基于SVM和CRF双层模型的FrameNet框架消歧
2021-09-26秦博宇郝晓燕刘永芳
秦博宇,郝晓燕,刘永芳
太原理工大学 信息与计算机学院,太原030600
框架语义学(frame semantics)是由Fillmore于20世纪70年代提出的。框架语义学作为认知语言学语言结构研究的两大基础理论之一[1],认为语言及词汇的理解必须建立在框架(frame)之上。在框架语义分析中,FrameNet作为一个独特的语义知识库已经得到了众多研究者的关注。FrameNet是在Fillmore等学者的主持之下由加州大学伯克利分校建立的一项以框架语义学为基础理论的研究工程,曾作为国际计算语言学协会(ACL)国际语义测评SemEval-2007的第19项任务[2]——Frame Semantic Structure Extraction的测评语料对框架语义结构进行抽取。
框架消歧任务是框架语义分析的一个子任务,同时它也是框架语义分析中必不可少的中间环节,具有非常重要的作用。其主要任务是在例句中根据给定目标词的上下文语境,自动识别出该目标词所属的框架。框架消歧任务可以解决自然语言当中的“一词多义”现象,在一定程度上为机器翻译、信息检索等领域提供了语义支持。
目前的框架消歧研究都是将其看作一个传统的单模型分类问题。虽然框架消歧任务在单个模型中都取得了较好的结果,但是仍然存在以下几方面的问题。首先,其结果比较依赖统计模型的性能及参数设置。其次,分类模型将目标词看作独立的个体进行分类不能很好地利用目标词之间的隐性联系。最后,特征标记被认为相互独立,特征之间的关联性较小。
针对以上这些问题,本文选择了在框架消歧任务中表现较好的SVM分类模型和CRF序列标注模型进行组合,首次提出了基于SVM和CRF的双层模型对FrameNet语料进行框架消歧的方法。首先利用SVM模型对待消歧目标词进行分类得到分类标签,然后将分类标签序列与文本特征序列输入到CRF模型,建立特征之间的关联并进行序列标注。
基于SVM和CRF的双层模型利用分治思想将框架消歧问题转化为分类问题和序列标注问题,解决了双层模型在FrameNet框架消歧任务中的空白局面。首先,CRF模型可以充分利用观察序列中的全部特征信息[3-4],弥补了SVM模型对目标词单独分类导致忽略了目标词之间的隐性联系这一缺陷。同时,CRF模型作为双层模型的第二层可以充分利用SVM模型的分类标签这一特征。这些分类标签可以提供大量的分类信息,与原有的文本语义特征结合可以建立起特征之间的联系,在一定程度上解决了特征之间无关联的问题。其次,SVM模型适合处理有限样本的分类问题,并且可以获得全局最优值[5],解决了CRF模型只能取得局部最优值这一缺陷。由于双层模型优势互补,能够进一步提高框架消歧的准确率,最终本文提出的新的可行的FrameNet框架消歧方法取得了较为理想的结果。
1 框架消歧研究现状
