基于位置降噪和丰富语义的电子病历实体关系抽取
2021-10-12李丽双袁光辉刘晗喆
李丽双,袁光辉,刘晗喆
(1. 大连理工大学 计算机科学与技术学院,辽宁 大连116024;2. 辽宁省肿瘤医院(中国医科大学肿瘤医院) 重症医学科,辽宁 沈阳 110042)
0 引言
电子病历文本中含有丰富的临床医学信息,从中抽取实体之间的关系是一项重要任务,可以为临床数据库的构建、医学知识图谱生成和临床辅助决策等提供数据支持。目前,电子病历文本中实体关系抽取的研究大多数是句子级的,主要研究从电子病历中抽取疾病、检查和治疗这几类实体间的关系。
应用于电子病历领域的实体关系抽取方法主要有三种。早期,研究者使用的是基于规则的方法。例如,Harkema等[1]提出一种上下文算法,该算法首先获取出现在上下文中的词法线索,然后依据此词法线索推断临床报告中提到的临床条件状态,对于包含给定条件的临床报告,该算法取得了很好的效果。基于规则的方法主要依赖专业人员制定的规则抽取信息,但实际运用中研究人员往往难以归纳出所有的语法和规则,所以性能一般较差。随着机器学习技术的不断发展,利用浅层机器学习技术进行电子病历文本实体关系抽取的方法[2-5]逐渐增多。这些方法主要依赖于手工构建的一些特征,如词汇、语境、词位置信息、块标记等。例如,Rink和Harabagiu[3]采用SVM的方法,首先利用词汇、标记和相关领域的语料资源构建特征,然后将构建的特征用SVM进行实体关系分类,该方法在 2010年i2B2/VA关系分类的挑战赛中取得了最好成绩。基于浅层机器学习的方法,过于依赖人工构建的特征,且这些特征需要外部自然语言处理工具生成,如词性标注和句法分析工具等,因此,模型性能受外部因素影响较大。相比之下,基于深度学习的方法可以利用模型自动学习特征的构建,且在电子病历关系抽取任务中取得了较好的性能。例如,He等[6]先利用电子病历领域语料训练得到词向量,然后将词向量送入多窗口的卷积神经网络(Convolutional Neural Networks,CNN) 提取特征,最后结合添加了类别约束的损失函数训练模型,在2010 年 i2B2/VA 关系抽取语料上F1值达到了69.7%。Raj等[7]提出了一种基于双向长短时记忆 (Bi-directional Long-Short Term Memory,BiLSTM)和多层池化的模型,模型首先利用BiLSTM 编码句子信息,对编码后的信息以最大池化的方式抽取实体相关词特征,然后将池化后特征送入CNN 模型抽象出更高维特征,并对此高维特征再次以最大池化的方式过滤,最后将过滤后的特征送入全连接层做分类,在2010年i2B2/VA关系抽取语料上F1值为 64.38%。
基于深度学习的方法虽然能够自动学习构建特征,但是构建特征的质量容易受到词向量的影响,而电子病历领域由于可用训练语料缺少且文本半结构化,文本所含专业词汇较多等领域特性,使病历文本的语义不能有效表达。例如,“ID-afebrile, no wbc, started on Azithromycin for COPD flare”,类似的病历文本会使词向量训练难度增大,过多的专业词汇也使得通用领域的词向量不能被有效使用。因此,当前的深度学习模型应用在电子病历领域的效果并不是很好。
Li等[8]和Luo等[9]通过引入 MIMIC-III[10]临床医学数据扩充词向量的训练语料,在一定程度上缓解了语料不足问题,但由于医学领域知识的丰富性,病历文本中的医学实体仍不能被有效地表示。事实上,实体之间关系的判断往往不依赖于某些专业词汇及实体本身的语义,而是取决于实体所在上下文中与实体相关的常用词。例如,“Her pain was under good control with PO pain medications and she was deemed suitable for discharge”。其中,“Her pain”是“problem”类型的实体,“PO pain medications”是“treatment”类型的实体,实体之间的关系类型是 TIP(treatment 改善了 problem),通过关键词“was under good control”就可准确判断出上述实体之间的关系。综上所述,如何找出与实体相关的常用词,从而引入通用领域语料的丰富语义,是解决电子病历领域词表示匮乏的更好方法。
