基于K-means 划分区域的深度学习空气质量预报
2021-10-13徐爱兰朱晏民於香湘彭小燕
徐爱兰,朱晏民,孙 强*,於香湘,彭小燕
(1.南通大学 信息科学技术学院,江苏 南通 226019;2.江苏省南通环境监测中心,江苏 南通 226006;3.南通市气象局,江苏 南通 226006)
近年来,随着工业化与城市化进程的不断加快,空气污染问题也越发严重。空气污染会对公众的日常生活造成负面影响,甚至会引发一系列健康问题[1-3]。开展环境空气质量预报工作是保障及时妥善应对重污染天气的重要技术手段,对区域大气污染联合减排也具有指导意义。
现有的空气质量预报方法主要有数值分析法与统计分析法。然而,数值预报法通常需要准确的输入数据和昂贵的计算资源来进行空气质量预报;而统计预报法对于非线性变化的污染物浓度预报准确性较低[4]。目前通过人工智能、机器学习等方法实现环境空气质量预报已成为各国环保领域的研究热点和发展趋势[5-6]。文献[7-8]分别采用时空极值学习机算法和Light-BGM 方法研究PM2.5浓度。深度学习方法是近年来新兴的一种机器学习算法,通过对大量数据的学习训练,发现其中的内在特征,从而提升分类或者预测的准确性。主流的深度学习方法包括卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、长短期记忆网络(long short-term memory,LSTM)模型及各种模型相结合的方法[8-9]。已有国内外研究学者提出将深度学习模型应用于空气质量预报领域[10-13]。目前主流的混合深度学习模型由CNN 和LSTM 组成,可以提取出训练数据的时空特征[14-17]。Huang 等[18]以北京市为案例,通过对过去24 h PM2.5浓度与气象数据进行训练分析,给出未来1 h 的PM2.5浓度预报,但该方法并未考虑到站点间的空间相关性问题。
空气污染物浓度的变化会受到空间因素[18]与气象因素[19-21]的影响。为精准预报空气污染物浓度,模型通过输入其他监测站点的历史数据,从而分析污染物的空间演变特征。然而,输入空间相关性较强的监测站点数量难以确定。如果模型输入的监测站点数量较少,会导致模型分析污染物空间演变特征不够充分;反之,如果模型输入的监测站点数量过多,会增加对于空间相关度较低的站点的不必要分析,导致模型的运算量显著提升,影响污染物预报的准确性与时效性。此外,如何设计CNN-LSTM 模型,从而对空气污染物进行空间与时序分析,仍是研究学者面临的难题。
基于上述分析,本文提出一种基于K-means 划分区域的CNN-LSTM 空气质量预报方法。使用Kmeans 方法对各空气质量监测站点进行区域划分,并使用最小均方误差与轮廓系数两项指标判定划分区域数量。将划分区域内的监测站点污染物数据和气象数据通过CNN-LSTM 混合深度学习网络训练学习,该网络使用CNN 模型提取出污染物浅层时序特征与空间特征,再使用LSTM 模型对这些特征进行深层次的时序提取,同时对气象数据进行分析,得到污染物的时空特征。在基于单站点的时均预报实验中,CNN-LSTM 模型体现出比LSTM 模型更优异的性能。在使用混合模型的基础上,进一步加入由K-means 划分区域内其他监测站点的历史污染物浓度数据,能够更充分地发挥出CNN-LSTM模型提取污染物时空变化规律这一特性。实验表明,基于多站点数据的CNN-LSTM 模型能有效提高污染物浓度的预报精度。
1 研究方法
本文设计的基于K-means 划分区域的CNNLSTM 空气质量预报框架如图1 所示,主要包括区域划分和模型预报两个部分。在区域划分步骤中,本文使用K-means 聚类算法对各空气质量监测站点进行区域划分,并在模型预报部分,选用目标站点所在区域内所有站点的污染物历史数据,结合气象数据作为CNN-LSTM 模型的输入,从而给出目标站点的污染物浓度值预报结果。

