基于服务关联网络的服务依赖关系识别
2021-10-11杨冬菊张伟达赵卓峰
杨冬菊,张伟达,赵卓峰
(1.大规模流数据集成与分析技术北京市重点实验室,北京100144;2.北方工业大学 数据工程研究院,北京100144)
0 引言
随着服务计算技术的快速发展,以Web服务为基础的面向分布式服务计算架构模式已经成为互联网环境下的主流形态[1-3]。互联网上的服务和软件资源变得极大丰富。网上网下和跨领域之间建立了密切业务联系,从而形成了跨网跨域跨世界的大规模网络化复杂服务的生态系统——大服务[4]。大服务环境中的服务通过跨网跨域跨世界进行组合,服务之间通过建立复杂的依赖及协作关系来处理物理信息空间的大数据和复杂的关联业务。在此背景下,服务具有多样化、异构、复杂、海量等特点,服务的系统运行与协同互操作模式等发生了巨大变化,利用云环境实现组合服务的划分、分布式部署及并行执行成为必然趋势[5-6]。在对组合服务进行合理划分和分布部署时,需要考虑两方面因素:①大服务视角下,服务之间可能会传递大量数据,即服务之间存在数据依赖,两个服务之间的执行距离及网络延迟会影响组合服务的总体执行效率;②服务执行时除了存在逻辑上的前后依赖关系,还可能需要频繁交换控制信息,即服务之间存在控制依赖,部署在动态、开放环境中分布执行会由于存在设备、网络等不确定性影响组合服务的成功执行。
进一步剖析上述两个问题,如何识别并发现服务之间存在的数据依赖及控制依赖关系是实现组合服务合理划分、分布部署的前提和基础。在该过程中,需要解决3个问题:①如何刻画、设计服务之间的依赖模型;②如何通过对已有服务关系的挖掘识别构建服务依赖关系;③如何基于服务依赖关系支撑组合服务的划分和分布部署。
针对上述问题,本文提出一种基于服务关联网络的服务依赖关系挖掘方法,通过对已有组合服务的处理与解析,得到服务之间的控制流和数据流,构建服务关联网络,并以此为基础利用图遍历算法DFS(depth-first search)、社区发现算法Louvain配合改进的关联规则挖掘算法HFPGrowth(Hmark-Frequent Pattern Growth)算法生成服务依赖图,通过服务依赖图有效地描述服务之间的依赖关系的强弱,从而支撑组合服务的合理划分与分布部署,提高组合服务的运行效率,减少组合服务因为网络通信等原因导致失败的概率。最后通过3个实验验证了本文方法的可行性和有效性,并通过与经典算法的对比分析验证了方法的执行效率。
1 相关工作
目前对服务依赖关系的研究大多集中在两方面:①基于服务依赖关系实现服务的自动组合或组合服务的演化、优化;②基于服务依赖关系在组合服务失效替换时保持其事务属性。在实现方法上,大致可以分为3种:①利用Petri网等理论实现服务组合的推理或调优[7-9];②利用机器学习、事件驱动等手段建立服务依赖图,通过服务依赖图支撑服务组合或组合中的服务替换[10-14];③通过服务编排建立相应的服务组合演化模型[15]。文献[7]基于Petri网全局依赖网的服务组合自动演化,根据用户演化需求对服务组合进行正反向演化推理,为服务组合自动演化提供了形式化描述工具。文献[8]引入基于Petri扩展有色网(Expand Colored Petri Net, ECPN)构建支持事务级属性的层次化服务组合模型,然后利用服务事务粒度与服务补偿机制进行服务组合失效替换,促使服务组合的可信性增强演化。