基于嵌入式端的动态气体轻量化分析方法研究*
2021-09-29贾颖淼李紫蕊范书瑞
贾颖淼,李紫蕊,范书瑞,张 艳
(河北工业大学电子信息工程学院,天津 300401)
动态气体的分析在检测气体泄漏源[1],环境监测[2-3],估计气源距离[4]等方面有巨大应用。在复杂的动态环境中,传感器的响应曲线受周围环境的温度,湿度以及空气的方向和速度的影响[5-6],导致气体羽流发生复杂的不规则变化,另外,当存在不同种类的气体时,复杂环境也会导致多种气体的不均匀分布。
为了对室外复杂环境中的气体进行准确识别,深度学习被应用到气体识别领域中。Mishra等人[7]利用最简单的四神经元人工神经网络对进行了归一化差分处理(NDSRT)的传感器数据进行分类,把原始传感器响应转换成为具有浓度不变性的虚拟多传感器使用,所有的测试样本在变换后都得到了准确分类。张天君等人[8]使用LSTM基于煤矿实际生产时检测的时间序列预测瓦斯浓度,可以较好的预测出瓦斯浓度,预测误差在0.000 5~0.040 0之间,在拐点处的预测误差也保持在0.014以下。之后,他又提出了基于RNN的多参数融合预测模型对瓦斯浓度进行预测[9],对瓦斯浓度时间序列的预测精度较高,可作为矿井瓦斯浓度预测的参考模型。胡志伟等人[2]利用K-最近邻算法(KNN)与深度卷积神经网络相结合,实现了空气质量的短期预测。但是模型较为复杂,数据处理繁琐。但以上算法均在PC端实现,具有训练的模型大,参数多;训练缓慢;功耗大和成本高等问题,如何在终端设备上运转深度学习相关算法,实现模型的轻量化人工智能的设计,是我们还面临的一项挑战。
陈寅生等人[10]利用基于KPCA和MRVM算法实现了二元混合气体的准确识别,准确率达到了99.83%。李紫蕊等人[11]研究了基于随机森林和粒子群优化的SVR混合气体的定量分析方法,可以准确的对混合气体进行分类并且预测气体浓度。但是由于EAIDK-310支持的安装包的格式为aarch64类型文件,而sklearn官网上提供的安装包没有此种类型的文件,这种情况导致sklearn在EAIDK-310上无法安装,从而论文中提出的方法暂时无法在EAIDK-310上部署调用。
为解决上述问题,本文研究了基于CNN的气体浓度预测方法,提出了用于动态气体识别的轻量级卷积神经网络架构FD-CNN(fast detection-convolutional neural network),采用OPEN AI LAB的EAIDK-310开发板作为嵌入式端智能平台,将在PC端训练好的气体模型部署到嵌入式端实现气体的成分识别以及浓度预测,测试模型在嵌入式端的有效性和可靠性,得到空气质量分析结果。
