基于改进SSD安全头盔反光衣检测算法
2021-09-24韩泽佳肖秦琨张立旗
韩泽佳,肖秦琨,张立旗
(西安工业大学 兵器科学与技术学院,西安710016)
众所周知,监控系统对工地的安全至关重要,在过去的十几年里,一部分人工智能技术,如计算机视觉和机器学习,已经迅速应用到工地的智能监控当中[1]。实现对工人安全头盔反光衣实时检测是关系到工人安全的一项重要任务,同时有利于实现无人值守降低人工成本。因此,能够实现自动检测工人是否穿戴安全头盔反光衣具有重要意义。
自2014年Grishick 等提出的R-CNN 算法后,深度学习算法开始在目标检测领域占据了主导地位[2]。目前基于深度学习模型的目标检测算法主要分为两类:一类是两阶段算法。这类算法的典型代表是Fast-R-CNN[3],Faster-R-CNN[4]等基于区域提议系列。与传统的检测算法相比,这种算法大大提高了检测精度,但使用分段检测算法导致检测速度变慢,不能满足实时性要求,是这种算法的最大缺陷;另一类是一阶段检测算法,通常以YOLO[5]和SSD[6]算法为代表。这种算法不需要生成候选区域,而是直接生成物体的类别概率和位置坐标,这种算法能满足实时检测的要求但是精度不如两阶段算法。
文献[7]通过在YOLOv3 中引入通道注意力机制和改进损失函数的方法对YOLOv3 进行改进,使检测更加精准有效;文献[8]在SSD 算法的基础上通过使用表征能力更强的残差网络作为特征提取网络,然后再通过特征融合的方式提高目标检测精度;文献[9]通过调整原SSD 检测框架的参数并添加自注意力模块来提高对安全帽佩戴的检测。而上述方法没有针对检测安全帽和反光衣提出合理的改进方案,因此,本文主要研究了在SSD 算法的基础上提出改进,实现对安全帽反光衣的实时高效检测。
本文针对原SSD 算法检测精度不高问题做出以下改进:①改进SSD 模型的特征提取网络,原始的VGG16 模型被部分ResNet50[10]取代,克服了VGG 网络深化导致的网络退化问题,提高网络检测精度。②同时针对网络模型高层卷积核几何变换能力低的问题,在最高层卷积层Conv_11 中添加可形变卷积模块,使高层卷积核的采样点位置根据图像内容自适应变化,以适应形状、大小等不同目标的几何变形用来提高检测精度。
1 SSD 基本网络结构
