从数据视角透析认知追踪:框架、问题及启示
2021-09-23孙建文栗大智
孙建文 栗大智 彭 晛 邹 睿 王 佩
(1.华中师范大学 教育大数据应用技术国家工程实验室,湖北武汉 430079;2.华中师范大学 国家数字化学习工程技术研究中心,湖北武汉 430079;3.华中师范大学 图书馆,湖北武汉 430079)
一、引 言
云计算、大数据、人工智能等技术的发展,推动教育从数字化、网络化向智能化跃升,为突破个性化学习技术瓶颈,实现“因材施教”的千年梦想提供了历史机遇(杨宗凯, 2019)。教育情境可计算、学习主体可理解、学习服务可定制是个性化学习面临的三大挑战,其中,学习主体是教育系统的核心要素,对学习主体的精准洞察是开展“因材施教”的前提(刘三女牙等, 2020)。认知追踪作为数据驱动的学习主体建模技术,已成为近年来国内外智能教育领域的研究热点(Piech et al., 2015; Khajah et al., 2016; Zhang et al., 2017; 徐墨客等, 2018; 李菲茗等, 2019; 刘恒宇等, 2019; 黄振亚, 2020; Liu et al., 2021)。
认知追踪(Knowledge Tracing, KT),也被译为“知识追踪”,本研究认为译作“认知追踪”更能表达其追踪对象是主体的人,而非客体的知识这一意蕴。认知追踪的思想源于美国著名心理学家阿特金森(Atkinson & Paulson, 1972),1995年被美国卡耐基梅隆大学科比特等(Corbett & Anderson, 1995)引入智能导学系统,并提出贝叶斯认知追踪方法(Bayesian Knowledge Tracing, BKT),其任务是根据学生的答题记录,对学生的知识掌握状态进行建模,目标是预测学生答对下一道题的概率。2015年,美国斯坦福大学皮希等(Piech et al., 2015)首次将深度神经网络技术用于认知追踪,提出一种基于循环神经网络的深度认知追踪方法(Deep Knowledge Tracing, DKT),预测性能显著提升。深度认知追踪方法顺应了人工智能技术发展趋势,引起了学者的关注,DKVMN( Zhang et al., 2017)、SKVMN(Abdelrahman & Wang, 2019)、SAKT(Pandey & Karypis, 2019)、KQN(Lee & Yeung, 2019)、GKT(Nakagawa et al., 2019)、AKT(Ghosh et al., 2020)以及HMN(Liu et al., 2021)等模型先后涌现。
