融合知识图谱的NBA赛事新闻的自动写作
2021-10-12吉娜烨廖龙飞闫燕勤俞定国
吉娜烨,廖龙飞,闫燕勤,俞定国,张 帆
(1. 浙江传媒学院 智能媒体技术研究院,浙江 杭州 310018;2. 浙江大学 软件学院,浙江 杭州 310058)
0 引言
当下,新闻自动写作逐渐成为研究热点之一,国内外有很多媒体和机构通过研究新闻自动生成技术发布了自己的写作机器人。2014年美国洛杉矶时报的机器人Quakebot[1]在地震发生后的三分钟自动生成和发布了灾难新闻的报道。腾讯财经是中国第一家使用新闻写作机器人的媒体,他们开发的Dreamwriter[2]根据算法在第一时间自动生成稿件,瞬时输出分析和研判,一分钟内将重要资讯和解读送达用户。2015年11月新华社开始尝试使用新闻自动生成技术来进行写作,他们的“快笔小新”[3]能快速地生成一篇财经类的新闻。在2016年的里约奥运会上,今日头条通过使用Xiaomingbot[4]写稿机器人来实现奥运赛事新闻的自动生成。由此可见,新闻自动写作技术有着非常广泛的应用场景,但由于新闻种类繁多,且涉及到多个不同学科领域的交叉,现在还处于探索阶段。
当前新闻自动生成技术主要有三大发展方向,分别为模板式、抽取式、生成式[5]。结合模板的新闻生成方式是新闻生成技术中最为成熟的方法,它需要针对新闻中不同的内容自动选择对应的新闻模板生成新闻文本。新闻模板的构建一般由人工完成,这能在一定程度上保证生成新闻的质量。最近几年来出现了一系列在体育新闻这一特定类别新闻领域自动写作的代表性研究。Xu等[6]通过使用文本摘要算法从足球赛事文字直播中抽取重要句子来生成足球新闻。陈玉敬等[7]针对NBA文字直播数据中篮球比分变化特点,提出了一种篮球赛事新闻生成方法。Zhu等[8]基于条件随机场, 结合正向关键词和反向关键词, 抽取足球直播文本中的关键句, 自动写作足球赛事新闻战报。此外,针对足球新闻的自动写作,出现了一系列使用卷积神经网络技术自动生成新闻脚本的方法[9-12],此类方法本质上属于抽取式或生成式的自动文摘法。
目前关于知识图谱的相关研究已经非常普遍,国内外也有很多大型的开源知识图谱库,如Wikidata[13]、Freebase[14]、DBpedia[15]、CN-DBpedia[16]等。在运用方面,知识图谱最典型的应用是辅助搜索引擎提高搜索质量,如国外谷歌公司的Google Search,百度公司的“知心”。此外,知识图谱也可以运用到问答系统中,增强回答结果的精度。除搜索引擎和问答系统的应用外,最近也涌现了各种知识图谱在其他领域的研究探索,如情报学领域[17]、农业旅游领域[18]、药物发现领域[19]等。与新闻相关的知识图谱方面的研究和应用也有许多,例如,宋卿等[20]针对知识图谱技术在新闻领域中未来的应用分析;文献[21]尝试使用知识图谱来对新闻的真假进行检测;文献[22]应用知识图谱可以很好地提升文本摘要的效果。
