人工神经网络在环棱螺体质量缺失值预测中的应用
2021-09-27杨利娟金武黄珊珊闻海波马学艳唐小林王卫民曹小娟
杨利娟,金武,黄珊珊,闻海波, 马学艳,唐小林,王卫民,曹小娟
1.华中农业大学水产学院/教育部长江经济带大宗水生生物产业绿色发展工程研究中心/ 农业农村部淡水生物繁育重点实验室,武汉430070;2.中国水产科学研究院淡水渔业研究中心/中美淡水贝类种质资源保护及利用国际联合实验室,无锡 214081
环棱螺俗称螺蛳、豆田螺、石螺,隶属于腹足纲(Gastropoda)、前鳃亚纲(Prosobranchia)、田螺科(Viviparidae)、环棱螺属(Bellamya)。环棱螺属常见的种有铜锈环棱螺、方形环棱螺和梨形环棱螺等[1]。因有着营养价值高[2]、用途多[3]的优点,环棱螺越来越受到人们的关注和喜爱[4-5]。然而,随着长江全面禁渔推行,作为水域生态系统中重要成员的环棱螺已被纳入禁捕行列。因此,开展环棱螺繁育工作以推进其养殖业发展势在必行。
目前,环棱螺育种重点关注体质量性状的遗传改良[6],但在育种过程中常因种群保管不善、养殖水环境剧变、饵料不适口及流行性疾病暴发等因素导致环棱螺死亡。虽然环棱螺死亡个体形态学数据(如壳高、壳宽、壳口高和壳口宽等)仍能测量获得,但其体质量数据则会缺失。育种数据缺失的处理包括直接删除[7]、尝试填补[8]、不处理[9]3种方法。在实践中,因为育种性能优异的个体来之不易,为了尽可能利用所有的信息,往往需要对缺失值进行处理。本研究基于人工神经网络的预测功能,利用测得的环棱螺4个形态学数据和体质量数据构建模型,继而对缺失的体质量数据进行预测并评估其效率,以期为环棱螺选择育种提供高效的数据分析工具。
1 材料与方法
1.1 环棱螺采集及数据测量
从阳澄湖、太湖、江阴、官莲湖、洪湖和仙桃共采集获得1 045个环棱螺,利用游标卡尺测量其形态学(包括壳高(SH)、壳宽(SW)、壳口高(AH)和壳口宽(AW))数据,同时测量体质量。此外,从微山湖采集201个环棱螺,测量其壳高、壳宽、壳口高和壳口宽。本研究从以上7个采样点(含体质量缺失的微山湖群体),共采集获得1 246个环棱螺,具体情况见表1。

表1 环棱螺采样点和数目 Table 1 Sampling sites and number of Bellamya
1.2 数据分析
1) 人工神经网络构建。体质量未缺失采样群体数据集中随机抽取75%的数据(784个)用于训练模型,总体数据中剩余的25%的数据(261个)用于测试模型。在建模过程中,经过预先多次的参数调整,人工神经网络设定为1个隐含层和3个神经元的结构。人工神经网络类似于生物神经元结构,经训练的模型利用输入的4个形态学数据生成1个输出预测的体质量值。神经元的输出都是输入的加权和加上偏差的函数。一旦接收到的信号总量超过激活阈值,则每个神经元都执行简单的操作[10]。每个典型的神经元用数学函数可以表示为式(1):
