英文作文跑题智能化检测技术及应用
2021-09-29刘娜
刘娜
(咸阳师范学院 外国语学院, 陕西 咸阳 712000)
0 引言
英文作文的内容是否紧扣题目,是判断作文质量和给出评分的重要依据。目前英语教学中用于辅助作文评分的系统对于跑题文档的检测能力普遍不足[1-3]。因此,本文提出并设计了一种英文作文跑题智能化检测算法,创建LDA(Latent Dirichlet Allocation,潜在Dirichlet分布)模型以获取文档的主题及其分布信息,利用Word2vec模型对词向量进行训练从而进一步获取词项表达的语义,最后通过二者的结合进行跑题检测。该算法弥补了传统算法对词项语义信息缺少分析的不足,具有很强的实用性。
1 创建LDA模型
1.1 LDA模型
LDA模型是一种非监督机器学习算法,主要用于提取包含在文档集中的主题信息,其结构为“文档—主题—词”的形式,描述了由词汇表达主题,由主题构成文档的文档集构建过程[4-5]。LDA模型下的文档集结构,如图1所示。
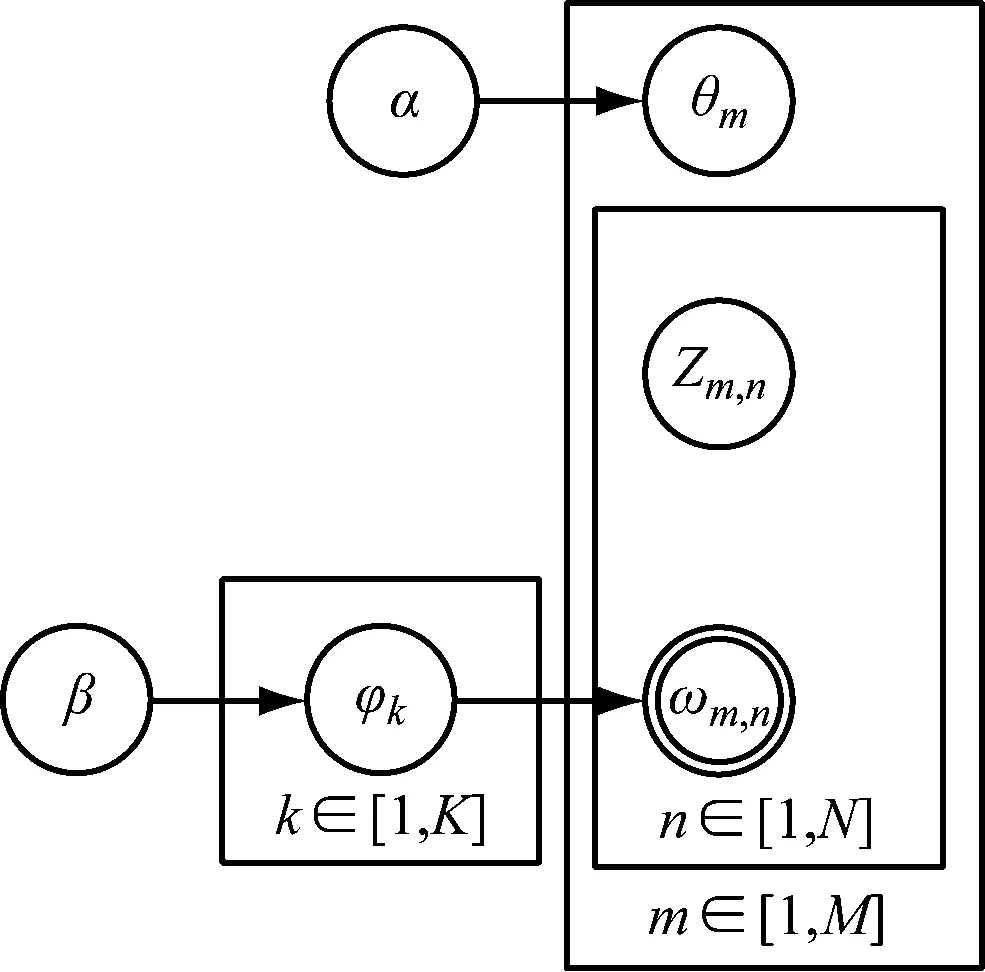
图1 LDA模型描述的文档结构
图中,α、β均为模型的超参数,α代表文档集中的潜在主题与文档思想的接近程度,β代表各潜在主题在文档集中的概率分布;M代表文档总数;K代表主题总数;N代表单个文档中特征词汇的数量;θm代表全部主题在第m个文档中的概率分布;φk代表与某个主题对应的特征词汇的概率分布;Zm,n代表第m个文档中第n个特征词所属的主题;wm,n代表第m个文档中的第n个特征词。
1.2 参数预估
对于文档集LDA模型的创建,θ与φ两个参数的预估值最为重要。本文采用Gibbs抽样法进行参数值估算,具体过程如下。
(1) 将主题zi初始化,随机得到一个(1,T)范围内的整数,假定N为某个特征词汇的数量,则i=1,2,…,N,全部主题初始化后得到初始Markow链。
(2) 循环采样使Markow链不断靠近目标分布,迭代至二者无限接近时停止采样,在此条件下θ与φ的估算式分别为式(1)、式(2)。
(1)
(2)
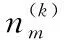
1.3 LDA建模