综上所述,知识图谱在许多不同的领域均可发挥很大的作用,但应用于新闻自动写作的研究鲜有。此外,现有的大型开源知识图谱库基本都是通用型知识图谱,这些知识图谱库往往“广度”有余而“深度”不足,未包含更加深层次的信息,无法直接应用到特定领域中。所以针对NBA赛事新闻自动写作的特定应用,需要构建特定的知识图谱库,才能更有效地发挥作用。而知识图谱具有知识的检索方式,非常适合结合模板来自动生成新闻。此外,知识图谱能够为新闻受众提供更加条理化的信息,结构化的实体知识使得新闻不再流于表面描绘,若以可视化的形式呈现新闻背后的知识,可丰富自动写作的新闻文本,传达更多的信息,提供新闻的深度阅读。
本文根据NBA赛事新闻本身所具有特点,构建了一个反映新闻要素的NBA赛事知识图谱(1)NBA赛事知识图谱已公开发布在http://www.openkg.cn/dataset/basketballkg,提出了一种结合知识图谱的融合模板、抽取和生成多种模式的新闻自动写作方法。如图1所示,本文首先根据爬取的篮球相关领域知识信息,定义体现新闻要素的实体、属性和关系,构建了一个专有的NBA赛事知识图谱。接下来提出了一种关键事件抽取(Key Event Extraction, KEE)算法,建立用关键事件以凸显赛场趋势的描述模板库来生成新闻的初稿。最后使用知识图谱补充背景常识信息并突出新闻描述重点,从而生成新闻的终稿。结合NBA赛事知识图谱,本文工作可以深度挖掘球员、球队、比赛等背景信息,并为用户呈现丰富多样的可视化新闻,支持深度阅读。
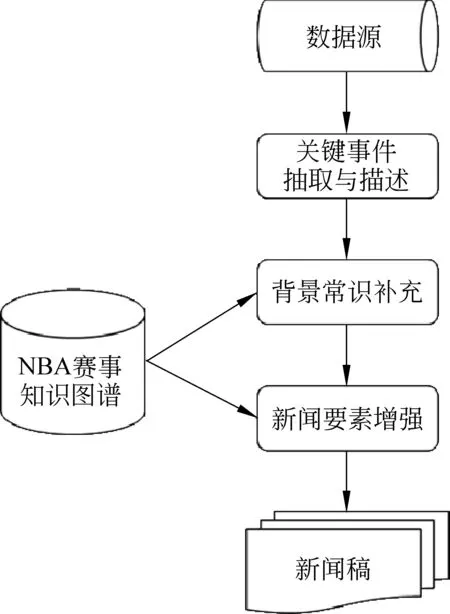
图1 本文方法概览图
1 面向赛事新闻的知识图谱的构建
本文通过构建NBA赛事知识图谱,来补充缺失的比赛常识和背景等信息,辅助体育新闻的生成,让生成的新闻稿件质量更高。本文构建的NBA赛事知识图谱属于特定领域知识图谱,其中的实体类定义为篮球赛事中的三个重要概念,分别为“球队”“球员”和“比赛”。对于各实体,定义了辅助NBA赛事新闻生成需要用到的基本信息,例如,“球队”实体,定义了“名称”“别名”“分区”等属性。在属性定义的基础上,定义了突显新闻特点的实体之间的关系,包含“当前效力”“交手”“历史交手”“参与比赛关系”这四种关系。根据从虎扑篮球网站(2)https://nba.hupu.com以及百度百科上爬取的相关数据,我们构建了一个能体现NBA赛事新闻特点的知识图谱,统计数据如表1所示。该NBA赛事知识图谱中节点的总数目有5 893个,其中,现役球员节点数量有620个,退役球员节点有3 407个;球队节点数量有30个;抽取的比赛场数由1985年起到2019年一共有43 510场,需要用到的比赛节点数量为1 836。
