融合图像深度的抗遮挡目标跟踪算法
2021-10-09王希鹏
王希鹏, 李 永, 李 智, 张 妍
(武警工程大学 信息工程学院,陕西 西安 710086)
0 引言
目标跟踪是计算机视觉研究领域的热点之一,被广泛应用于自动驾驶、智能视频监控、人机交互等多个方面。单目标跟踪是指在给定第一帧目标框的情况下,在视频的后续帧中自动地标出该目标的位置和大小。早期的单目标跟踪算法以相关滤波为主,CSK[1]相关滤波算法采用灰度特征,KCF[2]算法在CSK算法的基础上做出了改进,采用了HOG特征。近几年,随着目标跟踪数据集的扩充、跟踪标准的完善、深度学习模型的不断优化,基于深度学习的目标跟踪方法取得了很好的成绩。SINT[3]是第一个使用孪生网络解决目标跟踪问题的算法。SiamFC[4]算法由于是端到端的跟踪网络,速度方面有了很大的提升,这使得基于孪生神经网络的跟踪器真正地流行起来。SiamRPN[5]在孪生网络的基础上将目标检测算法Faster R-CNN中的RPN模块应用到跟踪任务上来,回归分支代替了原始的尺度金字塔,因此该算法在提升精度的同时,速度也得到了提升。
在单目标跟踪问题中,算法的性能受到环境因素的影响,主要包括光照变化、尺度变化、目标遮挡等。尽管基于孪生网络的跟踪器已经取得了优异的性能,但依然存在一些缺陷。目标遮挡在目标跟踪任务中经常出现,在很大程度上影响了目标跟踪算法的性能。大部分基于孪生网络的跟踪器选取第1帧目标为模板,之后每一帧的搜索区域与目标模板比较,计算相似度,由于不更新目标模板,在目标被遮挡或发生形变时就会发生跟踪漂移。基于孪生网络的跟踪器仅提取图像深度特征用于视觉跟踪,忽略了图像中的语义信息,这导致基于深度学习的跟踪器在目标遇到遮挡或运动模糊的时候,跟踪性能只能依赖离线训练时特征的质量。Zhu等[6]提出了FlowTrack跟踪器,将光流信息整合到端到端的深度网络中,光流在计算上比较慢,而且光流仅提取连续帧中的运动信息。Wu等[7]用卡尔曼滤波器构造目标运动模型。
上述跟踪器使用了图像深度特征和目标的运动特征,但是忽略了图像中高层的语义信息。人眼在跟踪目标时,直觉上会估计出图像中场景的深度信息。场景的深度估计是机器人视觉领域的研究重点之一。很多研究将场景深度信息与跟踪任务相结合[8],但场景深度信息的提取都基于RGB-D相机,对硬件设备要求较高。单目深度估计领域相关技术的发展使得不需要RGB-D相机也可以得到场景的深度信息。早期单目深度估计的方法大多基于机器学习。Godard等[9]提出Monodepth2算法,使用深度估计和姿态估计网络的组合来估计单目图像中的深度,提升了深度估计的性能。通过单目图像深度估计可以准确得到图像场景中的深度信息,并利用像素值进行表示:当目标离相机较远时,像素值较小;离得较近时,像素值较大;当目标被遮挡时,跟踪框内的像素值会发生改变,从而可以判断跟踪目标是否被遮挡,并对跟踪器得到的目标位置进行修正。
本文主要针对目标跟踪中的遮挡问题,提出将Monodepth2算法得到的场景深度信息融合到SiamRPN跟踪器中,根据Monodepth2得到每一帧图像的深度信息:当目标没有被遮挡时,目标深度值在时序上的变化是平滑的;当发生遮挡时,目标深度值会快速变化。将SiamRPN与Monodepth2得到的响应图进行融合,克服目标被遮挡时产生的跟踪漂移问题。为验证本文算法的性能,利用OTB-2015[10]数据集中部分存在遮挡的视频序列进行测试。