在创建LDA模型之前必须对单个文档dm进行去标点符号、分词等预处理,以缩减模型的计算步骤,以剩余的有用词汇构建新的文档集D,其文档—词汇矩阵形式的表达方式为式(3)。
(3)
式中,M为文档总数量;m为单个文档在文档集中的编号;wmn为第m个文档中的第n个词汇。
单个文档的LDA模型创建过程如下。
Step1.对狄利克雷分布α进行取样,获取第m个文档中所有主题的概率分布θm。
Step2.对θm进行取样,获取第m个文档中包含的第n个词汇对应的主题zm,n。
Step3.对狄利克雷分布β进行取样,获取与主题zm,n相对应的词汇的概率分布φzm,n。
Step4.对φzm,n进行取样,最终得到特征词汇wmn。
同时,由图1可见,单个文档在文档集中的概率分布表达式为式(4)。
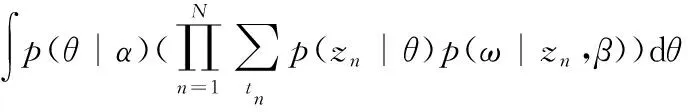
(4)
由式(4)即可推算出特征词汇的概率分布P(wn∣ti)。
2 确定主题相关度
2.1 Word2vec模型
Word2vec模型能够将特定文档集中的词汇转换为实数向量,从而通过词汇的上下文语境将文档内容的筛选转化为简单的多维向量运算,以向量空间中的相似度表征词汇语义的相似度。Word2vec模型的架构如图2所示。
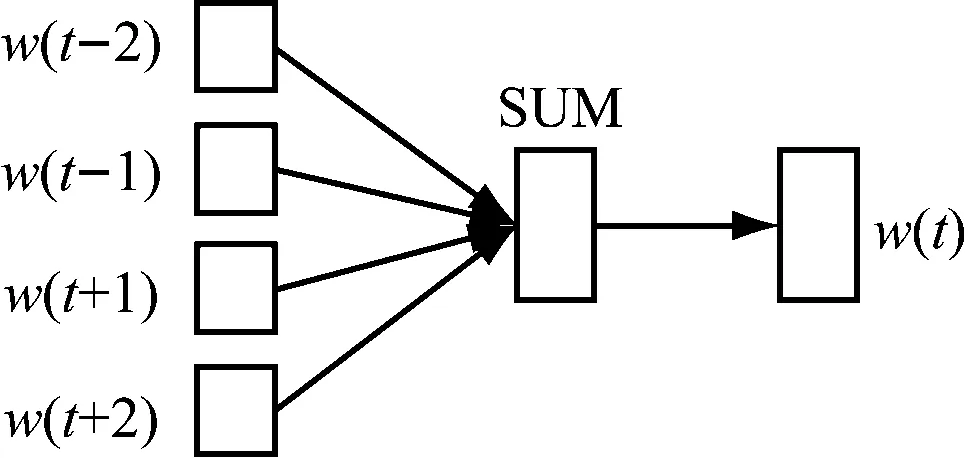
(a) CBOW
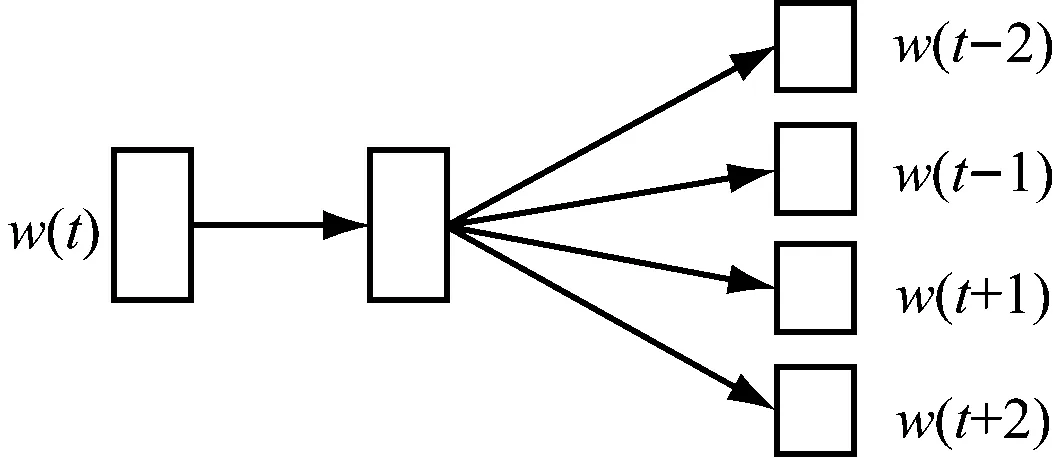
(b) skip-gram图2 Word2vec模型结构
Word2vec由CBOW和skip-gram两种模型构成。由图2(a)可见,CBOW模型能够基于特定词汇的上下文w(t-2)、w(t-1)、w(t+1)、w(t+2)对该词汇的词向量w(t)进行预估,而图2(b)中的skip-gram模型则是基于词汇w(t)预测其上下文w(t-2)、w(t-1)、w(t+1)、w(t+2),由此可以保证Word2vec的训练效果。
2.2 主题相关度计算
首先,利用Word2vec模型完成文档集的训练,获取各词汇在文档中的语义相似度。将词汇转换为向量,通过两个词向量的余弦值表征对应词汇语义的接近性,余弦值越大表明两个词汇的语义越接近。假定两个n维词向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n),其余弦值表达式为式(5)。
