挖掘理想重建图像自相似性的超分辨率
2021-09-26李键红吴亚榕詹瑾
李键红 吴亚榕 詹瑾

摘 要:為了解决图像超分辨率过程中训练步骤对海量数据的过于依赖、先验泛化能力不强等问题,进一步提高重建图像的质量,提出了一种新的图像超分辨率算法. 首先对图像自相似性理论进行扩展,指出理想重建图像自相似性表现极为强烈,而受降质因素干扰的重建图像自相似性则会明显减弱. 本文将这一规律视为先验,通过构建联合高斯混合模型对其进行描述,这使得每个重建图像片的自相似性都能够用一个特定的高斯分布进行刻画,最后算法以迭代的方式分片重建整幅高分辨率图像. 在为每个高分辨率图像片建模的过程中,为了使训练样本具有较强的一致性,仅使用输入图像中与其空间位置相近的图像片进行训练. 该算法避开了易于引入误差的最近邻域查找步骤,且成本函数存在解析解. 实验表明该算法重建图像清晰、自然,重建结果中的显著边缘和纹理结构都得到了有效保持,正确的高频信息得到了明显恢复. 在将BSD500部分数据集放大3倍的实验中,本文算法的PSNR平均值高于MMPM算法0.529 db,SSIM平均值高于MMPM算法0.030.
关键词:单帧图像超分辨率;自相似性;高斯混合模型;概率密度函数;最大后验概率;维纳滤波解
中图分类号:TP391.4 文献标志码:A
Image Super-resolution by Exploiting
Self-similarity of Ideal Reconstruction
LI Jianhong1,WU Yarong2,ZHAN Jin3
(1. School of Information Science and Technology,Guangdong University of Foreign Studies,Guangzhou 510006,China;
2. School of Mechatronic Engineering,Zhongkai University of Agriculture and Engineering,Guangzhou 510225,China;
3. School of Computer Science,Guangdong Polytechnic Normal University,Guangzhou 510665,China)
Abstract:To solve the problems such as over-reliance on massive data and weak prior generalization ability in the training procedure of image super-resolution,thus further to improve the quality of reconstructed high resolution image,a new image super-resolution algorithm was proposed. This paper firstly extends the theory of image self-similarity and points out that the self-similarity of ideal reconstruction image is extremely strong,but this property can be sharply weakened when the reconstructed image is attacked with some degradation factors. Then this discovery is considered as a prior and described by constructing a joint Gaussian mixture model,so that the self-similarity of each reconstructed image patch in the prior term can be represented by a specific Gaussian distribution. For maintaining the training samples' consistency,only the image patches extracted in the input image closed to its spatial position are permitted to join in the modeling process for each high-resolution image patch. This style can avoid the step of finding the nearest neighbors which is liable to introduce errors. Finally,the whole high-resolution image can be reconstructed patch-wise in an iterative way. Extensive experiments demonstrate that the reconstructed images generated by the proposed algorithm are clear and natural,in which the salient edges and texture structures are effectively preserved,and the correct high-frequency information is recovered. The 3× super-resolution experiment in BSD500 shows that the average PSNR is higher 0.529 db than the state-of-the-art algorithm MMPM,and the average SSIM is 0.030 higher than MMPM.
Key words:single image super-resolution;self-similarity;Gaussian mixture model;probability density function;maximum posterior probability;Wiener filter solution
图像超分辨率是指通过软件计算的方式处理一幅低分辨率图像,估计对应高分辨率图像的技术. 它是常见的信号编辑形式,是低成本获取高分辨率图像的主要手段,广泛应用于空间遥感、视频监控及数字家庭等场景. 近年来,由于潜在广阔市场地驱动,以及飞速发展的软/硬件支持,超分辨率取得了显著进展,已成为学术界讨论的热点话题.
一般来说,根据低分辨率图像反推对应的高分辨率图像是一个典型的病态逆问题[1]. 为了得到清晰可靠的重建图像,人们通常引入先验对高分辨率图像的重建过程进行约束,先验恰当与否和重建图像质量密切相关. 根据引入先验形式的不同,超分辨率算法大致可分为插值法、重建法和学习法三类.
基于学习的方法指的是借助外界高分辨率图像建立训练集,并利用训练集归纳低/高分辨率图像间的映射,使先验以隐含的方式包含在映射中. 这类方法能够有效地恢复成像过程中丢失的高频信息,生成在输入图像中观察不到的细节,从而使其倍受重视,成为超分辨率技术的主流. Yang等[2]将稀疏表示的思想引入到超分辨率中,用不同尺度的图像片联合训练字典. 但该方法导致字典中与输入图像片差异很大的“原子”参与计算,在重建结果中产生噪声. Timofte等[3]将稀疏表示与邻域嵌入相结合,对每一个低分辨率图像片,在字典中查找距离它最近的“原子”,利用该“原子”在字典中的k近邻构建矩阵算子. 在此基础上,Timofte等[4]进一步挖掘初始的训练图像,再次提升此算法的性能. 深度学习在超分辨率中也得到了广泛应用[5-7]. 但这类算法通常需要借助图形处理单元(Graphics Processing Unit,GPU)训练海量图像,以确定神经节点的权重. 在训练过程中,先验不易在此类方法中发挥作用,限制了重建图像的质量以及重建过程的稳定性.
