基于改进编解码网络的极化SAR地物分类
2021-10-08闫成杰刘秀清
闫成杰, 王 沛, 刘秀清
(1. 中国科学院空天信息创新研究院, 北京 100190; 2. 中国科学院大学, 北京 100049)
0 引言
PolSAR图像地物分类是PolSAR图像解译中非常重要的一个分支。传统的PolSAR图像分类算法主要根据图像的统计特性或散射特性,采用支持向量机、随机森林和集成学习等分类器进行分类,然而由于图像斑点噪声和地物复杂性的存在,目前传统的机器学习方法不能取得令人满意的效果[1]。
近年来深度学习(DL)发展迅猛,在诸多领域取得了一系列突破。目前已有不少国内外学者将深度学习应用于PolSAR领域,Xu等[2]利用CNN实现了PolSAR图像相干变化的检测。Wang等[3]利用CNN模型对双极化SAR图像进行海冰分类,成功地实现了海冰密度的估计。
然而,以上方法[2-3]都是将PolSAR数据映射到实数域,然后进行切片预测,切片分类结果为中心像素点类别,因此存在边界不连续和计算冗余的问题,除此之外,映射过程也造成了一定的信息损失。近年来计算机视觉领域提出了语义分割技术,实现了端到端的像素级图像分类,例如FCN、SegNet、DeepLab和U-Net等。文献[4]利用 FCN实现了道路检测和中心线提取。文献[5]提出基于H-A-α分解输入的FCN,实现了快速PolSAR图像分类。虽然文献[4-5]中的模型解决了计算冗余问题,但是在解码的过程中图像位置信息丢失,边界不连续问题依然存在。编解码网络需要全标注的输入图像,这对于PolSAR图像来说很难获取,文献[6]使用带标记训练像素的零初始化地面真值图训练FCN模型,但是这种方法存在网络收敛速度较慢和边缘粗糙问题。
针对以上问题并结合PolSAR图像的特性,我们对经典的编解码网络作了一些改进。为了解决相位信息丢失问题,引入复数域CNN;为了解决边缘粗糙问题,引入辅助通道,采用反池化和特征图两种方式进行位置信息传递;为了提升对多尺度地物的分类能力,在编码网络的最后一层引入IASPP;针对地面真值未全部标记的问题,我们进行两阶段模型训练并使用动态标注和动态权重。综上,本文的结构安排如下:第一节介绍复数域CNN、IASPP、辅助通道以及上采样的两种方式。第二节详细介绍改进编解码网络及其训练流程。第三节为实验部分,在基于AIRSAR平台的16类地物数据上进行实验,验证本文所提出的算法的准确性和高效性。
1 关键改进
1.1 复数域CNN
目前在深度学习领域对SAR图像的分类研究大都集中在实数CNN。建模过程中,输入、网络参数和输出都是实数,需要将复数域SAR数据投影到实数域。投影必然会带来信息丢失,尤其是相位信息的丢失,然而PolSAR数据的相位信息对于PolSAR图像分类十分重要,因此将CNN推广到复数域,是十分必要的。
在复数域卷积神经网络(Complex-Valued-CNN, CV-CNN)中输入图像由实部和虚部两部分组成,表达式如下:
(1)
式中,c为X的通道数,m,n为图像尺寸。在编程实现时我们由两组交互并行的实数卷积网络来等效构成复卷积神经网络,Xr和Xi分别表示实部和虚部,相对应卷积核表达式如下:
(2)
式中,c,o分别为卷积层的输入、输出通道数,s为卷积核尺寸,Kr,Ki分别为卷积核的实部和虚部。
记Conv(·)为实数卷积,记Conv(·)为复数卷积,记KO为第o个卷积核,则复数卷积的具体计算表达式如下:
I′O=Conv(X,Ko)=
Conv(Xr+jXi,Ko,r+jKo,i)=
Conv(Xr,Ko,r)-Conv(Xi,Ko,i)+
j[Conv(Xi,Ko,r)+Conv(Xr,Ko,i)]
(3)
即复数卷积的输出为
(4)
1.2 改进型ASPP
和普通卷积相比,空洞卷积引入了扩张率参数,该参数定义了卷积核相邻点之间插入的零的个数(扩张率-1),如图1所示,分别表示普通卷积和扩张率为2的空洞卷积。
文献[7]指出多尺度特征有助于分类精度的提升,DeepLab[8]中受到空间金字塔池化的启发,提出ASPP,该方法使用具有不同扩张率的多个并行的空洞卷积层进行多尺度特征提取,最后将多个分支提取的特征进行融合。然而当扩张率过大时只有部分像素点参与计算,大量的信息丢失,因此文献[9]提出DenseASPP,DenseASPP其实是多个串行的空洞卷积层,感受野逐层递增。
由于训练数据集较少,如果采用DenseASPP 结构,深层网络模型训练难度较大,所以本文将ASPP和DenseASPP进行结合,提出了改进型空洞空间金字塔池化(IASPP)。IASPP结构如图2所示,整体结构类似DenseASPP,两层ASPP级联,最后经过3×3卷积融合特征和通道降维得到多尺度特征图。