文献[9]将服务聚类成服务簇,然后基于Petri的服务网元建立相应的服务簇网元及其矩阵模型,根据失效服务网元标准矩阵和组合服务网模型,提出一种替换服务的快速查找与替换算法。文献[10]通过一种数据服务依赖图模型来实现服务组合,根据输入的用户数据需求约束,在依赖图上搜索满足需求的数据服务依赖子图,然后执行组合后的复合数据服务生成可视化数据视图。文献[11]将连续查询机制引入可感知服务质量 (Quality of Service, QoS)的自动服务组合中,以基于事件驱动的动态服务组合演化,通过有向无环图建立服务依赖图,配合事件驱动方法主动监控并处理动态服务,进而实现组合优化。文献[12]基于控制依赖和贝叶斯网络组合而成贝叶斯服务依赖图的错误定位方法,用于发现复合服务中的错误服务。文献[13]通过分析WS-BPEL过程与其成员服务间的依赖关系,预判成员服务是否动态更新。文献[14]基于事件驱动建立物联网业务流程,通过对业务流程分解,将其划分为多个服务和多个协同逻辑碎片,从而实现业务流程的分布式完全解耦执行。文献[15]通过面向服务编排建立相应的服务组合演化技术框架或模型。
已有研究工作大多基于服务自动组合、演化及失效替换等出发点分析服务依赖,与本文关注的组合服务划分与分布部署差异较大,而且大多只关注单一的数据依赖或控制依赖,显然无法直接应用在复杂多变的大服务环境中。
2 问题定义及方法原理
为便于问题定义与理解,以“高速公路紧急事故处置”场景为例作进一步说明。该场景定义了一个组合服务“高速公路紧急事故处置”,将高速公路上处置紧急事故时需要的所有服务按照逻辑顺序组合在一起,如图1所示。启动事件为监测到事故发生,首先进行事故信息的采集,包括事故发生的时间、地点、当前路段的流量和车速、最近几个收费站的车流量、当前的天气情况、事故地点附近的收费站或路段监控摄像头等,根据这些数据对事故级别进行判定,包括车辆损伤程度、有无人员伤亡、有无恶劣天气、有无道路损毁等,然后对事故进行相应处置,包括警车和救护车等应急车辆的调度以及其他车辆的管控,前者搜索范围内的紧急车辆并进行紧急通知,后者根据收费站、路段管控范围等生成管控方案。
分析上述组合服务发现,部分服务之间需要传输大量数据,如图1中事故判定的前提是需要路段流量计算、气象监测、路段摄像头等服务操作提供的事故数据采集信息才能进行事故计算等操作,因此在事故数据采集服务和事故处理服务之间会传输这些实时、大量数据。除了服务之间存在流程上的逻辑依赖关系,在部分服务之间存在频繁的信息交互,如警车、救护车调度和查找并通知服务,如果查找指定的范围内救护车和警车不符合调度条件,则需要扩大搜索范围进行二次通知,依次迭代下去,直至符合调度条件为止,因此在应急车辆调度服务和警车调度服务、救护车调度服务之间存在较为频繁的信息交互。如果将这些相互具有强依赖性的服务随机部署在不同的节点或网络环境上,大量数据传输时网络距离或网络开销会直接影响组合服务的执行效率,同时频繁的信息交互会由于动态、开放环境下设备、网络等的不确定性影响执行结果。
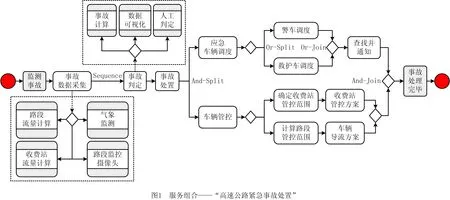
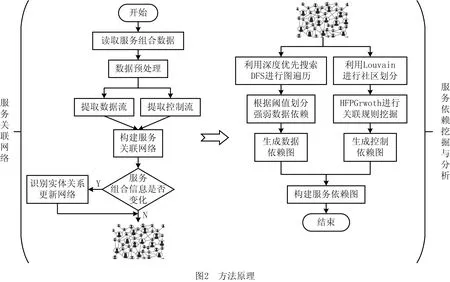