近年来,自相似性在图像处理中得到了广泛应用[8-13]. 这一性质指的是当从局部入手(即图像中的一个5 × 5、7 × 7或其他小尺寸的图像片)对图像进行考察时,会在这幅图像自身或更高\低尺度内的其他位置发现与之尺寸相同、包含内容极其相似的图像片[8-10]. 基于自相似性的超分辨率算法把输入图像视作样本,训练模型、估计高分辨率图像. Glasner等[8]提出一个整合式的超分辨率框架,把相似图像片视为同一场景的不同视图,整合多帧图像超分辨率和基于学习的超分辨率两种思想对图像进行放大. 然而对于自相似性弱的图像,某些图像片查找到的最近邻域会与之存在较大差异,使重建结果中出现噪声,甚至引入错误高频. 另外,该方法需要在输入图像的多尺度中搜索最近邻域,算法相对耗时. Freedman等[14]经验性地指出自然图像中几乎所有图像片在其自身或较低尺度内的最近邻域,只需在该图像片所在位置附近检索就能查找到. Yang等[15]进一步在理论上通过数学推导对这一性质加以证明. 这使得查找最近邻域消耗的时间显著缩短,然而由于使用的训练样本数量有限,导致此类方法的重建图像在边缘位置过于锐利,看上去不够自然. 为了解决此种“小样本”问题,He等[16]引入高斯过程回归,在每个图像区域内构建样本集合、训练参数. 但该算法没有挖掘区域间的关联关系,使得重建结果中的显著边缘产生变形,附近存在噪声. 基于同样的目的,Huang等[17]通过变换矩阵对输入图像片进行特定的几何变形,不仅扩展了最近邻域的查找空间,而且使图像片间的匹配更加准确,提高了重建图像质量. 该算法对于直线条居多、无复杂纹理的“建筑场景”效果较好,但对包含复杂纹理的“自然风光”而言,由于几何变形导致了纹理结构的失真,在重建图像的对应区域会出现伪影.
另外,自相似性先验表达式在众多领域也得到了应用[18-21]. 自相似性先验表达式通常会与其他先验如局部平滑先验、稀疏先验、低秩先验等结合使用. 算法一般先查找若干最近邻域,然后借助这些相似图像片的稀疏系数相似或相似图像片构成的矩阵具有低秩结构等特点设计先验表达式. 为了确定模型参数,这些算法仍需外界图像参与训练. 成本函数中的先验表达式由多项构成,此类算法求解计算复杂、耗时,不易在实际中使用.
本文挖掘理想高分辨率图像的自相似性,提出了一种简单、高效的超分辨率算法,创新点如下:
1)拓展了自相似性概念. 重建高分辨率图像越清晰,它体现出的自相似性就越强烈;当高分辨率图像中存在噪声、模糊等因素影响或缺失高频信息时,它所体现出的自相似性会明显减弱. 基于此性质,提出了一种新的先验,通过对低分辨率图像进行建模、推導后发现,满足这一先验的重建图像,它的任意图像片都服从于某个特定的高斯分布.
2)设计了一个迭代框架,在每次迭代中,使用前次估计的高分辨率结果结合输入图像构造训练集合. 对每个图像片,考虑到图像内容的连贯性,该算法使用输入图像中与之空间位置较近的图像片集合构造训练样本,并采用快速更新的方式确定模型参数. 实验表明,该算法对于恢复图像高频细节,保持图像纹理结构等有显著优势.
3)该算法简单、高效,不仅无需外界样本参与,而且避开了耗时的最近邻域查找步骤. 另外,在高斯混合模型建模、参数更新的过程中仅使用少量高斯成分,成本函数方程存在闭合解. 更为重要的是该算法能够根据输入图像的不同而自动进行模型参数的调整,使得该算法更为鲁棒,易于扩展到图像去噪、复原等其他领域.
1 相关工作
图像在成像过程中会受到相对运动、聚焦失准等复杂因素干扰,很难找到一个完美的数学模型来精确刻画成像过程,因此在实际应用中,对于图像的超分辨率问题,通常用一个线性系统对整个成像过程进行模拟[1]:
Y = DHX + n, (1)
式中:X∈RMN和Y∈RMN/s2 是来自同一场景,但分辨率不同的两幅图像,X是未知的高分辨率图像;Y是人眼能够观察得到的低分辨率图像,(为了操作方便,此时的图像X和Y已通过字典排序的方式转换成向量的形式,M代表图像的像素点行数,N代表图像的像素点列数,R表示像素点的亮度取值自实数空间范围,s表示X和Y间的缩放倍数);矩阵D和H分别对应成像过程中的下采样和低通滤波操作;n∈RMN/s2 是成像过程中产生的加性高斯白噪声,满足n ~ N(0,σ2I),σ为描述噪声等级的标准差,I为单位矩阵. 图像X和Y的尺寸分别为M × N和M/s × N/s. 显然对于一幅低分辨率图像Y而言,X存在着无穷多的解与之匹配. 为了得到一个满意的解X*,先驗知识的引入就变得尤为关键. 一般情况下这类问题可以描述为一个最大后验概率方程:
X* = ‖Y - DHX‖22 + λP(X) (2)
式中:‖Y - DHX‖22 为保真项,使重建高分辨率图像经过成像模型处理后,与输入的低分辨率图像尽可能相似;P(X)为先验项,用于确保高分辨率图像满足先验P的约束;λ = σ2/η2是两项间的平衡系数(η是尺度缩放因子). 然而图像就其整体而言内容丰富、结构多样,很难找到统一形式的先验. 但当从小局部(如5×5、7×7的图像片)进行观察时,图像片内容单一,有极强的规律性,易于描述. 因此通常从图像片出发对先验项建模,将P(X)表述为:
式中:Pi为抽取矩阵,负责抽取未知高分辨率图像X中的i第个图像片,即Pi X = xi,xi∈Ra2 ,a为图像片的尺寸;ρ(xi)为第i个图像片xi的先验表达式,它的具体表示形式因选择先验的不同而不同,对应成本函数的求解过程也不一样. 一般而言,这类问题的成本函数是非凸的,直接求解会非常困难. 常见的思路是为变量xi引入辅助变量,使用“半二次分裂”(Half Quadratic Splitting,HQS)算法求解[22].
