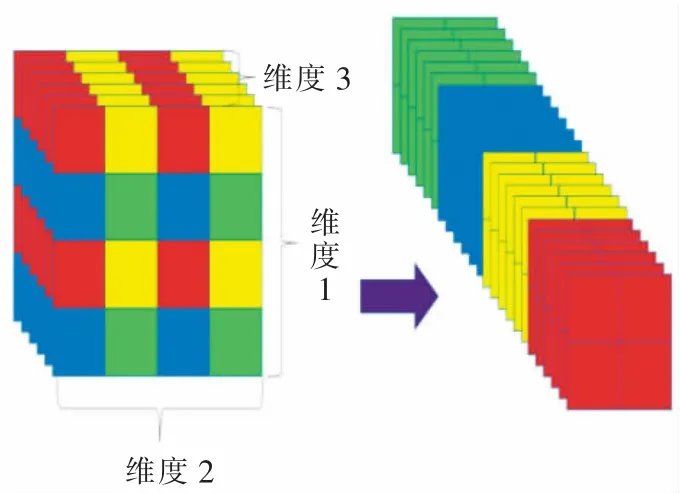
图2 步长为2 的特征变换Fig.2 Feature transformation of step size 2
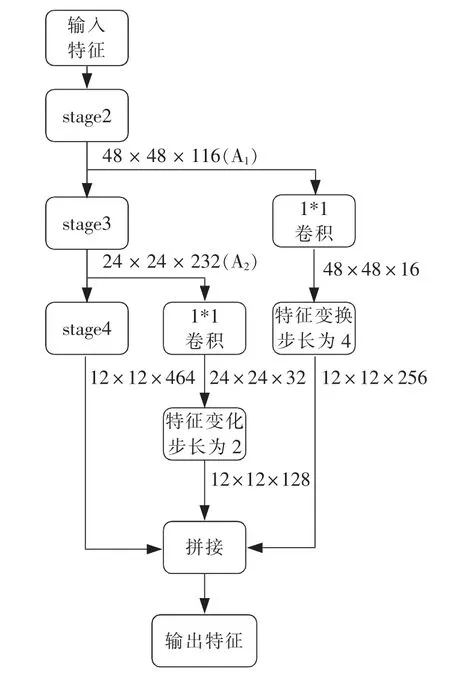
图3 特征融合图Fig.3 Feature fusion diagram
特征经过stage2 后得到特征图A1,A1经过stage3 继续提取特征。同时,A1经过1*1 卷积操作减少通道数,接着通过特征变换与stage4 的输出特征在通道方向进行拼接。类似地,特征经过stage3后得到的特征图A2,与stage4 的输出特征在通道方向进行拼接。这样,拼接后的输出特征中含有较为丰富的交通信号灯信息,能够有效提高识别准确率。这里,ShuffleNetv2 提取特征时,在每个卷积层后都加上批量标准化层(Batch Normalization)[16]和非线性激活函数层(Leaky ReLU)[17]。需要注意的是,本文未使用ShuffleNetv2 最后阶段积层、全局池化层和全连接层。
为了实现不同尺度特征的拼接,本文使用了特征变换。特征变换是对输入的特征图进行维度变换(如图2),维度1、维度2、维度3 分别是图像的高、长和通道数。具体来说,对于stage3 的输出特征图,特征变换先以步长为2 在维度1 和维度2 上进行切片,再将得到的2 × 2 数据块在维度3 上叠加,在保持特征信息的情况下,实现特征图的变换。对于stage2 的输出特征图,特征变换除了以步长为4 在维度1 和维度2 上进行切片外,其他和stage3 相同。经过特征变换后,stage2、stage3 输出的特征图大小和stage4 相等。通过特征拼接,ShuffleNetv2 输出大小为12 × 12 的特征图,通道数为128+256 +464=848。
1.3 基于多尺度的目标检测和结果融合
除了在ShuffleNetv2 网络结构上通过特征变换丰富交通信号灯的输出特征,本文还基于高、中、低层的特征(图1 中的y1、y2、y3),通过多尺度的目标检测,提高小目标检测的准确率,如图4 所示,SBL、Conv 与图1 中的SBL、Conv 含义相同,而3*3、1*1 表示卷积核大小。
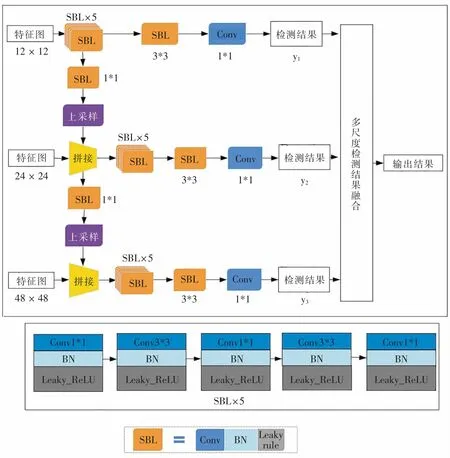
图4 基于多尺度的目标检测示意图Fig.4 Multiscale-based object detection
整个网络分为低、中、高3 个尺度。低尺度的特征通过上采样,融入到高尺度的特征中。由于YOLOv3 将目标检测问题转化成回归问题,因此,在每个尺度的预测过程中,如果交通信号灯的中心点落入到某个网格当中,那么该网格就负责预测交通信号灯的类别与位置。通过预测,本文得到结果向量M=12 × 12 × B ×(N+C+x+y+w+h),其中,B 为目标边界框个数,N 为目标类别的数量,C为目标边框置信度,x 和y 代表预测的目标边框的中心,w 和h 代表预测的目标边框的宽和高[18]。由于最小尺度的特征图y1为12 × 12,因此将图像分成12 × 12 的网格。这里,图4 中的Detection Block 是由3 个1*1 的卷积块和2 个3*3 的卷积块交替连接实现的。