在上述过程中,识别并发现服务之间存在的数据依赖及控制依赖关系成为要解决的核心问题,依据服务依赖关系实现组合服务的合理划分与分布部署执行,更好地支撑分布式环境下组合服务的高效、可靠执行。由此本文提出一种基于已有组合服务构建服务关联网络并根据服务关联网络识别服务依赖关系的方法。首先对组合服务进行预处理,解析得到服务之间的前驱后继关系及数据交互情况,利用有向图构建服务关联网络,然后对服务关联网络进行深度遍历和挖掘,形成由数据依赖图和控制依赖图组合而成的服务依赖图,依据服务依赖图实现组合服务的划分。方法原理如图2所示。
3 服务关联网络模型及构建
3.1 服务关联网络模型
定义1服务(AS)。指服务提供者与消费者之间为共同创造价值而进行的某种交互协作,往往表现为交互界面、功能实体等。它可以由软件实现,也可以由人工或人机实现,可以是不可再分的原子服务,也可以是抽象服务。为简化操作,本文暂时只考虑软件定义的原子服务。可以表示为九元组:
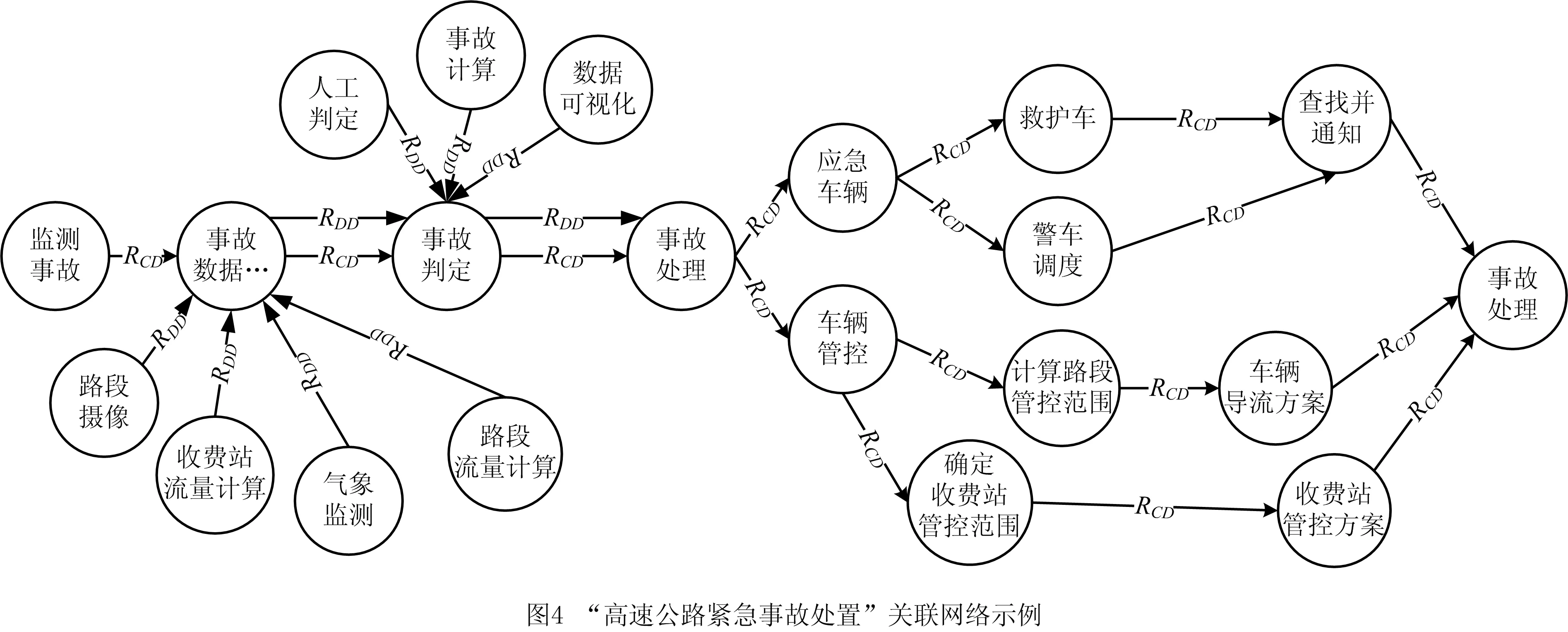
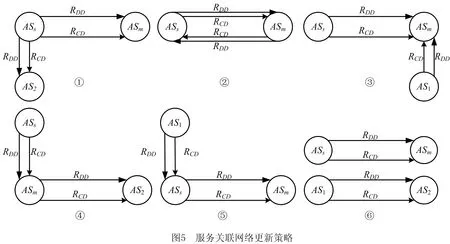
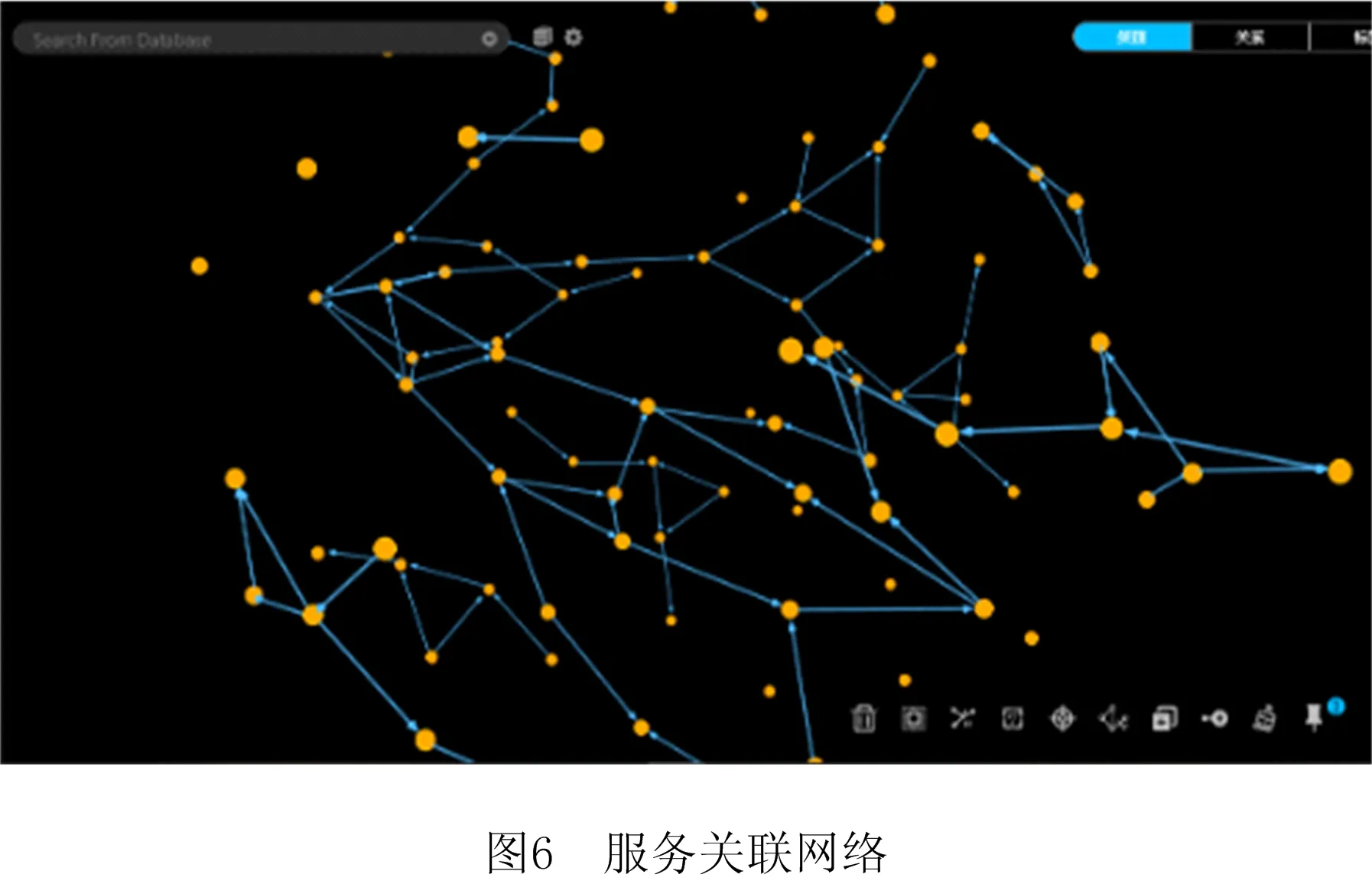
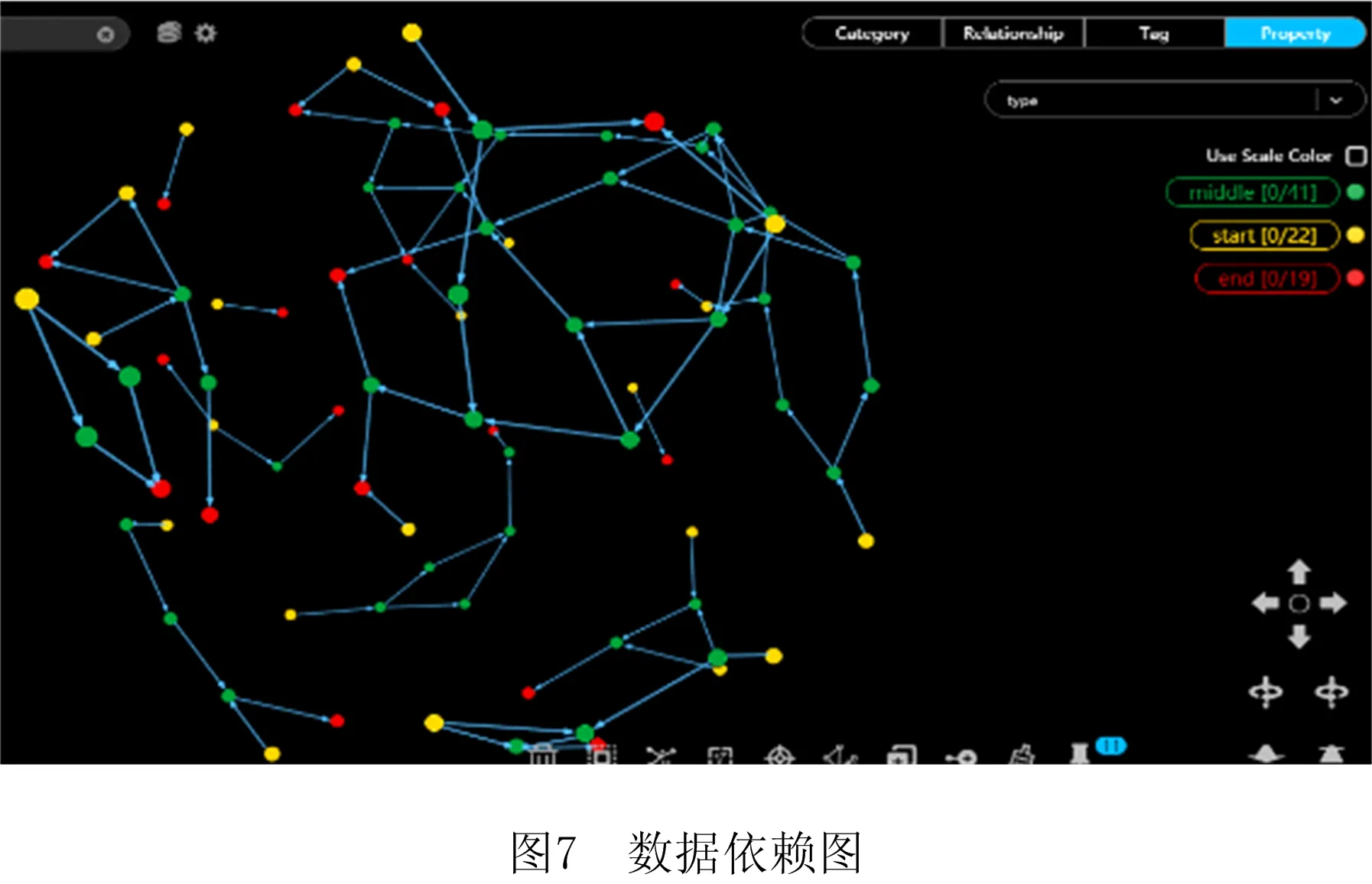
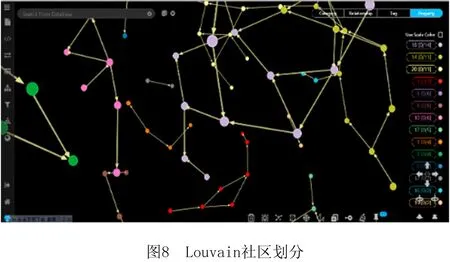
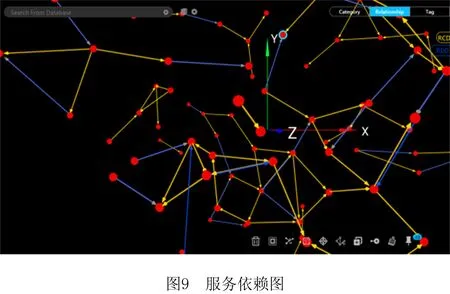
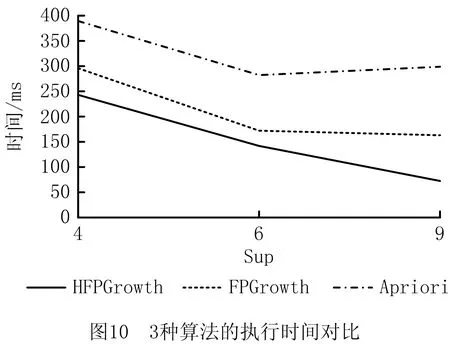
AS= Type,Community,Operations>。 其中:Id是AS的唯一标识符;Name是AS的名称;Desc是AS的语义描述;Input是AS的输入参数集合,Input(AS)={IP1,IP2,…,IPn},其中IP代表其中的输入参数;Output是AS的输出参数集合,Output(AS)={OP1,OP2,…,OPn},其中OP代表其中的输出参数;Publisher是AS的提供商;Type是流程中AS的类型标识,有start、middle、end等;Community是AS所属社区;Operations是AS的执行操作。 定义2服务关联网络(SN)。记录服务之间关联关系的网络。它可表示为一个有向图。 SN= 式中:V是有向图的顶点集,V={AS1,AS2,…,ASn},ASi∈AS,1≤i≤n;E是有向图的边集,E=V×V={(ASi,ASj,R) |ASi,ASj∈V,ASi→ASj(ASi和ASj存在某种关联关系),R是关系的类型,1≤i,j≤n}。其中,R∈{“RDD”,“RCD”},当R=“RDD”时,表示两个服务之间具有数据依赖关系,当R=“RCD”时,表示两个服务之间具有控制依赖关系。 定义3服务组合(SC)。将多个服务组合在一起完成复杂的业务需求,采用BPMN 2.0规范[16]进行描述。数学表达式采用类BNF范式[17]表示为: SC::=X|ASs⊙ASm|ASs◇ASm|ASs⨁ASm |ASs△ASm|ASs||cASm|ASs#ASm。 其中:X表示服务或者空服务;ASs⊙ASm,ASs◇ASm,ASs⨁ASm,ASs△ASm,ASs||cASm分表表示图3所示Sequence、And-Join、Or-Join、And-Split、Or-Split五种控制结构[18]。大部分复杂控制结构都可以由这5种变迁组合构成,ASs#ASm表示ASs和ASm之间存在数据流。 定义4数据依赖(RDD)。