高斯混合模型(Gaussian Mixture Model,GMM)因其思想简单、推导方便、能准确描述任意概率密度函数等特点备受研究人员青睐. 近年来,将GMM作为先验形式在计算机视觉、图像处理等领域得到了广泛应用,在图像分割、恢复、视频压缩等方向展现出了极高的效率[23-24]. 它的基本形式为:
式中:z∈Rd是一个d维随机向量;K为高斯混合模型高斯成分的个数;参数πk、 μk和∑k分别表示第k个高斯成分的权重系数、均值向量和协方差矩阵. 第k个高斯成分的表达式为:
根据高斯混合模型的定义可知,πk = 1,对于参数集合{πk,μk,∑k}K k=1的估计,通常采用期望最大化(Expectation Maximization,EM)进行.
与本文算法在形式上相似,但又存在本质差异的工作包括PLE[25]、EPLL[26]、LINE[27]、J-GMM[28]和 MMPM[29]. 其中 EPLL、J-GMM 均使用高斯混合模型对外界海量图像片进行建模,进而假定未知图像片由混合模型中的某个高斯成分生成,然后通过最大后验概率估计将该成分找到,最后使用均值向量和协方差矩阵计算维纳滤波解. 然而图像中存在大量的图像片,并不服从这一假设. 它们需要借助多个高斯成分或混合模型之外的新成分才能准确生成. 这使得信号估计过程中,仅使用某个高斯成分的均值向量和协方差矩阵计算的维纳滤波解不准确,导致重建图像中存在噪声和模糊现象. MMPM算法与J-GMM算法步骤相同,区别在于它使用学生氏分布替换混合模型中的高斯成分,在重建结果中同样存在少量噪声和模糊. PLE和LINE算法也从上述假设出发,先查找待恢复图像片在训练集中的最近邻域,再通过这组最近邻域直接构建混合模型中能够生成对应图像片的高斯成分. 然而查找最近邻域步骤过于耗时,同时这种硬阈值聚类的形式减弱了训练样本间的一致性,导致高斯成分所涉及到的参数不准确,在重建结果中易出现噪声.
本文仅使用输入图像构建训练集,对每一个待超分辨率的图像片,在训练集中选择空间位置相近的图像片进行联合高斯混合模型训练,利用高斯混合模型,得到每一个未知的高分辨率图像片都服从一个“特定”的高斯分布这一结论. 最后利用混合模型之外某个高斯分布的均值向量和协方差矩阵估计对应的高分辨率图像片.
2 理想重建图像自相似性超分辨率
2.1 训练集构造
自相似性是图像自身固有的一种性质,它指的是在图像中任意抽取的图像片会在这幅图像自身其他位置或其他尺度内重复出现的现象. 在这一基础上,对自相似性进行扩展. 通过进一步实验,发现在超分辨率工作中,越是清晰的高分辨率重建图像,图像片重复出现的能力就越强烈;但在含有噪声、模糊或缺失高频信息的高分辨率重建图像中,图像片的重现能力明显减弱. 如图1所示,中间的小图像为输入低分辨率图像,图1为其不同的超分辨率版本. 对于4幅图像中某个位置的图像片,在对应的低分辨率图像中查找最近邻域,可以发现这4个来自不同版本同一位置的图像片,在低分辨率图像中的最近邻域都能够在这个位置附近找到. 更为重要的是:只有在理想超分辨率图像中的图像片,它找到的最近邻域才与之在外观上相似;其他版本中这个图像片找到的最近邻域,在外观上都与之存在差异. 在BSD500数据集中进行类似的实验,发现绝大多数的图像都存在上述特点. 因此可以认为在超分辨率算法中,重建高分辨率图像越清晰,它所体现出的自相似性越强烈;但当高分辨率重建结果中存在噪声、模糊或缺失高频信息等因素时,它所体现出的自相似性会显著减弱.
借助这一规律,提出一种新的超分辨率算法,采用迭代的方式,用輸入图像Y估计对应高分辨率图像X. 算法迭代框架如图2所示,假定前一次迭代估算的高分辨率图像X未满足算法要求,将其视为理想高分辨率图像的低频版本,替换当前低频图像X′,实现了X′的更新,然后将X′使用双三次方法下采样 s倍,得到与输入图像同尺寸的低分辨率图像Y′. 此时X为未知的高分辨率图像,X和Y′可以视为X和X′通过成像模型处理的低分辨率版本,X′和Y′可以视为X和Y的低频版本.
根据上述的图像自相似性扩展规律可知,如果 X和X′相对于Y和Y′足够清晰,那么在X和X′中抽取的图像片Xi和X′i(xi∈Ra2 ,a为抽取图像片的尺寸),应该能够在其对应的低分辨率版本Y和Y′中找到重现,即存在图像片yj和y′j,其外观与xi和x′i高度相似,即图像片xi和x′i在Y和Y′的图像片联合的概率密度函数中以最高的概率存在.
基于上述分析,将图像的超分辨率问题构造如下:对于未知的高分辨率图像片xi,先构造训练数据集,抽取Y和Y′中的图像片进行连结,得到训练数据集{yj;y′j},其中yj和y′j表示分别从Y和Y′中抽取的第j个图像片. 将理想的高分辨率图像X中抽取的图像片xi和缺失高频成分的高分辨率图像X′中对应的图像片x′i相连结,得到向量[xi;x′i]. 根据图像的自相似规律可知:[xi;x′i]在训练集合{[yj;y′j]}中的概率密度函数中应以最高的概率存在. 考虑到图像内容本身有很强的连贯一致性,为了使得到的概率密度函数更准确,在构造xi的训练集时,我们在Y和Y′中分别设定一个w×w的滑动窗口,其当前中心位置与xi位置相同,仅将窗口中的图像片集合作为xi的训练集,窗口外的内容不参与图像片xi的计算. 考虑到窗口内能够抽取的图像片有限,参与计算的样本可能不足,我们将窗口中的内容进行旋转和镜像操作,并从这些旋转和镜像图像对应的窗口中抽取图像片以此扩充训练样本.