认知追踪的快速发展,促进了人工智能与教育教学的交叉融合。然而,多项研究使用相同的数据集和模型,却得到不同的实验结果,原因是不同学者对数据集的处理操作不一,导致实验结果出现差异。该问题也引起部分学者的关注,如威尔逊等(Wilson et al., 2016)对深度认知追踪方法的数据处理方法提出疑问,认为应删除数据集的重复记录,按照学习系统使用过程实际顺序进行排列。后续研究大多采纳了这一建议。有学者(Xiong et al., 2016)从数据角度就深度认知追踪方法大幅提升预测性能提出三点质疑,并从数据重复性、支架题目影响、多技能题目处理三方面,将数据分为三个子集,并通过实验证明数据处理方式对实验结果的显著影响。这对后续研究有较大的参考价值,如GIKT、qDKT等模型均直接采用这一数据集划分方式(Yang et al., 2020; Sonkar et al., 2020)。近年,多位学者从不同角度讨论如何对数据进行更合理的操作(Zhang et al., 2017; Lee & Yeung, 2019; Xu & Davenport, 2020)。此外,更多论文仅对数据处理进行简单描述,或只给出数据集的基本统计信息。数据处理的不一致不仅会造成模型性能偏差,更会导致难以直接、公平地比较不同学者的创新工作,阻碍认知追踪领域的知识发展及学术共同体的成长,从而制约整个方向的可持续发展。其原因在于:一是研究偏好。人工智能与教育的交叉促进了认知追踪的发展,同时也沿袭了人工智能研究领域普遍存在的“重模型、轻数据”惯性。谷歌研究员桑巴希万等(Sambasivan et al., 2021)指出,学者们往往青睐模型创新,很少专门围绕数据展开研究,但数据质量在很大程度上决定了模型及后续应用的成败,造成数据级联问题。二是数据认知。人们对数据的操作是否合理很大程度源于对数据内涵的理解是否准确,而数据的含义通常由其逻辑和业务背景决定。不同的认知追踪数据集产生于不同的学习系统,背后有不同的教学设计与策略,由此带来数据一致性认知挑战。
综上,随着认知追踪成为研究热点,其数据处理不一致问题愈发凸显。已有研究大多从问题本身出发,很少考虑数据产生的教育场景、概念逻辑以及建模过程。因此,提出一种兼具理论指导与实际可操作性的数据分析框架,促进对认知追踪数据内涵的深层理解和规范操作变得很有必要。本研究通过调研分析,提出一种以认知追踪问题域的基本对象及相互关系为核心的概念框架,并运用该框架对数据处理过程中的关键问题进行一致性分析及提出规范化建议,最后结合认知追踪的研究趋势,讨论未来智能教育的发展。
二、概念框架
(一)数据集调研
本研究聚焦于2015年深度认知追踪提出以来,新模型不断涌现但数据处理不一致现象愈发严重这一问题展开调研。研究者以2015—2021年为文献检索时间范围,在中国知网、Springer、ACM、arXiv和Web of Science等数据库中,分别以“知识追踪”“认知追踪”“Knowledge Tracing”为关键词,搜得93篇文献,排除未明确描述数据集的文献,最终得到论文35篇,涉及18个数据集、29个模型及改进算法(见图1),包括ASSISTments系列数据集(50.5%)、Statics数据集(13.3%)、Algebra系列数据集(12.4%)和Synthetic-5数据集(10.5%)。
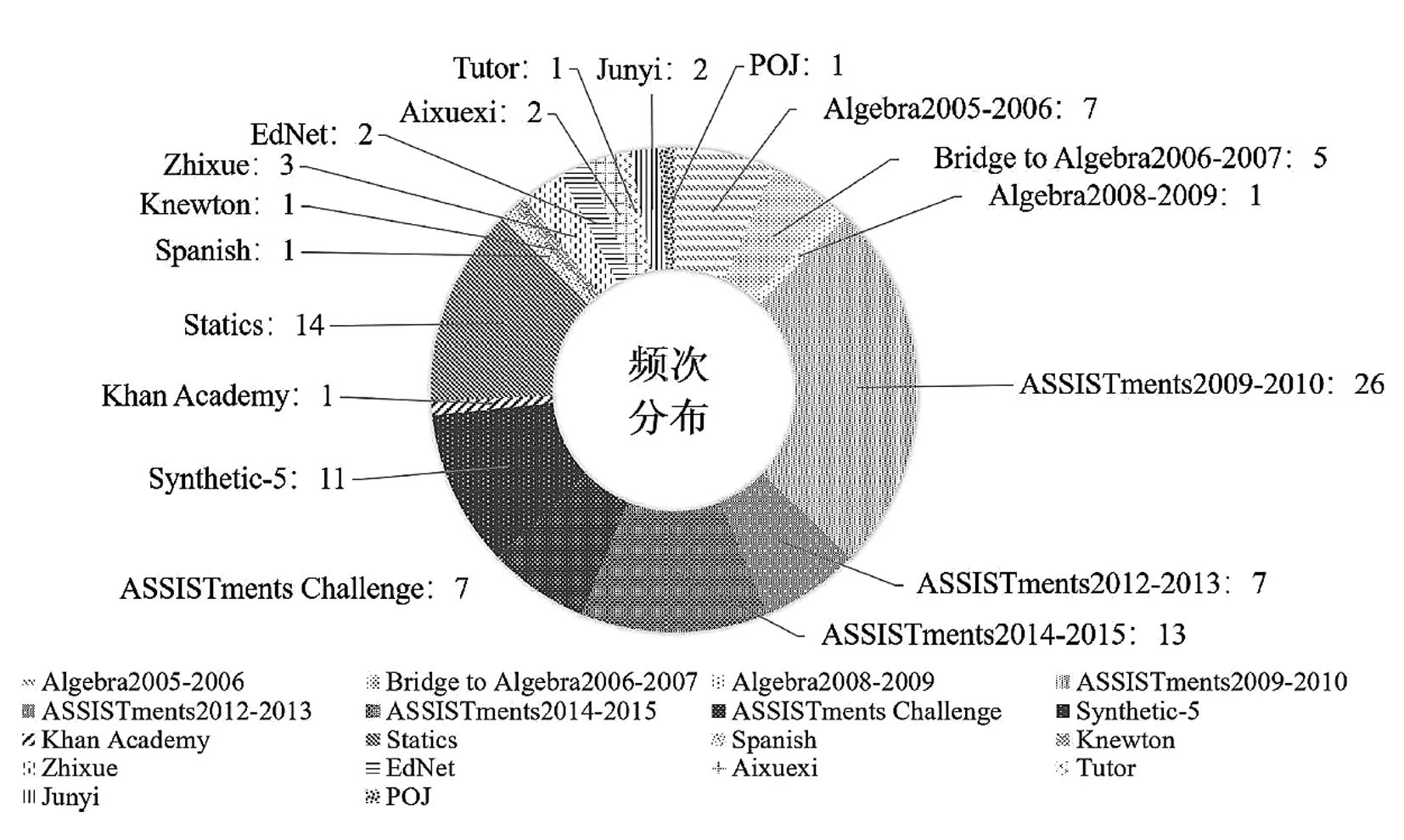
图1 样本文献中各数据集使用频次分布
1.ASSISTments系列