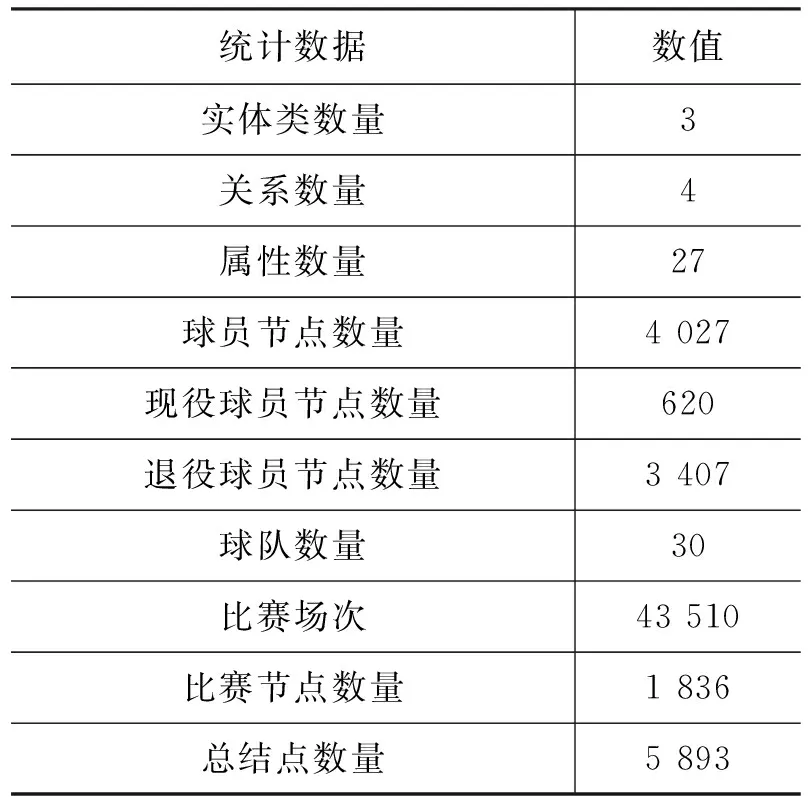
表1 知识图谱结果统计
2 NBA赛事新闻的自动写作
为了生成相关NBA赛事新闻,本文提出了一种KEE算法,该算法从比赛的文字直播数据中抽取关键事件,再根据NBA赛事新闻特点制定新闻模板,针对KEE算法提取的关键事件生成新闻初稿。在用KEE算法写作的初稿基础上,本文结合构建的NBA赛事知识图谱,对初稿内容进行补充完善,从而得到更高质量的新闻结果。
2.1 赛事关键事件抽取
文字直播中,每一条数据都记录着球场上发生的一个事件,但是这些单独的事件并不能都出现在生成的新闻中,需要进行概括后选择其中关键的事件生成新闻内容。而关键事件的获取,需将文字直播分段,概括出不同时间段发生的关键事件,从而提炼新闻要素。
因比赛中关键事件发生时往往伴随着分差的改变,故本文通过分析分差变化趋势对数据进行分段。对文字直播数据中的每一条信息L,可用五元组(quarter, time, team, event, score)表示。其中,quarter指当前的节数,time是本节剩下的时间,team是发生事件的球队,event是发生的事件,score是发生事件后的分数。记主队a与客队b在NBA篮球比赛中某一节时刻t的比分之差为dif(t),可用直播数据中t时刻的比分值(score)表示如式(1)所示。
dif(t)=scorea,t-scoreb,t
(1)
其中,时刻t∈{t0,t1,…,tn},可得所有时刻的得分差序列集合{dif(t0),dif(t1),…,dif(tn)}。这里以主队视角进行描述,分差为正时代表主队领先,反之,负分差代表主队落后。为了获得一节NBA赛事中新闻受众感兴趣的发展过程和趋势,需从求得的分差结果中进一步分析分差波动频率和幅度。
本文构造了一种基于关键时间点的分段方法来权衡分差的波动频率和幅度。因一节NBA比赛中分差达到最大的时刻和分差达到最小的时刻均为这节比赛的一个转折点,故我们将这两个时刻定义为此节比赛的关键时间点,分别用key_time1和key_time2表示,具体如式(2)、式(3)所示。
接下来需要根据两个关键时间点判断其所在区间: 如果关键时间点出现在这节比赛前六分之一的时间,则将这节比赛开始时间t0作为关键时间点;如果出现在这节比赛的后六分之一的时间,则将这节比赛结束时间tn作为关键时间点。故key_time1和key_time2可表示如式(4)所示。
(4)
以下将分为dif(key_time1)-dif(key_time2)>8和dif(key_time1)-dif(key_time2)≤8这两种关键时间点的分差情况对该节比赛的整体趋势进行判断。当比分差距>8时,则该节比赛分差波动幅度大,可以看作关键时间点前后差别大。此时这节比赛适合按照时间点切割为三段,对应赛场上的形势,概括为下几种情况:
(1) key_time1>key_time2,dif(key_time1)>0,dif(key_time2)<0: 先“扩大优势”后“被反超”再“缩小劣势”;
(2) key_time1
(3) key_time1>key_time2,dif(key_time1)<0:先“缩小劣势”后“扩大劣势”再“缩小劣势”;
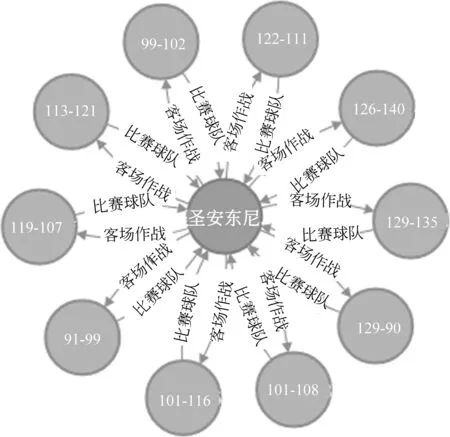
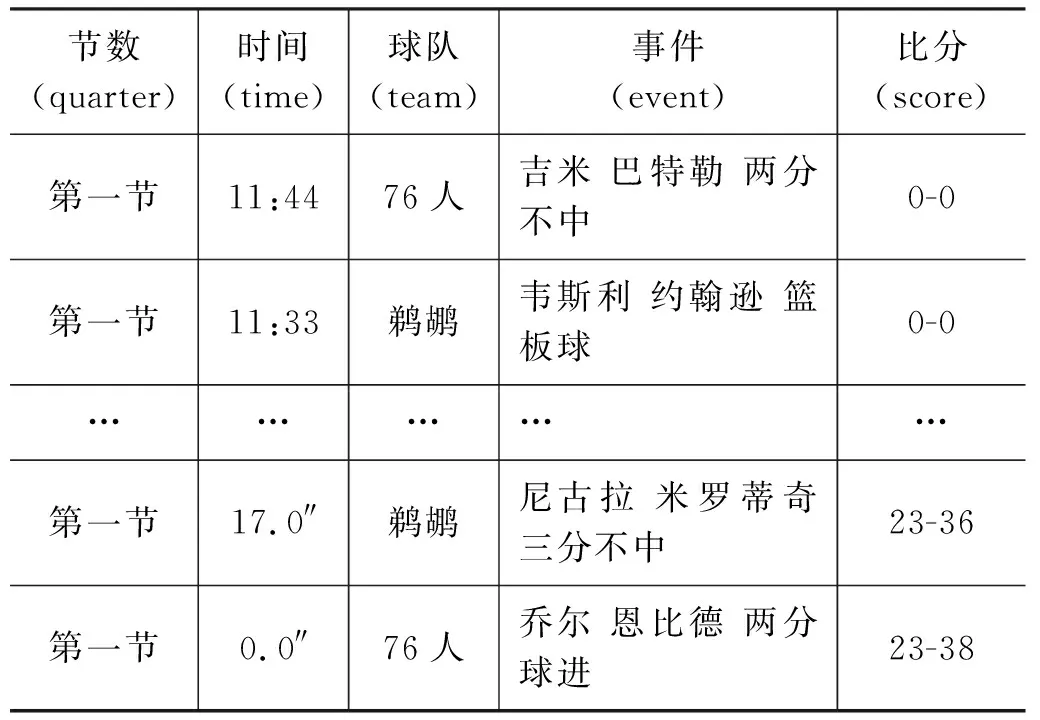
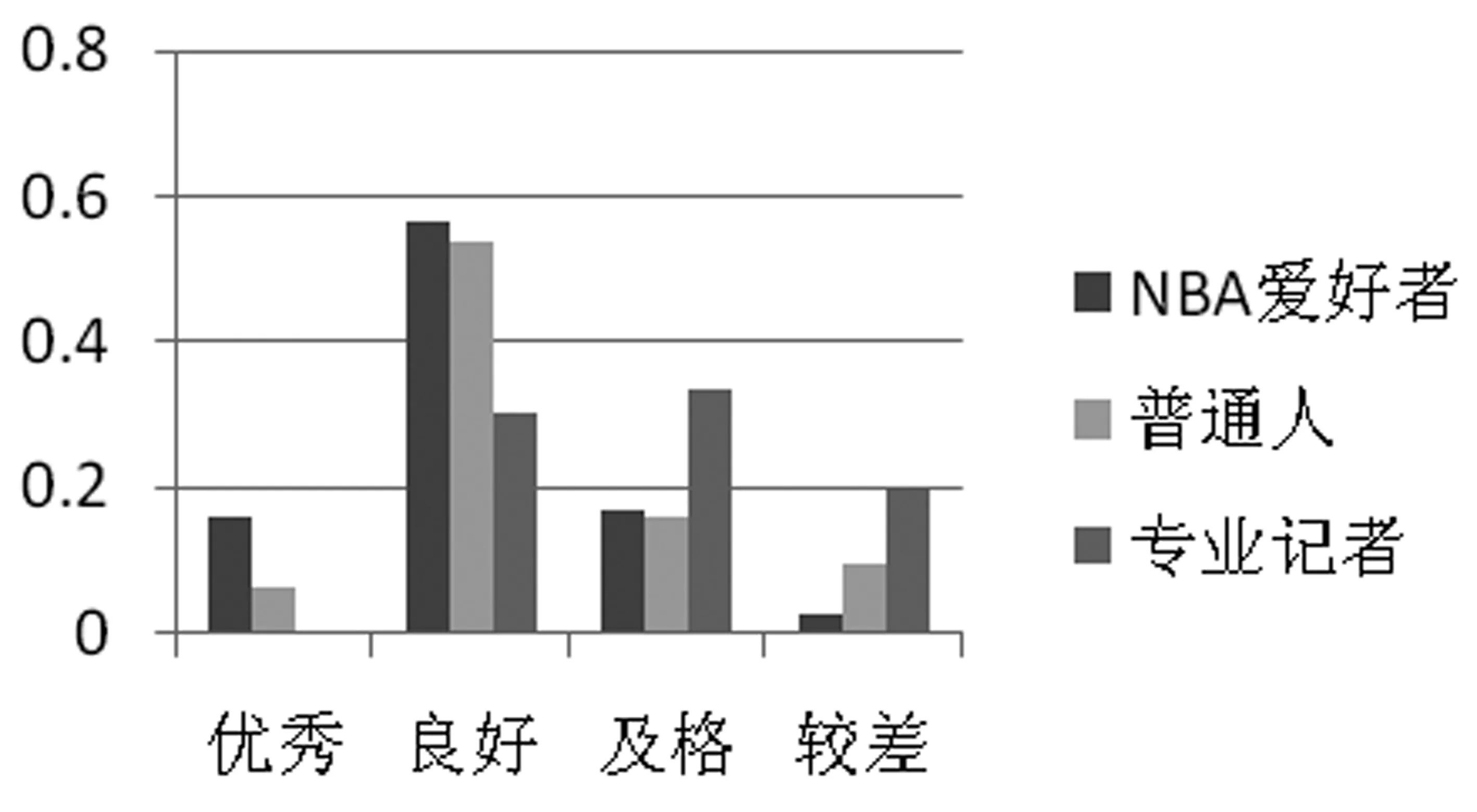
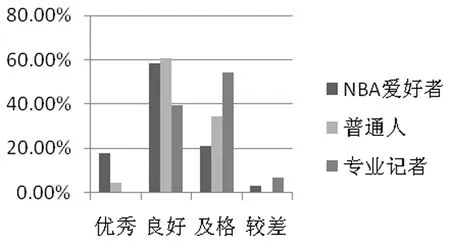
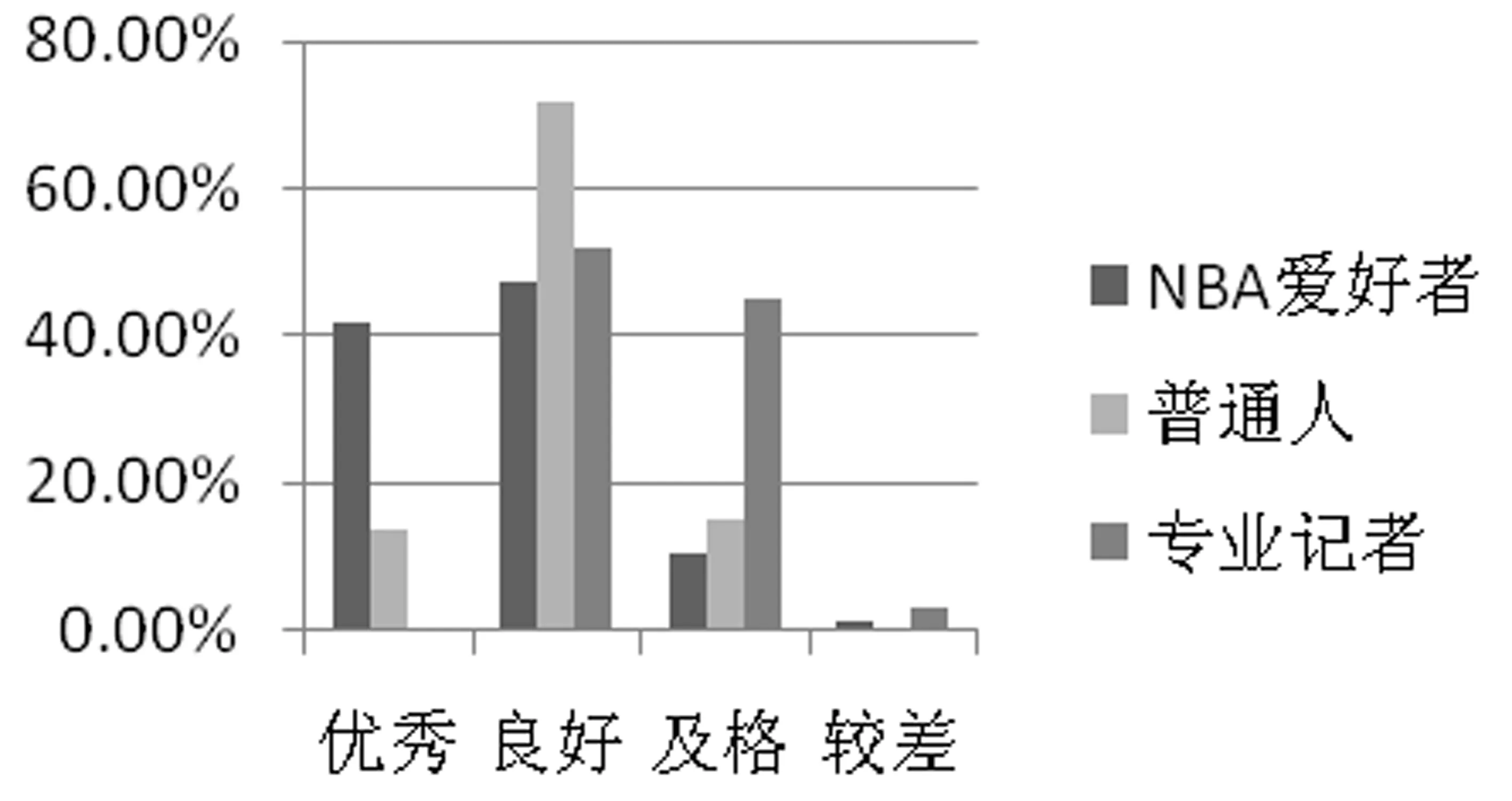
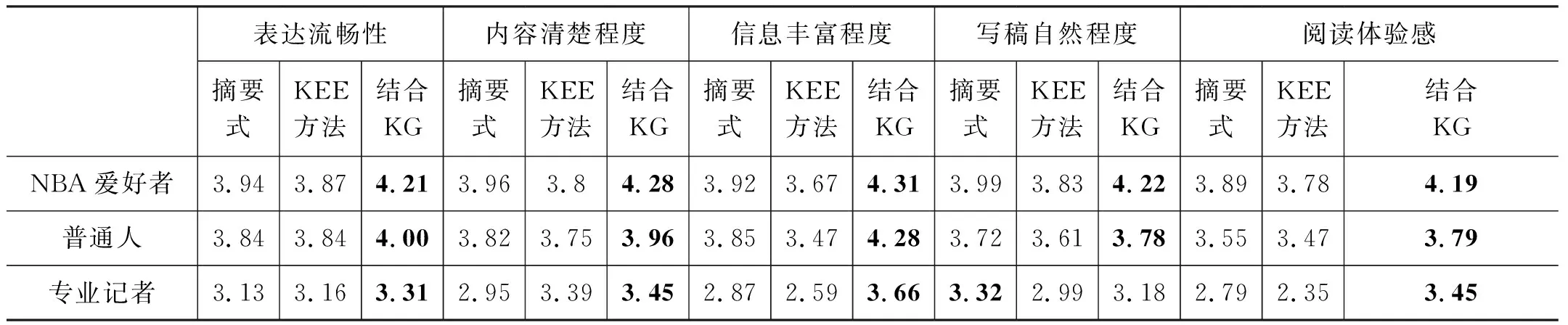
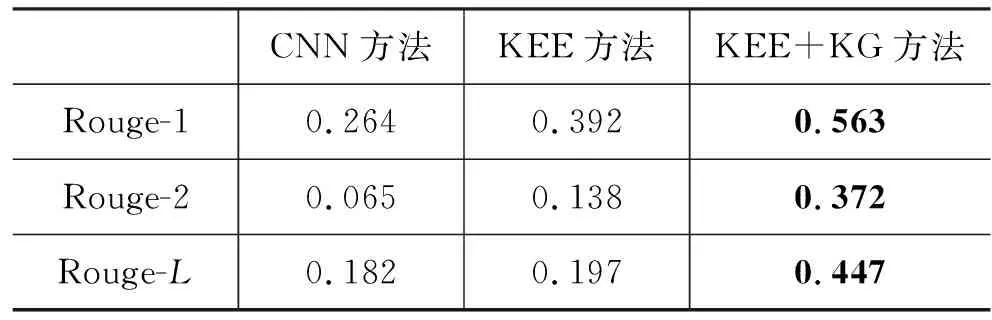
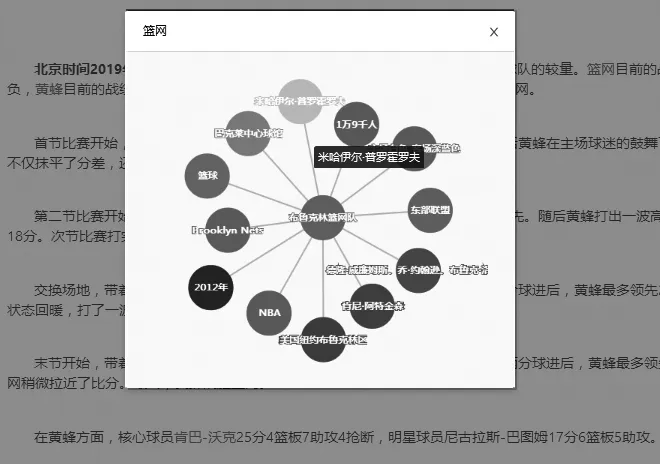
(4) key_time1 (5) key_time1>key_time2,dif(key_time2)>0:先“扩大优势”后“缩小优势”再“扩大优势”; (6) key_time1 当比分差距≤8时,则该节比赛分差波动幅度较小,赛场形势偏向拉锯状态,此时可将该节比赛作为整段来处理,具体分为以下三种情况: (1) dif(key_time2)>10:最小分差大于10且分差变化幅度不大,赛场形势概括为主队“稳稳领先”; (2) dif(key_time1)<-10:最小分差小于-10且分差变化幅度不大,赛场形势概括为主队“稳稳落后”; (3) dif(key_time1)>0,dif(key_time2)<0:分差在0分左右变化,赛场形势概括为两队“胶着”。 除了上述一般情况以外,还有少量特殊情况,更适合将一节NBA比赛划分为两段。综合以上各类情况,我们将一节比赛分段为如表2所示的一些情况,分别对应赛场主队和客队的比分趋势,有助于后续的新闻生成。 表2 NBA赛事分段及趋势概括(部分) (1) 得分类别: 得分类别包括文字直播中的“两分球进”“三分球进”“罚球命中”。 (2) 打铁类别: 打铁类别包括“两分不中”“三分不中”。 (3) 篮板类别: 篮板类别包括“进攻篮板”“防守篮板”。 (4) 犯规类别: 犯规类别包括“投篮犯规”“个人犯规”“进攻犯规”“恶意犯规”“技术犯规”等。 (5) 失误类别: 失误类别包括“传球失误”“出界”“丢球”等。 (6) 阵容调整。 (7) 暂停。 以住的语文课堂教学方式都比较单一,教师在讲台上讲课,学生被动接收,课堂上很少有信息的交流,都是教师一直的“灌输”,教师讲什么学生只能被动地增收。这样一来学生自主学习的能力就会被弱化,没有交流,一些不同的意见和观点也会被一致化,即只有教师教的才是对的。这样的教学结果也可想而知。 接下来将相关的信息存储到上述对应的类别中,按照事件描述特征(表3)从所有事件中转换各类事件eventt,抽取关键事件E*,定义为五元组E*=(player,team,action,result,time),其中,player, team指的是动作的施加者和他的球队;action是具体的动作,大多为基本事件;result是动作发生后的比分;time是动作发生的时间。 表3 NBA赛事关键事件(部分) 本文提出的基于关键时间点进行关键事件抽取的算法(KEE算法)如下: 算法1 基于关键时间点抽取关键事件的算法 完成上述新闻关键事件的抽取后,需要对关键事件进行描述才能成为一篇新闻报道的部分内容。为满足关键事件的描述需要,我们构建了对应的模板,表4给出了部分关键事件描述模板。 表4 关键事件描述模板(部分) 续表 除了上述定义的关键事件需要在新闻中涉及之外,对一节比赛整体发展趋势的描述也可作为新闻的一部分,比赛趋势描述模板如表5所示。 表5 趋势描述模板(部分) 生成新闻时一般需要结合两类模板才能使最后生成的新闻效果好。具体的做法是,在趋势模板中对应分段随机选择关键事件进行插入,生成的结果示例如下: “比赛开始,鹈鹕稍微占据主动,领先76人2分左右。然而之后76人不仅扳平了比分,还取得领先,领先最多达16分,乔尔-恩比德一人砍下13分,是球队的首要功臣。首节比赛打完,76人领先鹈鹕15分。” 目前生成的新闻初稿包含了这场NBA比赛的流程和关键事件描述。虽然生成的初稿能够涵盖这场比赛的基本信息,但是依然存在着两个较大的缺陷: 一是比赛背景信息不全;二是未体现新闻描述重点。为了解决这两个问题,增加新闻的生成质量,将使用到第1节构建的NBA赛事知识图谱来辅助新闻生成。 2.3.1 背景常识补充 NBA赛事知识图谱中蕴含的如球员之间的交手记录、球员最近状态等背景常识信息可以对赛事新闻内容进行补充,可通过直接查询或推理得到。图2为对阵双方圣安东尼奥马刺和金州勇士这两队查询得到的胜负关系,据此补充新闻中的背景信息,可表达为“圣安东尼奥马刺对阵金州勇士62胜38负”。 图2 球队历史胜负关系示例 除了从知识图谱中直接获取事实之外,还可根据实体及关系进行推理,得到更丰富的背景信息。例如,可从知识图谱中查到球队A和球队B近期的交手比赛时间、最终得分等信息,如果球队B最近与A交手都输了,则可推理得到“球队A对阵球队B占据明显优势”。