基于强化学习的组合优化综述
2021-09-28顾一凡
顾一凡
(南京航空航天大学计算机科学与技术学院,江苏南京 210016)
0 引言
优化问题的主要重点在于在不同可能性中寻找当前问题的最优解或最佳配置。这一类问题通常被分成两种:具有连续变量的问题和具有离散变量的问题[1]。例如:在凸优化问题中的一个可行解通常属于实数空间,这样的解被称为一个连续优化的可行解,而查找一系列城市的游览路径则是离散的优化问题。一般而言,在离散空间中查找解的问题被称为组合优化(CO)问题。
当前RL 与CO 结合有两种不同方式:主体学习与联合学习方式。主体学习方式可通过智能体直接作出决定,该方法直接通过RL 策略构造问题的解或完整解的一部分,而不需要求解器的反馈。例如,在TSP 问题中,神经网络首先对智能体进行参数化处理,然后该神经网络逐步构建路径,将路径长度作为奖励来更新策略。联合学习方式则是与现存的求解器联合训练RL,使其可提升CO 问题的解在不同性能度量指标上的表现。例如,在混合整数线性方程(Mixed-Integer Linear Program,MILP)中,常用方法是“分支限界”,其在每一步都选择树子节点的分支规则,该方法可能会对树的整体大小及算法运行时间产生影响。另外,分支限界属于启发式方法,需要一些专家知识对参数进行调整。值得注意的是,可通过RL 智能体接收与运行时间成正比的奖励训练智能体学习节点选择策略。
通常来说,使用RL 解决CO 问题可看作是学习解决此类问题的策略,而不是使用运筹学中人为设定的方法,在该层次上可将其分为学习构造启发式以及改进启发式方法。学习构造启发式方法通过学习策略不断构造解,而改进启发式方法则是学习一种基于迭代的改进策略,该方法试图解决在启发式学习中遇到的一些问题,即需要使用一些额外过程以找到良好的解决方案,例如采样等。
1 相关基础知识
1.1 组合优化问题
首先给出关于组合优化问题的基本定义:
定义1(组合优化问题):假设Ω 是解的决策域,且F:Ω →R是一个决策域到目标域映射的目标函数。组合优化问题旨于找到目标域上的最优值,以及找到该最优值在决策域Ω 上对应解的结构。
通常来说,组合优化问题的决策域Ω 是有限的,且存在局部最优解,可通过比较所有可行解得到。但是,现实中的组合优化问题一般都是NP 难问题,找到一个最优解往往需要较高的时间成本,因此传统方法是在一定时间内找到一个折中的解。
下面主要介绍使用RL 解决的一些特殊的组合优化问题,这些问题在现实中有着广泛应用,例如最大分割问题、旅行商问题、财务投资组合管理问题等。
定义2(最大切割问题):给定一个图G=(V,E),找到一个点集的子集S⊂V,且该子集最大化分割C(S,G)=∑i∈S,j∈VSwi,j,其中wi,j∈W是连接顶点i与边j的权重。
定义3(旅行商问题(TSP)):给定一个完整的加权图G=(V,E),其目标是找到一个最小权重的路径,使得每个城市只被访问一遍。
定义4(最大独立集(MIS)):给定一个图G=(V,E),找到一个点集的子集S⊂V,使S中没有两个顶点通过E的边相连,且最小化目标为|S|。
1.2 强化学习
一般来说,RL 智能体通过马尔可夫决策过程(MDP)指导智能体在环境中进行动作[2],并通过收集相关奖励来更新模型。环境由状态集合S 中的状态组成,状态集S 可以是离散的,也可以是连续的。智能体所有可能执行的动作都在动作集合A 中,智能体的主要目标是通过执行动作增加获得的奖励值R。从S 中每个状态s 到最佳动作a 的映射函数被称为策略,表示为π(s)。因此,为解决MDP 问题,需要找到最佳策略π*以最大化预期奖励:
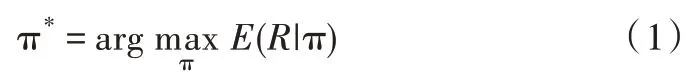
其中,奖励值可表示为:

智能体在经过N 步之后重启,如果N 趋向于∞,则表示智能体以一种无回合的形式进行训练。一般来说,γ 体现智能体关注短期奖励的程度,当γ<1 时,其会阻止累计奖励被无限放大。
2 强化学习应用于组合优化分类
在过去几十年中,科学家们研究了解决CO 问题的各种可能方法,因此也提出了许多CO 求解算法,包括基于机器学习的方法等。如文献[3]从机器学习的角度总结了解决CO 问题的方法,并列出了几个有效算法;文献[4]致力于描述图神经网络(GNN)及其在CO 问题上的可能应用;文献[5]通过调查研究,介绍了使用机器学习(ML)方法解决CO 问题的最新研究成果。
本文仅专注于使用RL 解决CO 问题,以下主要从两个方向对RL 解决CO 问题的相关研究进行分类:①基于值函数的RL 方法;②基于策略的RL 方法,具体对应成果如表1所示。对于每一种方法,以下章节会进行详细介绍,并给出相关工作的不足及需要改进的方向。

Table 1 RL methods for solving CO problems(value function,strategy)表1 用于解决CO 问题的RL 方法(值函数、策略)
3 强化学习应用于组合优化的方法
3.1 基于值函数的方法