图1 基于K-means 划分区域的CNN-LSTM空气质量预报框架示意图Fig.1 Structure of CNN-LSTM air quality forecast with divided area based on K-means
1.1 K-means 聚类方法
K-means 聚类算法是一种常见的无监督机器学习方法,通过对样本集进行全局分析,划分成为不同的簇。由于每个簇内的样本特征相似,簇间样本特征相异,使用K-means 聚类算法可以确定与目标监测站空间相关性较强的相邻站点。本文根据空气污染物监测站的地理位置划分区域,因此选择监测站的经度与纬度的归一化值作为K-means 聚类的输入,从而进行空间划分。
假设有样本集D={d1,d2,…,dm},其中每个样本代表监测站点坐标di=(yi,zi),yi为第i 个监测站点的经度,zi为第i 个监测站点的纬度,样本集D 共计包括m 个站点样本。在进行K-means 聚类前,首先对所有站点的坐标进行归一化,假设横坐标集合Y={y1,y2,…,ym},纵坐标集合Z={z1,z2,…,zm},坐标归一化公式为
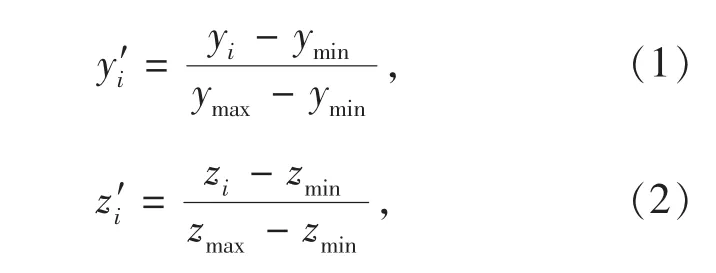
其中:ymax为集合Y 中的最大值;zmax为集合Z 中的最大值;ymin为集合Y 中的最小值;zmin为集合Z 中的最小值;yi、zi为原始值;为归一化后的值。经过归一化后的监测站点坐标di=(y′i,z′i)。
假设划分为k 个簇C={C1,C2,…,Ck},则Kmeans 算法步骤如下:
1)从样本集D 中随机选择k 个样本作为初始聚类中心{μ1,μ2,…,μk};
2)依次计算样本集中的每个点到各聚类中心的欧氏距离λij=‖di-uj‖2,分配至最近的聚类中心,从而得到k 个簇;
4)重复步骤2)与步骤3),直至聚类中心不再变化。
K-means 聚类算法中最关键的部分是确定k值,评价聚类质量有效性的指标误差平方和(sum of the squared errors,SSE),定义如下:

SSE 的值越接近0,说明样本分类效果越好。当k 小于最佳聚类个数时,随着k 增加每个簇的聚合度会明显增加,SSE 会迅速下降;当k 大于最佳的聚类数目时,每个簇的聚合度增加速度会放缓,SSE下降会趋于平缓。因此,最佳聚类数为SSE 迅速下降转为平缓下降所对应的k 值。但面对SSE 下降趋势转变不明显的情况时,需要引入轮廓系数(silhouette coefficient,SC)作为另一项判定聚类质量有效性的指标,样本集D 第i 个样本的SC 定义为

其中:a(i)为第i 个样本到同簇其他样本的平均距离;b(i)为第i 个样本到距离最近簇Cj中样本的平均距离。最近簇Cj定义为
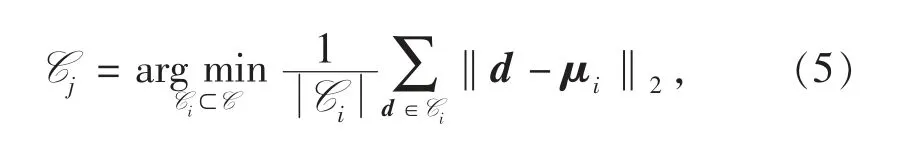
整个样本集D 的SC 为
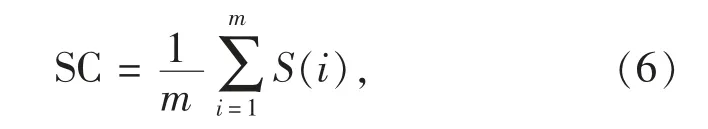
其中SC 的取值范围为[-1,1],SC 越接近于1,说明聚类质量有效性越好。
1.2 CNN-LSTM 混合深度学习模型
本文选用的深度学习模型为CNN 与LSTM 相结合的模型,其模型结构如图2 所示。其中CNN 模型用于对历史污染物浓度数据进行分析,得出污染物的空间演变特征;LSTM 模型用于将CNN 模型提取得到的特征进行更深层次的时序特征提取,同时结合历史气象数据进行分析。最终经过全连接层计算,得出污染物的时空特征。