SSD 于2016年问世,是单阶段检测算法中比较经典的算法,因其不错的检测结果和能达到实时检测的速度广泛应用于工程实践中,SSD 整体结构如图1所示。
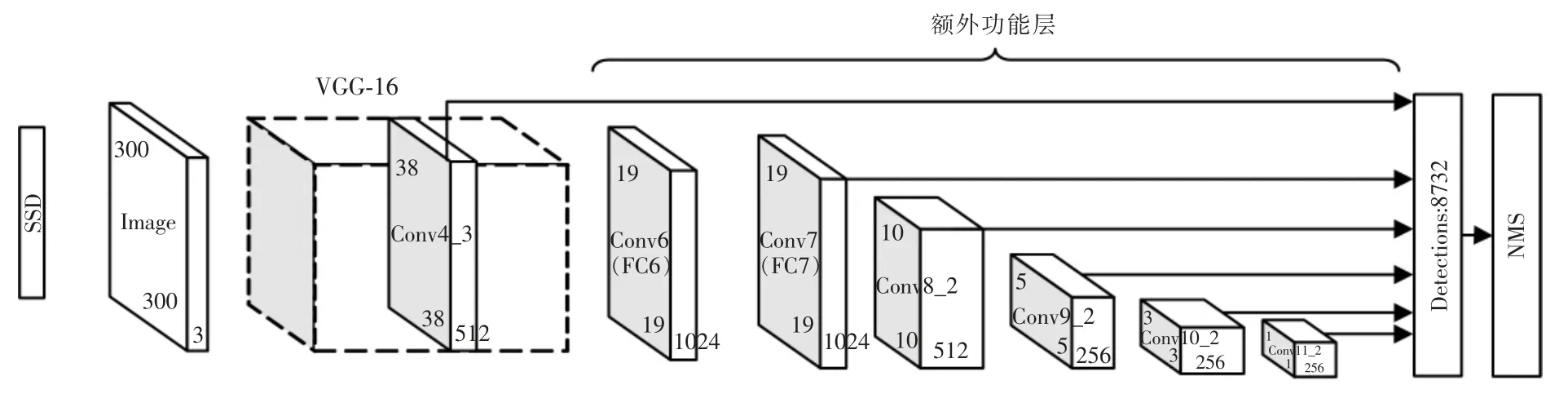
图1 SSD 算法原理图Fig.1 SSD algorithm schematic diagram
从图1可知,SSD 网络结构和算法流程大致可以分为两个部分:基础网络VGG-16 和额外功能层,其中对原始VGG-16 做出修改,保留前5 层卷积层,同时将全连接层FC6 替换为3×3×1024 的卷积,即Conv6,全连接层FC7 替换为1×1×1024 的卷积,即Conv7,并在Conv7 后面添加了4 个卷积层Conv8~Conv11 部分均为两个尺寸,分别为3×3 和1×1 的卷积层构成的卷积模块。
2 改进SSD 结构
2.1 改进特征提取网络
通过实验发现,深层网络存在退化问题,随着VGG16 网络深度的增加,网络精度出现饱和度下降的问题,之所以选择ResNet50 是因为当feature map 的大小减半时,其数量会在同一时间能翻倍,从而保持了网络的复杂性。这样就可以解决网络深度增加时的精度下降问题。为了提高特征学习效果和检测精度,采用ResNet50 作为特征提取网络,但并不是完整的使用了ResNet50 层结构,在这里使用的是Conv1~Conv4 所对应的一系列残差结构,将后面的残差结构舍弃掉,同时使用残差结构的Conv4_1作为第一个feature map 进行输出。残差块结构如图2所示。
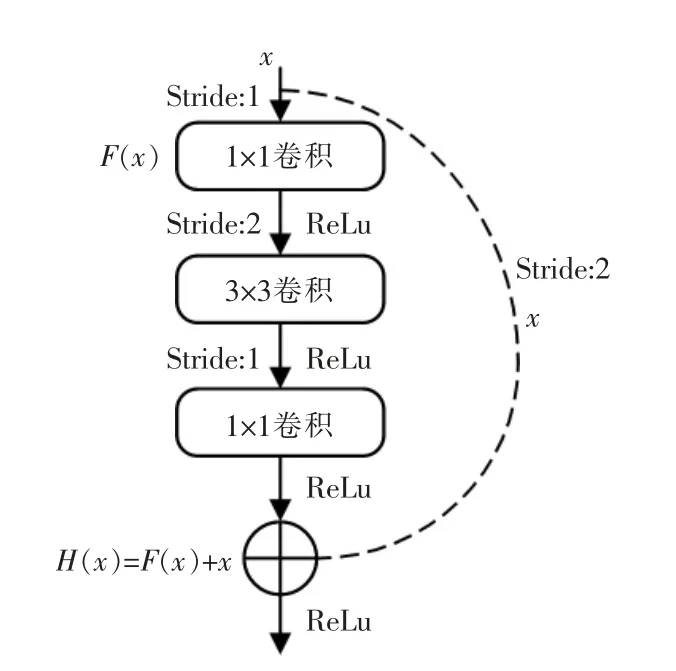
图2 残差结构Fig.2 Residual structure
下面表达式中,其中σ 代表非线性函数ReLu[11]:

然后通过一个恒等式和第2 个ReLu 函数,得到输出y 为
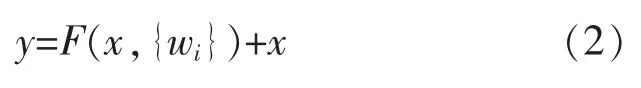
对于一个或者几个堆成的结构,当输入为x 时,它的学习的特征是H(x),wi为权值系数,为实现残差结构的恒等映射,可以通过H(x)-x 趋近于0,使H(x)逼近于x。在这里对残差结构进行修改,修改后的残差结构如图3所示,将Conv_4 的Block1 中的3×3 的卷积核和捷径上的1×1 的卷积核Stride=2 修改为Stride=1。