图2 IASPP结构图
假如空洞卷积扩张率为d,卷积核大小为k,则其感受野大小为
R=(d-1)×(k-1)+k
(5)
两个感受野分别为R1、R2的卷积层,级联后的感受野为
R=R1+R2-1
(6)
IASPP实际扩张率组合如图3所示,最大感受野为33,而后续编码网络最后一层的输出尺寸为32×32,因此33的感受野足够大且不会因为过大而引入背景噪声,除此之外,多种感受野的组合能够捕获更多的多尺度特征。

图3 级联ASPP扩张率组合
1.3 辅助通道
PolSAR图像的特征可以分为以下4个类别[10]:
1) 基于辛克莱(Sinclair)散射矩阵[S],比如交叉极化比和共极化比;
2) 基于协方差矩阵[C]、相关矩阵[T]的极化目标分解特征;
3) 纹理特征;
4) 空间语义特征。
卷积神经网络低层部分学习纹理等简单信息,高层部分学习高级语义信息,所以CNN只是利用了3)、4)的特征来进行分类。1)中的特征在传统的分类中也不常用,在此不予考虑。对于2)中的极化目标分解特征,文献[11]中指出可以分为4种:基于K矩阵的二分量分解、基于散射模型的目标极化分解、基于特征矢量的目标极化分解和基于散射矩阵的相干分解。
为了引入极化目标分解特征,我们增加了辅助通道,整个辅助通道只采用1×1的卷积。对应以上4种分解,我们分别选取了Huynen分解,Freeman-Durden三分量分解,Cloude分解和Krogager分解组成一个12维的分解特征,以此作为辅助通道的输入。辅助通道本身作为一个独立的模型,具有分类的功能,所以辅助通道除了将位置信息传递给解码网络进行特征融合,还将分类结果传递给主通道进行模型融合。
1.4 双通道上采样
编解码网络为了实现端到端的像素级图像分类,需要在解码网络中使用上采样。本文使用上池化[12](unpooling)和反卷积&特征图两种上采样方法:上池化是指在编码网络中记录最大池化索引,在解码网络中利用该索引进行上采样得到稀疏的特征图,然后进行卷积操作生成密集的特征图,主通道编码网络的位置信息采用此种方式传递给解码网络,具体过程如图4所示;反卷积&特征图指把编码网络中池化之前的特征图存储下来,在解码网络中和反卷积得到的特征图进行融合,这样既保留的位置信息,又获取了高层的语义信息,辅助通道的细节信息通过这种方式传递给解码网络。