1 PC端模型搭建
1.1 网络模型结构搭建
赵小今提出的1D-CNN[12]、Guangfen Wei提出的改进型LeNet-5[13]Peng Pai提出的GasNet[14]均是基于CNN的气体识别方法,与这三种方法相比,本文提出的网络结构层数较少,只包括一个卷积层和一个最大池化层用于提取和选择特征,一层Flatten层将多维数据转换为一维数据,两层全连接层将学习到的分布式特征映射到样本标签中。
如果将模型应用于动态气体的成分识别,最后一层全连接层有5个神经单元,激活函数选择“Softmax”,使输出结果为测试样本属于各个类别的概率;如果将模型应用于回归预测,网络最后一层只有一个神经单元,激活函数选择“lineaer”,使输出结果预测的气体浓度。如图1所示。
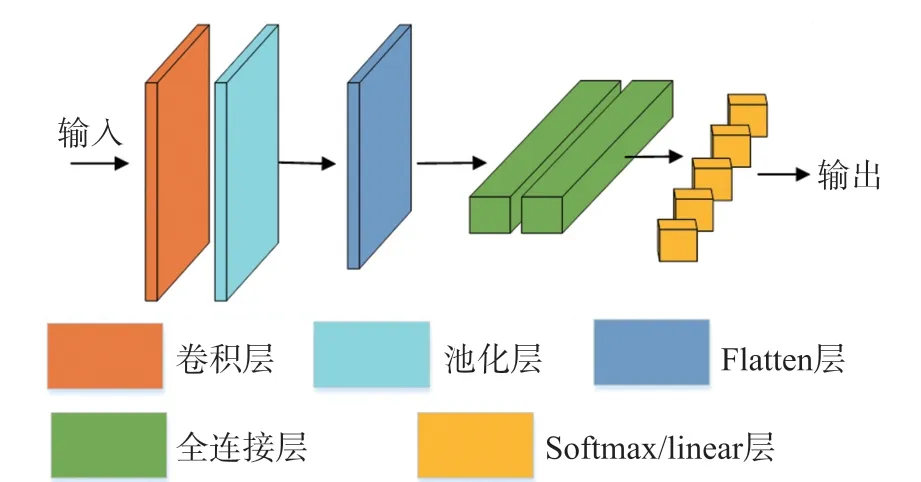
图1 FD-CNN网络结构
网络中,卷积核大小为3×3,数量为64个,Padding选择为SAME,步长为1,以保证卷积层的输入输出形状不变,池化层步长为2,减少输出特征图的大小。第一层全连接层有128个神经单元。网络结构优化参数选择如表1,权重W的初始化方式为Glorot uniform initializer,由均匀分布来初始化数据,偏置b初始化为0。利用Adam进行优化,其超参数设置为默认值,Adam优化器实现简单,对内存需求少,其超参数具有很好的解释性,通常无需调整,属于默认工作性能比较优秀的优化器,适合本问题。用均方误差(MSE)作为优化的目标函数,均方误差代表预测值与真实值之差平方的平均值,计算公式如式(1)。m为预测样本数量,yi为第i个样本的预测值,为第i个样本的真实值。

表1 参数设置
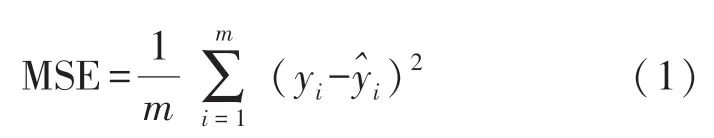
训练过程中选用随机梯度下降法进行多次迭代训练,迭代次数设置为150,在每次训练迭代中,从训练数据选择N个样本作为一批数据而不进行替换,然后,利用神经网络的正向传播来计算损耗,利用反向传播来更新参数。在反向传播中,通过最小化损耗对θ的梯度乘以一个小的步长α(称为学习率)的梯度来更新每层的参数θ(包括权重W和偏置b),如式(2)。
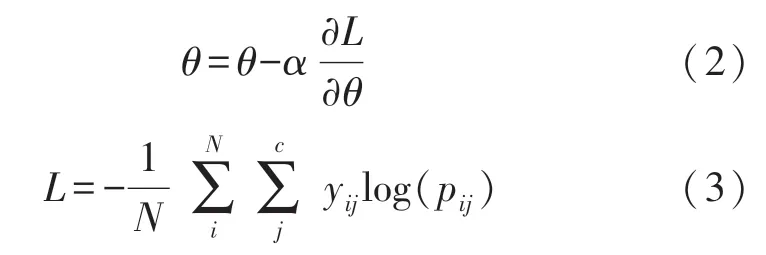
1.2 训练与测试模型
对动态气体进行成分识别时,输入样本数据的大小是100×8,经过150次迭代训练,训练过程中损失值和准确率的变化如图2,其中带“+”的代表训练集损失,平滑曲线代表训练集准确率,可以看到在训练过程中,损失值下降,准确率上升,最后损失值平稳在0.02左右,准确率平稳在98%。