2.2 自相似先验设计
对于每个图像片xi所使用的训练集合{[yj;y′j]},yj∈Ra2 ,y′j∈Ra2 ,引入高斯混合模型逼近训练集的概率密度函数,如式(6)所示:
Pyjy′j=πk Nyjy′jμykμy′k,∑yyk ∑yy′k ∑y′yk ∑y′y′k (6)
式中:向量μk = [μyk;μy′k]和矩阵∑k = [∑yyk,∑yy′k ,∑y′yk ,∑y′y′k ]分别表示第k个高斯混合模型的均值向量和协方差矩阵,内部的元素向量μyk、 μy′k和矩阵∑yyk、∑y′y′k 分别表示训练集合联结前的图像片向量集合{yj}和{y′j}在高斯混合模型聚类结果中第k簇两组图像片的均值向量和协方差矩阵,∑yy′k 、∑y′yk 是第k簇训练样本中两组图像片的协方差矩阵,按照协方差矩阵的定义∑yy′k = (∑y′yk )T(T表示对矩阵进行转置操作),πk表示高斯混合模型中第k个高斯成分的权重. 式(6)中高斯混合模型参数集Ω = {πk,μk,∑k}K k=1的求解采用EM算法,分为E步和M步迭代进行估计.
然而,在实际执行过程中,如果对每一个高分辨率图像片的估计都使用EM算法进行模型训练,会导致算法的执行异常复杂,不能在可容忍时间范围内结束计算. 为了解决这一问题,使用参数自动更新的EM算法进行模型训练[30]. 由于相邻两个高分辨率图像片存在内容重复,其对应的参数间有着密切的关系,后一个图像片的参数集能够借助前一个图像片模型的训练结果,仅使用新出现的样本对参数集进行更新,既能够快速完成训练,又能够保证模型的准确程度. 图3中算法详细地列出了模型参数更新的具体步骤.
Input:LR image Y;upsampling factor s
Output:Reconstructed HR image X
X = upsampling(Y,s)% bicubic
For t = 1 : T do
X′ = X;
Y′ = downsampling(X′,s);% bicubic
{π′k,μ′k,Σ′k} = initialize(Y,Y′);% with EM
For each patch x′iextracted from X′
{yj,y′j} = training(Y,Y′);
zl = [yl;y′l];% l = 1,2,…,M
For k = 1 ∶ K
For each new example zi
γ(k|zi,Ω) = ;
nk = γ(zi | μk,∑k);
End For;
πk = [απ(nk /M) + (1 - απ)π′k]nk;
μk = αμπk zi /πk +(1 - αμ)μ′k;
Σk = αΣ + (1 - αΣ)∑′k
End For
Compute μ Xi and ∑ Xi with the GMM
parameters Ω = {πk,μk,∑k};
Estimate xi with μ Xiand ∑ Xi;
End For
Estimate the HR image X with {xi}N i=1;
End For
Return X
对于未知的高分辨率图像X,把从中抽取的图像片xi和在图像X′中相同位置的图像片 进行连结,得到对应的连结向量[xi ;x′i],它在训练集合的概率密度函数中存在的概率可以表示为:
进而可以发现xi 的条件概率服从一个特定的高斯分布:
P(xi |x′i,Ω)~N(xi | μXi,∑Xi) (8)
式中:μXi为这个高斯分布的均值向量,∑Xi为这个高斯分布的协方差矩阵,它们的表达式分别为:
其中Δik和(Δik)2分别为式(9)和式(10)中的公共因子,Δik的具体表达式为:
事实上Δik描述了图像片x′i由当前所训练的高斯混合模型中第k个高斯成分生成的后验概率. 在实验中发现,在高斯成分个数K确定的前提下,对于绝大多数的图像片而言,集合{Δik}是稀疏的,即绝大多数Δik值为0,或非常接近0,尤其是混合模型中高斯成分的个数K = 3时,仅使用Δik取最大值时所对应的高斯成分,即第Δik个高斯成分,可准确表示μXi和∑Xi(在实验部分,将进一步对图像片的该性质进行说明),Δik的表达式为:
式(12)表示在第i个图像片所对应的高斯混合模型分布中,第k*i个高斯成分对应的公共因子Δik*i值最大,N表示在图像X中抽取图像片的总数. 因此图像片xi对应的特定高斯分布的均值向量 μXi和协方差矩阵∑Xi可以近似表示为:
μXi≈ μyk*i +∑yy′k*i (∑y′y′k*i )-1(x′i - μy′k*i) (13)
∑Xi≈∑yk*i -∑yy′k*i (∑y′k*i )-1∑y′yk*i (14)
通过上述推导,理想的重建图像中任意抽取的图像片x其自相似先验的具体表达式为:
ρ(x) = (xi - μXi)T∑-1Xi (xi - μXi) (15)
進而,整幅图像的自相似性先验表示为:
P(X) = (Pi X - μXi)T∑-1Xi (Pi X - μXi) (16)
式中:N为在未知超分辨率图像X中抽取的图像片数量;Pi为一个预先设定的抽取矩阵,用于抽取X中的第i个图像片. 由于式(15)(16)中所描述的先验知识是对未知的高分辨率图像中的每一个图像片在较低尺度中重现的概率进行估计,是对理想重建高分辨率图像的一种刻画,因此将这一先验知识称为理想重建图像自相似先验.