Q-learning[15]是一个典型的基于值函数的RL 方法,但对于大部分实际问题而言,要找到最优解十分困难。NP 难问题因其对应的RL 状态与动作空间连续或过大,使得传统RL 方法无法得到有效使用。随着深度学习的崛起,证明神经网络(NN)对于高维输入数据可以学习出有效的函数逼近方式,从而促进了深度Q 网络(DQN)的发展[16]。由于结合了神经网络(NN)与Q 学习的优点,DQN 已成为目前解决许多强化学习问题最受欢迎的方法之一。
对于大多数问题,如最大分割[17]、TSP 问题[18]等,现有研究使用了与DQN 相同的Q 值更新公式,即使用图形嵌入网络对Q 函数进行参数化。文献[17]中使用图注意力网络[19]与一种transformer 结构[20]对CO 问题进行编码;文献[18]使用了structure2vec 图神经网络,这也是一种流行的图编码技术。
文献[18]旨在解决TSP 问题,其主要通过DQN 学习良好的启发式策略,然后将其直接集成到各种基于约束的算法中,如分支限界以及迭代的差分搜索等。在训练中,从某些分布中随机抽取测试用例Qi,计算其奖励值函数为其中,UB(Qi)表示Qi在值函数中的上界,c 表示成本,ρ是一个比例因子。
最近有一些研究专注于解决最大公共子图问题[7],其构建了一种联合子图节点的新型嵌入网络,以便使用单个网络嵌入两个图,网络权重更新方法与DQN 一致。
上述工作都会遇到一个与DQN 共同的问题,即DQN依次构造最优解使得算法不能重新考虑次优解。为解决该问题,对DQN 的训练过程进行了修改,形成了另外一组解决CO 问题的RL 方法[8],其使用在分类领域很受欢迎的协同训练方法构建CO 问题的顺序策略。本文介绍了针对最小顶点覆盖问题的两种策略学习方法:第一种方法复制文献[18]中描述的策略,第二种方法利用分支限定法解决整数线性规划问题。通过创建一种与模仿学习[21]相似的算法,根据两种策略之间的信息交互识别出哪种方法更具有优势,以此开展更新过程。
3.2 基于策略的方法
文献[11]进行了将策略梯度算法应用于组合优化的首次尝试,即使用有学习基线的强化学习算法解决TSP 与背包问题。文献[22]提出指针网络体系结构作为编码的输入网络,该方法使用解码器的指针机制,根据输入的分布顺序构造CO 问题的可行解,类似于文献[23]的异步并行训练。
文献[11]中提出的方法由于其动态性质不能直接应用于车辆路径规划问题(VRP),即节点一旦被访问,该节点则不能再次被访问。文献[12]对文献[11]的方法进行拓展以找到VRP 的可行解。具体来说,其通过使用一维的卷积嵌入层替换LSTM 单元来简化编码器,从而使模型对输入不敏感,因此不同的输入顺序不会影响模型性能,之后使 用RL 对TSP 与VRP 进行策略学习,而A3C[23]中使用随机VRP 进行策略学习。
另一个重要的CO 问题是3D 装箱问题。文献[13]使用RL 方法制定策略,该策略代表物品的最佳包装顺序。在提供的入库商品序列特征上进行算法训练,通过计算包装商品的表面积评估生成的策略,其中使用启发式算法生成的结果作为训练基准。为了进行推断,使用贪婪的解码方式以及一种通过波束搜索的方法进行采样。文献[14]将该方法进一步拓展到监督学习方向,采用RL 与监督学习相结合的方法。文献[24]提出一种条件查询学习(CQL)方法,使用注意机制调节装箱过程中需要执行的3 个子动作,即盒子的选择、旋转与定位。
文献[25]通过学习改进启发式方法解决VRP 问题、在线作业调度问题等。该算法不断重写解的不同部分,直到收敛为止,而不是按顺序构建解。状态空间表示为问题所有解的集合,而动作集则由区域(图中的节点)及其相应的重写规则组成。文献[25]通过Q-Actor-Critic 算法共同训练区域选择和规则选择策略。
与之相似的是,文献[26]提出通过学习改进启发式方法,使用2-opt、交换与重定位方法解决CVRP 与TSP 问题。此外,还可以学习改进启发式方法并使用2-opt 解决文献[26]中的缺点,该缺点使得策略网络体系结构很难拓展到k-opt[27-28]。为此,将图形神经网络与递归神经网络一起作为解码器,并在解码器中使用指向策略,根据指向机制顺序输出k-opt 操作。文献[29]进一步扩展了上述工作,使用通用的销毁与维修操作改进启发式算法。文献[30]提出深度自动延迟策略(ADP),将图卷积网络编码器与最近策略优化(PPO)算法结合使用,可通过回滚过程学习最大策略,排除无效解。
4 结语
本文介绍了几种通过强化学习方法解决经典组合优化问题的算法,随着相关研究的发展,各种新算法不断被提出。这些问题都是从计算时间的角度处理大规模问题,这也使得计算时间成为相关算法与传统算法性能对比时一个重要的考虑因素。此外,另一个需要解决的问题是提高算法策略的泛化能力,即在小规模CO 问题上训练后得到的模型可用于大规模组合问题。在同一研究领域,将已有RL 模型迁移到其他具有不同分布特性的问题上也是一个具有前景的研究方向。最后,当前方法都是使用RL 方法的变体结合更高效、稳定的数据采样方法,这种结合方式能够有效地解决组合优化问题。