图2 气体成分识别模型训练时损失和准确率变化
对混合气体进行回归预测时,利用文献[11]中预处理后的数据,网络结构的输入数据尺寸为(1,4,1),即每个训练样本的大小为1×4,只有1个通道。经过150次迭代训练,损失值和MAE的变化过程如图3所示,其中带“+”的代表训练集损失,平滑曲线代表训练集MAE,可以看到在训练的过程中,损失值和MAE都在不断地下降,最后损失值平稳在16附近,MAE平稳在2附近。
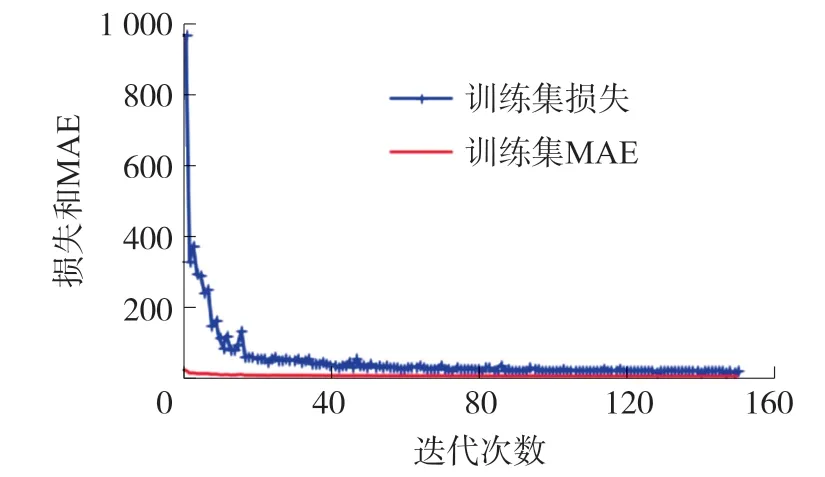
图3 气体浓度预测模型训练时损失和MAE的变化
2 模型部署
模型的部署完整流程图如图4所示,模型由计算机端部署到嵌入式端。在windows系统下利用Keras框架训练得到的分析模型为.h5文件,首先将其转换为Tensoflow的.pb文件,然后在Ubuntu系统中利用tengine模型转换工具将模型由.pb文件转换为.tmfile文件,以上操作均可以在计算机端完成,最后在EAIDK-310板子上的Linux系统下完成模型的调用与气体的分析。
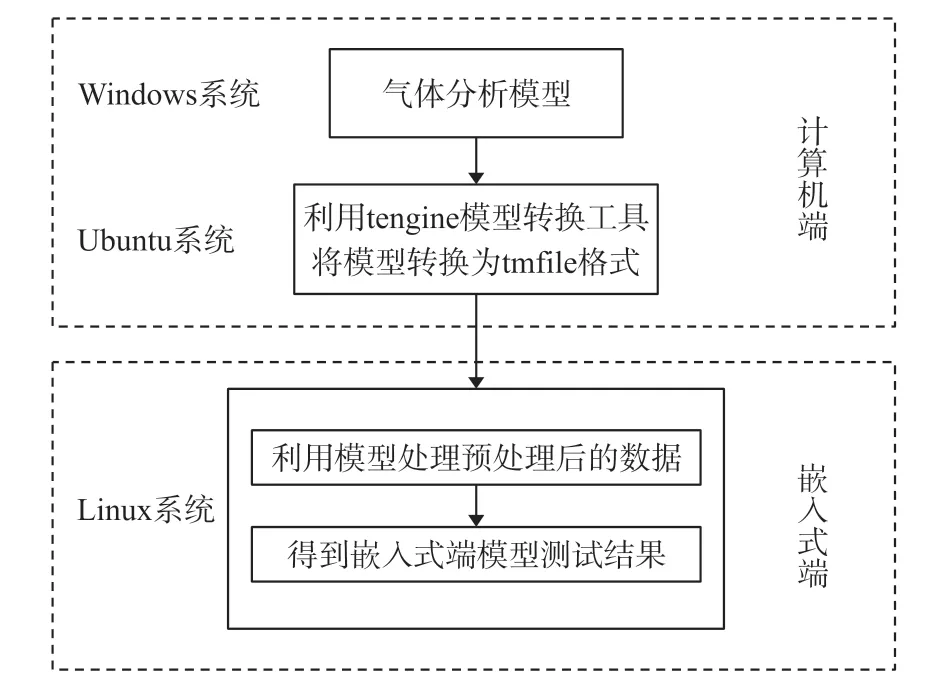
图4 模型部署流程图
2.1 模型转换
通过第1节PC端的训练,我们得到了FD-CNN.h5模型,此模型是在Kears框架下利用CPU训练得到的模型,h5文件包含模型的结构,以便重构该模型;模型的权重;训练配置(损失函数、优化器等)和优化器的状态。而嵌入式端Tengine的模型文件为.tmfile文件,因此需要将FD-CNN.h5文件转换为FD-CNN.tmfile文件。
Tengine的模型转换工具仅支持Caffe、Onnx、Mxnet、Tensorflow或tf-lite模型向tmfile模型的转换,因此首先要在计算机端的windows系统下将.h5模型转换为Tensorflow的.pb模型。.pb文件包含了计算图,可以从中得到所有operators的细节,也包括tensors和Variables定义,因此只能从中恢复计算图。
我们首先读取载入FD-CNN.h5模型文件,识别模型网络中的张量数据的类型/格式、运算单元的类型和参数、计算图的结构和命名规范,以及它们之间的其他关联信息。然后将得到的模型结构和模型参数信息翻译成Tensorflow框架支持的代码格式。在Tensorflow框架下保存模型,即可得到FD-CNN.pb模型文件。
将.pb模型利用模型转换工具转换为.tmfile,命令格式为:
[Usage]:./install/tool/convert_model_to_tm[-h][-f file_format][-p proto_file][-m model_file][-o output_tmfile]
convert_model_to_tm是tengine提供的模型转换工具,其中,-h代表help选项,-f指定模型框架类型,此处指定tensorflow,-m指定源模型路径,-o指定转换后的Tengine模型路径。
2.2 模型调用
EAIDK-310上自带的操作系统为Fedora28,在系统上进行的模型迁移和部署操作都是基于Tengine框架的,因此首先要利用下载工具下载tengine源码,安装依赖包,并编译源码。
Tengine框架支持Caffe、TensorFlow等模型文件,可以在此开源框架下进行模型的测试工作。Tengine核心API流程如图5所示,首先利用init_tengine函数初始化Tengine,此函数仅调用一次,然后创建Tengine计算图,在运行前分配所需资源,接着运行Tengine图推理,推理完成之后使用两次postrun_graph函数停止运行图并释放所占资源,最后销毁创建的计算图。
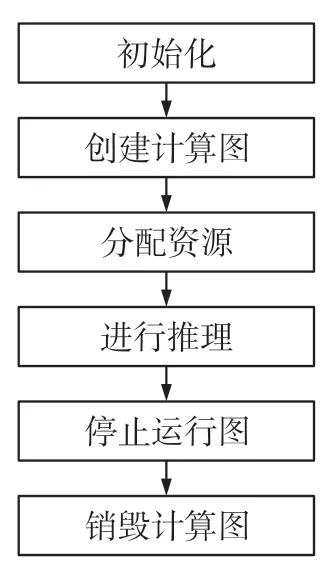
图5 Tengine核心流程
3 实验结果与分析
3.1 数据描述
本文用于动态气体混合物的快速成分识别的数据是TGM数据集[15],此数据集在风洞中获得,拥有两个独立气源,其中一个气源释放乙烯气体,另外一个气源释放一氧化碳(CO)或者甲烷气体,不同浓度的气体随着湍流自然混合,由8个化学电阻性气体传感器收集。因此完整的数据集由重复6次的30种气体组合组成,因此一共进行了180次测量,得到了180个样本,每次测量时间是300s。数据集中有甲烷(Met)、乙烯(Eth)、一氧化碳(CO)、乙烯-一氧化碳(Eth-CO)、乙烯-甲烷(Eth-Met)五种类别的样本,同时每类样本中混合气体的浓度并不相同,对数据进行动态时间规整(Dynamic Time Warping,DTW)预处理,以及滑动窗口再取样,以增加样本数量,减小样本尺寸,使每个样本的维数为(2970,8),预处理后得到的样本集如表2。
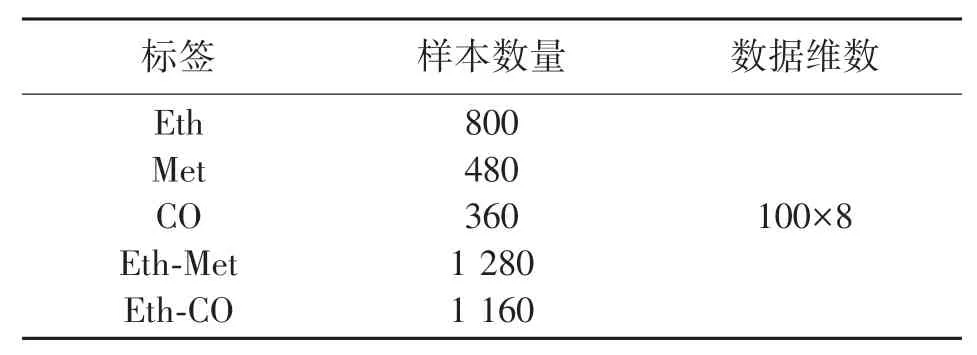
表2 预处理后的数据集
由于数据集种各个类别的数量不同,使用分层抽样划分训练集和测试集,其中,训练集占90%,测试集占10%,此次分层抽样得到训练集中3 672个样本,测试集中408个样本。训练集用于FD-CNN模型的训练,测试集用于计算机端以及嵌入式端模型的测试。