2.3 高分辨率图像重建
先验的表达式确定后,该算法的成本函数就能够通过这个具体先验表达式进一步构造出来. 在本文的超分辨率重建算法中,要求得到的超分辨率重建结果在满足理想重建图像自相似性先验的同时,重建的高分辨率图像在通过成像式(1)处理后,还应与输入的低分辨率图像尽可能的相似. 为了兼顾这两个要求,通过加权求和的形式整合这两项表达式,将该算法的成本函数设计为:
其中第一项称为保真项,它能够使得估计的高分辨率图像X在经过退化模型处理后得到的结果与观察图像尽可能的一致;第二项是先验项,用于约束重建的高分辨率图像满足尺度间自相似性. 用于两项间的权衡. 这个成本函数的求解较为简单,可直接对式(17)进行求导,并令导数为0,即可得到关于X的表达式,进一步整理可以得到超分辨率图像的最终估计结果:
然而在重建高分辨率图像X表达式的计算过程中,需要操作的矩阵通常具有极大的规模,如下采样矩阵D、滤波矩阵H和抽取矩阵Pi,这样的计算方式占用内存空间过大、耗时且复杂,对于普通计算设备而言,极易造成内存溢出;同时也考虑到输入的低分辨率图像存在噪声、模糊等情形. 为了解决这一问题,尝试使用“分解”的策略进行解决. 针对每一个图像片xi,在先验给定的前提下,借助它的后验概率密度函数进行计算,如式(19)所示:
式中:i是理想高分辨率图像片xi的通过该算法得到的估计版本;‖yi - Di Hi x‖2与成本函数中的保真项‖Y-DHX‖2作用相同;(x - μXi)T∑-1Xi(x- μXi)与成本函数中的先验项(Pi X - μXi)T∑-1Xi(Pi X - μXi)相一致;σ2与平衡参数λ相对应,但此时的σ2有着明确的意义,它表示输入图像中假定高斯白噪声的方差. 通过对式(19)求导,并令导数为0,来求解此方程,可以得到每一个图像片的表达式,最后,用估计到的图像片集合{xi}N i=1,在忽略边界位置处的影响后,根据式(20)构造完整的图像X.
根据前述算法的描述,可以完成算法的一次迭代,通过判断当前X和X′的差异是否足够小,以决定算法是否需要执行下一次迭代. 当满足输出条件时,即可直接输出X作为超分辨率重建的结果,这个超分辨率过程的伪代码如图3所示. 最后,在图4中给出了本文算法对一幅彩色图像进行超分辨率重建的完整过程.
3 实验结果与分析
通过主观视觉观察和客观参数比较两种方式验证理想重建图像自相似性先验超分辨率算法的效率. 首先对算法流程中需要设定的参数进行说明,然后给出本文算法和同类以及前沿算法重建图像质量、消耗时间的比较,最后对该算法的性能做进一步的理论分析.
3.1 实验设置
在实验过程中,为了模拟成像过程,构建理想高分辨率图像和低分辨率输入图像测试样本对,用于测试算法的性能,我们在一些常用测试集中随机抽取样本作为理想的高分辨率目标,将这些抽取到的图像用双三次方法下采样s倍,并用高斯低通滤波器(均值为0,方差为0.5)对它们滤波,以生成用于输入的低分辨率图像. 将这些低分辨率图像输入到测试算法中,超分辨率s倍,得到的重建结果和计算过程消耗的时间可用于评价该算法. 一般而言,图像重建结果越接近理想目标图像,计算过程消耗时间越少,算法的性能越高.
本文算法在首次迭代执行前,仅有输入图像Y已知,先将Y双三次上采样s倍的结果初始化为X′,再将X′使用双三次下采样s倍用于初始化Y′. 由于图像尺度间的自相似性有随着尺度的降低而减弱的特性,当超分倍数较大时,直接放大到目标倍数会降低重建图像质量,为此我们采用逐级放大的方式进行处理,每次放大2倍,并将超分辨率结果作为算法的输入再次放大,直到达到目标倍数为止,最后一次放大不足2倍时,直接放大到目标倍数. 对于输入的彩色图像,先将这幅图像从RGB空间转换到YUV空间,由于代表亮度信息的Y通道对人眼较为敏感,用本文提出的理想重建图像自相似性超分辨率算法进行处理;代表颜色信息的U、V通道对人眼的刺激相对迟弱,U、V通道直接用双三次上采样方法放大到目标倍数,再将重建结果从YUV空间转换到RGB空间进行显示及保存.
另外,考虑到随着算法迭代次数增加,重建结果中包含噪声的能级应逐渐减少,将式(20)中描述噪声等级的参数设定为σ = ,(T为算法的迭代次数). 由于此算法考察的是图像自相似性,不同尺度间的图像片抽取尺寸相同,式(20)中图像片尺寸参数设定为a = 7,即抽取尺寸为7 × 7的图像片. 算法中的每一个未知超分辨率图像片都需要在输入图像Y和它的低频版本中对应的位置处设置窗口,以便抽取训练样本. 若窗口尺寸设置过大,则样本间的一致性不强,影响模型的准确程度;若窗口尺寸设置过小,则会因为抽取到的样本数量不足,导致模型欠拟合. 本文将窗口尺寸设定为w = 32,即每一个估计的图像片都在输入图像与之相同中心位置 32 × 32的窗口中抽取训练样本. 对于边界附近的超分辨率图像片,为了能够定位到相应的窗口,需要对图像Y和Y′做镜像扩展处理. 与窗口尺寸相匹配的高斯混合模型中高斯成分的个数设置为K = 3.
3.2 主观观察结果
为了验证本文算法的有效性,我们选择与本文形式类似方法(包括Glasner[8]、GPR[16]、Self-ExSR[17]和MMPM[29])、借助外界训练集合方法(ScSR[2]、ASDS[31]、A+[4]、SPM[32]和JOR[33])以及深度学习方法(SRCNN[5]、FSRCNN[6]、lapSRN[7])进行了一系列的比对实验. 所选择的比较算法除Glasner算法外均从作者主页下载,Glasner算法的代码为我们使用Matlab2019b软件自行编写,且效果与文献[8]中给出的结果基本一致. 本文算法和参与比较的算法均在Intel(R)Core(TM) i7-5600 CPU @ 2.60 GHz,8.00 GB缓存的硬件环境,Windows 7专业版64位操作系统,Matlab2019b的软件环境下进行实验.