图2 CNN-LSTM 模型架构示意图Fig.2 Structure of CNN-LSTM model
1.2.1 CNN 模型
为直观显示CNN 模型卷积运算过程,图3 给出了二维CNN 模型运算示意图。与全连接层计算特征的方式不同,卷积核通过稀疏连接的方式,使用数量远小于输入数据量的权重计算输入数据的特征,从而降低了CNN 模型的参数数量,不仅降低了模型计算复杂度,还能提高模型的泛化性能。
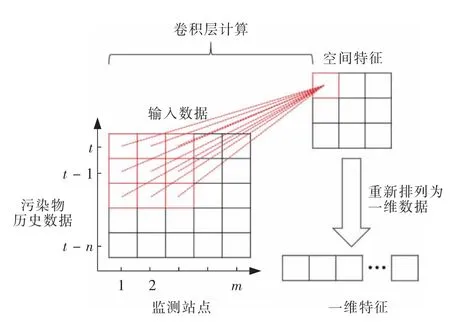
图3 CNN 模型结构示意图Fig.3 Structure of CNN model
以图3 为例,该示意图仅考虑使用1 个卷积核进行运算的情况。假设输入数据为1 个5 × 5 的二维矩阵,其中横坐标代表监测站点,纵坐标代表污染物的历史浓度数据,共计25 条输入数据。假设卷积层中卷积核的尺寸为3 × 3,经过一次卷积运算后,可以得到1 个空间特征。假设卷积核移动的步长为1,则经过卷积核自左向右,自上而下共9 次运算后,可以提取得到9 个空间特征。最后重新排列为一维特征以输入至LSTM 模型。此外,通过增加卷积层及卷积核的方式,更多的特征会被提取。
1.2.2 LSTM 模型
LSTM 模型由多个子单元组成,1 个LSTM 单元的结构如图4 所示,由遗忘门ft、输入门it、输出门ot、输入节点gt及输出节点ct组成。xt代表LSTM 单元在t 时刻的输入,ht则作为单元在t 时刻的输出,ct代表t 时刻的LSTM 单元状态,定义如下:

图4 LSTM 模型结构示意图Fig.4 Structure of LSTM model
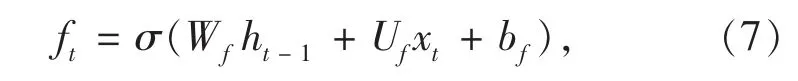