对混合气体进行回归预测时,实验样本基于UCI数据集[16],该数据集由不同浓度的甲烷、乙烯、空气以及其混合物在16个传感器(TGS2600、TGS2602、TGS2610、TGS2620(每种类型有4个单元))的阵列下的响应组成,持续测量的时间为10 486 s。对数据进行归一化以及主成分分析后,发现前4个主成分的累计贡献率达到99.69%,因此前4个主成分足以代表的特征信息。
本文选取15 499行单一气体甲烷的数据进行实验,预测其浓度。经过特征提取后,数据大小变为15 499×4。对降维后的数据按照1∶1的比例划分训练集和测试集,其中训练集用于模型的训练,测试集用于测试PC端训练模型的准确率以及模型部署在嵌入式端之后的效果。测试集中一共包含7750个测试样本(每个样本代表1 s的数据)。
3.2 PC端气体分析
对动态气体进行成分识别时,将提出的FD-CNN模型与1D-CNN,Improved LeNet-5,GasNet进行比较。由于本次实验样本中有5中类别,因此我们需要使用多分类的评价指标来衡量他的分类性能,针对多分类模型的评价,可以将多分类问题转换为二分类问题,这样可以得到模型预测的准确率,Precision,Recall,F1-score,AUC等。除此之外,我们还可以利用直接定义的多分类指标Kappa系数以及海明距离等,如表3所示。此外,我们还比较了模型的训练时间,模型预测样本的时间,以及不同模型的惨呼量来衡量模型的效率,如表4所示。实验的所有模型使用的训练和测试数据相同。

表4 不同模型的效率比较
从表3中可以看出,GasNet的准确率、Precision、Recall和F1-score在四个模型中都是最好的,本文提出的模型FD-CNN在准确率和Precision上略差于GasNet,但AUC比GasNet较好,除1D-DCNN外,其余三个模型的AUC均在0.99以上,相差不大。KAPPA系数和海明距离是常用的多分类评价指标,KAPPA系数在实际应用中一般取值[0,1],系数的值越高,代表模型实现的分类准确度越高,四个模型中GasNet的kappa系数最高,其次是FD-CNN和Improved LeNet5,1D-DCNN最小。海明距离衡量预测标签与真实标签之间的距离,取值在也在[0.1]之间,其值越接近0,证明预测标签与真实标签之间距离越小,预测越准确,四个模型中,也是GasNet的海明距离值最小,其次是FD-CNN。所以,但从分类性能来看,GasNet的分类性能略优于FD-CNN,但是两者差距不大,两者的分类性能明显优于Improved LeNet5和1D-DCNN模型。