在服务组合执行的过程中,如果两个AS之间存在业务的数据交互,即存在服务ASs,ASm,使得Output(ASs)∩Input(ASm)≠∅&&Q(Output(ASs),Input(ASm))>Y,则称ASs,ASm之间存在数据依赖关系,记作RDD(ASs,ASm)。ASs称作ASm的数据流前驱,ASm称作ASs的数据流后继。其中Y是阈值,Q(C1,C2)表示两个集合的交集阈值函数,参数C代表集合。 定义5控制依赖(RCD)。在服务组合执行的过程中,服务之间的执行是有前后顺序的,这是服务业务逻辑之间的依赖,称为控制依赖。5种结构下的控制依赖描述如下: (1)Sequence结构下,有ASs⊙ASm,表示服务ASs执行后才能够执行ASm。此时ASs是ASm的控制前驱,ASm是ASs的控制后继,则ASs和ASm之间存在控制依赖,记作RCD(ASs,ASm)。 (2)Or-Split结构下,有ASs◇ASi,∀ASi∈{AS1,AS2,…,ASn},1≤i≤n,表示在服务ASs执行后选择执行AS1,AS2,…,ASn中的其中一个服务。在此情况下,任意ASi要么不执行,要么一定在ASs后执行,则ASs和ASi之间存在控制依赖,记作RCD(ASs,ASi)。 (3)Or-Join结构下,有ASi⨁ASm,∀ASi∈{AS1,AS2,…,ASn},1≤i≤n,表示在服务AS1,AS2,…,ASn中至少一个执行完毕后才能够执行服务ASm。在此情况下,ASi和ASm之间存在控制依赖,记作RCD(ASs,ASi)。 (4)And-Split和And-Join结构与前面类似,不再赘述。 遍历并解析已有组合服务得到包含的服务及其前驱后继依赖关系,转化成有向图模型进行描述与存储,得到服务关联网络。当有新的组合服务加入时,需要识别并判断服务节点、关系在已有服务关联网络中是否存在并根据不同的策略更新合并。具体步骤如下: 步骤1数据预处理。读取已有服务组合,根据前驱后继将服务标注type属性,start、middle、end分别表示一个服务组合的执行启动服务、中间服务以及结束服务。 步骤2解析提取数据。对服务组合进行解析得到包含的服务及其关系,筛选具有数据依赖或控制依赖关系的服务节点对,分别存储为节点数据以及关系数据。 步骤3利用上述数据初始化构建服务关联网络。以前述“高速公路紧急事故处置”为例,建立的服务关联网络如图4所示。 步骤4当有新的组合服务加入时,首先判断服务节点及关系在已有服务关联网络中是否存在,假设关联网络中存在服务节点及关系,ASs→ASm,RDD(ASs,ASm)&&RCD(ASs,ASm),新加入的服务节点及关系是,AS1→AS2,RDD(AS1,AS2)&&RCD(AS1,AS2),则具体更新策略如图5所示。 (1)当ASs=AS1,ASm≠AS2时,加入服务节点AS2以及关系RCD、RDD,更新后如图5中①所示。 (2)当ASs=AS2,ASm=AS1时,则说明两个服务节点都存在,但是关系方向有变化,则节点不变,在两个节点之间加入新的关系,如图5中②所示。 (3)当ASs≠AS1,ASm=AS2时,加入服务节点AS1以及关系RCD、RDD,更新后如图5中③所示。 (4)当ASs≠AS2,ASm=AS1时,加入服务节点AS2以及相应的关系RCD、RDD,更新后如图5中④所示。 (5)当ASs=AS2,ASm≠AS1时,加入服务节点AS1以及相应的关系RCD、RDD,更新后如图5中⑤所示。 (6)当ASs≠AS1,ASm≠AS2时,新建立服务节点AS1、AS2以及关系RCD、RDD,更新后如图5中⑥所示。 (7)当ASs=AS1,ASm=AS2时,则认为已经存在,不做变更。 若RCD、RDD只存在一种,则处理策略类似。 步骤5节点由于宕掉或者其他原因退出网络,此时也要匹配节点以及节点周围的关联关系,一起退出网络。 服务关联网络中记录了服务节点的类型属性(start、middle、end)和服务之间的数据依赖关系,依据类型属性及数据依赖关系对服务关联网络进行遍历,抽取相关服务节点及其关系得到数据依赖图。数据依赖图是服务关联网络在数据依赖维度上的投影。在该过程中,使用深度优先搜索遍历所有数据依赖项,算法如下: 算法1服务关联网络遍历associatedNetworkDFS(Graph associatedNetwork, Type start, Type end,String Y)。 输入:服务关联网络associatedNetwork,启动服务(start),结束服务(end),阈值Y; 输出:数据依赖图dataDependenceGraph。 1.if (d==associatedNetwork.Depth() && Node nextNode.type.equals(end){//d的初始值为1表示图的深度 2. return dataDependGraph.put(nextNode,Y); //根据阈值返回强弱数据依赖图 3. for (Node nextNode in start){//遍历跟节点n相邻的节点nextNode, 4. if (!visit[nextNode]){//未访问过的节点才能继续搜索 5. visit[nextNode]=true; //搜索过的节点设置成已访问 6. if (DFS(nextNode, d+1)){ return true;}//如果搜索出有解 7.visit[nextNode]=false; //重新设置成未访问 8. } 9. } 10. return ; 11. } 在实际环境中,服务关联网络会出现分布不均匀的情况,表现为有向图上的节点入度或出度从1~n分布,有些节点只存在单路径。这些数据在关联分析时对结果影响很小,但是对分析效率影响很大,因此提出一种社区发现与关联规则挖掘组合方法。首先使用社区发现算法(Louvain)将服务关联网络划分成多个社区,每个社区内形成一个服务网络,去掉处于独立状态的节点,形成有向连通图。然后在传统FPGrowth算法基础上进行改进,提出HFPGrowth算法对筛选后的服务社区进行关联规则分析,利用分析结果构建控制依赖图。控制依赖图是服务关联网络在控制关系维度上投影与分析的结果,能够记录服务之间存在的控制依赖关系。 4.2.1 社区发现算法-Louvain Louvain算法基于模块度(如式(1))进行社区发现,该算法在效率和效果上均表现较好,并且能够发现层次性的社区结构,其优化的目标是最大化整个图属性结构(关联网络)的模块度。 (1) 其中:m为图中边的总数量,ki表示所有指向节点i的连边权重之和,kj同理。Aij表示节点i,j之间的连边权重。δ(u,v)判断节点u和v是否在同一社区,算法主要步骤如下: (1)将图中的每个节点看作一个社区; (2)对每个节点,依次尝试将节点分配到其每个邻居所在的社区,计算分配前与分配后的模块度变化,并记录分配后模块度最大的那个点。