1 融合图像深度的抗遮挡目标跟踪算法
1.1 基于孪生网络的目标跟踪算法
孪生网络主要用来衡量输入样本的相似性。SiamFC[4]分为模板分支和搜索区域分支:模板分支输入x,经过特征提取网络φ,可以得到一个卷积核φ(x);搜索区域分支输入z,经过特征提取网络φ,得到一个候选区域φ(z)。φ(x)与φ(z)进行互相关操作,得到一个响应图,如式(1)所示,其中⊗代表互相关运算。从响应图中选取响应最大的位置,作为目标当前的位置,进行多尺度测试,得到目标当前的尺度,如式(2)所示。
f(x,z)=φ(x)⊗φ(z);
(1)
p=argmax[φ(x)⊗φ(z)]。
(2)
SiamRPN将原来目标跟踪任务中的相似度计算转化为回归和分类问题,其中的RPN模块可以理解为一种全卷积网络,该网络最终目的是为了推荐候选区域。RPN中最重要的是anchor机制,通过预先定义anchor的尺寸和长宽比引入多尺度方法。SiamRPN中anchor有5种长宽比:0.33、0.5、1、2、3。通过平移和缩放对原始的anchor进行修正,使anchor更接近真实的目标窗口。
1.2 单目图像深度估计算法
由于像素级深度数据集难以获取,使得监督学习在单目深度估计中的应用受到限制,所以基于自监督学习或无监督学习的单目图像深度估计的研究越来越多。单目深度估计的输入为一帧RGB图像,输出为深度图,深度图中每个像素值表示该像素在空间中的位置Lp。Monodepth2算法利用单目和双目图像序列在自监督框架上进行训练。采用最小化像素投影损失,对每个像素进行计算,解决遮挡问题:
(3)
式中:pe表示光度重建误差;It表示每个目标视图;It′→t表示相对位姿。采用auto-masking方法过滤掉序列中相邻两帧固定不变的像素。选用多尺度结构,将低分辨率深度图上采样到输入分辨率,在高分辨率下重投影、重采样,计算光度重建误差。
在目标跟踪中,计算目标框区域内深度平均值作为跟踪目标的平均深度值:当目标没有被遮挡时,目标平均深度值在时序上的变化是平滑的;当目标被遮挡时,目标平均深度值会快速变化。本文采用在单目和双目数据集中训练的模型。Monodepth2算法深度图如图1所示,两张图片均来自目标跟踪的OTB-2015数据集,左侧均为原始图像,右侧均为由Monodepth2得到的深度图。

图1 Monodepth2算法效果Figure 1 Monodepth2 algorithm effect
1.3 融合图像深度的抗遮挡目标跟踪算法
在目标跟踪任务中,解决部分遮挡通常有两种思路:一种是利用检测机制判断目标是否被遮挡,如果被遮挡,则更新模板,提升模板对遮挡的鲁棒性[11];另一种是把目标分成多个块,利用没有被遮挡的块进行跟踪[12]。根据人的视觉知觉,当人在对视频中目标进行视觉跟踪时,会估计出视频中场景的层次关系,判断目标和干扰物的位置关系,减小跟踪过程中遮挡对目标跟踪的影响。根据上述思路,本文提出将图像深度信息引入到单目标跟踪算法中,构建遮挡判别模块,利用目标深度信息的变化判断遮挡情况并修正跟踪结果。