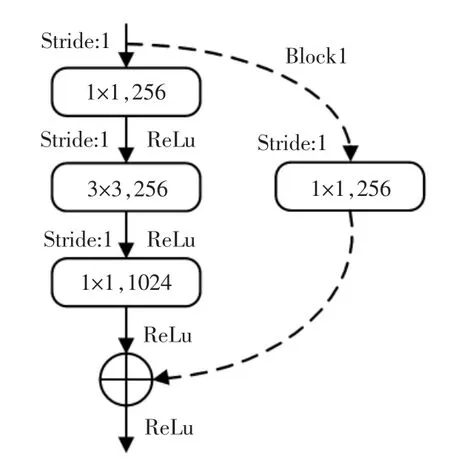
图3 修改后的残差结构Fig.3 Modified residual structure
修改后带来的变化是,当特征矩阵经过Conv_3所对应的一系列残差结构之后输出的特征矩阵是38×38×512,通过修改后的步距特征矩阵输出是38×38×1024,修改后的残差层所对应的卷积核大小个数和输出特征矩阵的大小如表1所示,调整后的步距只对高和宽产生影响,不会对深度产生影响。
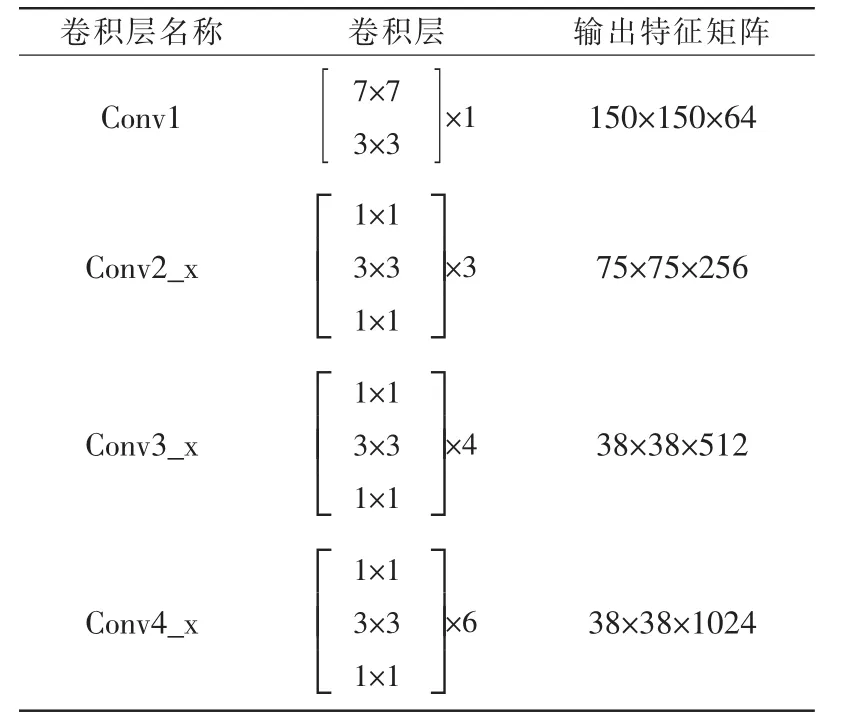
表1 修改后的残差卷积层输出结果Tab.1 Output results of modified residual convolution layer
2.2 引入可形变卷积
图像的高层特征语义信息比较丰富,然而对目标位置的预测比较粗略,为了提升SSD 算法对目标位置的预测来提高检测精度,引入可形变卷积[12],可形变卷积网络本质上是对传统平方卷积的一种改进,传统的平方卷积使用规则的格点采样,使得网络难以适应几何形变。卷积的采样方式如图4所示,其中图4(a)为正常卷积采样的方式,图4(b),图4(c)和图4(d)为可形变卷积在正常的采样坐标上加了一个位置偏移量,其中图4(c)和图4(d)展示了可形变卷积可以做尺度变换和旋转变换。
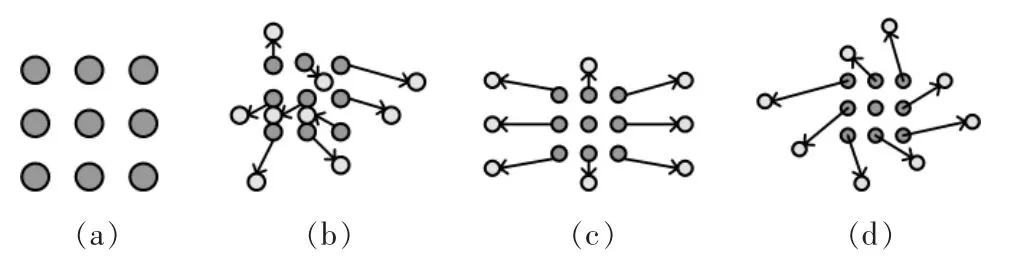
图4 卷积采样方式Fig.4 Convolution sampling method
这个模块很轻,它为偏移学习增加了少量的参数和计算同时很容易利用神经网络中的反向传播进行端到端的训练提高检测精度,从公式的角度来看,传统的卷积定义为
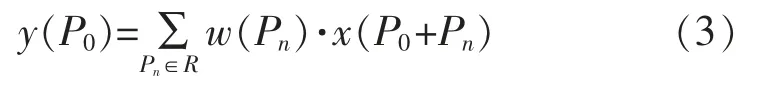
式中:Pn代表卷积网格中的任意一个像素;P0代表输出特征图y 上的一个位置;w 代表卷积核的权重;R 代表一个膨胀系数为1 的标准3×3 卷积核。
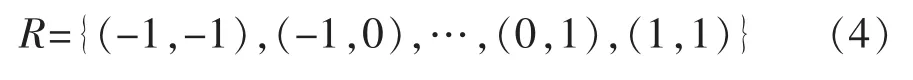
可形变卷积定义为
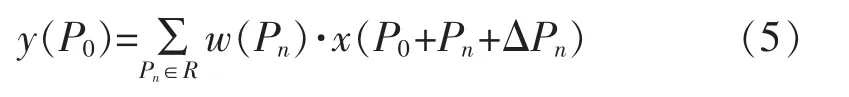