选择对应模块度最大的点,加入其所在社区; (3)重复步骤(2),直至每个节点的社区归属不再变化; (4)压缩每个社区,将其压缩成一个新的节点,这时,边的权重为两个节点内所有原始节点的边权重之和; (5)迭代上述步骤,直至图中模块度不再变化。 算法2社区发现算法graphLouvain(Graph associatedNetwork)。 输入:服务关联网络图associatedNetwork; 输出:划分后服务社区CommunityGraph。 1.associatedNetwork.initSingletonClusters();//网络初始化 2.nodeNumber=associatedNetwork.getNodeNumber();//获取图中节点的数量 3. while(localCommunity){ //当局部社区的结构不再发生变化 4. for i=1 to nodeNumber {//其中nodeNumber为网络中的节点数量 5. Cn=searchNeighbor(i).getCommunity; //获取节点i的邻居节点的社区属性 6. △Q=calcModularityFunction(i,Cn); //计算节点i移入Cn之后模块度增量 7.Cmax=maxModularityCommunity(△Q); // 计算使模块度最大化的邻居 8. Ci=getCommunity(i); 9.if(Ci !=Cmax){ Ci=Cmax;} //i所在社区Ci不同于最大值,修改为最大值 10. update Community(); //形成新的社区超点 11.restructuringNetwork(Ci); //重新构造网络 12. } 13.buildHierarchicalCommunityStructure(); 14. List 15. returnCommunityGraph.put(community); 16. } 4.2.2 关联规则挖掘算法-HFPGrowth算法 数据的关联分析能够从大规模数据中分析并挖掘有价值的关联性知识,主要通过关联规则挖掘来实现,本文对传统的FPGrowth算法进行改进,使其在面对大规模的服务组合环境下,在执行效率和结果正确率上都有一定提升。 在传统算法中,需要利用FP-Tree构造算法生成一个包含完整频繁项信息的FP树,其中FP树的频繁项头表中拥有ItemName(项名称)、Count(到达节点子路径数)、NextLink(指针,指向FP树中同名的第一个节点)。在该过程中,首先构造FP树是无序的,导致后序遍历出大量无序结果,这在服务关联网络中是不允许的,因为服务之间存在依赖关系,即有业务逻辑顺序。其次,在构造FP树的过程中,若新增节点在树中要新启一个分支,即没有同父节点,则需要在项头表中找到与该节点同ItemName的节点,遍历其列表,直至最后一个同名节点的域,向最后追加此节点。这样,每当数据量较大时,每次都要遍历到最后再追加,执行效率会受影响。 针对上述问题,本文在FP树的构造节点提出一种优化树、表结构的方法,具体如下: (1)要绝对保持对事务集合中的服务的执行顺序,剔除非频繁1项集后取消其对原始数据的排序操作。 (2)在原有的项头表的基础上添加一个新的属性Hmark。