电网通信管理系统中电源数据信息处理方法研究
2021-09-23陈思羽张雁王志强
陈思羽, 张雁, 王志强
(国网陕西省电力公司信息通信公司,陕西 西安 710048)
0 引 言
随着通信技术水平的不断提高,以国家电网通信信息管理系统(TMS)为基础的通信信息化平台的功能也在不断增加,但是在电源管理方面依旧是空白,只能进行基本的台账信息录入,无法实现电源数据的动态管理和数据交互,为此提出一种电源数据的分类方法,为实现电源数据的信息化管理提供支持。
在现有的研究中,文献[1]提出了一种不均衡数据分类算法,虽然能够提高对少数类样本的分类准确率,但是并不适用于电源数据处理。文献[2]提出了一种基于自适应随机森林的数据流分类算法,虽然能够提高平衡数据流分类的效率,但是无法推广到非平衡数据流中。
本文基于以上内容,根据电网通信系统中电源数据的特性和通信管理系统,对电网电源信息数据管理系统进行设计,提出一种改进朴素贝叶斯分类算法,对电源信息数据处理提供支持。
1 电网通信数据信息管理系统
在电网通信管理系统中,通信电源的数据信息管理处于探索期,还没有一个规范的标准,通信电源的信息也只有静态台账数据,无法对现有的业务提供支持[3]。为此结合计算机技术对通信电源数据管理系统进行设计,如图1所示。
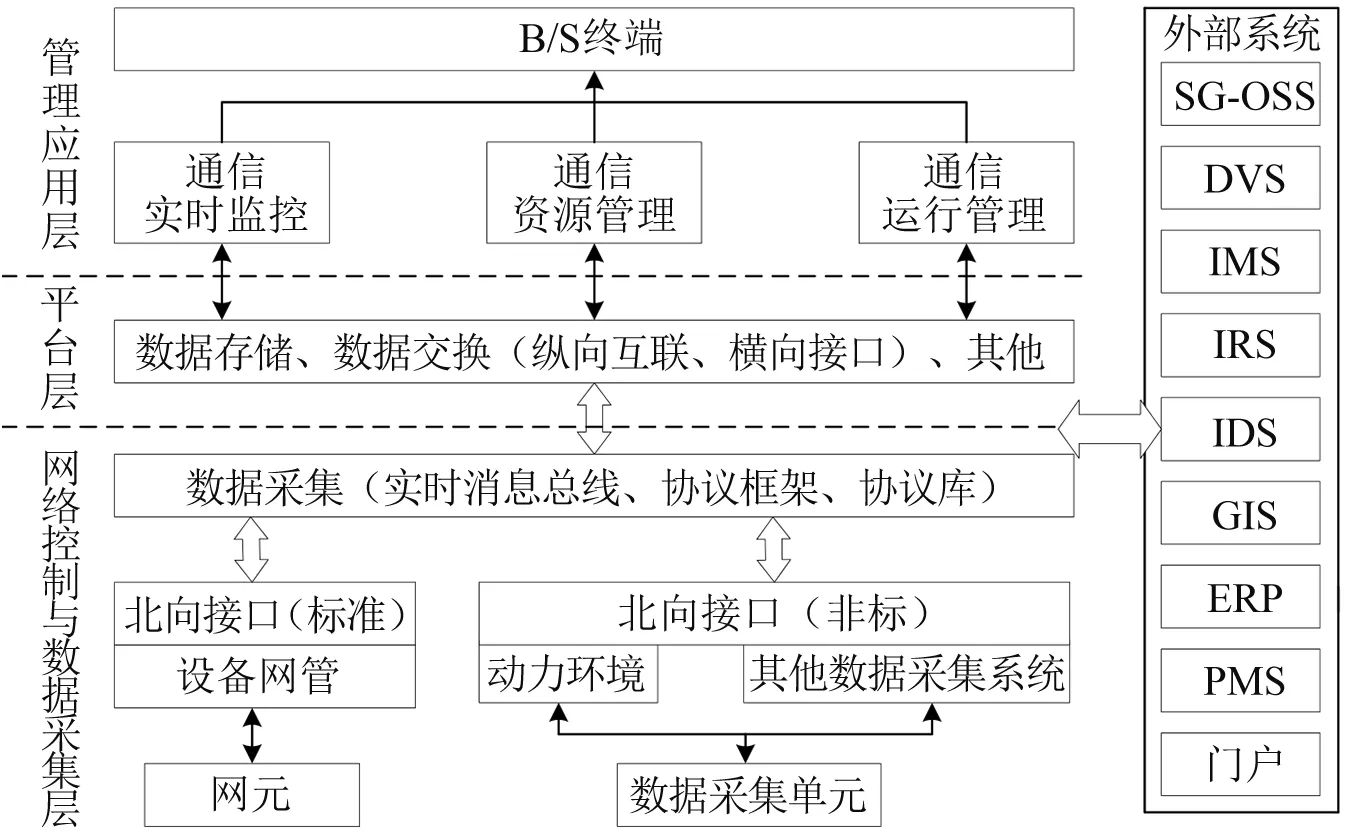
图1 通信电源管理系统
为了更好地表现系统结构,将系统分为3个层次,分别是应用层、平台层和采集层[4]。
采集层主要负责数据的采集,数据的采集主要依靠数据采集单元来实现,数据采集完成后,通过数据接口向上层传递[5]。除此之外,还有动力环境为数据采集提供动力支持。采集层处理数据采集设备单元之外,还有各种网元和设备网管,管理数据传输的设备。实现数据传输的智能化管理。需要指出的是,由于使用的采集设备来自不同的厂家,导致向上层传输的接口种类过多,同时数据传输的种类也会很多[6]。
平台层主要负责数据的存储,将采集到的各种类型的数据进行处理以及存储,云存储随着不断发展已经被广泛地应用到各个领域[7]。云存储最大的优势在于可以使用少数的硬件存储设备来获得几十倍甚至几百倍的云存储空间。本文的数据存储方式也使用云存储,既保证了数据的安全性,又减少了系统成本[8]。
数据应用层主要是对数据的应用,主要包括数据的实时监控,通信资源分配以及通信系统的运行管理,数据最终会传输到应用终端上,根据数据的信息来判断系统的运行情况。