(5)
其次,词汇wj与主题ti的相关度可通过对应ti的所有特征词汇的余弦相似度的概率加权和S(wj,ti)来表示,即式(6)。
(6)
由此可对词汇wj与文档dm的相关度进行计算,具体计算为式(7)。
(7)
最后,对文档中所有词汇与文档相关度进行求和计算得到主题相关度,即式(8)。
(8)
3 跑题检测模块
本文所提出的跑题检测模块,一方面基于LDA模型获取文档的主题及词汇信息,另一方面通过Word2vec训练模型转换的词向量获取词汇的语义相似度,其具体检测流程如下。
Step1.对文档集中文档的内容进行预处理。依据空格位置进行分词,将任何形式的大写字母统一转换为小写字母,删除停用词和标点符号,去掉所有词缀保留词干,得到由具有特定语义的词汇所形成的精简文档。
Step2.基于新的文档集生成文档—词汇矩阵。以式(3)表示向量形式的文档,其中第i行的第j列向量表示第i个文档中的第j个词汇。
Step3.创建LDA模型,基于文档—词汇矩阵为所有文档创建对应的LDA模型,利用式(1)、式(2)分别得到模型参数θm与φk的预估值并进行降序排列,获取所有文档中的主题和词汇及其各自的概率分布。
Step4.基于Word2vec模型对词向量进行训练。将经过预处理的新文档集输入Word2vec模型,训练后得到所有词汇的词向量,利用式(5)对词汇的语义相似度进行两两计算。
Step5.计算主题相关度,利用Word2vec模型计算文档集中的每个词汇与特定主题的特征词汇的余弦相似度,然后通过式(6)—式(8)得到主题相关度,将得到的相关度数值与设定的阙值进行对比,即可检测出跑题的英文作文。
4 应用测试与结果分析
4.1 测试方法
本次研究过程中共选取1 230篇不同题目的英文作文作为测试样本,其中作文题目共分为6个类别,每个题目对应的作文数量为205篇。每类题目的作文中都包含一定数量的跑题作文,每一篇作文都已经过人工评分(专家给分的平均分),作文满分为15分的情况下若人工评分低于5分则将其认定为跑题作文。
通过本文所设计的检测算法对1 230篇英文作文进行跑题检测,得到的结果与人工评分结果进行对比,以验证算法的效用。本次研究选取准确率、召回率和F值作为所设计算法的评价指标。假定T为得到正确认定的跑题作文的数量;A为系统认定为跑题的作文的总数量;B为实际跑题的作文的总数量,则准确率P和召回率R的表达式分别为式(9)、式(10)。