目前针对框架消歧的研究并不是很多,大部分都借鉴词义消歧的方法,采用单个统计模型分类的思想来解决。美国的Bejan和Hathaway[6]抽取词元特征和命名实体特征,利用支持向量机和最大熵模型建立多分类器,将框架识别看作是多分类问题。结果显示使用SVM进行框架消歧的准确率比最大熵模型要高。瑞典的Johansson和Nugues[7]使用基于依存句法的方法来提取框架语义结构。他们利用过滤规则来提取能够激起不同框架的目标词,然后利用SVM模型对目标词进行分类。实验中选取了目标词的词根、词形、目标词的依存类型集合、子节点和父节点集合作为特征,在FrameNet语料上取得了较好的结果。该研究证明在一定程度上,依存句法特征可以提升框架消歧的准确率。Li等[8]针对汉语框架消歧提出了基于依存分析的条件随机场模型,首次将框架消歧问题看作是一个序列标注问题,框架识别效果较好。该研究初步验证了条件随机场序列标注模型在框架消歧任务中的有效性。刘海静[9]将框架消歧分别看作是序列标注和分类问题,利用SVM模型和T-CRF模型的框架消歧结果进行对比。实验证明了T-CRF模型相较于SVM模型来说在汉语框架消歧任务中可以得到较好的结果。李济洪[10]等将框架消歧看作是分类问题,选取了词、词性、基本块和依存句法树上的特征,用最大熵模型进行框架消歧。该模型得到最好的结果是69.28%。李国臣等[11]认为人工特征选择方法不能有效利用每个目标词的语义特征,因此针对汉语框架消歧问题提出了特征模板自动选择算法,利用最大熵模型建模,取得了较好的结果。
综合上述研究可以发现,传统的单分类模型比较依赖统计模型的性能及参数设置。并且,分类模型将目标词看作独立的个体进行分类,无法利用目标词之间的隐性联系。另外,特征标记被认为相互独立,特征之间的关联性较小。因此针对以上问题本文提出了基于SVM和CRF双层模型的框架消歧方法。与以往的研究不同的是,该方法融合了双层模型不同标记间的联系信息,建立起不同标记序列间的信息交互,有效解决了无法提取目标词之间的隐性特征和特征之间无关联的问题。本文研究的是使用SVM和CRF双层模型对于FrameNet框架消歧的有效性。
2 基于SVM和CRF的双层框架消歧模型
2.1 支持向量机(SVM)
SVM是建立在统计学习的VC理论和结构风险最小化原则上的[12],善于处理小样本、非线性及高维模式识别问题,是目前机器学习中最常用且性能表现较好的一个分类器。在本文的研究中主要讨论的是将SVM模型用于为待消歧目标词分类。
假设训练数据集为T={(x1,y1),(x2,y2),…,(xm,ym)},其中xi∈输入空间,yi∈{-1,+1}是xi的标记,i=1,2,…,n。如果xi属于正类,则将yi标记为+1;否则将yi标记为-1。SVM的任务就是寻找能够将训练数据划分为两类的最优超平面,即求解下面公式(1)的凸二次规划方程:
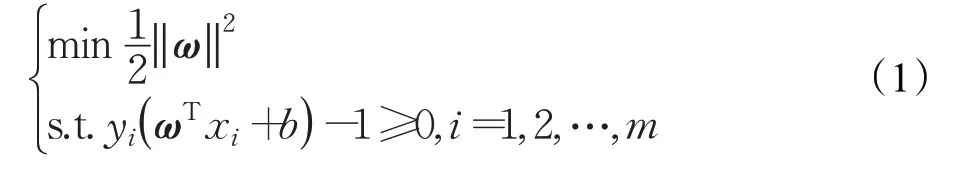