再如,针对单个球队圣安东尼奥马刺,可查询得到该球队最近的状态信息(图3),可知该球队最近十场比赛的情况。若球队最近十场比赛都赢了,则可推理出“十连胜”“状态火热”。 图3 球队最近比赛结果示例 2.3.2 新闻要素增强 NBA赛事新闻若要获得读者的青睐,除了上述平铺直叙的赛况描述之外,还应增强新闻描述要素,突出读者关注的明星球员的发挥或是最近表现出色的球员。在本文构建的知识图谱中,每个球队至少有一个领袖球员、多个明星球员。以此类球员为重点对比赛进行描述并对这些人的数据进行追踪和汇总,将使得新闻更为生动,更具有话题性。图4为知识图谱中查询到的洛杉矶湖人队的领袖球员和明星球员,获取他们的所有“得分事件”“篮板事件”“助攻事件”,生成汇总数据,可得到如下的一段球员表现新闻报道: 图4 球队明星球员示例 “在湖人方面,领袖球员勒布朗-詹姆斯得到17分13篮板5助攻,明星球员凯尔-库兹马19分6篮板,布兰登-英格拉姆14分2篮板2助攻,极大地帮助了球队。” 为了生成相关NBA赛事新闻,首先需要编写爬虫爬取相关比赛的文字直播数据,然后对爬取的数据进行数据预处理。本文用来生成新闻的数据为简洁文字直播数据(3)处理后的文字直播数据已公开发布在https://github.com/conniemy/BasketballNews,虽然不包含事件细节的描述,但是涵盖了整场比赛的发展流程,且具有规范性。表6为一段简洁文字直播例子。在简洁篮球文字直播数据中,每一条信息都可以由五元组=(quarter, time, team, event, score)表示。这里事件event的种类是固定的,一般包括“暂停”“失误”“篮板球”“得分”“打铁”“阵容调整”和“犯规”七种情况,并且事件都是独立的,前后事件没有必然的联系。 表6 简洁文字直播示例 本文选取虎扑篮球网站中NBA比赛对应的文字直播数据作为数据源,每场比赛至少由4小节构成。首先根据文字直播对数据进行分段,依据KEE算法结合模板库进行NBA 赛事新闻的自动写作。我们根据虎扑网一场比赛的文字直播数据(4)https://nba.hupu.com/games/playbyplay/156270自动生成一篇赛事新闻稿,如图5所示。 图5 赛事新闻初稿示例 在此基础上,本文结合NBA赛事知识图谱来增强上述新闻稿的生成质量,在上述结果的基础上可以得到如图6所示的赛事新闻稿,横线部分突出展示了结合知识图谱生成的新闻内容。对比两则新闻可以直观地看出,结合知识图谱的新闻稿质量明显更高,知识图谱所带来的信息补充效果明显。 图6 赛事新闻终稿示例 在对比实验方面,本文使用了利用卷积神经网络(CNN)自动生成足球新闻的方法[9-10,12]作为对比实验,因上述工作均未公开足球文字直播数据集和源码,故评测采用了Bi-LSTM+CNN[23]方式在本文公开的篮球文字直播数据集上进行了实验,以下简称CNN方法。 