(9)
(10)
F值是一个能够综合反映准确率与召回率的评价指标,其表达式为式(11)。
(11)
创建LDA模型的过程中,假定主题数量K的初始值为2,模型超参数α按经验进行取值为α=50/K,α取值随主题数量变化而变化,β按经验取固定值β=0.01,同时对LDA模型的Gibbs抽样共迭代1 000词。
基于Word2vec模型进行文档集的训练时的参数设定为:词向量维数(size)——50;上下文窗口(window)大小——5;词语出现的最小阈值(min-count)——1;是否使用CBOW模型(cbow)——1(0为使用,1为不使用)。
4.2 结果分析
当主题数量K=2时,通过本文所设计算法进行跑题检测得到的结果,如表1所示。
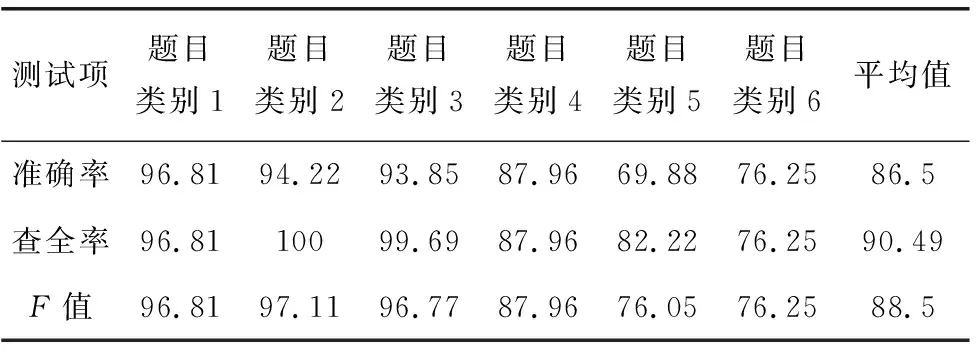
表1 K=2时算法的检测结果/%
由表1中的数据可见主题数量为2时算法的准确率平均值为86.5%,召回率平均值为90.49%,F值的平均值为88.5%。改变K的取值,依次取2、3、5、10、15、20、25重复检测过程并以F值为评价指标对检测结果进行评判。不同主题数量条件下的检测结果,如图3所示。
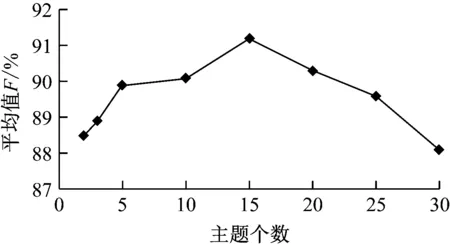
图3 不同主题数量条件下的检测结果
由图3可见,主题数量为15时F值最高,因此可认定最佳主题数量取值为15。按照K=15对α进行取值并对所有英文作文样本再次进行跑题检测,最终得到的准确率平均值为91.86%,召回率平均值为90.54%,F值的平均值为91.2%,可见本文所设计的算法具有很强的跑题检测能力。
5 总结
为了解决现有的跑题作文检测算法在准确性方面的不足,本文基于LDA模型与Word2vec模型提出并设计了一种英文作文跑题智能检测算法,介绍了LDA模型的创建过程,阐述了基于Word2vec模型进行主题相关度计算的方法,并基于二者的共同作用实现了跑题作文智能检测算法的设计。通过实际应用得到检测结果并与人工评分结果进行对比以验证所设计算法的检测能力,对比结果显示,算法的准确度高于90%,具有很强的实用性。