针对本文的框架消歧任务来说,每个待消歧词元可以激起的框架不止一个,因此可以将框架消歧任务看作是一个多分类的问题,采用“一对一(One versus One)”的策略构造多分类器。SVM模型识别的对象是FrameNet例句中的待消歧目标词,将这些词的语义特征提取成支持向量集,计算其到超平面的距离,如果得到了大于0的值,则意味着是+1类,否则为-1类。
2.2 条件随机场(CRF)
条件随机场(CRF)模型是由Lafferty等人于2001年提出的,它是基于最大熵模型和隐马尔可夫模型的判别式概率无向图学习模型,其中线性条件随机场(CRFs)是最简单的一种。
给定一个观测序列X={X1,X2,…,Xn},Y={y1,y2,…,yn}为X对应的状态序列,CRF模型如图1所示。
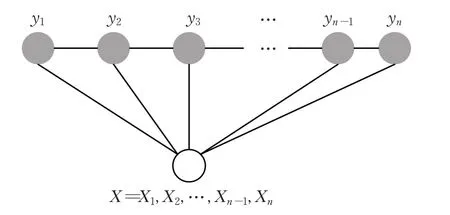
图1 CRF模型结构图Fig.1 Structure diagram of CRF model
CRFs定义其对应状态序列的条件概率为:

在训练过程中,通过训练数据集并使用最大似然估计获得条件概率模型;解码时采用Viterbi解码算法,对于给定的条件序列X,求出条件概率最大的输出序列Y*。
特别地,CRF可以很好地利用上下文信息且一般用于序列标注任务,是目前主流的序列标注模型。对于本文研究的框架消歧任务来说,目标词的上下文信息对于消歧结果非常重要,但是框架消歧是针对有歧义目标词为其分配合适的框架,并不是一个典型的序列标注任务。因此,为了将框架消歧任务换成一个序列标注的问题,本文将每个待消歧目标词所属的正确框架分配给该目标词,其他目标词被标记为“O”,这样就可以实现基于CRF模型的框架消歧方法。
2.3 基于SVM与CRF的双层模型
对于传统的单模型方法来说,大部分研究采用了分类的思想对歧义目标词进行分类。然而单分类模型没有考虑到目标词之间的联系,导致隐性特征难以被提取、特征之间的关联性较小,并且分类结果比较依赖于分类模型的性能及参数的设置。
针对上述不足,本文提出了基于SVM和CRF双层模型的框架消歧方法。在双层模型的第一层采用SVM模型对语料进行粗分类并得到语料的分类标签;然后将分类标签作为新的特征与原有的语义特征结合,在双层模型的第二层利用CRF模型进行序列标注,最终获取到待消歧目标词最合适的框架。具体的实现过程分为两个步骤(两层):
(1)利用SVM模型对文本序列的特征向量进行粗分类,得到文本中对应待消歧目标词的分类标签序列,并且使用分类标签对文本序列进行预标注,标签集℧1={labeli,O},i=1,2,…,n。其中labeli表示待消歧目标词对应的标签,O表示其他词。
(2)将SVM分类标签作为特征加入CRF模型的特征模板,为已经预标注的文本序列标注其对应的框架名称,标签集℧2={F,O},其中F表示待消歧目标词激起的正确框架名称,O表示其他词。