本文在SiamRPN跟踪算法中引入单目图像深度估计,利用深度信息进行遮挡判别,在发生遮挡时对SiamRPN的跟踪结果进行修正。算法框架如图2所示。算法输入为第t帧图像和第t-1帧跟踪目标的深度图。将原图像同时输入孪生网络跟踪器和深度估计算法,分别得到搜索区域内所有的锚点框、对应的响应得分和搜索区域深度图,将以上输出信息和前一帧跟踪目标的深度图输入遮挡判别模块得到预测的目标位置。

图2 融合图像深度的抗遮挡目标跟踪算法框架Figure 2 Framework of anti-occlusion target tracking algorithm based on image depth
每个锚点框的位置表示为(xc,yc,w,h),其中(xc,yc)表示锚点框的中心位置坐标,w和h分别表示锚点框的宽和高。Dt(x,y)表示当前深度图(x,y)位置上的像素值。Di为锚点框内的平均深度值。遮挡判别模块将所有N个锚点框的平均深度值Di与前一帧的跟踪目标平均深度值Dp作比较,得到深度差值。对所有锚点框的所有深度差值求平均值,得到平均深度差值M,计算式为
Di=mean(∑x,yDt(x,y));
(4)
(5)
通过锚点框与对应的响应得分S1得到当前最佳锚点框。由于目标跟踪任务中,环境因素的影响会导致深度估计准确率降低,固定的遮挡阈值会造成过多的遮挡误判,所以本文算法将平均深度差值M设置为遮挡阈值,遮挡判别计算过程如下:
(6)
式中:d为当前帧前15帧跟踪目标的累计深度平均值;Ds为最佳锚点框的平均深度值;当B=1时,判断目标为遮挡状态,B=0时,判断目标未被遮挡。
当判断目标被遮挡时,算法对孪生网络跟踪器生成的锚点框进行修正,将深度差值加权融合到锚点框响应得分中。锚点框响应得分分布在0到1之间,而深度差值数值变化较大,所以首先对深度差值|Di-Dp|进行归一化处理,将深度差值数值变换至0到1之间,将其作为遮挡判别的响应得分S2。将RPN模块输出的锚点框响应得分S1与遮挡判别响应得分S2进行加权融合,计算式如下:
S=S1·λ+S2·(1-λ)。
(7)
式中:λ为权重系数。
2 实验结果与分析
本文算法基于Python3.6实现,硬件实验环境为Intel Core i7-6700K CPU,主频4 GHz,内存8 GB,显卡GeForce GTX 1060配置的计算机。
为验证算法的有效性,本文采用OTB-2015[10]中部分存在目标遮挡的视频作为测试数据集,视频序列名称分别为Singer1、Walking、Walking2、Skating2-2、Bolt、David3、Girl2、Woman、FaceOcc2、Jogging-1、Human5。OTB数据集采用跟踪精确度和跟踪成功率两种评价指标。跟踪精确度计算了跟踪算法估计的目标位置中心点与标注的中心点之间的距离小于给定阈值的视频帧所占的百分比。跟踪成功率反映了算法估计的目标位置与标注位置之间的重合程度,当某一帧的重合程度大于设定的阈值时,则该帧被视为成功的,成功帧的总数占所有帧的百分比即为跟踪成功率。
本文anchor设置与SiamRPN算法一致,为0.33、0.5、1、2、3共5种长宽比。式(7)中权重参数λ的取值非常重要,需要通过实验确定,λ太大或太小都会引起跟踪漂移。本文赋予基准跟踪器响应得分更大的权重,λ∈[0.7,1]。表1为λ取不同值时的跟踪成功率和跟踪精确度。根据表1中性能对比,本文的融合权值λ取0.85。得到修正的响应得分S后,求出S中的最大值和对应的锚点框位置,将此锚点进行修正得到最终的坐标。