实体在句子中的位置信息对实体关系的判断至关重要。目前,对实体位置信息的利用方法主要有两种: ①根据实体位置找到实体边界对句子分段,如Zeng等[11]和Li等[12]等; ②构造每个词与实体的相对位置向量,如 Cai等[13]和Gehring等[14]等。根据实体位置对句子分段的方法使用实体位置信息的粒度过粗,不能在词粒度上使用;第二种方法实现了更细粒度上实体位置信息的利用,但词相对位置向量引入了自身所包含的噪声信息。位置向量由多维特征组成,其与词向量的生成是独立的,直接与词向量结合后会产生噪声,影响模型对词语义的识别。一个词的位置向量衡量的是该词在距离上与实体的相关程度,因此位置向量可以由词向量线性表示,即可以将位置向量转化为词向量的权重分数,从而降低位置向量噪声对词向量的影响。然而,在一句话中,距实体相同位置的词因为其本身词义和上下文环境的不同,与实体的相关程度是不同的,距离信息不能直接转为词权重。
基于上述问题,本文提出一种基于位置降噪和丰富语义的电子病历实体关系抽取模型。模型首先将位置向量与电子病历领域语料训练的词向量拼接送入BiLSTM,利用BiLSTM将位置信息与词语义信息融合;然后对融合后的信息通过注意力机制计算词与实体的相关度作为词的权重,再将权重与大规模通用领域语料训练的词向量结合,从而实现位置向量降噪和通用领域语料丰富语义的引入;最后采用CNN提取相关词特征进行实体关系类别的判断。在2010年i2B2/VA关系抽取语料上的实验结果表明,本方法可有效地引入外部语料的丰富语义并降低位置向量噪声对模型的影响,F1值为76.47%,达到了目前先进水平。
1 方法
本文提出一种基于位置降噪和丰富语义的实体关系抽取模型,模型架构如图1所示,主要包括以下部分。

图1 模型架构
(1) 输入层: 预处理后的电子病历领域语料。
(2) 嵌入层: 转换输入层语料为向量表示。
(3) 注意力层: 计算每个词到实体的向量投影,然后将此投影向量与实体向量模的比值作为词与实体的相关分数,最后将词与两个实体的相关分数做乘积得到该词的最终权重,通过此权重实现位置向量降噪和通用领域语料丰富语义的引入。
(4) 特征编码层: 利用CNN 和映射层提取相关词特征。
(5) 输出层: 根据提取到的特征判断实体关系类别。
下面介绍模型的实现细节。
1.1 输入层
输入层为预处理后的电子病历文本语料。在病历文本中,一句话可能包含多个实体,每个实体可能参与多个关系,例如,“cxr no focal consolidation or edema, old biapical scarring ABG 7.34/79/74 U / A negative”,其中,“cxr”和“ABG”是“test”类型的实体,“edema”和“old biapical scarring”是“problem”类型的实体,实体“cxr”与实体“edema”的关系是“TeRP”(测试显示出医疗问题)。为了能够更准确地判断每一个实体可能与其他实体存在的关系,本文在实体类型的约束下将实体两两配对,分别对每一组实体进行关系识别。进一步考虑,电子病历中的实体大部分是由多个单词组成的,且实体语义对实体关系的判断影响不大,因此本文将实体直接替换成实体类型,这样也便于计算跟实体相关的词的权重。例如,上句话替换“cxr”与“edema”后为“Test no focal consolidation or problem, old biapical scarring ABG 7.34/79/74 U / A negative”,将替换后的句子作为模型的输入。