在本文的FrameNet框架消歧任务中,将文本的特征向量输入到SVM模型中,利用SVM模型将文本分类并且得到文本中语料的分类标签label。通过第一层SVM分类得到的分类标签label,可以得到文本的一个分类标签序列L={L1,L2,…,Ln},输入序列X为FrameNet文本序列,输出序列Y为文本对应的标签序列。将分类标签序列L和输入序列X共同作为CRF模型的输入。在随机变量X取值为x,随机变量L取值为l的条件下,随机变量Y的条件概率为:
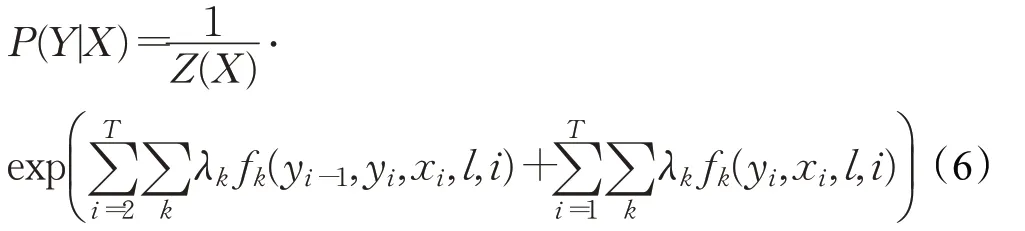
在给定输入序列X={x1,x2,…,xn}的情况下最大化输出标签序列Y的联合条件概率的似然估计,最大可能的标记序列为:

从定义可以看出基于SVM和CRF的双层模型将分类标签作为特征加入势函数中,可以融合双层模型不同标记间的联系信息,建立起不同标记序列间的信息交互,将相互独立、没有信息交互的序列联系到了一起,解决了特征之间无关联的问题,丰富了特征模板。
双层模型的算法实现具体步骤如下:
(1)输入:FrameNet语料序列X={X1,X2,…,Xn}。
(2)抽取特征集F={f1,f2,…,fn}。
(3)利用SVM模型对文本的特征向量进行粗分类,得到SVM模型的分类标签序列L={L1,L2,…,Ln}。
(4)将分类标签label作为特征增加到CRF模型特征模板当中,此时抽取的特征集为F*={f1,f2,…,fn,label}。
(5)将语料序列X、SVM模型的分类标签序列L及文本特征F*输入到CRF模型,得到第二层的标注序列
Y={Y1,Y2,…,Yn}。
(6)输出:标注结果。
基于SVM和CRF的双层框架消歧模型系统分析流程图如图2所示。
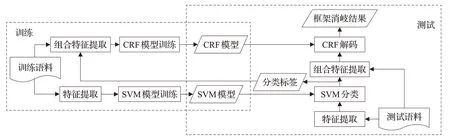
图2 双层模型系统分析流程图Fig.2 Analysis flow chart of two-stage model system
3 特征提取及选择
3.1 SVM模型的特征
SVM模型特征主要包括两个方面,分别是词性和依存句法关系。提取文本中句子的词性特征及依存句法特征时分别使用了Stanford大学的自然语言处理工具stanford-postagger及stanford-parser。
以目标词“CAN”为例,特征提取及选择步骤的具体示例如下:
例句1Breakfast came with tea in petrol CANS.
将例句进行依存句法分析后可以得到一棵依存句法树,如图3所示。
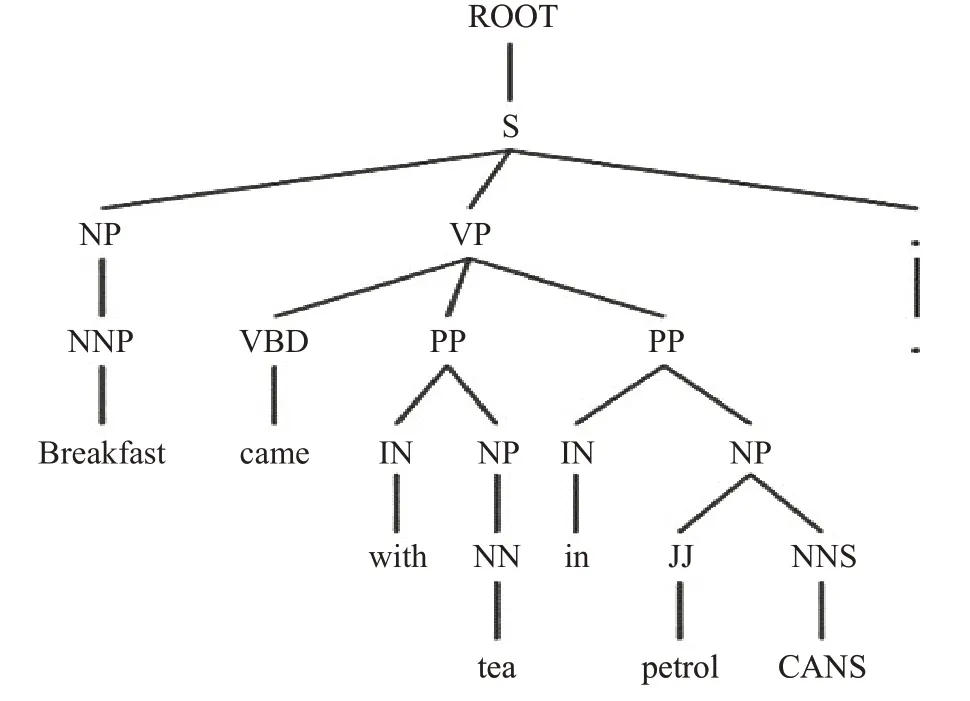
图3 依存句法树Fig.3 Dependency syntax tree
依存句法树中的叶子节点对应着句子中的单词,图3中的ROOT表示要处理的句子,S表示陈述句。在依存句法分析树中,对于句子中的每个单词或短语所充当的成分都有明确的标记,这些功能符号都具有对应的含义。表1显示了部分常用的各种标记及其功能。
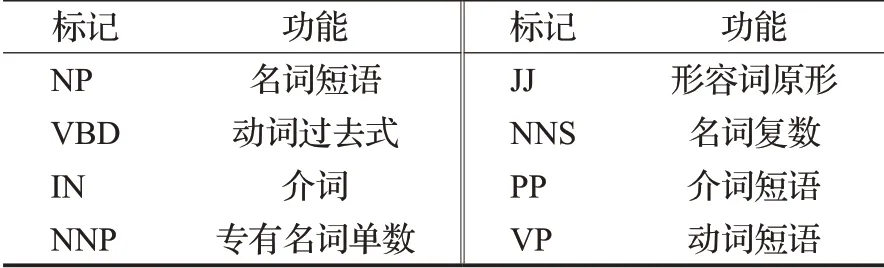