表1 λ取不同值时的跟踪结果Table 1 The tracking results with different λ values
测试跟踪器包括SiamRPN[5]、SRDCF[13]、Staple[14]、CFNet[15]、SiamFC[4]、fDSST[16]。表2中展示了7种算法在11个视频序列上的跟踪精确度,其中10个视频序列中本文算法的精确度均不小于基准跟踪器SiamRPN。SiamRPN作为孪生网络跟踪器,只学习了离线的通用特征,在跟踪目标被遮挡时,跟踪器判别能力不足,无法区分跟踪目标与遮挡物。本文提出的遮挡判别模型能有效地利用图像深度信息提升跟踪算法在目标被遮挡时的跟踪性能。
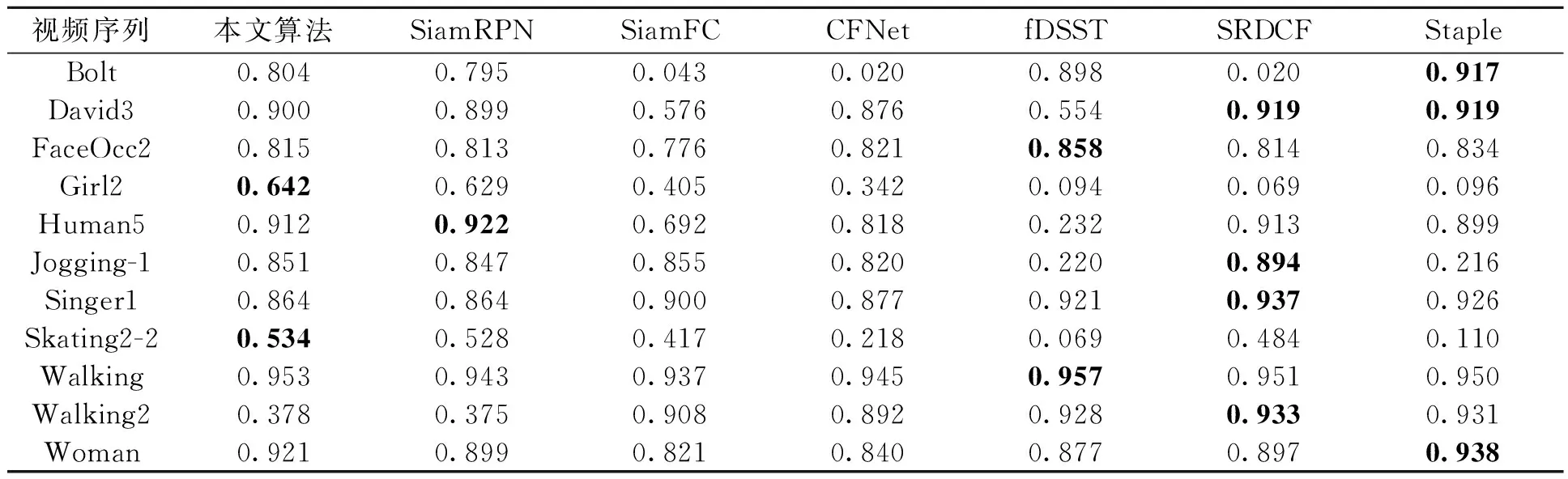
表2 不同算法在11个视频序列上的跟踪精确度Table 2 Accuracy on 11 video sequences using different algorithms
图3展示了跟踪算法在不同属性视频序列下的跟踪精确度对比,在这些属性的视频序列下,本文算法的跟踪精确度均高于基准跟踪器SiamRPN,在4种属性的视频序列中,平均跟踪精确度分别提升了0.009、0.005、0.01、0.008,图像深度信息在目标跟踪中起到了辅助作用。

图3 部分属性视频序列下的精确度曲线对比图Figure 3 Comparison of accuracy rates of video sequences with different attributes
图4为跟踪器在11个视频序列下的成功率和精确度曲线。在平均成功率上,本文算法(0.623)在SiamRPN算法(0.612)的基础上提升了0.011;在平均精确度上,本文算法(0.853)在SiamRPN算法(0.845)的基础上提升了0.008,分别提高了1.8%和0.9%。

图4 跟踪器在11个视频序列上性能对比Figure 4 Tracker performance comparison on 11 video sequences
图5记录了SiamRPN、SiamFC和本文算法在Woman、Skating2-2和Bolt这3个视频序列下的实际跟踪效果对比。紫色框为目标的标注框,红色框为本文算法结果,绿色框为SiamRPN算法结果,蓝色框为SiamFC算法结果。从图5中可以看出,本文算法在部分遮挡时的目标跟踪上取得了不错的效果。当目标被遮挡时,SiamRPN和SiamFC均会出现跟踪漂移的现象,而本文算法能有效缓解或避免此问题。
3 结论
为提高目标跟踪算法在目标遮挡场景下的适应性,提出将孪生网络跟踪器SiamRPN与单目图像深度估计算法Monodepth2结合。本文提出的基于深度信息的遮挡判别模型判断出目标是否被遮挡,有效地避免了跟踪漂移。若出现遮挡,算法会将原跟踪器的锚点响应得分与遮挡判别响应得分进行加权融合得到最终响应得分,重新选择锚点计算目标框的位置。针对OTB-2015中具有遮挡属性的11个视频序列进行测试。实验结果表明,在目标遮挡场景下,与6种主流跟踪算法相比,本文算法具备更优的跟踪性能。同时也说明,图像深度信息可以辅助提升目标跟踪的性能。下一步研究工作可针对遮挡判别策略进行改进或采用性能更优异的图像深度估计算法,进一步提高算法的跟踪性能,也可以尝试将此遮挡判别模块应用于其他跟踪算法中。