图4 上池化示意图
2 改进编解码网络
本节将介绍所提出模型的具体结构和训练流程。
2.1 改进编解码网络整体架构
整个网络架构如图5所示,由主通道和辅助通道组成。主通道是常规的编解码架构,辅助通道通过解码网络和主通道进行交互。主通道在复数域进行计算,辅助通道在实数域进行计算。
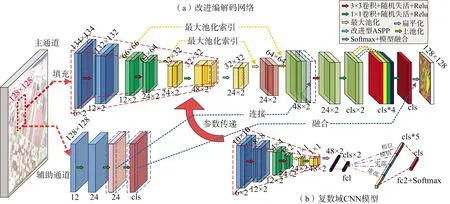
图5 模型结构
编码网络由3个卷积层构成。对于模型输入数据和每个卷积层的输出数据进行归一化处理,用以加快模型的收敛速度并缓解梯度弥散问题。归一化处理之后,使用Relu函数激活,使用尺寸 2×2,步长为2的窗口池化。对每个卷积层的参数进行随机失活(dropout),用于增加网络的泛化性能。从结构图中我们可以看到解码网络还连接了多尺度层,多尺度层的作用以及实现方法我们在1.2节已经进行了详细阐述。最终编码网络的输出作为解码网络的输入。
解码网络将输入进行上采样,最终实现像素级概率图的生成,其中上采样是实现精确的目标分割的关键步骤。主辅通道上采样方式如1.4节所述。主辅通道组合得到的特征图通过卷积进行融合,使得与目标密切相关的部分得到放大,同时有效抑制来自其他区域的噪声,最终生成准确的分割图。
2.2 训练流程
模型训练分为两步,首先训练复数域CNN模型,输入为以样本点为中心的10×10的切片,输出为切片中心点属于每个类别的概率。然后进行参数传递并训练改进编解码网络,具体训练流程如下:
算法1改进型编解码网络
输入:协方差矩阵[C],分解特征D,真值标签G。
1) 将真值标签G未标记的区域记为其他类,对像素点权重W进行初始化;
2) 以步长为64的128×128滑窗在[C]和D上进行切片,获得训练数据;
3) 读取存储的复数域CNN模型,将参数转移到主编码网络并冻结,只训练解码网络和辅助通道部分;
4) 每次迭代得到预测结果M,根据M更新W和G;
5) 根据更新的G和W进行下一轮迭代训练。
输出:像素级的分类结果。
算法1详细介绍了编解码网络的训练流程。针对输入数据只有部分标注的问题,我们将未标记区域初始化为其他区域,利用每一次训练的结果对这些区域进行伪标注,并作为下一轮学习的目标。除此之外,我们还引入了权重矩阵W,权重矩阵W的取值可以分为welse和wtrain两大部分:welse为伪标注区域权重,赋予较小的值(本文采用1)且是固定的,虽然伪标注区域的标签不完全正确,但是给伪标注区域赋予较小的权重,实验证明整个网络也是迭代收敛的;wtrain为标注区域权重,取值相对welse较大且是动态变化的,每一轮训练之后对wtrain进行更新,预测正确的像素点权重不变(本文采用10),预测错误的像素点赋予更大的权重werror(本文采用50),这种动态的权重使得模型更多的关注区分难度比较大的类别。
3 实验结果与分析
在本结中,首先给出了实验数据集的描述和实验结果评价指标,然后在PolSAR数据集上进行7组实验:实数域CNN、复数域CNN、原始U-net网络、编解码网络(M1)、编解码网络+预训练(M2)、编解码网络+预训练+多尺度(M3)、编解码网络+预训练+多尺度+辅助通道(M4),证明了本文采用的算法以及算法中所采用的策略的有效性,其中M1-M3采用反卷积&特征图进行位置信息传递。后续统一以括号中的简写来指代网络模型。实验基于Tensorflow深度学习框架,运行环境为NVIDIA GeForce GTX 1050-ti GPU(4 GB内存)、Intel(R) Core(TM) i5-8300H CPU@2.3 GHz(16 GB内存)。
3.1 数据集和评估指标
本文使用基于AIRSAR平台的荷兰Flevo-land地区PolSAR数据进行实验。图6(a)为Flevo-land基准数据的Pauli图像。地面真值标签和颜色对应关系分别在图6(b)和图6(c)中示出,图6(b)中的黑色区域为未标注区域。图像中有14类农作物和2类人造目标,包括土豆、水果、燕麦、甜菜、大麦、洋葱、小麦、豆类、豌豆、玉米、亚麻、油菜、草和苜蓿以及道路和少量建筑。