其中:Wf、Wi、Wg和Wo是循环权值;Uf、Ui、Ug和Uo是输入权值;bf、bi、bg和bo是偏权值;⊙表示阿达玛积;σ 和tanh 为激活函数。在遗忘门、输入门和输出门共同工作的情况下,相较于CNN 与RNN 模型,LSTM 模型可以处理长期时间特征的预测任务。在本文提出的CNN-LSTM 模型中,LSTM 模型的输入xt为t 时刻的气象数据与t 时刻CNN 模型提取得到的空间特征,从完成更深层次的污染物浓度时空特征中提取。
2 实验结果与分析
本文选取南通市作为研究案例城市,研究目标站点为虹桥站点,该实验方案可以拓展到其他更大的预测范围。实验分为两个部分:第一部分为基于K-means 的区域划分实验,对南通市各空气质量监测站点进行空间聚类分析以划分区域;第二部分为基于CNN-LSTM 模型的污染物浓度预报实验,使用CNN-LSTM 模型分别进行基于单站点与多站点污染物历史数据的性能评估。
实验选取的污染物为PM2.5,污染物详细数据信息如表1 所示。气象数据包括时均气压(hPa)、气温(℃)、相对湿度(%)、风速(m/s)、风向及降水量(mm),其中风向为量化指标,根据16 个方向,分别对应16 个量化值。本实验污染物数据由江苏省南通环境监测中心提供,气象数据由南通市气象局提供。
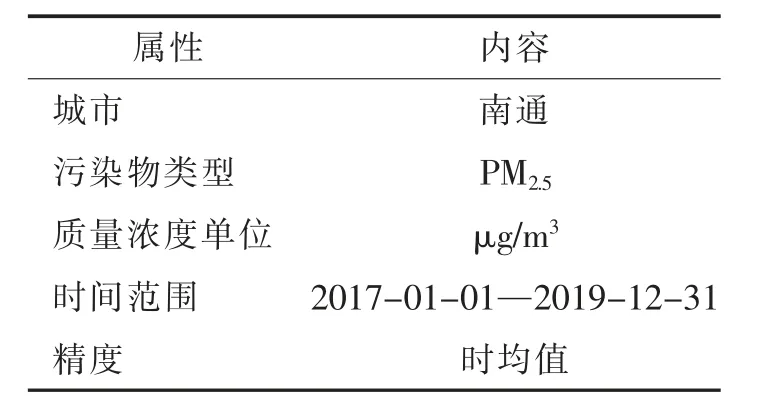
表1 污染物数据信息Tab.1 Data Information of Pollutant
2.1 基于K-means 的区域划分
本文使用K-means 方法对南通市“十三五”期间19 个空气质量监测点位进行空间上的区域划分。表2 为南通市19 个空气质量监测站点的经纬度数据,将各监测站点经度与纬度进行归一化处理后,作为K-means 聚类算法的输入属性。

表2 南通市各空气质量监测站点经纬度Tab.2 Latitude and longitude of air quality monitoring stations in Nantong
在使用K-means 方法进行区域划分前,首先需要确定聚类分类数。为此本文选用误差平方和SSE与轮廓系数两项聚类评价指标对聚类质量有效性进行判定,从而选取最佳的分类数。
当选择不同k 值时,SSE 的变化曲线如图5(a)所示,k 的取值范围为[1,12]。从图5(a)中可以看出,当k <4 时,SSE 下降趋势明显;当k >4 时,SSE下降趋势放缓,但未能与k <4 时SSE 曲线的下降趋势表现出明显变化,需要引入轮廓系数SC 作为另一项判定聚类质量有效性的指标。
图5(b)为SC 随聚类分类数k 变化的曲线,k的取值范围为[2,12]。由图5(b)可知,当k=8 时,SC 取得最大值,但此时会出现1 个分类簇内只有1个样本的情况。考虑到不同空气质量监测站点之间的影响,需要保证每个分类区域内至少有2 个站点,因此实验最终选择聚类分类数k 为7。图6 为基于K-means 的区域划分结果,表3 为南通市各空气质量监测站点所对应的区域。本文选择南通市崇川区虹桥空气质量监测站点作为研究站点,经Kmeans 划分区域后归为区域2,因此在验证CNNLSTM 模型性能的实验中,选用区域2 内所有站点的污染物历史数据作为CNN 模型的输入,共计5 个站点:城中子站、虹桥、南郊、星湖花园、紫琅学院。