用于记录每一个数据项当前的头结点,通过对这种新的频繁项头表数据结构,执行insert_tree()操作后在项头表Hmark前插入节点,并把Hmark指向最新插入的节点。这样可以避免遍历操作,减少FP树的构建时间。 优化后的项头表数据结构如表1所示。 表1 项头表数据结构 算法3关联规则挖掘算法HFPGrowth (List 输入:原始事务集合SD,最小支持度minSup 输出:控制依赖图controlDependenceGraph 1. Collection freqMap=getFrequencyAndSup(SD); // 计算频数以及支持度 2. Map 3.TreeNode tree=new TreeNode("Null"); //构建根为null的空树 4. for(item in SD){ //向树中插入节点 5. if(tree.traverse(p)){ //遍历FPtree 6. count(N)++;,//如果树中有N.itemName=p.itemName,N计数增加 7. }else{ 8. Node node=new Node(N); //创建新节点 9. count(n)=1; //计数置为1 10. tree.add(node); //链接到树中 11. headers.add(Hmark,node); //在与同名的频繁项头表,插入到Hmark前,并设置此节点为新的Hmark。 12. } 13. if(!p){insert_tree(p.next,tree)}//如果p非空继续递归 14.} 15. Map 16. List 17. returncontrolDependenceGraph.put(rules);//返回控制依赖图 为了能够更加准确形象地表现服务之间的依赖关系,同时避免单一依赖关系的局限性,将4.1节中得到的数据依赖图和4.2节中得到的控制依赖图通过匹配不同节点、计算重叠节点和关系的方式进行合并,形成服务依赖图。 本文描述的方法使用Java、Spark与Python实现,图数据库采用GraphXR+Neo4j,源数据库采用Mysql,网络拓扑采用MATLAB完成。 为验证本文方法的有效性,设计了3个实验:实验一是功能验证,首先从ProgrammableWeb[注]https://www.programmableweb.com/。上爬取服务,利用MATLAB生成的网络拓扑将这些服务进行映射,分析并提取数据,形成服务关联网络。然后基于服务关联网络,利用图遍历计算出数据依赖图,利用Louvain+HFPGrowth组合算法完成控制依赖图的获取,构建服务依赖图,形成可视化展示。 实验二是算法的执行时间验证,将HFPGrowth算法和传统的Apriori、FPGrowth算法在同样的社区服务网络上执行,对比执行时间。 实验三是算法的结果验证,将Louvain+HFPGrowth组合算法与传统的Apriori、FPGrowth算法基于原始的服务关联网络图上进行实验,比对执行结果。 实验环境为Intel(R) Core(TM) i5-5200U CPU @2.20 GHz 2.19 GHz.操作系统为Windows 10家庭版64位,8 GB内存。实验工具为IntelliJ IDEA 2018.3.5、PyCharm 2018.2.3、Neo4j 3.5.16、Graph XRv2.2.1、Mysql 5.7以及MATLAB R2014a。 