本文使用3 个尺度得到多个预测结果,需要将它们融合起来。在检测过程中,同一个目标可能会有多个检测框,因此本文使用非极大值抑制算法[19](non-maximum suppression)消除那些置信度较低的检测框,使得每个物体只保留1 个检测框,完成检测结果的融合。
1.4 先验框的选择
YOLOv3 原本的先验框(anchor box)是在VOC2007和VOC2012 两个通用的目标检测数据集上确定的,但并不适合交通信号灯。为了提高模型的针对性,本文使用K-means[20]算法在LaRa 数据集上重新确定YOLOv3 的先验框。具体流程如下:1)随机在样本中选取K 个聚类对象,并以此作为聚类中心(本文的K 个聚类对象即为K 个anchor box);2)分别计算每一个样本对象到K 个聚类中心的距离,并将每个样本对象分配到和其距离最近的一个聚类中心,被分配的样本对象组成一个新的聚类;3)根据当前样本重新计算每个聚类中心;4)不断地重复步骤2)和3)直到最终K 个聚类中心保持稳定。本文中使用IOU 作为样本和聚类中心间的距离函数
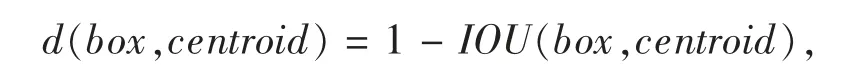
其中:box 表示标注矩形框;centroid 表示聚类中心的矩形框;IOU 表示聚类中心的矩形框和标注矩形框的交并比。为了不影响准确率,同时提高检测速度,本文选择了9 个先验框(即K=9),其宽和长分别为(5,16)、(7,24)、(8,26)、(3,12)、(8,24)、(7,22)、(4,13)、(6,19)、(13,38)。
2 实验结果与分析
2.1 实验数据与平台
2.1.1 数据集
本文使用LaRa 公开数据集[21],一共包含9 168张带标签图像,每个图像的分辨率为640 × 480。其中,训练集7 500 张,测试集1 668 张。数据集原始标签包括红灯、黄灯、绿灯、模糊4 类,其中红灯5 280 张,黄灯58 张,绿灯3 381 张,模糊449 张。
本文采用随机缩放、随机亮度调整、随机对比度调整、随机饱和度调整等方法来增强数据集。其中,随机缩放倍数是8~12 之间的随机数;随机亮度调整设定阈值为0.5,并在区间内随机选取1 个数a,如果a≥5,则亮度调整比例为a,如果a <0.5,则在区间(-a,a)内随机抽1 个数b,调整比例即为b +1。随机对比度调整、随机饱和度调整与随机亮度调整方法相同,阈值均为0.5。
2.1.2 实验平台
