基于故障模式的装备质量问题文本分类方法
2021-09-23费清春史莹莹曾庆国
费清春,史莹莹,曾庆国
(1.南京电子技术研究所,江苏 南京210039;2.工业和信息化部电子第五研究所,广东 广州511300)
0 引言
随着计算机技术的快速发展,企业建立了产品质量问题处理信息系统,存储了大量的产品质量问题处理历史记录。产品质量改进通常是建立在产品质量问题数据分析的基础上,将质量问题快速、准确地自动归类为不同的故障模式,对于促进企业识别质量问题关键因素,推动产品质量改进具有十分重要的现实意义。如何将成千上万,甚至是几十万条质量问题数据按照故障模式自动分类,单凭专家筛选、甄别和分类,是一个巨量的、难以短时间完成的任务,成为了亟需解决的实际问题。以关键词检索等自动化程度较低的人机协作模式开展质量问题分类,结果存在大量的误报和漏报,不能满足实际使用的需要。
运用大数据技术,分析挖掘产品质量问题数据,能够为产品质量改进的技术创新提供有效的技术支持[1]。当前,计算机领域已形成了中文分词、文本挖掘等自然语言处理技术,在此背景下,本文重点聚焦装备质量问题文本数据的故障模式自动分类方法展开研究。
1 相关研究
在计算机文本挖掘方面,Kenter等人[2]合并由相同算法、语料库、参数设置得到的不同维度词向量,训练出分类模型,并利用此分类模型计算短文本问题之间的相似度;Kusner等人[3]基于词与词之间的最小移动距离,求解问题文本之间的文档相似度;孟繁宇[4]则将基于检索词的摘要提取问题转化为文本聚类问题,利用提取式摘要抽取方法,对文档的主要特征进行向量化抽取和去冗余等操作。
针对装备故障和失效等质量问题分类方法研究,张计晨[5]围绕天气雷达运行工作原理,分析雷达发射系统故障触发机理,形成发射系统故障分类模型。龚俊杰[6]提出航空产品质量问题的三维分类模型,从“过程-问题-性质”三个维度对质量问题的不同分析类别进行定义,再通过每一维度的层次分类,实现对问题的全面分类管理。李擎等人[7]提出基于层叠隐马尔可夫的设备质量风险隐患识别模型,在此基础上统计每类质量问题的出现频度,实现对基于风险等级的质量问题管理方案。谢荣琦[8]则将数据挖掘中的特征聚类算法引入质量特性识别过程中,并与过滤型特征算法相结合,构造面向复杂产品关键质量特征的问题识别模型。张青等人[9]提出基于主题扩展的领域问题分类方法,给出了评价分类的指标。Liu等人[10]提出了一种基于朴素贝叶斯的分类算法,通过计算描述文本的统计学特征进行分类。洪晟等人[11-15]针对雷达电源系统健康分级分类、车载离子电池的健康状况评价等方面,开展特征数据训练,并引入长-短期记忆网络预测和判别健康状态,在互相依存网络中开展故障关联分类分析、级联失效分类分析等。
上述研究文献启发了笔者通过文本之间的相似度判断问题分类的思路,相对于从装备实时监测状态判定故障模式,本文从自然语言处理的角度,提出一种基于文本特征抽取和相似度计算的装备质量问题自动分类方法,为解决此类问题提供了一个新的路径。
2 装备质量问题文本分类基本定义
定义1装备质量问题文本表示为6元集合P,如式(1)所示:

其中,pi表示质量问题的特定数据项。p1表示质量问题唯一编号;p2表示质量问题发生的部位;p3表示质量问题现象文本;p4表示质量问题原因文本;p5表示质量问题纠正文本;p6表示质量问题纠正措施文本。
定义2装备质量问题故障模式表示为3元集合F,如式(2)所示:

式中,fi表示装备质量问题故障模式的特定数据项。其中,f1表示故障模式唯一编号;f2表示故障模式名称;f3表示故障模式文本描述。
定义3装备质量问题分类的结果表示为装备质量问题文本集P到装备故障模式集F的一个映射关系ζP→F。假设∀xi∈P均有且仅有一个yi∈F与之对应,即一个质量问题与一个故障模式存在唯一映射关系。
3 装备质量问题文本分类方法
3.1 质量问题文本分类框架与流程
本文提出了质量问题文本分类的框架,如图1所示。数据预处理对质量问题和故障模式文本进行中文分词等;数据特征提取对质量问题和故障模式文本提取有用的特征;相似度计算获得质量问题与故障模式的文本相似性;分类判定用以建立质量问题文本与故障模式文本的映射关系;指标评价完成评估质量问题分类方法的性能。
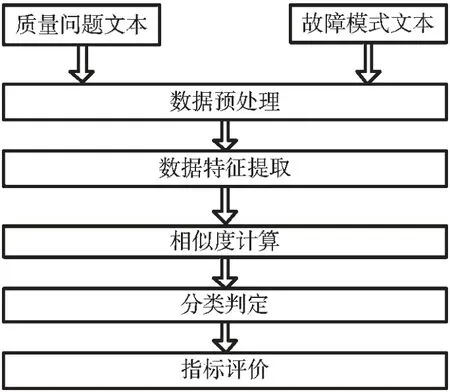
图1 装备质量问题文本分类框架图
基于故障模式的装备质量问题文本自动分类方法包含3个核心部分:(1)文本特征向量构造:利用中文分词技术分别将质量问题和故障模式文本切词,生成关键词特征向量;(2)质量问题特征向量相似度计算:进行质量问题文本与故障模式文本的特征向量之间的相似度计算;(3)质量问题故障模式判别:依据相似度阈值,自动判定质量问题归属的故障模式种类。装备质量问题文本分类方法的主要流程如图2所示。

图2 装备质量问题文本分类流程图
3.2 质量问题文本特征向量构造
在建立映射关系ζP→F的过程中,需要同时考虑质量问题文本的多维度信息pi和故障模式文本F中的多维度信息fi,最大程度地利用多元语义特征,具体步骤包括:
(1)提取装备质量问题文本的语义特征,构造质量问题文本特征向量,创建字符串s=p1+p2+p3+p4+p5+p6,对s进行中文分词并构建单词集合X。
(2)提取故障模式文本的语义特征,创建字符串f=f1+f2+f3,对f进行中文分词并构建单词集合Y,X和Y合并为词典Z,词典Z中单词的总数为n。
(3)建立质量问题文本的特征向量,记为v,向量空间长度为n;建立故障模式的特征向量,记为w,向量空间长度为n。
(4)对照文本在Z中查字典,按照独热编码方式,完成v和w特征向量赋值。
3.3 质量问题特征向量相似度计算
装备质量问题文本与质量问题故障模式文本的相似度记为a,相似度计算的常用方法包括杰卡德相似系数(Jaccard Similarity Coefficient)、余弦相似度(Cosine Similarity)和皮尔逊相关系数(Pearson Correlation Coefficient)等。
(1)杰卡德相似系数通过测量两个有限样本集合之间的重叠,计算它们之间的相似性。给定一个装备质量问题文本分词集合X,一个故障模式的分词集合Y,则杰卡德相似系数表示为:

(2)余弦相似度通过计算质量问题文本的特征向量v和故障模式的特征向量w的夹角余弦值来评估它们的相似度。给定一个质量问题特征向量v,一个故障模式的特征向量w,则余弦相似度表示为:
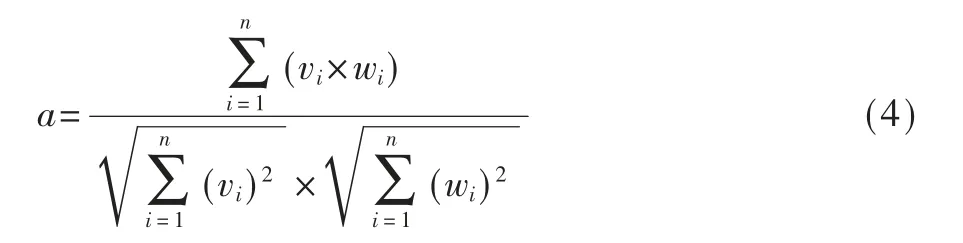
其中,vi和wi分别表示为装备质量问题文本和故障模式的特征向量中第i维特征值,a是它们之间的余弦相似度。
(3)通过计算装备质量问题文本的特征向量v和故障模式的特征向量w,得到皮尔逊相关系数,表示为:
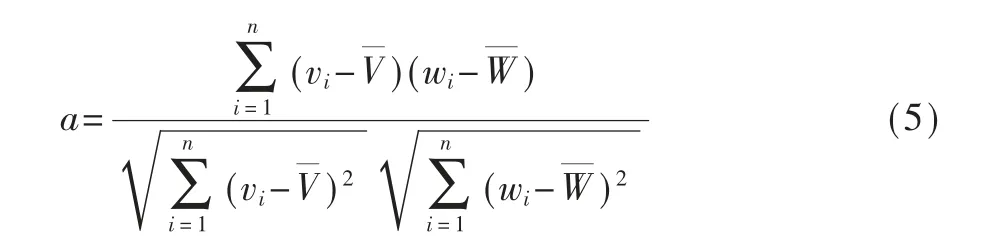
其中,vi和wi分别表示为装备质量问题文本和故障模式的特征向量中第i维特征值,和分别表示为装备质量问题文本和故障模式的特征向量平均值,a是它们之间的皮尔逊相关系数。
3.4 质量问题故障模式判别
在建立映射关系ζP→F的过程中,相似度a的值域为[0,1],在此范围内设置k作为质量问题分类故障模式的阈值。一个装备质量问题与所有故障模式文本均进行了相似度计算,假设与第i个故障模式的相似度最高,记为ai:
(1)当ai≥k时,则映射关系成立,即判定装备质量问题分类至第i个故障模式;
(2)当ai<k时,则映射关系不成立,即判定装备质量问题暂无映射的故障模式。
4 实验结果与分析
4.1 实验数据集
以某企业313项装备质量问题文本和6类故障模式文本数据开展实验对比与分析。其中,装备质量问题文本包括编号、部位、现象、原因、纠正和纠正措施等维度的短文本,而6类故障模式包括编号、名称和内容等维度短文本。
例如,一个装备质量问题文本编号为Q0001,现象为“雷达扫描线不转动,目标无法显示”,部位为“数据处理分析”,原因为“数据处理死机”,纠正为“重新安装升级后的软件”,纠正措施为“修改代码完善非法数据验证,提高容错性”。与之对应的装备故障模式编号为F001,故障模式名称为“雷达无法探测目标”,故障内容描述为“数据处理软件死机”。故障模式类别及其对应的装备质量问题文本数如表1所示。

表1 装备质量问题样本分类分布(个)
4.2 评价指标[9]
为了评价基于故障模式的装备质量问题分类方法的性能,采用准确率P、召回率R和F1指标(F1-score)作为实验评价指标。其中,准确率P反映了已分类结果的正确性,计算如式(6)所示。召回率R是已正确分类占所有应该正确分类的比例,计算如式(7)所示。F1同时兼顾了准确率P和召回率R两个方面的评价指标,它是准确率和召回率的调和平均数,计算如式(8)所示。

4.3 实验设计
为了有效验证本文提出的装备质量问题文本分类方法的有效性,设计了3个实验开展分类有效性的比对研究。
实验1:在相同的相似度阈值k下,按照杰卡德相似系数、余弦相似度和皮尔逊相关系数3种相似度计算方式,开展装备质量问题文本自动分类实验,选出性能最优的相似度算法,并开展相关结果分析。
实验2:按照实验1优选的相似度算法,开展装备质量问题文本分类实验,针对在不同的相似度阈值k下的各项指标,选出性能最优的相似度阈值k。
实验3:按照实验1优选的相似度算法,实验2优选的相似度阈值k,开展装备质量问题文本分类实验,依据在6个类别上的评价指标,分析目前存在的差距和改进方向。
4.4 实验结果
在实验1中,针对313项装备质量问题文本,按照杰卡德相似系数、余弦相似度和皮尔逊相关系数3种不同方式计算相似度a,统一设置相似度阈值k=0.01,实验1的性能指标结果如表2所示。
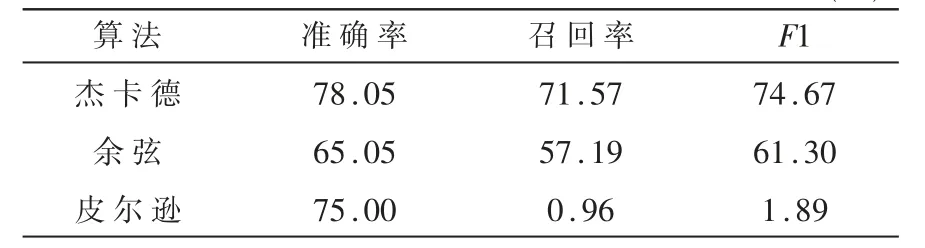
表2 实验1的性能测试指标结果(%)
在实验2中,按照杰卡德相似系数计算相似度a,设置相似度阈值k分别为0.01、0.1、0.2和0.3,实验2的性能指标结果如表3所示。