式中:ΔPn代表部分网络结构中的一些像素的偏移,由于偏移量ΔPn通常不是整数而是小数,非整数的坐标是无法在图像这种离散数据上使用,所以使用了双线性插值法[13]对ΔPn进行取整操作,公式为
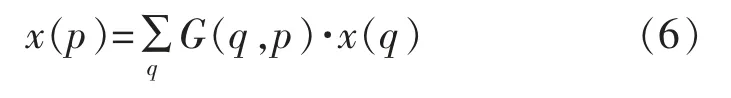
式中:p 代表任意像素的位置;p 代表公式(5)中的(P0+Pn+ΔPn);q 代表特征图x 上所有整数空间的位置;G(.,.)代表双线性插值内核,它可以分成两个一维的内核:
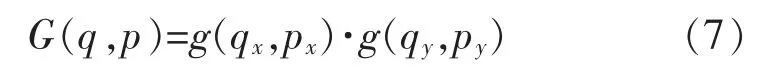
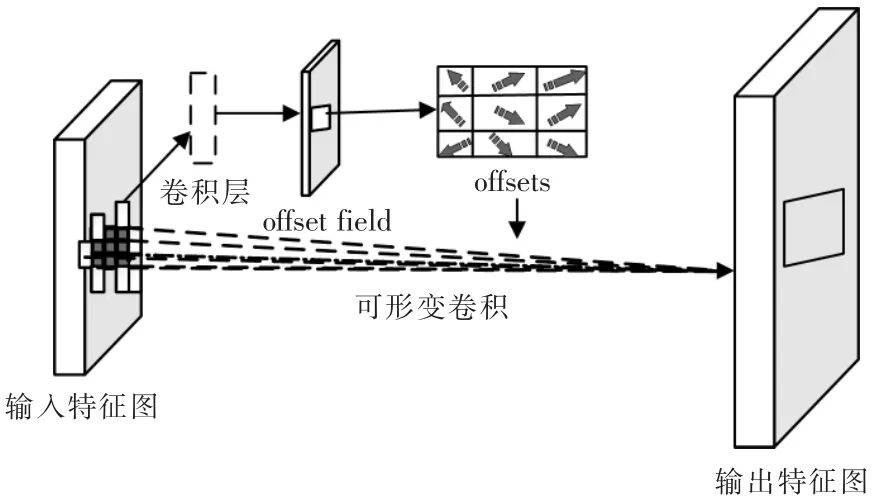
图5 可形变卷积层的实现过程Fig.5 Realization process of deformable convolution layer
引入可形变卷积后,原来的卷积神经网络分为了两路且共享一个输出特征图,其中上面的一路通过一个额外的卷积层来学习偏移offset,得到一个H×W×2N 的输出,其中N 代表像素的个数,2N 代表x 与y 两个不同方向的偏移。下面的一路的输入特征图和上面的偏移共同作为可形变卷积层的输入,计算过程和常规卷积一样。
改进后的SSD 模型在最高层卷积模块Conv11_2中添加可形变卷积模块,然后通过ReLu 函数输出表示为Conv11_2 的特征图。图5中可形变卷积模块层偏移量和可形变卷积层的具体参数如表2所示。

表2 可形变卷积层参数Tab.2 Parameters of deformable convolutional layer
2.3 改进后的整体网络结构
改进后的整体网络结构如图6所示,使用ResNet50 的Conv4_1 作为第一个特征图输出,第2~5 输出特征层输出依次由原来SSD 算法进行输出,最后一个输出特征层经过可形变卷积后进行输出,从改进后的SSD算法中选取38×38,19×19,10×10,5×5,3×3,1×1 总共6 种尺寸先验框进行输出,总共生成8732 个先验框。
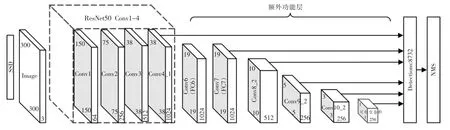
图6 改进后的整体网络结构Fig.6 Overall network structure after improvement