系统的数据采集单元部署在电网通信网络中的通信电源附近,设定采集频率进行固定采集,同时为了防止采集数据缺失和缺少,还需要进行不固定补采。
系统的对外接口主要负责与外部系统之间的信息交互,外部系统主要包括本级电网公司的SG-OSS系统和GIS系统等。
系统的接口决定着数据信息的交互方式和传输方式,系统可以通过对接口协议的统一化管理来实现数据交互的标准化。
2 关键技术
2.1 基于C4.5决策树的朴素贝叶斯分类算法
C4.5决策树分类算法过程如下。
(1) 假设通信管理系统中数据集S内有Si个分类模块,i={1,2,…,n},设置m个属性标签,定义Ti为每个属性标签集合,i={1,2,…,n}。假设Si是Ti类中的数据样本,对于一个固定样本分类所需要的期望值为:
(1)
(2) 属性A对数据进行划分的子集信息量为:
(2)
(3) 求信息增益,计算方法为原来的信息需求减去现在的信息需求:
Gain(A)=Info(S)-E(A)
(3)
(4) 属性A的信息增益率:
(4)
(5)
C4.5算法的主要过程是对生成的决策树进行剪枝操作,不断地完善决策树模型,对后续的数据分类提供支持。
朴素贝叶斯分类算法的核心思想是计算样本数据中属于每个类别的概率,然后根据概率的大小来确定样本数据的最终分类,即概率最大的类别为最终分类,主要过程如下。
(1) 提取数据样本的特征向量,用集合x表示,x={x1,x2,…,xn},其中每一个xi都代表一个数据特征。
(2) 经过C4.5决策树的特征分类后有类别y={y1,y2,…,yn}。
(3) 计算样本数据属于每种类别的概率:P(y1|x),P(y2|x),…,P(yn|x)。
(4) 根据概率大小判断数据的最终类别:P(yk|x)=max{P(y1|x),…,P(yn|x)},就确认为数据类别。
基于以上描述,本研究提出的新型分类算法步骤为:
(1) 提取样本数据的特征向量。
(2) 采用C4.5决策树算法进行分类。
(3) 根据决策树模型计算权重。
(4) 根据权重采用贝叶斯分类器分类。
(5) 得到分类结果。
朴素贝叶斯分类算法认为数据属性之间没有任何关联,是相互独立的,但是数据的属性或多或少都会有关联,通过C4.5决策树的训练模型来计算属性权重能够让分类结果更准确,最终的朴素贝叶斯分类的计算公式为:
P(yk|x)=max{P(y1|x)·w1,…,P(yn|x)·wn}
(6)
w1+w2+…+wn=1
(7)