我们随机选取了最近一个赛季的50场NBA比赛,分别自动生成了CNN新闻稿、采用KEE算法的新闻初稿以及KEE算法结合知识图谱的新闻终稿,分别进行了主观评测和自动评估。 3.2.1 主观评测 我们邀请了20名评测人员参加新闻质量主观评价。这20名评测人员中有4名是一线体育新闻记者,10位NBA篮球爱好者,6位仅对NBA赛事有所耳闻的普通人。首先进行新闻整体质量的评价,评判标准分为优秀、良好、及格、较差四个级别。不同人群针对摘要法新闻稿的评价结果如图7所示,针对KEE法新闻初稿以及KEE法融合知识图谱的新闻终稿的评价结果分别如图8、图9所示。 图7 CNN法新闻稿整体评价结果 图8 KEE法新闻稿整体评价结果 图9 KEE法融合知识图谱的新闻稿整体评价结果 评估结果表明CNN新闻稿整体的优秀率和良好率最低,KEE法次之,而优秀率和良好率在KEE法融合知识图谱之后有了明显提升(对NBA爱好者而言,优秀率从17.80%提升到41.60%;对专业记者而言,良好率从39.50%提升到52%)。综上,相对于CNN方法,本文融合知识图谱生成的新闻更让人满意。我们的方法虽然不能达到专业的新闻水平,但是能基本满足人们的阅读需求,尤其是NBA爱好者亦即该领域新闻的直接读者的需求。 为了更加全面地体现新闻质量,并对比出知识图谱应用之后的优势,我们设定了如下5个主观评价指标: 表达流畅性、内容清楚程度、信息丰富程度、写稿自然程度(是否有明显的机器痕迹)、阅读体验感。各指标分别设置为1~5分,其中,5分为最符合该指标,1分为最不符合该指标。评测者事先不知道哪个新闻是哪种方式产生的,根据自己的主观感受分别打分。 表7统计了20名评测人的打分平均值(结果保留到小数点后两位,四舍五入),可以看出,CNN方法在大部分情况下比KEE方法评分略高;但KEE方法结合知识图谱后,每个指标评分均有所提升,特别是“内容清楚程度”和“信息丰富度”上的提升比较明显,这是由于知识图谱的应用增加了生成新闻稿的背景信息和新闻描述重点。 表7 主观评价指标评分(平均值) 3.2.2 自动评估 除了上述直观的阅读体验评测外,我们还使用了ROUGE作为自动评估方法,使用ROUGE-N的F1作为评价指标,主要考察文本生成结果的充分性和必要性。自动评估采用的数据集来自从虎扑上爬取的494场篮球比赛的互动文字直播数据,一共58 745个句子,采用半自动的标注方法对句子进行了标注。评估数据集中,340场比赛43 211个句子作为训练集,154场比赛15 534个句子作为测试集。 本文分别比对了随机选取的50场NBA比赛由文字直播数据自动生成的CNN新闻稿、采用KEE算法的新闻初稿以及KEE算法结合知识图谱的新闻终稿,以同一赛事在虎扑上由专业记者撰写的赛事新闻作为优质参照数据。