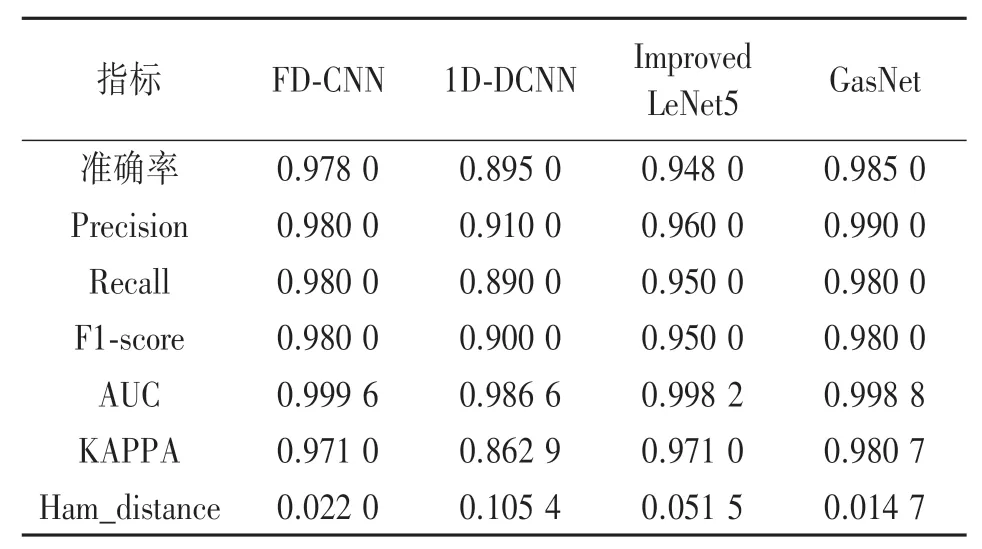
表3 不同模型的分类性能
如果从模型训练的效率来看,表4可以明显看出GasNet的训练参数最多,PC端训练模型的消耗时间也明显最长,其消耗时间是FD-CNN的4倍左右,模型预测所需要的时间更是FD-CNN的16倍,这是因为GasNet的模型结构比FD-CNN复杂的多,除去输入层和输出层,他有12次卷积归一化组合,共26层,这也是他的分类性能较好的原因。而FD-CNN用6层结构可以与GasNet模型达到相似的分类性能,是由于选取的网络层均具有代表意义,可以以最少的层数达到最好的分类效果。与Improved LeNet5相比,FD-CNN的参数量虽然更多,但是模型训练所需要的时间以及预测时间比Improved LeNet5少,且其分类性能也明显优于Improved LeNet5。对于1D-DCNN,他的参数量与FD-CNN类似,但是预测时间是FD-CNN的6倍。
除了模型的分类性能与效率,本模型是为了快速检测设计的,因此对于输入数据的长度也有要求,FD-CNN和ID-DCNN只需要输入10 s的数据便可得到分类结果,Improved LeNet5需要输入180s的数据,而分类性能最好的GasNet则需要300 s的数据才能得到分类结果。
综上所述,本文提出的FD-CNN分类性能与复杂的GasNet相似,但结构比GasNet简单的多,消耗时间是GasNet的1/16,其分类性能又明显优于效率相似的Improved LeNet5,各项指标均比Improved LeNet好,因此FD-CNN可以在网络层数最少且训练时间相对较短的情况下可以实现出色的测试准确率,在快速检测场景中,可以达到较高的准确率与效率。
对动态气体进行浓度预测时,利用FD-CNN模型对7 750个测试样本进行预测,并将预测结果与基于粒子群优化的SVR方法作比较,以均方根误差(RMSE),均方误差(MSE),平均绝对误差(MAE)以及R2为评价指标,评判模型拟合度的好坏,结果如表5。

表5 PC端浓度预测评价指标结果
由表5可以看出PSO+SVR的RMSE、MSE、MAE值均较小,但R2的值较大,证明PSO+SVR单纯在计算机端的回归预测效果好于FD-CNN,但是由于EAIDK-310的限制,sklearn安装包无法在EAIDK-310上安装,导致PSO+SVR模型无法部署在嵌入式端,并且发现使用FD-CNN的模型于PSO+SVR的R2只相差0.02,差距较小,也可以较好的进行回归预测,在测试集中选取140个样本点画出利用FD-CNN预测得到的预测浓度以及实际浓度的曲线图如图6。可以看到实际浓度与预测浓度曲线基本重合,图7是预测误差曲线图,可以看到,随机选取的140个样本中,预测误差最大为8×10-6,大部分误差在4×10-6以下,围绕2×10-6波动。