1.2 嵌入层
嵌入层的作用是将输入层的语料转换为向量表示,共包含两种表示方式。第一种是将电子病历领域语料训练的词向量和位置向量拼接,用于词的注意力权重计算。词向量的训练采用Word2Vec[15]的方法, 位置向量由不同频率的正弦和余弦函数生成[16],如式(1)、式(2)所示。
其中,PE为位置向量编码矩阵,pos表示词与实体相对位置,p为位置向量的维度,l表示位置向量的位置,奇数位置添加余弦变量,偶数位置添加正弦变量。虽然领域语料训练得到的词向量语义表示不够丰富,但是词向量之间的语义关联性更高,更容易获取词之间的依赖关系。这里将位置向量和词向量结合是为了学习到词在位置上与实体的关联信息。设原句子序列中词的嵌入向量表示分别为X={x1,x2,…,xi,…,xn},xi∈Rd+2p为句子中第i个词的嵌入向量表示 (i∈[1,n]),n为句子长度,d表示词向量的维度。第二种嵌入向量表示方式是采用来自网络爬虫获得的通用领域语料训练的词向量(840B标记,2.2M词汇),用于词特征提取。设原句子序列中的词向量分别表示为S={s1,s2,…,si,…,sn},si∈Rk为句子中第i个词的向量表示(i∈[1,n]),k表示词向量维度,n表示句子长度。
1.3 注意力层
注意力层计算句子中每个词与两个实体之间的语义相关度,找出与实体相关的常用词。首先将电子病历领域语料训练的词向量和位置向量拼接送入BiLSTM,编码句子信息。BiLSTM由三个门控单元组成,可以有效减弱长序列的梯度消失和爆炸,学习长距离词之间的依赖信息。ht(f)和ht(b)表示t时刻BiLSTM的前向和后向输出,ht= [ht(f),ht(b)]作为最终输出。
ht(f)=BiLSTM(ht-1,xt)
(3)
ht(b)的计算方式同ht(f),区别是ht(b)的计算方向是反向的,得到ht之后对BiLSTM的隐藏层输出通过注意力机制计算词与实体的相关度。衡量两个向量相关度的计算方式有余弦相似度、皮尔逊相关系数等,本文基于余弦相似度先计算出词与实体隐层输出向量的余弦夹角,并在此基础上考虑向量的模大小,使用词对应的隐层输出向量到实体对应隐层输出向量的投影与后者模的比值作为词与实体的相关分数,总体计算如式(4)、式(5)所示。
(4)
αt=ft(1)*ft(2)
(5)
通过上述的注意力机制,综合词语义信息和词与实体的相对位置信息,将之转化为词权重,再将词权重与不含位置信息的初始词向量相乘,得到加权的词向量,这样既不会改变词向量的分布,又可以有效利用位置信息,以权重的方式实现位置向量降噪。此时的权重也标识了词对实体关系判断的贡献度大小,权重大的词对实体关系判断贡献度比较大,且一般是常用词汇,可以用通用领域语料训练的词向量表示,由此可引入通用领域语料的丰富语义。设原句子序列中的词权重分别表示为α={α1,α2,…αi,…αn},αi为一个实数,表示第i个单词的权重,用式(6)计算特征编码的输入:
U=S·α
(6)
其中,“·”表示词向量与其对应的词权重相乘,S为通用领域语料训练得到的词向量,U即为特征编码部分的最终输入。
1.4 特征编码层

1.5 输出层
输出层的作用是将批正则化后的隐藏层β作为最终特征表示送入全连接层做分类。输出结果y属于c(c∈C) 种类型的概率P(y=c),如式(9)所示。
P(y=c)=softmax(Wβ·β+bβ)
(9)
其中,Wβ和bβ为权重矩阵和偏置,全连接层的激活函数为softmax,C为实体关系类别的集合,之后取最大概率的标签c作为最终类别。
2 实验
2.1 实验数据集
实验所用的数据集采用的是2010年i2B2/VA临床关系抽取语料,原始数据集共包含871份标注语料,本文使用的是部分数据集,共426 份,其中,训练集170份,测试集256份。数据集关系类别说明如表1所示。

表1 数据集关系类别说明
2.2 实验设置