表8是3种方法在同样ROUGE环境下在评估数据集上的评测结果。可以看出,本文提出的KEE方法实验结果略高于经典的文摘式CNN方法,相对而言更贴合人工撰写的新闻稿件,不像文摘式那么机械。KEE+KG方法的结果最优秀,这表明结合知识图谱生成的最终新闻稿,可以让NBA赛事新闻内容更为丰富,阅读性大大增强。自动评估的结果与主观评测的结果基本贴合,表明了本文融合知识图谱的自动写作方法的有效性。 表8 与CNN法新闻稿的自动评测对比 本文自动生成的融合知识图谱的NBA赛事新闻最后将呈现在网站页面上,并可应用知识图谱中的其他背景知识来丰富新闻文本的呈现。常见的NBA赛事新闻页面通常包含有新闻报道的文本、比赛图片或者比赛视频(图10)。但是这样的新闻呈现方式过于单调,并且读者无法获取新闻之外的额外信息。我们对新闻文本的部分关键词进行了标记,点击标记文本即可通过“弹窗”的方式补充展示背景知识。其中,球员或球队的背景知识呈现采用力导向图的形式(图11),从第1节构建的知识图谱库中获取球员、球队实体的属性,让用户可以快速了解该球员或球队。 图10 NBA新闻呈现页面 图11 生成新闻信息补充展示(球队背景常识) 此外,新闻中涉及如背景事件一类的新闻要素的深度解读,采用如图12所示的标签形式呈现。本文实现的结合知识图谱的NBA赛事新闻呈现,通过读者的交互式点击,可以让其获得除本场比赛报道外更多的背景知识,极大地增加了读者的阅读体验。 图12 生成新闻信息补充展示(新闻要素增强) 本文提出了一种融合知识图谱的NBA赛事新闻的自动写作方法。首先基于关键时间点对比赛进行分段,接下来获取比赛的趋势描述。在此基础上,本文根据篮球比赛的特点,定义了一些关键事件和与其对应的描述模板,用于新闻初稿生成。为了解决初稿中存在的背景信息缺失和赛事新闻要素描述不明等问题,使用构建的NBA赛事知识图谱辅助新闻终稿的生成,从而提升生成新闻的质量。该方法生成的新闻稿件表达流畅、内容清楚、信息丰富、以假乱真度高、阅读体验感良好。此外,本文构建的知识图谱还有助于NBA赛事新闻报道的深度可视化呈现。 下一步工作将在NBA赛事知识图谱中引入更加丰富的赛事知识,构建更多的实体和实体之间的关系,增强知识图谱辅助新闻生成的效果。同时在新闻模板中增加更多的描述模板和特殊事件,以期获得更高质量的NBA赛事新闻。
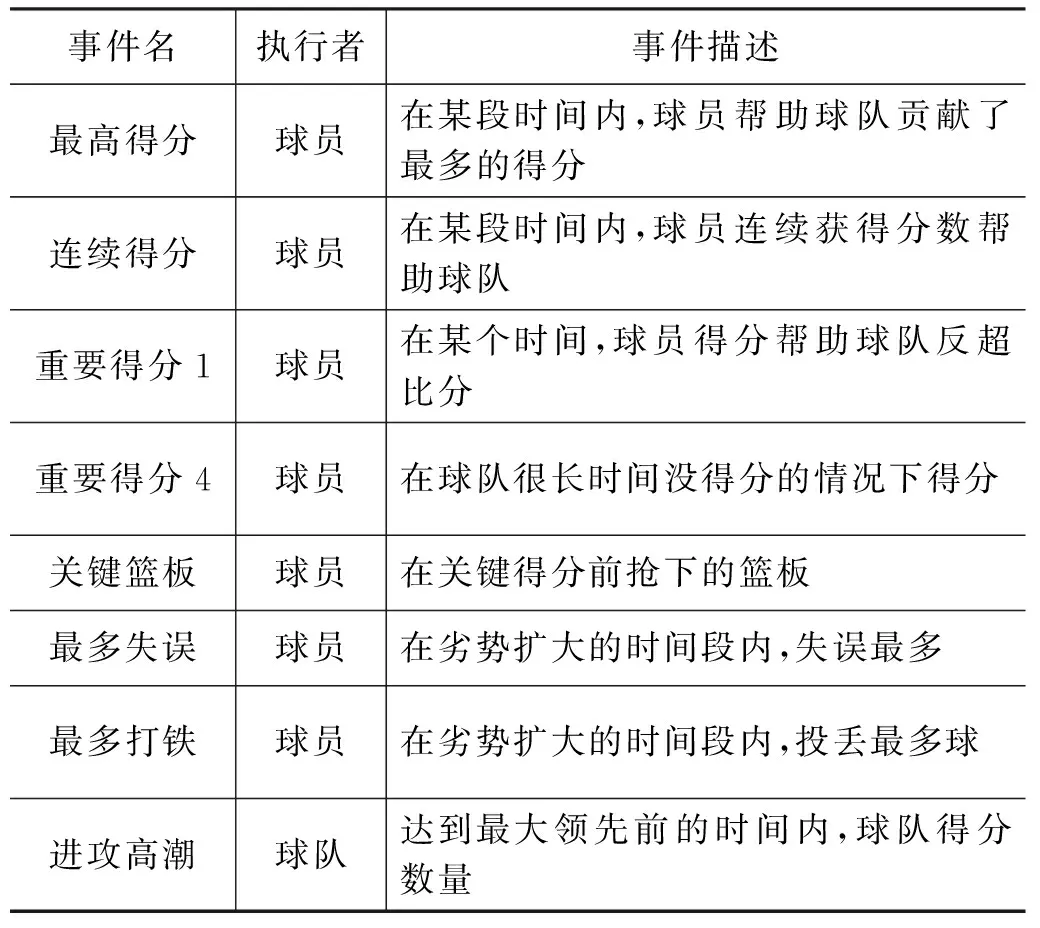

2.2 关键事件的描述


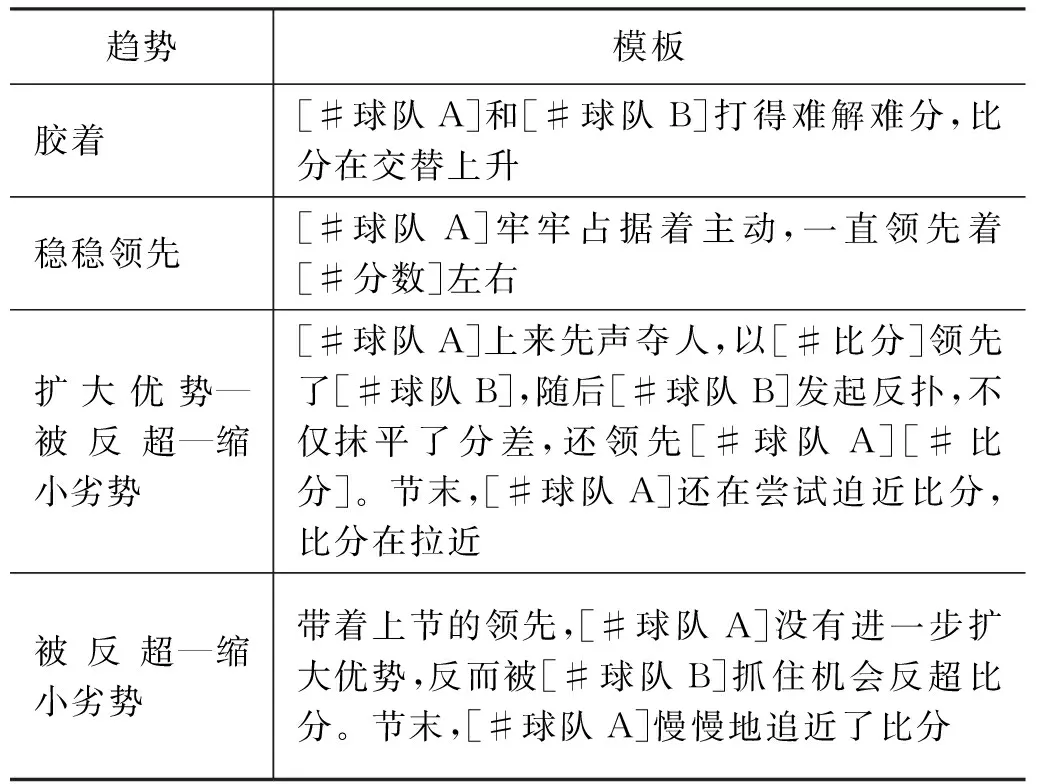
2.3 融合知识图谱的新闻内容生成


3 实验结果与分析
3.1 数据预处理
3.2 NBA赛事新闻自动写作结果与分析


3.3 结合知识图谱的NBA赛事新闻呈现


4 总结与展望