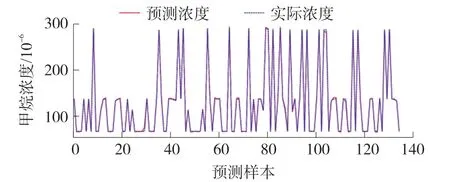
图6 计算机端FD-CNN浓度预测结果

图7 FD-CNN浓度预测误差
3.3 嵌入式端性能评估
将FD-CNN部署在EAIDK-310上,调用其模型运行应用程序对测试集进行测试,测试集中共有408个测试样本,每个样本中包含10 s的数据,表6中展示了随机挑选的10个样本的识别结果,识别完成后模型输出预测的最高概率及其对应类别,可以看到这10个样本全部识别正确,预测为此类别的概率全部为1.000 0(输出保留四位小数),识别效果较好,同时每个样本的消耗时间在13 ms以内,识别速度很快,效率较高。

表6 嵌入式端FD-CNN成分识别结果
修改模型中的最后一层全连接层以及激活函数,对甲烷气体的浓度进行预测,调用模型执行应用程序后,得到对7 750个测试样本的浓度预测结果。表7中列出了随机挑选的10个样本的预测结果以及进行浓度预测所消耗的时间。
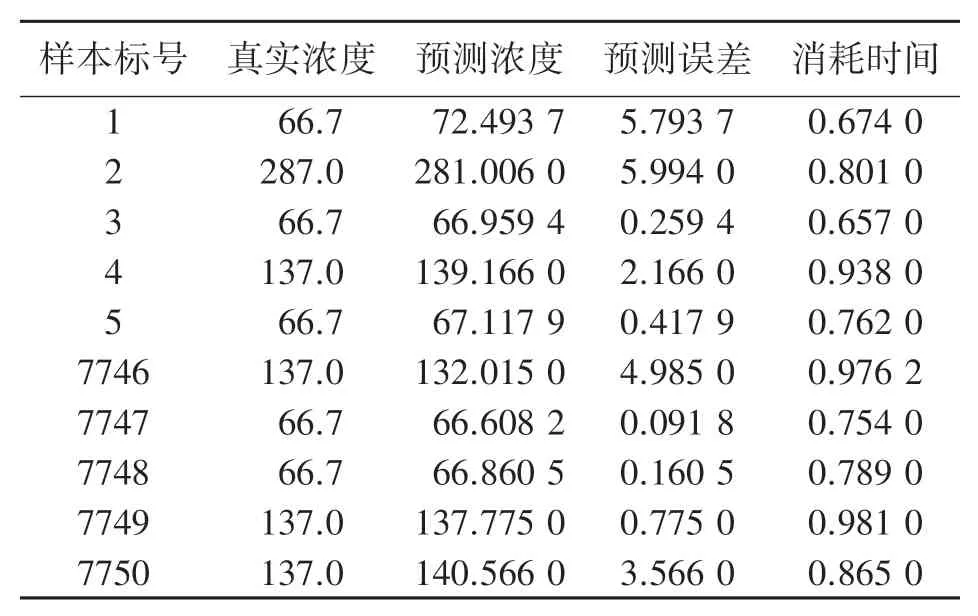
表7 嵌入式端FD-CNN浓度预测结果
可以看出10个样本的预测误差均在6×10-6以下,其中有5个样本预测误差在1×10-6以下,发现预测准确度很高,预测误差较小,10个样本的消耗时间均在1 ms以下,可以知道预测速度很快,效率较高。
4 结论
本文提出一种基于嵌入式CNN的气体分析方法FD-CNN,进行了气体分析模型在嵌入式端的移植部署,将计算机端训练好的FD-CNN模型通过格式转换、模型调用等步骤部署到EADIK-310上,在嵌入式端测试模型的有效性。实验结果证明,提出模型可以实现快速检测条件下的气体识别,识别准确率和效率均高于其他模型,在浓度预测方面,与PSO+SVR的预测效果近似相同,R2达到了0.994,与PSO+SVR仅仅相差0.02,识别准确率较高。经FD-CNN部署在嵌入式端后,发现成分识别和浓度预测的准确率都比较高,随机抽取的10个样本,在嵌入式端全部识别正确,且预测的浓度误差也保持在6×10-6以内,成分识别消耗时间保持在12 ms~13 ms之间,浓度预测的消耗时间在1 ms以下,计算效率很高。此次测试证明了在EAIDK-310上可以以高效率、高准确率实现空气质量分析。