模型训练平台为百度AI Studio,32 GB 内存,Intel(R)Xeon(R)Gold 6271C CPU@ 2.60GHz,Tesla V100 16 GB GPU。编程环境为Python3.7,深度学习框架为PaddlePaddle 1.8.0。移动端测试平台为Nvidia Jetson TX2,256-core Nvidia PascalTMGPU,8 GB 显存,32 GB 内存,通过PaddleLite 部署模型,编程环境为Python3.6。
2.2 实验结果分析
为了比较不同算法的性能,本文采用平均精度均值Pma(mean average precision)、Rmd(missing detection rate)、单张图片检测时间t(infer time)、模型大小s 作为衡量指标。

2.2.1 主干网络对比
为了确保实验的公平性,对比实验全部在LaRa数据集上进行。其中,将ShuffleNet-YOLOv3 方法YOLOv3 的backbone 替换为ShuffleNetv1;将ShuffleNetv2-YOLOv3 方法backbone 替换为ShuffleNetv2。三者实验对比如表1 所示。
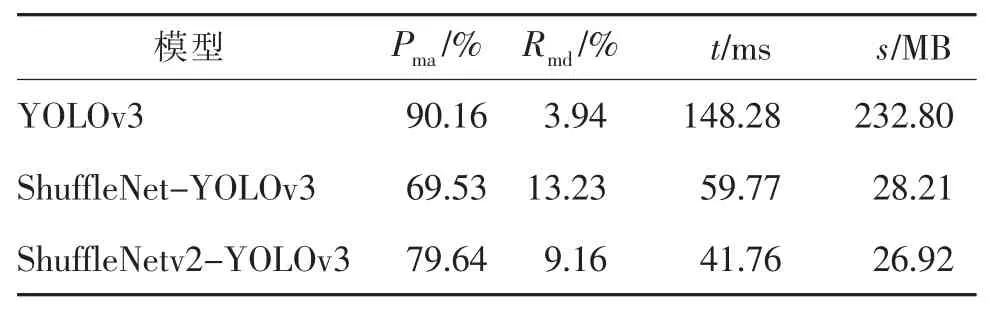
表1 主干网络测试结果对比Tab.1 Results comparison of backbones
从实验结果可看出,YOLOv3 的主干替换为轻量级神经网络ShuffleNetv1 和ShuffleNetv2 后,虽然在平均精度均值和漏检率上的性能有所降低,但模型的大小仅为YOLOv3 的1/8,检测速度提高为3倍,尤其是ShuffleNetv2 更加明显,因此更适用于实际交通信号灯的检测。若要将YOLOv3 推理时间降低到与ShuffleNetv2-YOLOv3 基本一致,需要在主流的Tesla V100 GPU 上,进一步采用TensorRT 推理加速技术。最终,YOLOv3 的检测时间可达到64.03 ms,接近ShuffleNet-YOLOv3 的推理时间。
2.2.2 特征变换对比
实验进一步对比了添加特征变换前后的ShuffleNetv2-YOLOv3 方法和本文方法,如表2 所示。
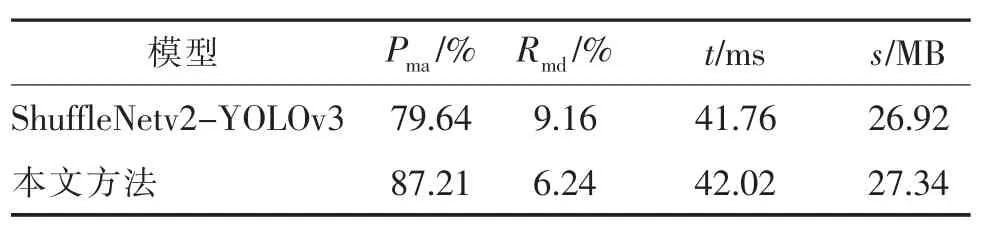
表2 特征变换结果对比Tab.2 Results comparison of feature transformation
从表2 可以看出,通过特征变换,本文方法增强了对物体检测能力,相较于ShuffleNetv2-YOLOv3有着更高的平均精度均值和更低的漏检率,仅增加了很少的检测时间。
2.2.3 轻量型模型对比
为了验证模型在移动端上的性能,我们将本文方法和最新的几个轻量级YOLOv3 模型(YOLOv3-Tiny 和MobileNetV2-YOLOv3)在Nvidia 移动端设备Jetson TX2 上进行测试,实验采用之前的测试集,输入模型图像大小为384×384,实验结果如表3 所示。