如图5和图6所示,显示的是图像“parrot” 和“fence”使用多种不同方法分别放大3倍和4倍的结果. 观察用线框标识出的局部子区域的放大显示结果,可以发现在显著边缘位置、纹理细节丰富区域能够明显地保持边缘和纹理的结构,能恢复出更多正确的细节,使图像看上去更加清晰、自然. 两组超分辨率结果中,ScSR、Glasner、Self-ExSR、GPR以及SPM方法重建的超分辨率图像在显著边缘位置都出现了可见的模糊和噪声. ASDS、A+、JOR、MMPM和本文提出的方法超分辨结果较为清晰,在显著边缘及纹理区域附近并未出现可见的噪声和模糊等形式的伪影. MMPM方法和我们的方法恢复出了较多的高频信息,观察“parrot”图像中鹦鹉的眼睛和羽毛区域以及“fence”图像中带有平行结构的“篱笆”,可以看出我们的方法对图形结构保持得更加完整,几乎观察不到可见的变形.
图7是方法和深度学习方法SRCNN和lapSRN对图像“barbara”超分辨率放大4倍的比较结果. 测试图像“barbara”包含丰富的纹理信息,在超分辨率过程中,这些纹理结构虽有固定的模式,却又不尽相同,在超分辨率过程中极易产生变形或引入噪声. 观察图7可以发现,我们的方法产生的超分辨率结果和理想高分辨率图像最为接近,基本上保持住了纹理区域的外观. SRCNN、lapSRN方法产生的超分辨率结果都使得纹理的基本结构发生了严重的变形,且能够观察到有明显噪声出现.
3.3 客观评价结果
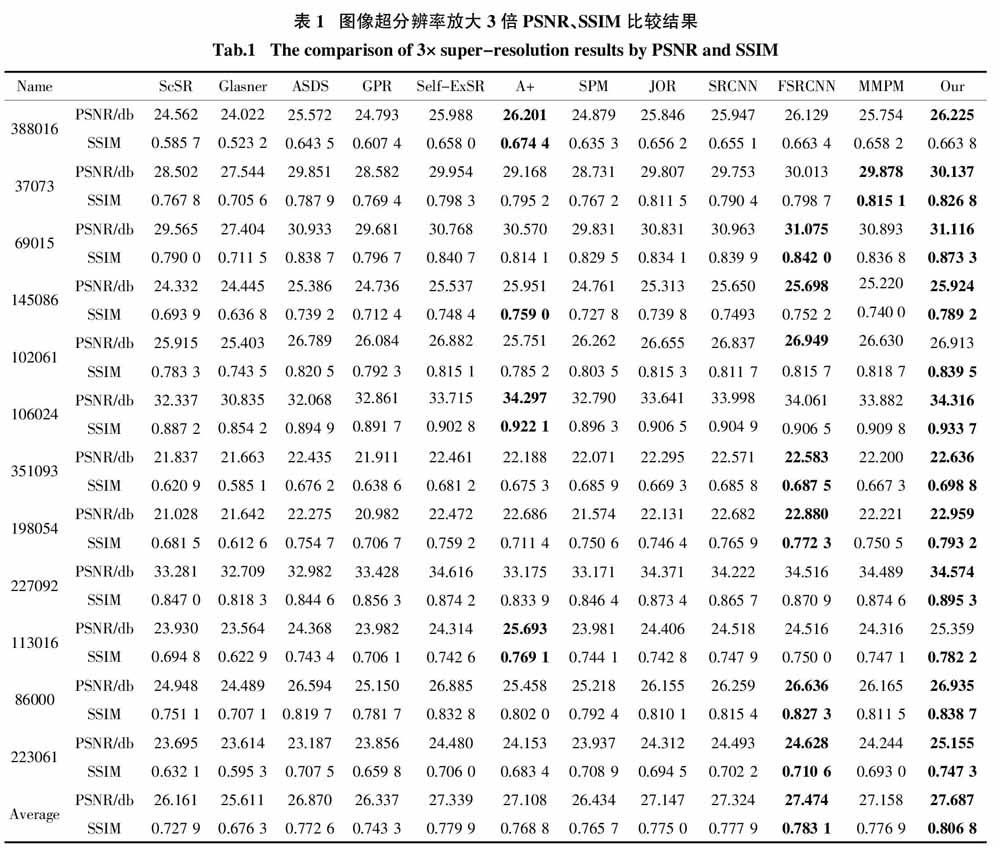
为了进一步说明理想图像自相似性先验超分辨率算法的性能,借助客观评价参数对我们的方法和其他方法进行比较,主要使用的评价指标包括峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity Index Measure,SSIM). 一般來说,这两个评价参数的数值越大,代表算法得到的重建图像质量越好. 在BSD500图像集合中随机抽取12幅图像,如图8所示,这些图像的内容囊括人物、动物、建筑物和风景等,包含显著边缘、复杂纹理和精细结构等内容,具有极强的代表性. 按照前述步骤操作,将这些图像进行超分辨率放大3倍处理,其客观参数比较结果如表1所示.