权重的具体数值则需要根据数据的具体属性分类个数决策树模型来确定,可以通过反推来确定权重数值,即用已知属性的数据代入模型来确定权重。
2.2 数据采集方案设计
上述系统中数据通过纵向横向接口来进行数据的传递,但是由于下层设备的厂家过多,导致接口种类也过多,这样的后果就是传输的数据的类型过多,不利于后续的信息处理。因此需要对上述的数据采集方案进行改造。
本文采用的数据采集方案用到的硬件配置为Xilinx XC7A200T型号的逻辑处理芯片、FPGA驱动和ADC HMCAD1520芯片。
工作原理为:输入采集到信息的模拟信号,Xilinx XC7A200T芯片可以将模拟信号转化成数字信号并传送到FPGA驱动上,FPGA会对数据进行进一步的处理,这样采集到的数据信息就会有一个统一的标准,选用Xilinx XC7A200T芯片的原因在于其内部有寄存器,可以用于配置功能参数,同时为了保证接口的统一性。本文在FPGA的设计过程中添加了SPI接口的自动配置模块,主要是实现HMCAD1520芯片的初始化参数自动配置,配置根据采集需求来定。
为了提高数据传输的容量以及速度,在FPGA中设计一个高速接口模块,并利用数据时钟来实现同步校准,方案的实施框架如图2所示。
该模块是以Xilinx内部自带的DDR和信号延时调节IP原语为基础设计的,同步模块的作用是校准时钟和数据的建立时间以及保持时间,这样可以保证数据采集的准确有效,完成数据的高质量、高速度和高稳定性采集,为后续的数据处理提供帮助。
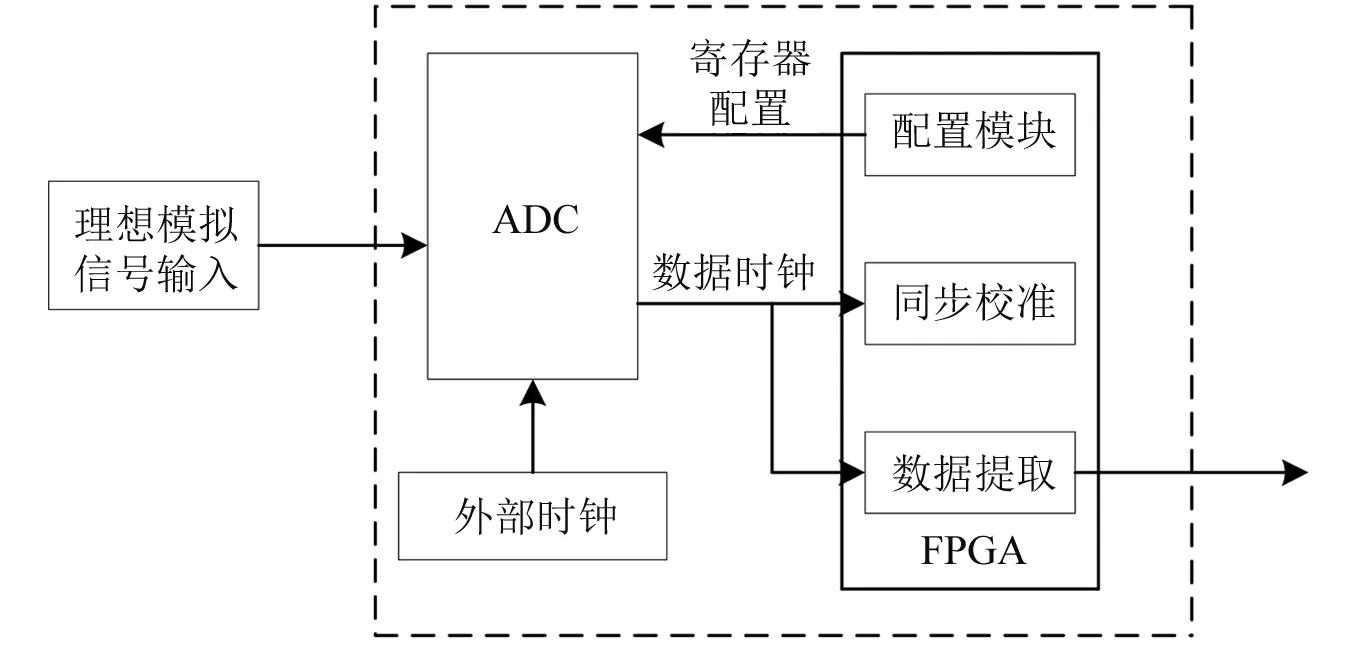
图2 方案实施框架
3 试验仿真与分析
3.1 改进朴素贝叶斯算法验证
采用MATLAB仿真软件对上述的改进朴素贝叶斯分类算法进行验证和性能分析,其中计算机配置的硬件为Windows10操作系统,CPU为Inter Core i5-7500H@3.40 GHz四核,运行内存16G。为了验证上述算法的有效性,将系统在某电网公司试运行一年,选取系统运行一年中四个月的数据作为数据集样本,数据集的基本特征如表1所示。

表1 数据集特征
采用上述数据,对本文提出的算法、朴素贝叶斯算法(算法1)和C4.5决策树算法(算法2)进行对比验证,验证的指标基于混淆矩阵原理的精准率和召回率,将上述四个数据集样本按4 ∶1划分为训练集和测试集,并训练模型。
精准率的计算公式为:
precision=TP/(TP+FP)
(8)
召回率的计算公式为:
recall=TP/(TP+FN)