在本文的模型中,优化方法为Adam,使用交叉熵损失函数,为了更好地训练和验证模型,和大多数方法一样,本文把训练集和测试集放在一起做了五折交叉验证。电子病历语料训练的词向量维度是200,位置向量维度是50,BiLSTM单向隐层大小为128,通用领域语料训练的词向量维度是300,CNN采用一维卷积,有四个窗口,窗口大小从1到4,通道数为64,隐藏层大小为32,batch为128,学习率为0.001。
2.3 实验结果与分析
为了验证所提出方法的有效性,本文做了多个对比实验。
2.3.1 消融实验
此模块的设计,必须充分调研各类用户的可能需求情况,利用关系数据库系统技术中的视图原理,设计出不同用户的不同数据处理模式即子模式。同时,在具体各子模式中对数据的查询与处理过程,还可以利用关系数据库系统中提供的诸如数据统计、求和、求最大值、求最小值等函数功能以及关系数据库合并等算法来实现对已有数据、知识的重组,对关联知识的挖掘等增值服务功能。
如表2所示,模型基线是将专业领域语料训练的词向量拼接位置向量做输入,然后将BiLSTM的输出直接送入CNN提取特征,这里的专业领域语料是指i2B2/VA临床关系抽取语料。
从表2中结果可以看出:

表2 消融实验F1值 (单位: %)
(1) 加入位置向量降噪后,模型性能提升了 2.5%。位置向量降噪的实现是利用注意力机制将 BiLSTM的隐层输出转化为权重,然后将该权重应用于对应的专业领域语料训练的词向量(不含位置向量),最后将加权的词向量送入CNN提取特征。模型效果提升的主要原因是BiLSTM的隐层输出中包含着位置向量噪声,将其送入后续模型提取词特征时,位置向量噪声会影响模型对词语义特征的提取,从而降低模型的性能。而采用注意力机制将权重与专业领域语料训练的词向量结合后,模型只对添加权重后的词向量做语义识别,不会受位置向量噪声的影响,即使权重存在一定的偏差,也不会改变词向量的语义特征分布,而且后续词特征提取的模型可以减弱权重偏差带来的影响,因此模型取得了更好的结果。
(2) 语义引入后,模型F1值提升了3.47%,语义引入是将权重与对应的通用领域语料训练的词向量相结合。这里选用通用领域语料的原因有两个: ①通用领域可用训练语料比较充足; ②我们的目标是根据注意力机制选出的常用词汇来判断实体关系类别,通用领域语料训练得到的常用词汇的语义表示更加精确。虽然通用领域语料不能表示专业领域的某些专业词汇和符号,但是经过注意力机制的选取,与实体关系判断相关的常用词将被赋予更高的权重,因此模型可以提取到用于实体关系判断的丰富语义特征。图2显示了添加注意力机制后每个词的注意力权重分布,颜色的深浅表示注意力权重的大小。以第一句话为例,其中,“problem”和“treatment”表示处理后的实体,关键词“was”和“control”被赋予的权重最高,而通过这两个关键词,模型就可以很好地判别出两个实体的关系类型为“TrIP”。

图2 注意力权重分布
2.3.2 位置向量噪声分析
消融实验中添加了位置向量降噪的模型,虽然性能较基线模型有所提升,但是并不能直观地从实验结果中观察出位置向量是否含有噪声,为了验证位置向量噪声的存在性及其对模型性能的影响,本文做了以下实验,结果如表3所示。

表3 位置向量噪声实验F1值 (单位: %)
首先,假设位置向量不含有噪声,那么将注意力层得到的权重与含有位置向量的语义特征结合时,模型性能就不会因受到位置向量的影响而降低,所以,本文将注意力层得到的权重分别与专业领域语料训练的词向量、专业领域语料训练的词向量拼接位置向量、BiLSTM隐层输出结合,以观察模型性能。从表3的结果可以看出,位置向量含有噪声且会降低模型性能。
(1) 当权重与BiLSTM 输出结合时,模型性能最差,主要原因是BiLSTM在处理专业领域语料嵌入时,会将词向量和位置向量融合到一起,形成隐藏层输出,对于加权后的隐藏层输出,其不仅自身包含位置向量噪声信息,由此计算得到的权重也会存在一定的偏差,将之送入CNN提取词特征时,由于位置向量已经与词向量交互融合,模型对词语义特征的提取会受到位置向量噪声的影响,因此最终性能较差,F1值为70.22%。