y=f(x)=∑xiwi
(1)
其中,xi为输入变量,wi为权重,i为输入变量的个数,1≤i≤n。
2)不同预测方法之间的比较。体质量数值预测分别采用R统计软件[11]的人工神经网络neuralnet包[12]和mice包[13]中的预测均数匹配法(predictive mean matching,PMM)[14]和随机森林预测法(random forest,RF)[15]。不同缺失值预测的方法统一以模型的决定系数R2来进行比较[16]。决定系数的计算方法为式(2):
(2)
其中,Xt和Xt′分别为第t个真实值与第t个预测值。
2 结果与分析
2.1 描述性统计
表2统计了体质量数据未缺失的6个地理群体环棱螺壳高、壳宽、壳口高、壳口宽和体质量数据(形态学数据精确到0.01 mm,体质量数据精确到0.01 g)。体质量数据未缺失群体的4个形态学性状数据的分布如图1所示。本研究构建的人工神经网络模型预测的微山湖环棱螺体质量为(3.91±1.30) g。微山湖环棱螺的形态学性状值小于其他6个地理群体环棱螺的形态学性状值,本研究基于人工神经网络模型预测的微山湖环棱螺的体质量也小于其他6个地理群体环棱螺的体质量(表2),这在一定程度上反映了本研究构建的人工神经网络模型对环棱螺体质量预测的准确性。

表2 形态学数据和体质量的描述性统计(平均值±标准差) Table 2 Descriptive statistics of morphological data and body weights (Mean±SD)
2.2 人工神经网络模型建模
人工神经网络模型的准确度经多次参数调整后,经过622 810次迭代后收敛(图2)。连接实线的数值为该连接的权重,连接虚线上的数值为每一步计算添加的权重。广义权重散点图显示,壳高、壳宽、壳口高、壳口宽这4个性状对体质量的线性相关关系很强(图3)。壳宽和壳口宽的广义权重多数分布于0附近,说明这2个性状对体质量的作用相对较弱。壳高和壳口高这2个性状对体质量的作用较强,这2个性状和体质量存在一定的非线性相关性。
人工神经网络模型对环棱螺体质量预测的决定系数为0.96,说明该模型具有较高的准确性。预测均数匹配法和随机森林预测法的决定系数分别为0.87和0.85,这说明人工神经网络和其他2种体质量缺失值预测方法相比,具有明显优势。

图1 微山湖环棱螺4个形态学性状数据的分布图Fig.1 Distribution of four morphological traits in Bellamya sampled from Weishan Lake