表3 各空气质量监测站点所对应的区域Tab.3 The area of each air quality monitoring station

图5 SSE、SC 随聚类分类数k 变化的曲线图Fig.5 SSE、SC with cluster number k
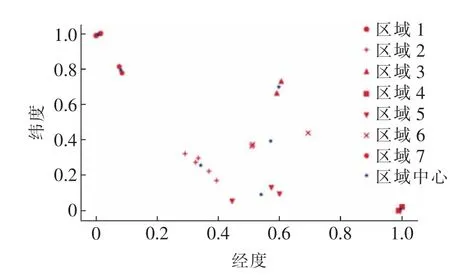
图6 基于K-means 的区域划分结果Fig.6 Result of division areas based on K-means
2.2 基于多站点的CNN-LSTM 污染物浓度预报
由2.1 节分类结果可得,在多站点模型中,污染物浓度数据选择城中子站、虹桥、南郊、星湖花园、紫琅学院共计5 个站点2017 至2019 年PM2.5浓度历史时均数据。在单站点模型中,污染物浓度数据仅选择虹桥一个站点历史数据。为保证数据整齐便于CNN-LSTM 模型分析,当出现某一时刻某站点污染物浓度数值缺失情况时,则删除其他站点与气象数据同时刻的数值,最终得到时均值共计25 236 条。
本实验选取2017-01-01—2019-11-30 的数据作为自训练数据,选取2019-12-01—2019-12-31数据作为预报测试数据,针对虹桥空气质量监测站点时均PM2.5浓度进行预报。所有模型的输入为过去24 h 的PM2.5污染物浓度与气象数据,预报结果为未来6 h 的PM2.5污染物浓度。将时间序列数据转化为模型训练样本后,最终得到训练样本共24 502个,测试样本共705 个。实验中模型超参数的设置如表4 所示。

表4 实验中模型超参数的设置Tab.4 Hyper parameters for all experiments
为评价模型的预报性能,本文使用均方根误差(root mean square error,RMSE)与平均绝对误差(mean absolute error,MAE)两种回归评价指标及相关系数(correlation coefficient,Corr)作为衡量模型预测性能的指标。给定真实观测值集合O={o1,o2,…,oi}及预报值集合P={p1,p2,…,pi},RMSE、MAE、Corr 的定义如下:

其中:n 为测试集样本数量;oi为第i 个样本点实际污染物浓度;pi为第i 个样本点模型预报所得污染物浓度;D[O]与D[P]分别为观测集合O 与P 的方差。当RMSE 与MAE 的值越小时,说明模型预报与真实值越接近,预报性能越好。相关系数Corr 取值范围为[-1,1],当Corr >0,说明2 个变量正相关,值越接近于1,说明相关性越强。
基于多站点与单站点的CNN-LSTM 模型仅在CNN 模型输入部分有所区别:基于多站点的CNN模型部分为二维卷积,分析多站点历史数据;基于单站点的CNN 模型为一维卷积,同时分析单站点的历史数据和气象数据。表5 为基于不同模型的时均值预报结果对比,可以看出,在基于单站点的预报实验中,CNN-LSTM 模型预报结果的RMSE 与MAE 均略高于LSTM 模型,说明CNN 模型无法从中提取出空间方面的演变特征,导致预报误差有所扩大。在采用多站点数据进行训练后,得益于CNN模型的空间特征提取能力,CNN-LSTM 模型的预报性能得到了提升,优于基于单站点LSTM 模型。从相关系数方面来看,基于多站点的CNN-LSTM 模型给出的预报结果,均比其他模型显示出与实测值更高的相关性。

表5 基于不同模型的时均值预报结果对比Tab.5 Model comparison between forecast results of hourly average value
图7—9 分别为各模型时均预报结果与实测值的对比,所有模型预报值均与实际值的趋势保持一致,但预报结果整体上低于实测值,此外对于出现污染物浓度骤增、骤减情况时,CNN-LSTM 模型给出的预报结果均有一定的滞后,这是深度学习模型训练样本特征长度固定所导致出现的情况。由于深度学习模型是通过对过去一段时间的污染物浓度值进行计算,从而给出未来污染物浓度。而且深度学习模型具有一定的泛化性,能够同时对污染物浓度较高或较低的情况给出预报结果,因此当模型输入为一段数值变化较小的污染物浓度时,给出的结果往往较为精确;但遇到污染物浓度骤增、骤减情况时,模型仍然误以为未来污染物浓度变化不大,给出的预报结果与实际有较大误差。尽管基于多站点的CNN-LSTM 模型会存在一定的预报滞后性,但面对重污染天气时给出的预报数值,比基于单站点的CNN-LSTM 模型更加接近真实值。在误差指标方面,与单站点CNN-LSTM 模型相比,RMSE下降了5%,MAE 下降了6%。因此,加入K-means划分区域的多站点数据后,CNN-LSTM 模型能有效提高污染物浓度的预报精度。