(9)
对数据样本进行特征提取,然后采用训练集对三种算法进行训练,分别采用三种算法对测试集数据进行分类,通过式(8)、式(9)计算得到三种算法的精准率和召回率,如表2所示。
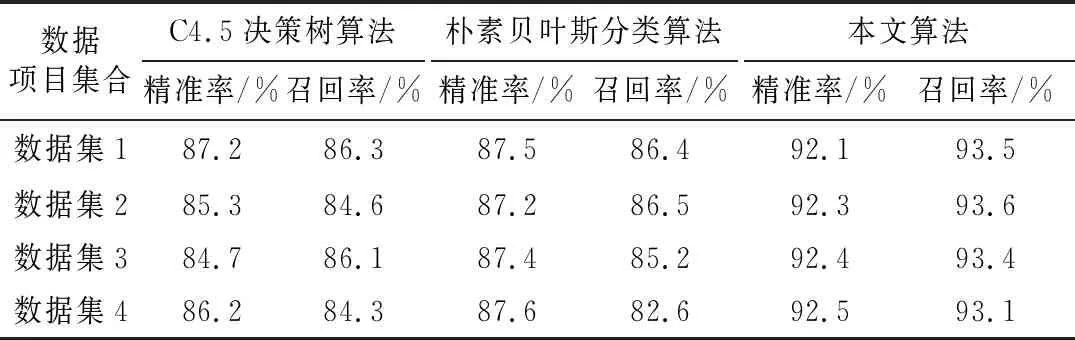
表2 三种算法的精准率和召回率对比
从表2可以看出,本文算法的精准率和召回率都高于算法1和算法2。为了更直观地表现三种算法的性能,将上述数据中的精准率和样本数量的关系用曲线图3表示。
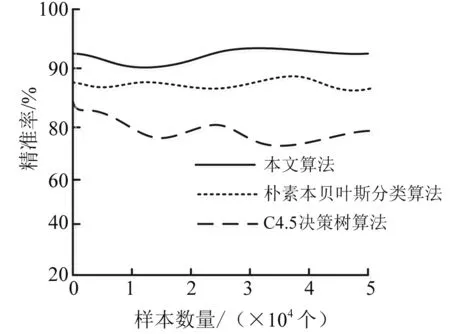
图3 三种算法的精准率对比
从图3可以看出,本文提出的算法的精准率在数据样本较小时,精准率存在波动现象,波动幅度不明显,但是随着样本数据的增加,最终稳定在90%以上,而另外两种算法的精准率不仅波动较大,并且低于本文提出的算法5%左右。由此可见,本文算法的性能优于其他两种算法。
3.2 改进数据采集方案验证
在某电网公司的通信网络中将上述数据采集方案的性能进行验证,与传统的数据采集方案的采集速度和数据质量进行对比,采集频率为3次/min,记录每次采集数据,调出一天内两种方案的采集数据进行对比,可以得到表3数据。

表3 采集信息数据
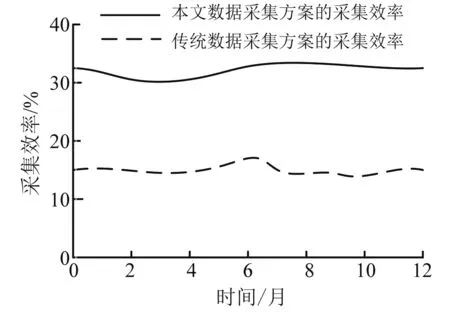
图4 采集效率对比
本文提出的数据采集方案的时间为35 s/次,传统数据采集方案的采集时间为60 s/次;本文的数据采集方案采集的数据完整度为98.5%,传统数据采集方案的数据采集完整度为92.3%。只依靠一天的采集数据并不能表现一种方案的好坏,记录一年的采集数据,计算数据采集的效率,稳定性是一个综合的指标。本文数据采集效率计算方式为数据的完整度除以采集时间,通过计算可以得到数据采集效率对比图,如图4所示。
通过图4可以看出,本文的数据采集方案的数据采集效率为30%左右,相比传统数据采集方案提高了15个百分点。基于以上描述,本文提出的数据采集方案性能优于传统数据采集方案,不仅提高了数据采集的效率,还提高了采集数据的质量。
4 结束语
本文针对电网通信系统中的通信电源数据的管理空白,引入大数据算法对电源数据实现信息化管理,优化了传统的数据采集方案,提高了数据采集的质量和效率,为后续的数据处理提供支持。最后通过试验证明了算法和数据采集方案的有效性,具有良好的应用前景。但是由于试验数据的不充分,难免会有一些问题没有发现,在后续的研究中可以进一步的优化。