对于每个先验框,SSD 网络计算两个关键组成部分,其中包括置信度损失和位置损失,其中置信度损失使用分类交叉熵损失函数计算先验框中存在对象的置信度,位置损失用于计算网络预测的边界框距离真实框的距离有多远。整体的多任务损失函数定义如下:
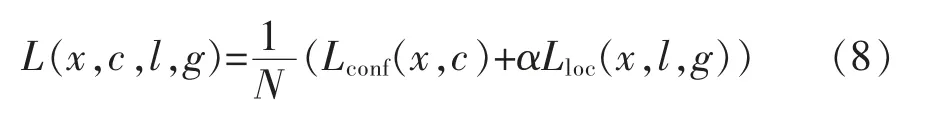
式中:Lconf代表置信度损失;Lloc代表位置损失;N 代表匹配到的正样本的个数;c 代表类别;l 代表预测框;g 代表真实框;α 是一个平衡系数。
3 实验结果与分析
3.1 实验数据集
通过现场拍摄获取以及网络爬虫的方式获取关于安全头盔和反光衣的图片6232 张,经过SSD原本算法中的水平翻转等数据增强方法最终生成数据集8166 张,其中训练集、验证集和测试集按照7∶2∶1 的比例进行分配,其中训练集和验证集参与网络的训练,本数据集要制作成符合VOC 格式,每张图片使用LableImage 软件进行标注生成对应的XML 文件,样本标签总共分为4 类helmet(佩戴安全头盔)、without helmet (没有佩戴安全头盔)、suit(穿反光衣)、without suit(没有穿反光衣),标注结果如图7所示。

图7 标注结果Fig.7 Labeled results
3.2 实验平台
本文的硬件服务器配置为一块Nvidia GeForce RTX 2080Ti 显卡,处理器为Intel(R)Xeon(R)Silver4110 CPU,实验操作系统为Ubantu18.04LTS。
3.3 模型训练
本文改进的模型首先通过加载原SSD 算法在COCO[14]数据集上训练得到的预训练权重,然后通过神经网络的迁移学习,加载预训练权重对收集的训练集和验证集进行训练,训练中的超参数设置如表3所示,最后得出训练的结果,进行分析。
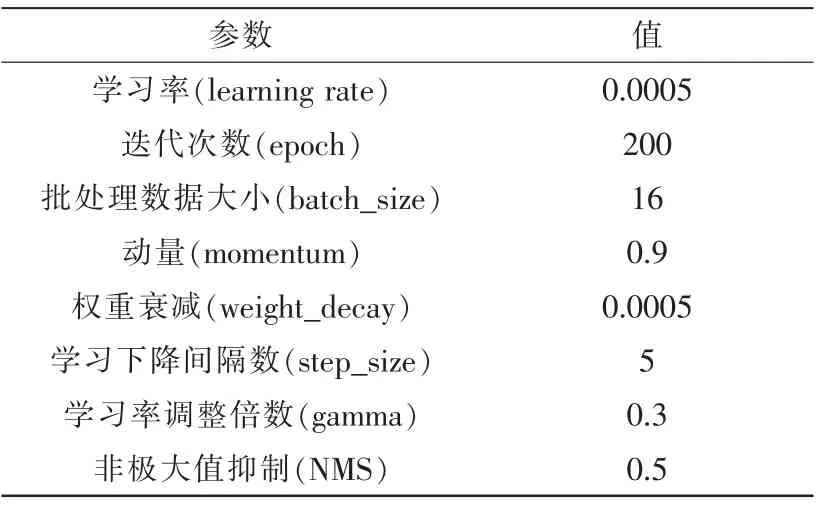
表3 训练超参数设置Tab.3 Training super parameter Settings
3.4 训练结果分析
本文算法使用8 进程数,使用SGD 优化器进行优化,初始学习率设为0.0005,每隔5 步降低一次学习率,由图8可以看出在经过200 轮的迭代训练后,训练结果稳定在一个较高的平均精度值,能达到83.7%。