图7 基于单站点的LSTM 模型时均预报结果Fig.7 Hourly average forecast results of LSTM model based on single station
此外,考虑到模型的时间复杂度问题,进一步统计不同模型进行一次训练所需的时间,训练使用GPU:NVIDIA GeForce GTX 1050Ti。基于单站点的LSTM 模型训练一次需要27 s,而基于单站点的CNN-LSTM 模型的主体部分为LSTM 模型,CNN 模型参数不足LSTM 模型的1%,因此加入CNN 仅增加1 s 模型训练所需时间。而基于单站点和多站点的CNN-LSTM 模型仅存在CNN 模型部分一维卷积与二维卷积的区别,训练一次所需时间均为28 s。
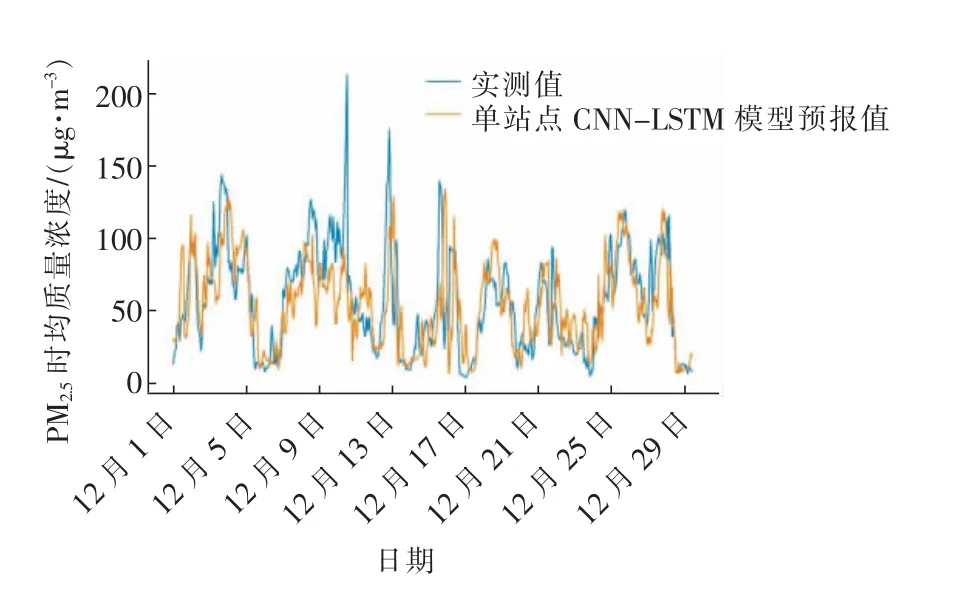
图8 基于单站点的CNN-LSTM 模型时均预报结果Fig.8 Hourly average forecast results of CNN-LSTM model based on single station
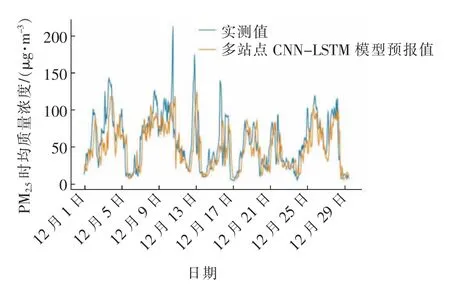
图9 基于多站点的CNN-LSTM 模型时均预报结果Fig.9 Hourly average forecast results of CNN-LSTM model based on multiple stations
3 结论
为精准预报空气污染物浓度,综合考虑污染物浓度受空间与气象因素的变化规律,本文提出使用K-means 方法选择监测范围内空间相关性较强的多个监测站点。在此基础上,设计基于多站点的CNNLSTM 模型,结合所选的多站点空气质量历史数据与气象数据,以分析污染物浓度演变的时空趋势,给出精准的空气质量预报结果。通过对南通市各监测站点进行区域划分,分别对LSTM 和CNN-LSTM 进行了单站点和多站点数据训练与预测实验。实验结果表明,基于K-means 划分区域的CNN-LSTM 空气质量预报方法在PM2.5浓度预报精度上优于传统单站点模型。