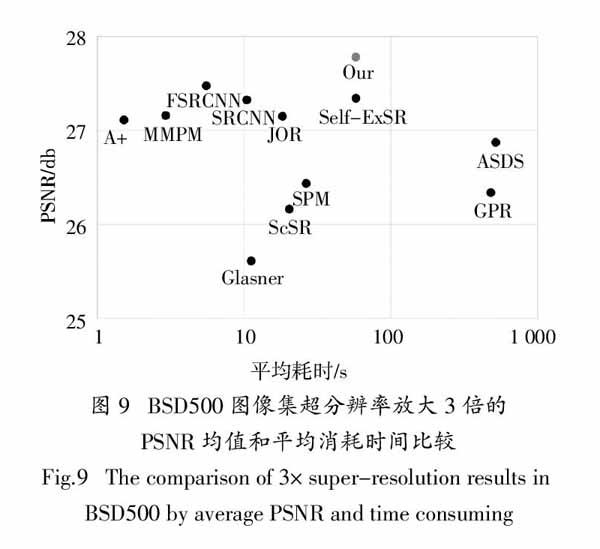
在表1中,每一行数据代表一幅图像使用不同方法超分辨率的结果,每一列代表一种方法超分辨率处理不同图像的结果,其中每一幅图像对应两行数据,第一行为PSNR结果,第二行为SSIM结果. 观察表1可以发现,在PSNR参数比较中,表1中我们的方法有10张图像结果最优;SSIM参数比较中,我们的方法有11张图像结果最优(最优结果均用加粗字体标出). 表1中我们的方法没有得到最优结果的图像,它们的评价参数数值也相对较大,都取得了次优结果. 另外,观察表1中评价参数平均值,可以看出我们方法的PSNR和SSIM平均值都排在第1位,我们方法的PSNR平均值高于MMPM算法0.529 db,SSIM平均值高于MMPM算法0.030. 为了从统计的角度出发验证本文算法的有效性,以BSD500图像集合全体作为测试对象,用本文算法和参与比较的11种前沿算法分别对测试集中的图像进行3倍放大. 其性能比较结果如图9所示,图中每一个实心圆点代表一个算法,每个点的横坐标表示算法的平均消耗时间,纵坐标表示算法重建图像的PSNR均值. 从图9中可以看出,本文算法平均PSNR值最大,图像质量最好. 该算法放大一幅BSD500中的图像平均消耗时间约1 min,明显少于GPR和ASDS算法,与Self-ExSR算法耗时相近.
3.4 分析討论
首先,联合高斯混合模型建模在形式上不同于训练字典下的稀疏算法,它在解决超分辨率问题中有先天优势. 因为超分辨率成像中的滤波矩阵和下采样矩阵均为非单位矩阵,在与字典进行计算时,会导致训练字典的互相干性增大[24],降低重建图像质量,而基于联合高斯混合模型的超分辨率方法不存在这样的问题.
在挖掘理想重建图像自相似性的超分辨率算法中,对每一个待超分辨率的图像片,该算法以当前图像片的位置为中心构建窗口,仅使用少量的高斯成分对图像片空间位置附近的样本建模. 由于这些图像片位置彼此相邻,描述的内容相似,具有较强的一致性,能使训练得到的高斯混合模型更加准确. 同理,Δik值也会体现出极强的稀疏性.
最后,已有方法都是将训练得到的高斯混合模型作为先验,并假定所有的图像片都能由模型中后验概率最高的高斯成分生成. 而我们的方法对这个高斯混合模型做进一步推导,把推导结论(每个未知的高分辨率图像片都服从一个特定的高斯分布)作为先验知识,设计成本函数. 二者的区别在于后者进一步挖掘了后验概率最高的高斯成分,利用了这个高斯成分的协方差信息进行计算,使得图像重建效果优于前者.
4 总 结
在超分辨率研究工作中,我们发现理想重建高分辨率图像的自相似性体现最为强烈,而受降质因素影响的重建高分辨率图像自相似性会明显减弱.
当使用高斯混合模型对这一现象进行描述时,通过对模型进行推导,可以发现每一个理想的高分辨率图像片的自相似性都符合一个特定的高斯分布. 将这个规律作为先验知识添加到超分辨率框架中,显著提升了重建超分辨率图像的质量. 该方法无需使用外界图像进行训练,仅通过输入图像和其对应的低频版本为每个重建图像片建模,以一种在线训练的方式联合构建高斯混合模型. 随着输入图像的变化,模型参数能够自动进行调整,以适应新的情况. 因此该算法较其他预测模型有着更强的鲁棒性,尤其适用于数字电视高清显示等需要较大超分辨率倍数但又无额外参数存储装置的场景.
参考文献
[1] NASROLLAHI K,MOESLUND T B. Super-resolution:a comprehensive survey[J]. Machine Vision and Applications,2014,25(6):1423—1468.
[2] YANG J C,WRIGHT J,HUANG T S,et al. Image super-resolution as sparse representation of raw image patches[C]// Computer Vision and Pattern Recognition. Anchorage,AK:IEEE,2008:1—8.
[3] TIMOFTE R,DE SMET V,GOOL L V. Anchored neighborhood regression for fast example-based super-resolution[C]// 2013 IEEE International Conference on Computer Vision. Sydney:IEEE,2013:1920—1927.
[4] TIMOFTE R,DE SMET V,GOOL L V. A+:Adjusted anchored neighborhood regression for fast super-resolution[C]// Asian Conference on Computer Vision. Singapore:Springer,2014:111—126.
[5] DONG C,LOY C C,HE K M,et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(2):295—307.
[6] DONG C,LOY C C,TANG X O. Accelerating the super-resolution convolutional neural network[C]// European Conference on Computer Vision. Amsterdam:Springer,2016:391—407.
[7] LAI W S,HUANG J B,AHUJA N,et al. Fast and accurate image super-resolution with deep Laplacian pyramid networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,41(11):2599—2613.
[8] GLASNER D,BAGON S,IRANi M. Super-resolution from a single image[C]// 2009 IEEE 12th International Conference on Computer Vision. Kyoto:IEEE,2009:349—356.