图6 Flevoland地区PolSAR数据
本实验采用Kappa系数、总体精度(OA)和类特定精度(PA)对实验结果进行评估。Pab表示真值为a预测值为b的点数,则ta=∑bPab表示类别a的像素点总数,则有以下定义:
类特定精度PA表示每个类别的预测正确率:
(7)
总体精度OA表示整个图像预测的正确率:
(8)
Kappa系数是一个统计量,表示预测和地面真值之间的一致性:
(9)
其中求和符号的取值范围是预测的类别。
3.2 实验结果
M1和M2模型的训练集和验证集收敛曲线分别如图7和图8所示,为了便于观察,两幅图的收敛曲线都作了适当的平滑处理和缩放。由图可知,M1、M2在训练集上的表现相差无几,但是在验证集上M2的整体OA更高,而且由于M2的编码网络经过了预训练,整个网络的收敛速度明显快于M1。图8中损失曲线先下降再上升,这是典型的过拟合表现,有趣的是在损失上升的过程中验证集的OA依然在提升,文献[13]对该现象进行了解释。

图7 M1和M2模型训练集收敛曲线

图8 M1和M2模型验证集收敛曲线
表1是7组对比实验的分类结果,每种地物的采样率不高于10%。切片预测时间约为130 s,而编解码网络预测时间约为3 s,速度提升了约44倍。除了预测时间,我们还从Kappa系数、OA、PA三个指标来综合评估算法的性能。由表1可知复数域CNN相比实数域CNN,OA和 Kappa系数分别提升1.01%、1.90%。文献[14]指出原始U-net模型不适合直接应用于遥感领域,本文M1模型和原始U-net模型相比,基本结构一致,但是具有更少的网络层数和通道数,在保证训练精度的情况下,增加了泛化能力,实验结果表明M1表现更好。M2和M1的对比见上一段落。M3引入多尺度,在7组实验中道路PA最高,达到了97.15%。M4相比M3引入了辅助通道,在草地、土豆等多个类别实现了最高PA,而且整体OA和Kappa分别为99.18%、98.90%,在7组实验中最高。
图9为Flevoland地区PolSAR图像分类结果图。图9(c1)~(c4)的图像组成部分从左到右、从上到下分别对应图9(b1)~(b4)中的A、B、C、D、E、F六个区域,黑色为未知区域,绿色为预测正确部分,红色为预测错误部分。从标注区域来看,M2相比M1整体预测误差明显减少。M2编码网络参数由复数域CNN转移得来,根据复数域CNN的训练流程可知,M2编码部分的感受野只有10,对于大尺度物体预测性能有待改进。M3和M2相比引入了IASPP,可以发现A和C区域的道路误差几乎消失不见,然而引入多尺度的同时也会引入一些背景噪声,这也就造成了E、F区域的预测效果有所下降。M4通过辅助通道引入单点信息,弱化了纹理特征,强化了细节,因此M4和M3相比,B、E、F区域的分类边缘误差降低,但是A区域中道路预测误差增加。
综上,对比实数域CNN和复数域CNN,可知复数域的引入使预测性能有了较大的提升;对比编解码网络和复数域CNN,可知编解码网络的预测速度有了质的飞跃,同时预测精度也有所提升;对比U-net模型和本文提出的M1-M4模型(M1和U-net、M2和M1、M3和M2、M4和M3为4组对照实验),证明了算法各个改进部分的有效性。综合对比7组实验,本文提出的M4模型整体表现最优。

表1 荷兰Flevoland地区PolSAR图像分类结果

图9 Flevoland地区PolSAR图像分类结果
4 结束语
为了充分利用PolSAR图像的相位信息并提高分类速度,本文提出了改进编解码网络,将PolSAR数据的实部和虚部进行并行交互处理,间接实现了复数域CNN, 并且引入IASPP和辅助通道来进一步提升算法性能,训练过程中通过参数传递加速收敛。在荷兰Flevoland地区PolSAR数据上进行7组实验,实验结果验证了本文所提出算法的有效性。针对地面真值难以全部标注的问题,本文提出了动态标签和动态权重的方法,虽然最后实验证明能够收敛,但欠缺严格的数学证明,寻找更加严谨有效的解决方案是接下来的重点研究方向。如何能够更加准确地区分极化特性近似的地物,也是后续工作重点之一。