表3 轻量级模型结果对比Tab.3 Comparison of results on lightweight models
从实验结果可以看出,本文方法在平均精度均值和漏检率上都优于另外两个模型。本文方法的单张图像检测时间和MobileNetV2-YOLOv3、YOLOv3-Tiny 相当。综合平均精度均值、检测速度和漏检率,本文方法在速度相当的情况下,平均精度均值较高,更适合应用于实际移动端的识别。虽然本文方法相较于其他轻量型模型具有较高的平均精度均值和较低的漏检率,但针对模糊图片中交通信号灯的误检率和漏检率较高。一方面因为模糊图片在训练数据集中包含较少,模型对这种情况学习不够充分;另一方面因为本文模型为轻量级模型,参数量较少,对各种复杂场景的适应能力还需提高。
2.2.4 检测结果对比
不同轻量级YOLO 模型的信号灯检测结果对比如图5 所示。其中,图5(a)是原图像,图5(b)为YOLOv3-Tiny 检测结果,图5(c)为MobileNetV2-YOLOv3 检测结果,图5(d)为本文的LW-YOLOv3检测结果。从检测结果可以看出:本文的轻量级YOLOv3 相较于其他3 个轻量级YOLOv3 模型,漏检率较低,对图像中较远的交通信号灯也可以检测到。YOLOv3-Tiny 漏检率最高,很多分辨率较低的交通信号灯未能检测到。

图5 不同轻量级YOLOv3 模型检测结果对比Fig.5 Comparison of detection results of lightweight YOLOv3 models
3 结论
本文提出了一种改进的基于ShuffleNetv2 的轻量级YOLOv3 模型,实现交通信号灯的检测与识别。算法将YOLOv3 的主干替换为ShuffleNetv2 并改进ShuffleNetv2 的网络结构,通过融合来自低、中、高层的特征组成高层的输出特征,不仅增加了交通信号灯的特征,也使得YOLOv3 多尺度预测的特征图中具有更丰富的交通信号灯信息。LaRa 数据集上的实验表明,本文方法的平均精度均值达到87.21%,虽然比YOLOv3 的精度有所下降,但检测速度是YOLOv3 的3 倍,同时模型大小仅为YOLOv3 的1/8。移动端设备Jeston TX2 上的实验结果表明,本文方法在检测速度相当的情况下,平均精度均值明显高于其他轻量级YOLOv3 模型。
目前交通信号灯信息的自动获取主要通过车路协同和交通信号灯检测识别等技术实现。车路协同技术依托先进的无线通信和新一代互联网等技术,主动将红绿灯信息发送给车辆,避免了环境、天气等因素的干扰,然而这种新型技术尚未成熟,目前还未能大范围落地使用,而且其对通信要求高、存在延迟等问题。而作为单车智能的交通信号灯检测识别,特别是基于深度学习的交通信号灯检测识别方法具有延迟小、实现方便、主动感知等特点,适用于没有路测感知的场合,然而也存在感知死角等问题。因此,在未来的发展过程中,这两种技术将互为补充,鲁棒地获取交通信号灯信息。