[9] ZONTAK M,IRANI M. Internal statistics of a single natural image [C]// Computer Vision and Pattern Recognition. Colorado:IEEE,2011:977—984.
[10] ZONTAK M,MOSSERI I,IRANI M. Separating signal from noise using patch recurrence across scales [C]// Computer Vision and Pattern Recognition. Portland,oregon,USA:IEEE,2013:1195—1202.
[11] MICHAELI T,IRANI M. Blind deblurring using internal patch recurrence [C]// European Conference on Computer Vision. Zurich:Springer,2014:1—16.
[12] LOTAN O,IRANI M. Needle-match:reliable patch matching under high uncertainty [C]// 2016 IEEE International Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:439—448.
[13] 潘宗序,禹晶,胡少興,等. 基于多尺度结构自相似性的单幅图像超分辨率算法[J]. 自动化学报,2014,40(4):594—603.
PAN Z X,YU J,HU S X,et al. Single image super resolution based on multi-scale structural self-similarity [J]. Acta Automatica Sinica,2014,40(4):594—603. (In Chinese)
[14] FREEDMAN G,FATTAL R. Image and video upscaling from local self-examples[J]. ACM Transactions on Graphics,2011,30(2):1—11.
[15] YANG J C,LIN Z,COHEN S. Fast image super-resolution based on in-place example regression [C]// 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland,oregon,USA:IEEE,2013:1059—1066.
[16] HE H,SIU W C. Single image super-resolution using Gaussian process regression[C]// Computer Vision and Pattern Recognition. Colorado:IEEE,2011:449—456.
[17] HUANG J B,SINGH A,AHUJA N. Single image super-resolution from transformed self-exemplars[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA:IEEE,2015:5197—5206.
[18] ZHA Z Y,YUAN X,ZHOU J T,et al. Image restoration via simultaneous nonlocal self-similarity priors[J]. IEEE Transactions on Image Processing,2020,29:8561—8576.
[19] LIN C H,BIOUCAS-DIAS J M. An explicit and scene-adapted definition of convex self-similarity prior with application to unsupervised sentinel-2 super-resolution[J]. IEEE Transactions on Geoscience and Remote Sensing,2020,58(5):3352—3365.
[20] FAN L W,LI X M,FAN H,et al. Adaptive texture-preserving denoising method using gradient histogram and nonlocal self-similarity priors[J]. IEEE Transactions on Circuits and Systems for Video Technology,2019,29(11):3222—3235.
[21] ZHA Z Y,ZHANG X G,WANG Q,et al. Group sparsity residual constraint for image denoising with external nonlocal self-similarity prior[J]. Neurocomputing,2018,275:2294—2306.
[22] ZHANG L,WEI W,SHI Q F,et al. Accurate imagery recovery using a multi-observation patch model[J]. Information Sciences,2019,501:724—741.
[23] 肖进胜,单姗姗,易本顺,等. 基于分区灰度投影稳像的运动目标检测算法[J]. 湖南大学学报(自然科学版),2013,40(6):96—102.
XIAO J S,SHAN S S,YI B S,et al. Moving targets detection based on subzone gray projection video stabilization[J]. Journal of Hunan University (Natural Sciences),2013,40(6):96—102. (In Chinese)
[24] 李明俊,张正豪,宋晓琳,等. 基于一种多分类半监学习算法的驾驶风格分类模型[J]. 湖南大学学报(自然科学版),2020,47(4):10—15.
LI M J,ZHANG Z H,SONG X L,et al. Driving style classification model based on a multi-label semi-supervised learning algorithm[J]. Journal of Hunan University (Natural Sciences),2020,47(4):10—15. (In Chinese)
[25] YU G S,SAPIRO G,MALLAT S. Solving inverse problems with piecewise linear estimators:from Gaussian mixture models to structured sparsity[J]. IEEE Transactions on Image Processing,2012,21(5):2481—2499.
[26] ZORAN D,WEISS Y. From learning models of natural image patches to whole image restoration[C]//2011 International Conference on Computer Vision. Barcelona:IEEE,2011:479—486.
[27] NIKNEJAD M,RABBANI H,BABAIE-ZADEH M. Image restoration using Gaussian mixture models with spatially constrained patch clustering[J]. IEEE Transactions on Image Processing,2015,24(11):3624—3636.
[28] SANDEEP P,JACOB T. Single image super-resolution using a joint GMM method[J]. IEEE Transactions on Image Processing,2016,25(9):4233—4244.
[29] HUANG Y F,LI J,GAO X B,et al. Single image super-resolution via multiple mixture prior models[J]. IEEE Transactions on Image Processing,2018,27(12):5904—5917.
[30] LU X,LIN Z,JIN H L,et al. Image-specific prior adaptation for denoising[J]. IEEE Transactions on Image Processing,2015,24(12):5469—5478.
[31] DONG W S,ZHANG L,SHI G M,et al. Image deblurring and super-resolution by adaptive sparse domain selection and adaptive regularization[J]. IEEE Transactions on Image Processing,2011,20(7):1838—1857.
[32] PELEG T,ELAD M. A statistical prediction model based on sparse representations for single image super-resolution[J]. IEEE Transactions on Image Processing,2014,23(6):2569—2582.
[33] DAI D,TIMOFTE R,VAN GOOL L. Jointly optimized regressors for image super-resolution[J]. Computer Graphics Forum,2015,34(2):95—104.
收稿日期:2020-12-17
基金項目:国家自然科学基金资助项目(61772144),National Natural Science Foundation of China(61772144);广东省自然科学基金资助项目(2017A030310618),Natural Science Foundation of Guangdong Province(2017A030310618)
作者简介:李键红(1981—),男,辽宁朝阳人,广东外语外贸大学讲师,硕士生导师,博士
通信联系人,E-mail:wyrljh@163.com