表1 依存句法树中常用的标记及其功能Table 1 Tags and their functions commonly used in dependency syntax trees
在依存句法树中每个叶子节点所表示的单词与其父节点之间存在着依存句法关系。本文所选取的依存句法关系(DEP)包括:nmod(复合名词)、conj(并列成分)、nsubj(名词性主语)、amod(形容词)、dobj(直接宾语)、case(介宾短语)这六种。
因SVM分类模型针对的是待消歧的目标词,通过训练后得到的模型对目标词进行预测框架类型,所以只需要考虑与待消歧目标词关系密切的文本特征即可。本文选择目标词、目标词前后位置的词、目标词的词性、目标词前后位置的词性、目标词的父子节点的词性、目标词前后位置词的父子节点的词性、目标词与父节点的依存句法关系、目标词与子节点的依存句法关系、目标词前后位置词与其父节点的依存句法关系及目标词前后位置词与其子节点的依存句法关系作为SVM模型的特征,从而将一个句子转化成特征向量。例句1待消歧目标词“CANS”在窗口大小为[-1,1]范围的句子分析结果如表2所示。
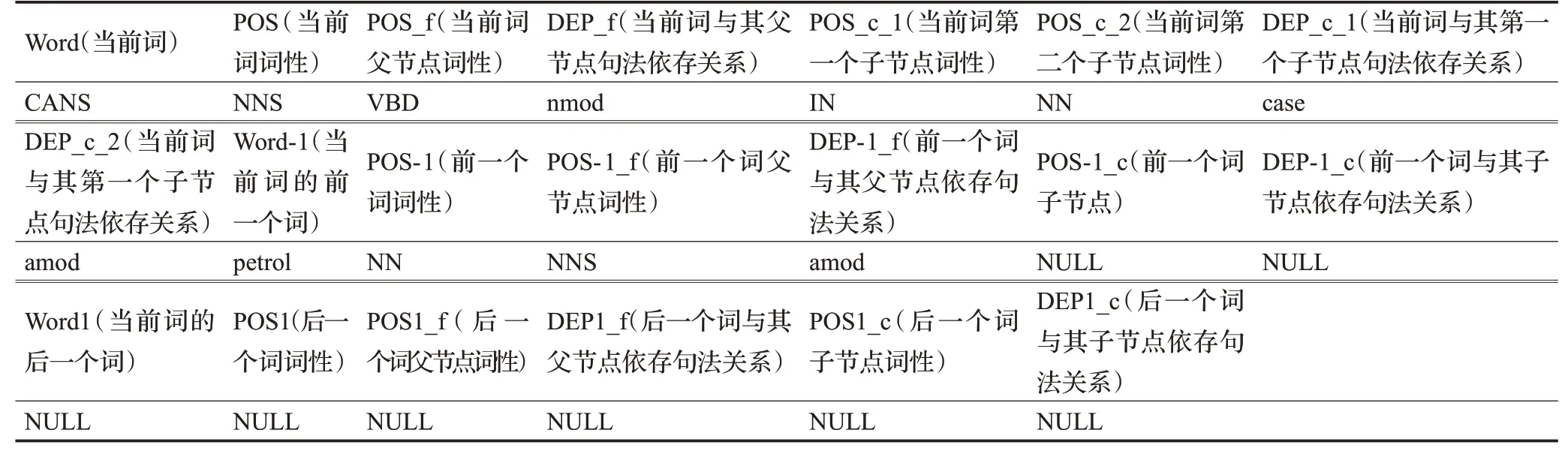
表2 例句分析结果Table 2 Analysis results of example
3.2 CRF模型的特征
CRF模型中比较重要的一步就是选取合适的特征构成特征模板。本文使用了开源工具包CRF++(V0.58)对语料进行框架消歧的训练和测试。CRF++工具包的特征模板格式为:%[row,col],其中row和col表示相对的行偏移和列偏移,当前标记值的行偏移和列偏移均为0。该格式不仅可以表示原子特征,还可以表示复合特征,格式为:%[row1,col1]/%[row2,col2]。
实验选取了词、词性、依存句法关系,及由SVM模型输出的分类标签作为特征进行实验。CRF模型实验中原子特征如表3所示,其中i=-3,-2,-1,1,2,3。

表3 CRF模型的原子特征Table 3 Atomic features of CRF model
利用原子特征进行组合,构建组合特征,能够更好地利用待消歧目标词的上下文信息,使得CRF模型能够获取上下文中更多隐性特征,进而能够提高框架消歧的准确率。具体的组合特征如表4所示。
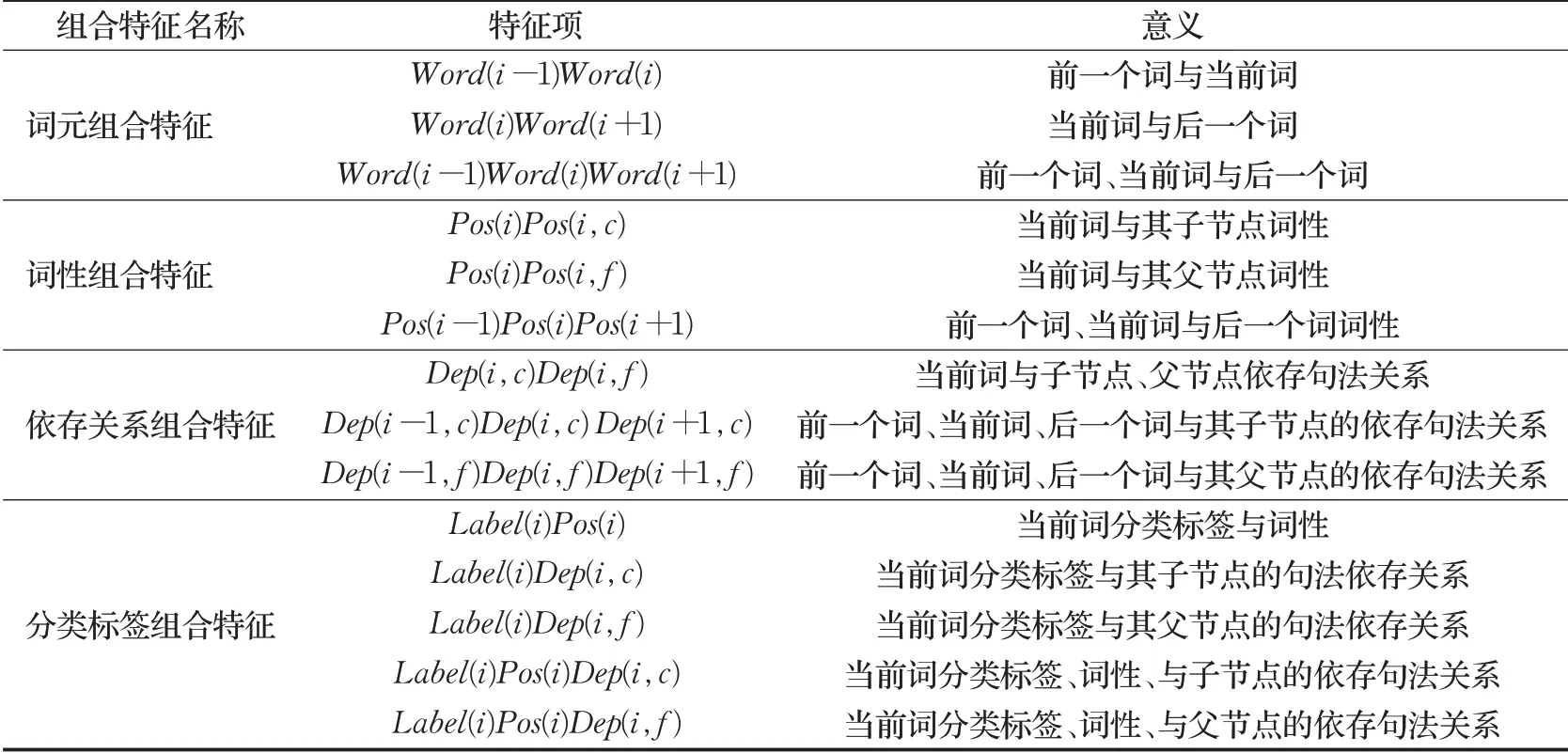
表4 CRF模型组合特征Table 4 Combination features of CRF model
综合以上原子特征及组合特征构建了CRF模型的特征模板,本文CRF模型的实验中特征模板如表5所示。

表5 特征模板设置Table 5 Feature template setting
4 实验与分析