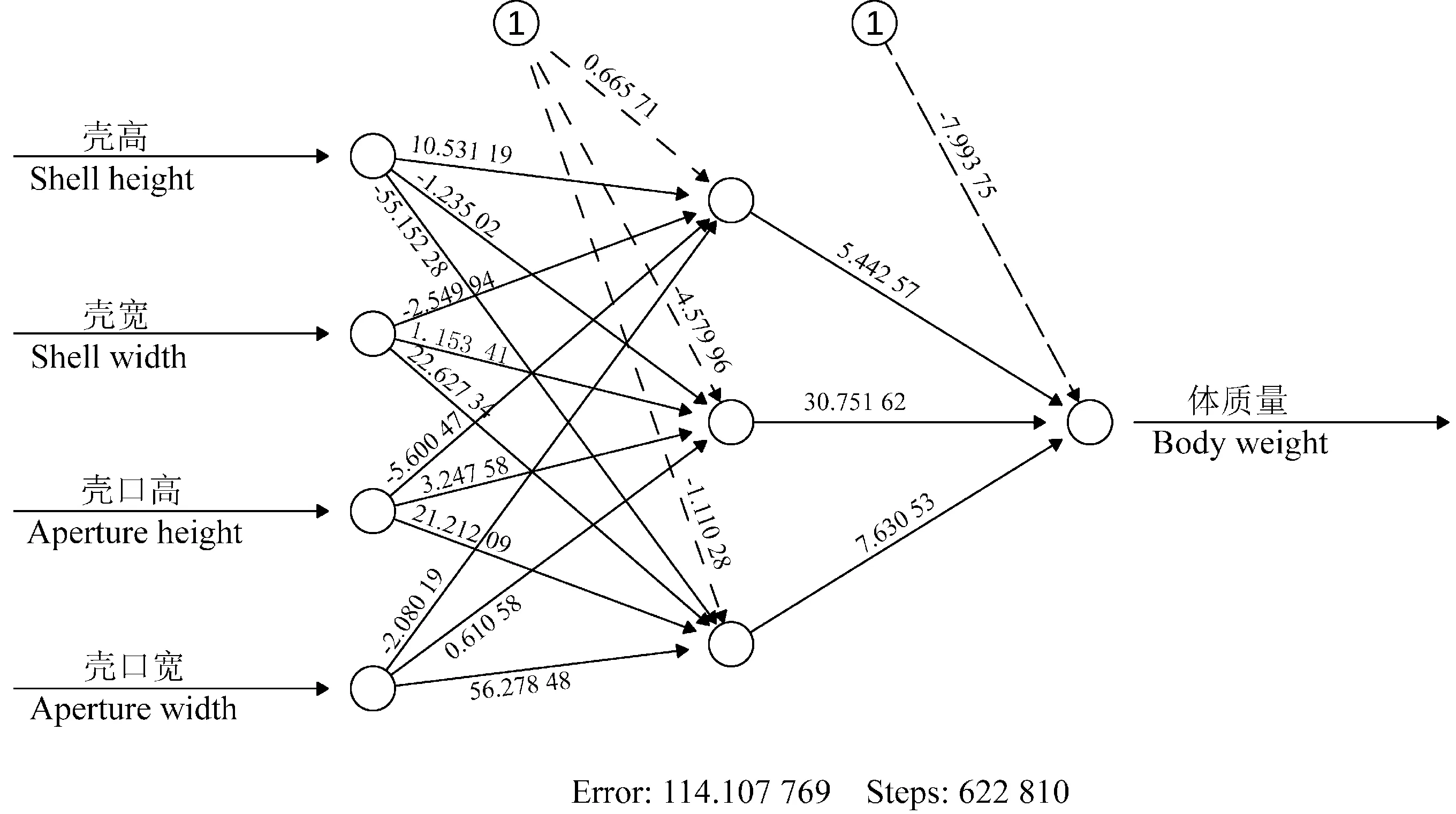
图2 人工神经网络结构图Fig.2 Neural network structure diagram

图3 广义权重的散点图Fig.3 Scatter plot of generalized weights
3 讨 论
3.1 人工神经网络在缺失值预测中的应用
人工神经网络作为一种并行的计算模型,不需要对研究对象的数据规律有大致的了解,只需要通过网络本身的学习功能就可以得到网络输入与输出的关系[9]。与传统建模方法相比,人工神经网络对非线性相关的数据的学习能力更强。基于神经网络进行缺失数据估计的基本步骤是:利用该系统中的已知数据训练网络,在网络满足要求后,把其他参数的数据(不含缺失值)输入网络,网络输出值即为缺失数据的估计值[9]。人工神经网络在一些复杂系统如飞机发动机[9]、农业气象[17]、原子反应堆[18]、农田生态系统[19]、湖泊水体[20]中数据处理中已取得了一定进展。对活立木茎干水分缺失数据的研究表明,人工神经网络较传统的插值方法优势明显,且神经网络方法预测精度受数据缺失量增多的影响较小[21]。对农业生产资料数据库中缺失数据的神经网络预测结果也显著好于传统的线性插补和加权分析[22]。与农学研究相似,生态学监测中也较易出现缺失值。基于神经网络的参数学习方法也取得了比其他算法更高的精度[23]。本研究率先探索建立了在水产育种领域较易出现的缺失值预测方法,并得到了比传统缺失值处理方法更高的决定系数。针对环棱螺育种过程中常涉及的体质量缺失问题,本研究提前进行了技术储备(即构建相应的高效人工神经网络模型),但同时也存在实验数据量偏少的不足之处,我们将在日后的研究中,加大数据量的采集。
3.2 常见缺失值预测方法的比较
在本研究中,尽管环棱螺形态学性状和体质量测量数据有限(1 045个个体),但构建好的人工神经网络模型对201个体质量缺失的样本预测仍取得了较高的准确度,在缺失数据增加若干数量级是否能取得类似效果仍待深入研究[24]。由于预测均数匹配法只有在某些特定的缺失数据类型时才能取得较好的效果[25],本研究中缺失的体质量数据与环棱螺自身形态学数据相关,可能也会造成该方法预测缺失值的决定系数偏低。此外,随机森林对缺失数据和非平衡的数据的结果分析比较稳健,能够在高维数据中有效地分析具有交互作用和非线性关系的数据[26],但对多元共线性不敏感[27]。在本研究建立模型过程中,可能由于训练集样本量偏小导致随机森林模型的决定系数低于人工神经网络,随机森林预测缺失值的优势未得到完全显示。后期可以通过增加训练样本量,进一步挖掘随机森林预测法的优势。尽管缺失值预测的方法有很多,但在实际分析中仍需谨慎对待预测结果,并进行多种方法的比较[28]。