(2) 当权重与专业领域语料嵌入结合时,模型性能有所提升。嵌入向量由专业领域语料训练的词向量和位置向量拼接而成,拼接后的向量前半部分仍是词向量的真实语义,且词向量与位置向量的相对位置是固定的,在CNN(一维卷积)模型的训练下,可以减弱后半部分位置向量对词语义特征提取的影响,因此模型性能更好,F1值为 71.90%。
(3) 权重直接与专业领域语料训练的词向量结合时模型效果最好,此时模型只提取加权后的词特征,不会受到位置向量的影响,F1值提升到73.00%。
综上可知,位置向量本身存在一定的噪声,将之直接运用于模型中时会降低模型性能。
2.3.3 BERT对比实验
BERT[17](Bidirectional Encoder Representation from Transformers)是一种预训练模型,其输出也可以被看作一种具有丰富语义的词向量。如表4所示,我们做了两组基于BERT的对比实验。

表4 BERT对比实验F1值 (单位: %)
第一组实验结果只用了BERT模型,将BERT对应两个实体位置的输出向量拼接,然后对拼接向量做分类。第二组实验是用BERT输出替换本文模型中通用领域语料训练的词向量,由此我们的模型可以引入BERT的丰富语义。从实验结果可以看出: ①只使用预训练模型BERT也可以取得很好的结果,最终F1值为82.03%; ②我们的模型在引入BERT的丰富语义后可以取得更好的结果,因为BERT输出的词向量是一种动态词向量,每个词的语义不是固定不变的,在不同的句子中有不同的含义,这样的表示更贴合句意。此外,用来训练BERT的语料更加丰富,所以其可以取得比通用领域语料训练的词向量更好的结果。
2.4 与现有结果的比较
本文将实验结果与相关工作做了对比,除Luo等[9]用的是全部数据集外,其他模型与本文所用数据集相同且用了五折交叉验证(表5)。
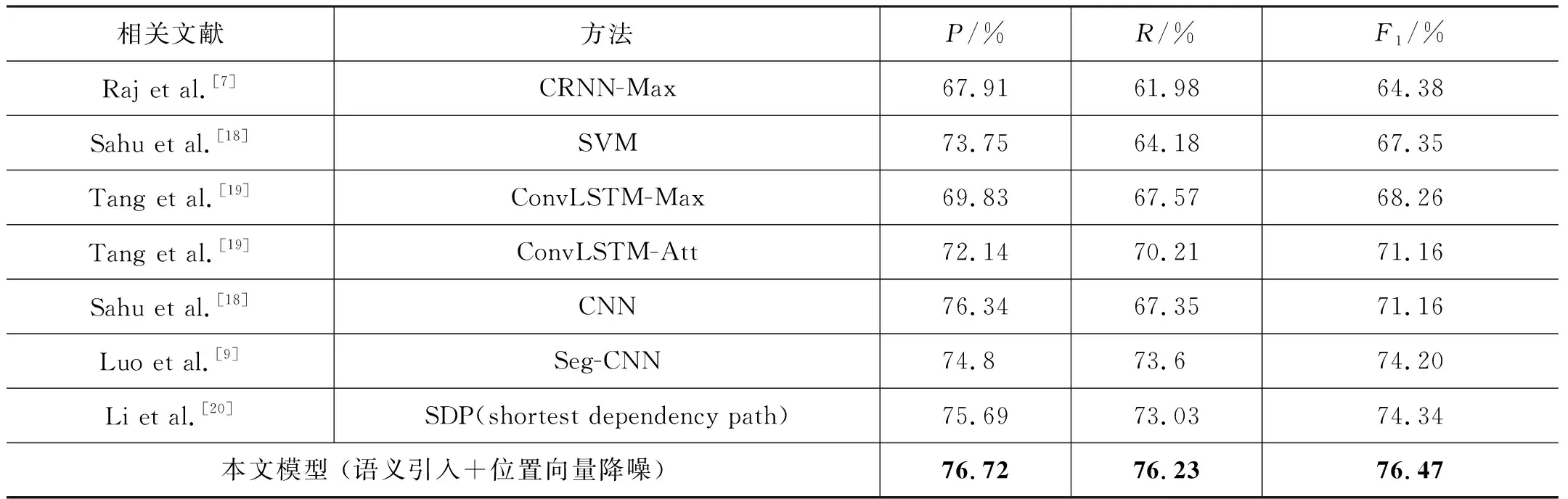
表5 对比实验结果
由表5所示,本文提出的方法性能最优,模型F1值达到76.47%。Raj等[7]使用不添加任何额外特征的词向量,通过 LSTM 和 CNN 结合并以最大池化的方式提取特征,最终F1值为 64.38%。Tang等[19]引入位置向量,将位置向量和词向量拼接,然后送入改进的长短时记忆网络,再经过多层注意力机制判断实体关系类别,最终F1值为 71.16%。Luo等[9]在添加位置向量的基础上引入 New York Times[18]和 MIMIC-III 语料训练词向量,使用分段 CNN 模型提取实体关系特征,在全部数据集上测试,最终F1值达到74.20%。与之相比,Li等[20]也利用了位置向量并引入 MIMIC-III 语料训练词向量,然后使用最短依存路径信息捕获实体相关上下文,使模型学习到语法特征,最终F1值达到74.34%。
本文模型利用词与实体相对位置信息生成位置向量,通过注意力机制提取位置与词的关联信息,再将之以权重的方式与初始词向量相结合,从而实现了位置向量降噪。在实现位置向量降噪的基础上,本文进一步引入通用领域语料训练的词向量,丰富电子病历文本的语义表示,模型的F1值达到76.47%,取得了当前的最优水平。
3 结论
电子病历领域的关系抽取任务对医疗知识图谱的构建、临床辅助决策、智能医疗问答等都有不可或缺的作用。在实体关系抽取任务中,位置向量有助于实体关系类别的判断,但也包含噪声信息,本文提出一种位置降噪方法,在利用位置信息的同时降低了噪声对模型性能的影响。而对于一些专业领域语料,由于词语义表示匮乏,本文提出了利用通用领域语料丰富语义的方法,丰富了词语义表达,在2010年i2B2/VA关系抽取语料上取得了目前最好的结果。综上所述,本文提出的方法改善了电子病历领域实体关系抽取的性能。