本文在训练SVM模型时使用了sklearn工具包进行实验,并且使用了其中的SVC函数。根据文献[9]可知,在SVM对待消歧目标词进行分类时可以选择线性核函数和非线性核函数(高斯核函数、多项式核函数、sigmoid核函数)进行实验,其实验结果显示如果参数设置比较合理的话,多项式核的结果是最优的。但是考虑到多项式核函数由于其参数设置过多,在参数训练中增加了难度,也增加了时间复杂度,因此选择框架消歧结果与其相差不大的线性核函数。
在训练CRF模型时使用了开源工具包CRF++(V0.58),并且设置了6组特征模板进行实验,充分利用了SVM模型对语料进行粗分类以后得到的分类标签,使得标签进一步辅助CRF进行序列标注任务。
4.1 实验语料
针对FrameNet框架消歧任务,本文从FrameNet语料库中选择了18个具有代表性的能够激起多个框架的词元、共2 614条例句,及49个框架,语料分布情况如表6所示。对获取的FrameNet语料过滤垃圾串,例如:无效字符及URL链接等。并且将预处理后的语料分别转化为CRF++和sklearn包所要求的训练格式。
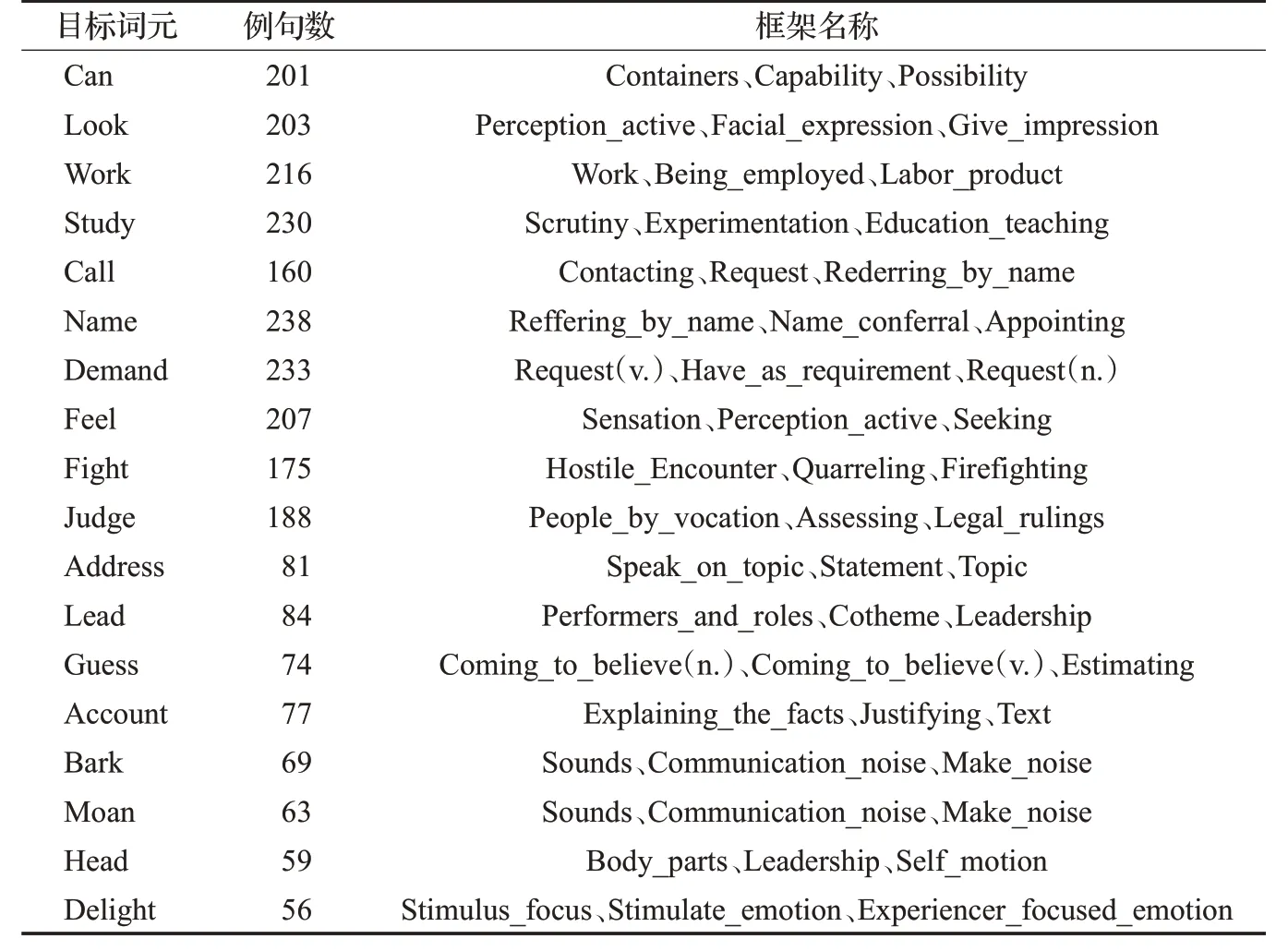
表6 语料分布情况Table 6 Distribution of corpus
4.2 模型评价指标
目前交叉验证在机器学习的研究中被广泛应用,尤其是在SVM模型的评测中经常出现该评价方法[13]。由于交叉验证可以在一定程度上减小过拟合并且能从有限的数据中获得更多有效的信息,因此本文采用交叉验证的方法对FrameNet框架消歧结果计算准确率,以评价实验结果。
给定一个目标词Targeti(i=1,2,…,n),n为选择的词元总数(本文选择个数n=10),在5-fold交叉验证实验CVj(j=1,2,…,5)下,目标词的分类准确率评价指标如下面的公式(8)所示:
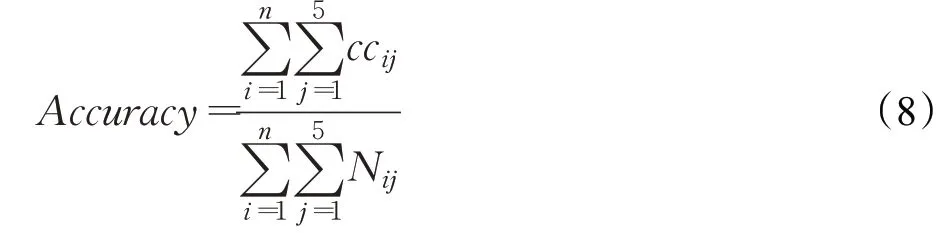
其中,Nij是目标词Targeti的例句均分为5份后,取第j份作为测试例句的数目,Cij是目标词Targeti的测试例句中框架标注正确的例句个数。
4.3 实验结果及分析
4.3.1 支持向量机模型(SVM)、条件随机场模型(CRF)与最大熵模型(ME)的实验结果对比及分析
为了测试传统的框架消歧模型在FrameNet语料上的性能,本文使用SVM模型[7]、ME模型[10]、CRF模型对18个待消歧目标词进行实验,并且计算在不同模型下的框架消歧准确率,结果如表7所示。
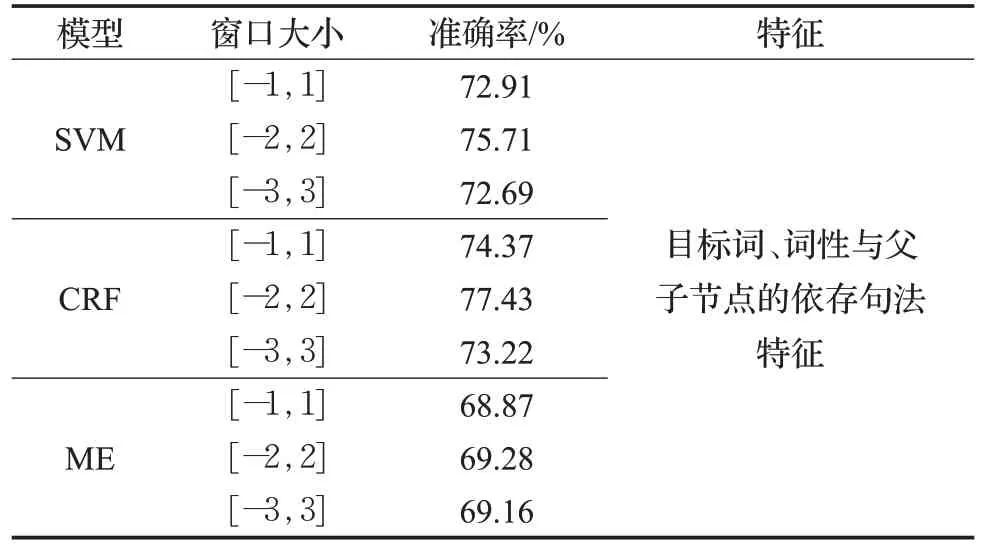
表7 单分类模型下的框架消歧结果对比Table 7 Comparison of frame disambiguation results under single classification model