表3 实验2的性能测试指标结果(%)
在实验3中,采用杰卡德系数计算相似度a,设置相似度阈k=0.01,在6种故障模式类别下,开展实验比对,实验3的性能指标如表4所示。
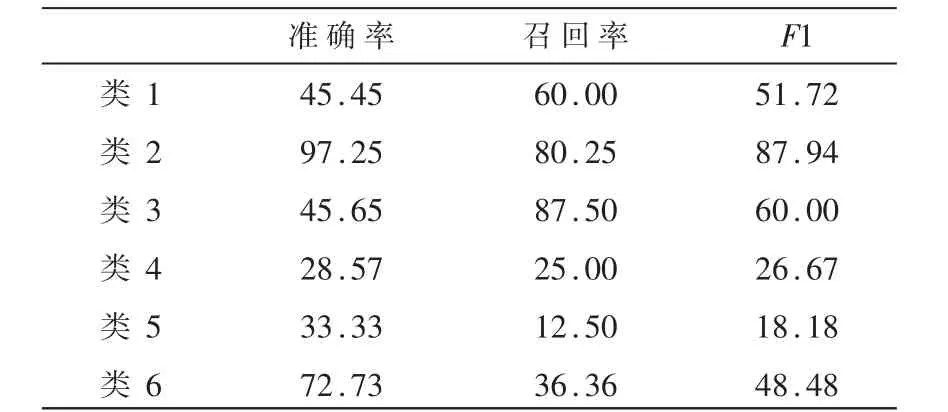
表4 实验3的性能测试指标结果(%)
4.5 结果分析
实验1结果表明,采用杰卡德相似系数在准确率、召回率和F1值3项评价指标上均优于余弦相似度和皮尔逊相关系数。相似度计算方式优选杰卡德系数。
实验2结果表明,采用杰卡德相似系数,随着阈值k逐步增加,准确率随之上升,而召回率则随之下降,准确率的提升会带来装备质量问题文本分类中漏报的风险,因此在[0.01,0.4]范围内,相似度阈值k最优为0.01。
实验3结果表明,采用杰卡德相似系数计算相似度,设置相似度阈值k=0.01时,在所有测试样本集上进行装备质量问题文本分类,整体上取得了较好的总体性能,然而,在6个故障模式类别之间性能差距较大,例如在故障模式类别2和故障模式类别4上的分类准确率和召回率具有显著差异性。因此,需要深度挖掘不同类别的质量问题文本特征,改进故障模式判别方式,均衡不同类别的分类差异,进一步优化分类效果。
5 结论
本文针对当前装备质量问题文本的分类方法自动化程度较低,提出了一种基于文本特征提取和相似度计算的分类方法,实现装备质量问题文本与故障模式的自动和有效分类,减少了对专业人员的依赖,极大地降低了分类中的人工工作量,推动了产品质量改进的效率。
在未来工作中,针对装备质量问题文本分类性能尚存在的差距,将采用深度学习模型挖掘质量数据的隐藏语义特征,进一步提升装备质量问题文本特征提取效果,并拓展故障模式库的广度和深度,优化装备质量问题文本分类的各项性能。