实验数据采用网络爬取与随机匹配相结合的方案,首先在ProgrammableWeb上爬取了600个RESTful API作为服务,在MATLAB上使用改进的Salama网络拓扑随机生成算法服务组合的网络环境,构造了102个服务组合,每个服务组合包含2-16个原子服务,将这些与Salama中的网络进行映射。每个服务都含有前述九元组的信息。 (1)实验一:功能验证 将构造的102个服务组合节点和关系数据导出为CSV文件存储。使用LoadCSV将上述节点和关系导入到Neo4j中,形成初始服务关联网络,使用GraphXR进行可视化,如图6所示。首先使用深度优先遍历算法DFS对图6进行遍历。获得如图7所示数据依赖图,黄绿红分别代表start、middle、end节点。蓝色箭头代表数据流的方向,两端是拥有数据依赖关系的服务节点。然后使用Louvain算法对服务关联网络进行社区划分,结果如图8所示。100个节点的服务网络划分为20个社区,并将每个服务所属的社区号存储回Community属性中。最后就是对Louvain算法划分出来的每个社区利用HFPGrowth算法进行关联规则挖掘,得到控制依赖图,合并数据依赖与控制依赖后的最终服务依赖图如图9所示。 (2)实验二:比较算法的执行时间 在前述20个社区,分别使用HFPGrowth算法、Apriori算法、FPGrowth算法进行关联规则挖掘,并比较算法执行时间,选取支持度为4~9,这里的支持度考虑了总的数据量和实际数据参考的值,同时,每一种方法进行10次实验,对10次实验结果的平均执行时间进行对比,结果如图10所示,相比FPGrowth算法,改进后的算法约有20%的运行效率提升。 (3)实验三:比较算法结果 将Louvain+HFPGrowth组合算法、Apriori、FPGrowth三种算法在实验一构造的服务关联网络图数据上进行实验,算法执行结果如表2所示。在同样的支持度下,Louvain+HFPGrowth的组合算法通过缩小范围从而获取符合服务依赖图的有序的关联规则项,有序的关联规则在实际环境下更能真实的体现服务组合运行过程中服务之间的执行过程,而Apriori和FPGrowth算法则是获得了很多无序等无用的关联规则项。 表2 3种算法下的结果挖掘数量对比 服务依赖关系的挖掘分析是近几年服务计算领域的研究热点。本文提出一种基于服务关联网络的服务依赖关系识别分析方法,首先利用有向图刻画服务关联网络模型,探索了一种通过已有组合服务分析服务控制流和数据流并构建服务关联网络的方法。利用图遍历算法、社区发现算法及改进的HFPGrowth算法识别并抽取服务之间的数据依赖及控制依赖关系生成服务依赖图,通过服务依赖图实现服务依赖关系的识别。最后通过实验验证了方法的可行性和有效性,并通过与几种经典算法的对比分析验证方法的效率。 服务依赖关系不仅能够支撑组合服务的划分与分布部署执行,还可以进一步支撑组合服务的构建、演化、以及组合服务的失效替换等。本文在这方面进行了探索和尝试。未来一方面拟结合服务链路执行动态数据对服务依赖关系进行修正与优化,另一方面将与分布式引擎结合进一步验证方法的有效性和执行效率。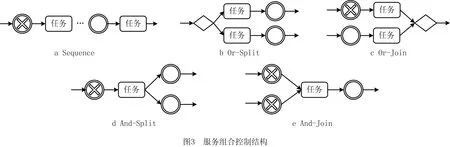
3.2 服务关联网络构建与更新
4 服务依赖关系识别
4.1 数据依赖图
4.2 控制依赖图

5 实验验证
5.1 实验环境及数据
5.2 实验及结果分析
6 结束语