由表7的结果可以看出,CRF模型在消歧结果上会比SVM模型准确率略高。CRF模型的框架消歧准确率最高可以达到77.43%,而SVM模型的最优框架消歧准确率为75.71%,与CRF模型相比低了1.72个百分点。因此可以看出在处理小样本数据时,CRF模型较SVM模型来说准确率略有提升,但是不明显,原因可能是上下文信息中含有噪声。ME模型与CRF模型和SVM模型相比较,最优框架消歧准确率较低,仅为69.28%,比CRF模型和SVM模型分别低了8.15和6.43个百分点,说明ME模型在处理小样本数据时性能明显较差。
4.3.2 CRF模型的实验结果及分析
表8列出了使用表5中设计的6个特征模板并且进行5-fold交叉验证得到的CRF模型的实验结果。由表8中的实验结果可以得出以下结论:
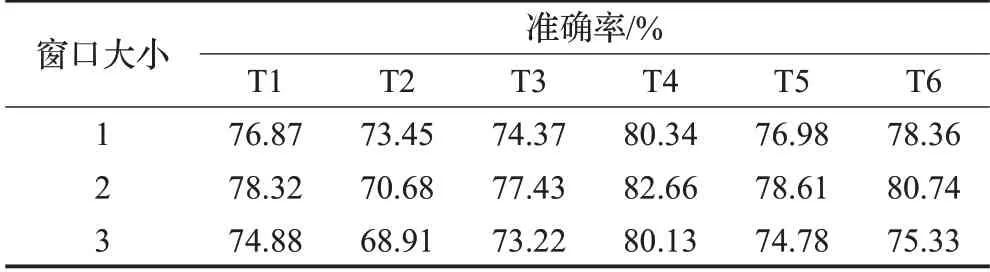
表8 CRF特征模板实验结果Table 8 Results of CRF feature template
(1)对比T1、T2模板可以看出,引入父节点的依存句法关系后,准确率明显下降。这是因为当前词的父节点并不能对当前词产生关键的语义影响,反而父节点特征的加入会使得系统噪声增加,影响了框架消歧的准确率。
(2)在加入分类标签的原子特征和组合特征(T4、T5)之后,相较于没有增加分类标签的特征模板,框架消歧的准确率为82.66%、78.61%,较T1、T2模板准确率78.32%、70.68%有所提升。这是因为对于框架消歧任务来说,每个待消歧的目标词至少可以激起两个以上的框架,要准确识别难度会比较大。经过SVM分类后得到的分类标签本身就携带了大量目标词的分类信息,CRF模型可以充分利用观察序列中的全部特征,因此可以在原本相互独立的、没有关联的分类标签序列和语义特征序列之间建立信息交互,使分类标签与文本特征之间的相关性在一定程度上丰富了特征模板,进而可以提升框架消歧准确率。因此该实验验证了第一层SVM模型得到的分类标签特征对于本文提出的基于SVM和CRF的双层模型来说可以在一定程度上提升框架消歧的准确率。
4.3.3 双层模型的实验结果及分析
为了验证本文提出的基于SVM和CRF双层模型的框架消歧方法比其他双层模型的框架消歧准确率高,本文使用4.3.1小节提到的传统的框架消歧模型进行组合,构成三个双层模型与本文使用的基于SVM和CRF双层模型的框架消歧方法进行对比实验,分别是ME+SVM、ME+CRF、CRF+CRF。本文基于SVM和CRF的双层模型的框架消歧结果与其他双层模型的框架消歧结果对比如表9所示。

表9 双层模型框架消歧实验结果对比Table 9 Comparison of disambiguation results of two-stage model
由表9的结果可以看出,ME+CRF模型的框架消歧准确率最低,对比ME+SVM模型来说准确率低了1.32个百分点,但是差别不明显。原因在于在训练数据中除目标词以外的词会被标记为“O”,所以经过特征选择之后这种标记被CRF模型学习到,就会在测试结果当中出现,导致一些本来应该标注为某一框架的目标词被错误地标记为“O”,进而影响准确率。