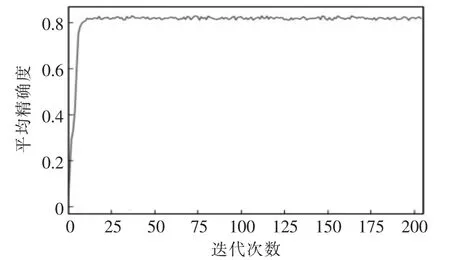
图8 训练曲线Fig.8 Training curve
3.5 实验结果对比
本文算法通过与原SSD 算法进行对比,测试图片对比结果如图9所示,通过测试结果图对比发现,原SSD 检测算法在灯光昏暗和不同角度下存在漏检现象的发生,本文算法的表现要优于原SSD 检测算法。

图9 SSD 算法改进前后对比图Fig.9 Comparison of SSD algorithm before and after improvement
为研究改进SSD 网络结构对检测准确度产生的影响,将原SSD 算法和改进的SSD 算法针对4 种标签的检测准确率进行对比,对比结果如表4所示,本文算法针对每类标签的检测精度比原SSD 算法都有所提升。
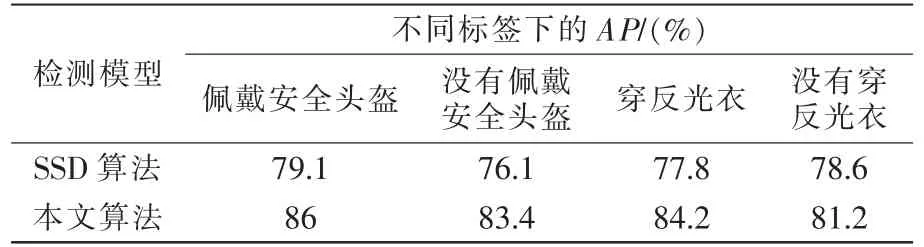
表4 SSD 和本文算法标签检测准确率对比Tab.4 Comparison of label detection accuracy between SSD and proposed algorithm
为了验证本文算法的有效性,将与已有的目标检测模型Faster-Rcnn,Faster+ResNet50,SSD+MobileNetv2,YOLOv3 算法进行测试对比,整个实验过程使用相同的硬件配置,统一使用本文所制作的数据集进行训练和测试,训练和测试结果如表5所示,可以看出在检测mAP 上Faster+ResNet50 的表现是最好的,但是它的检测速度只有11 帧/s,无法实现现场的实时检测,同时SSD 和YOLOv3 检测速度都很快,但是它们在检测mAP 上都不如本文算法。
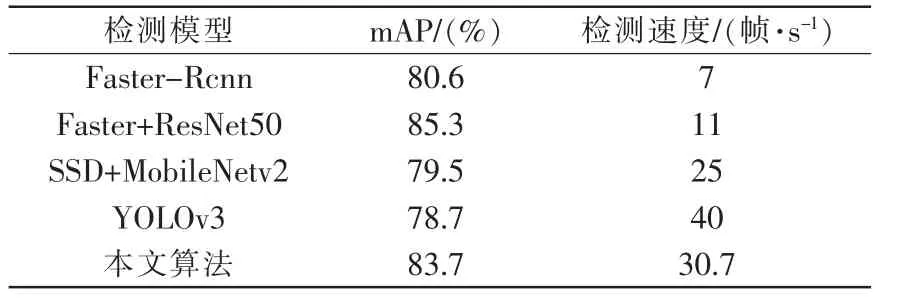
表5 测试结果对比Tab.5 Comparison of test results
4 结语
本文提出一种改进的SSD 检测安全头盔和反光衣算法,通过替换原SSD 算法的特征提取网络和使用可形变卷积的方法来提高检测精度,实验结果表明,本文算法能达到的检测mAP 有83.7%,比原SSD 算法提高了4.8%,同时检测速度为30.7 帧/s,在保证高精度检测的同时还能满足实时检测的要求,对实现安全头盔和反光衣检测具有良好的发展前景。