CRF+CRF模型的准确率与ME+SVM、ME+CRF模型的准确率相比较会有所提升,分别增加了3.32和4.64个百分点。原因在于CRF模型相较于ME模型来说,CRF模型可以避免严格的独立性假设和数据归纳偏置问题,还能够建立起标签序列与文本特征序列之间的关联,提高了框架消歧的准确率。
表9中其他的复合模型与本文的基于SVM和CRF的双层模型的框架消歧准确率进行比较,本文的双层模型准确率较高。原因在于其他双层模型仅仅是两次序列标注的简单叠加,并没有将两层模型联系起来。而本文提出的基于SVM和CRF双层模型的框架消歧方法是将SVM分类之后产生的分类标签作为特征输入到CRF模型中,将分类标签序列与文本特征序列融合,建立起不同标记序列间的信息交互,解决了特征之间无关联的问题,丰富了特征模板。
由于语料规模对框架消歧任务有一定影响,而且实验中标记的语料数量较多,因此针对以上提到的四个复合模型在实验语料逐步扩大的情况下进行了对比实验,实验结果如图4所示。从图4可以看出,随着语料规模的逐渐增加,四个复合模型的框架消歧准确率都会不断提升,但是当语料中的例句数达到700个例句之后,框架消歧结果逐渐趋于稳定。图4也侧面证明了该研究中使用的框架消歧语料例句数可以满足实验的要求。
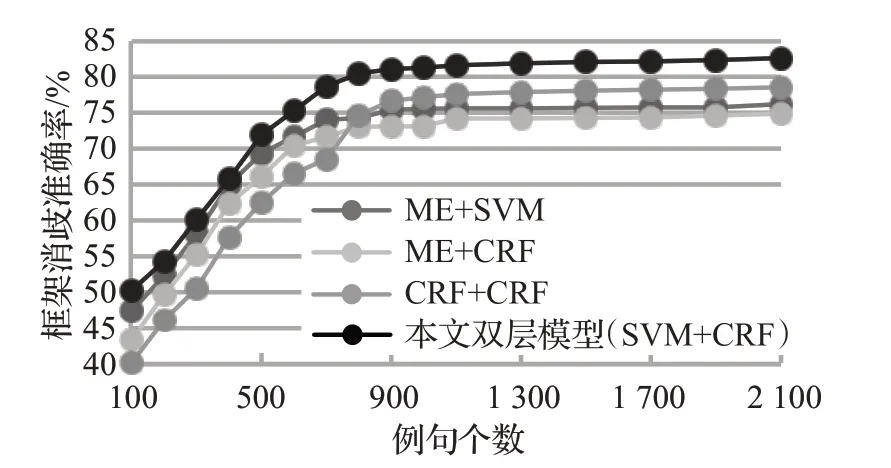
图4 不同语料规模下模型最优框架消歧准确率对比Fig.4 Com of optimal frame disambiguation accuracy of model under different corpus sizes
综合来看,利用SVM模型得到的分类标签作为特征与原有的文本语义特征结合可以使得本文提出的双层模型的框架消歧准确率达到82.66%,本文提出的方法在FrameNet框架消歧中取得了较好的效果。
5 结束语
本文在传统的利用单个模型处理框架消歧任务的基础上,选择在分类任务中表现较好的SVM模型及在序列标注任务中主流的CRF模型作为双层模型的结构,利用分治的思想将框架消歧任务分解为对待消歧的目标词分类及序列标注任务。结果也证明了本文提出的基于SVM和CRF的双层模型可以在一定程度上将两层模型的优势互补。一方面CRF模型能很好地利用目标词之间的隐性联系,并且在特征选择上充分利用了分类标签与文本特征之间的相关性,使得特征模板得以丰富;另一方面,SVM模型适合处理有限样本的分类问题,并且可以获得全局最优值,因此提升了FrameNet语料框架消歧的准确率。通过实验结果也证明了本文方法在处理FrameNet框架消歧任务上具有一定优势。
同时,FrameNet语料中还存在着丰富的文本信息,本文虽然利用了分类标签特征以提高框架消歧的准确率,但是特征的选择还是很局限。今后可以将框架之间的关系和句子所在的段落或者篇章这些丰富的上下文信息引入到框架消歧的研究中,以进一步提升框架消歧的准确率。