ASSISTments是美国伍斯特理工学院开发的在线学习平台(Feng et al., 2009),其数据集包含四个子集:ASSISTments2009-2010(ASS09)、ASSISTments 2012-2013(ASS12)、ASSISTments2014-2015(ASS15)、ASSISTments Challenge。据统计,至少有66篇论文使用了该系列数据集,使用ASS09数据集的论文超过18篇(Heffernan, 2019)。该数据集以题目—日志的形式收集学生数据,其中行是学生回答某道题的记录,内容包括学生和题目的交互特征,如是否回答正确、是否求助等。此外,数据集还记录了学校、班级等学生属性特征,以及题目编号、位置等题目特征。ASS09由2009—2010年采集的数据构成,被分成“非技能建构数据(Non-skill builder data)”和“技能建构数据(Skill builder data)”两部分,后者又被称为掌握学习数据,即学生必须连续正确回答三道题才算掌握了该项技能。从频次分布图看,该数据集使用最为广泛。ASS12由2012—2013年采集的数据构成,特点是在ASS09数据集基础上增加了挫折程度、困惑程度、注意力集中程度、厌倦程度等特征描述学生的情感状态。ASS15由2014—2015年采集的数据构成,仅包含100个单技能题目,没有支架题目,特征数较少。ASSISTments Challenge源于2017年国际数据挖掘竞赛,其特点是特征较为丰富,共82个特征,但较少被使用。
2.Algebra系列
Algebra是2010年国际知识发现和数据挖掘竞赛KDD Cup发布的公开数据集(Stamper et al., 2010),包含Algebra Ⅰ 2005-2006、Algebra Ⅰ 2006-2007、Bridge to Algebra 2006-2007等三个开发数据集,以及Algebra Ⅰ 2008-2009、Bridge to Algebra 2008-2009两个挑战数据集。其中,开发数据集包含学生真实答题结果在内的所有完整信息,旨在帮助参赛者熟悉数据格式和训练模型。挑战数据集不含学生答题结果,需要参赛者给出预测结果并提交。多数研究只使用Algebra开发数据集。
3.Statics
Statics是一门大学在线课程收集的数据,包含361092条记录,涉及335名学生和85项技能,共包含46个特征(Steif & Bier, 2014; Koedinger et al., 2010)。
4.Synthetic-5
Synthetic-5(又称为Simulated-5)是深度认知追踪方法的提出者皮希构造的模拟数据集,模拟了4000名学生50道题的答题情况,且学生答题序列相同。题目从五个模拟技能中抽取,每道题对应一项技能,重复实验20次,最后评估平均准确度和标准误差。
(二)认知追踪概念框架
综上,当前研究主要面向自主学习场景,以学生做题为主要学习活动,以预测学生的技能掌握状态或者答对下一题的概率为目标。从系统论角度看,学生、技能与题目构成了认知追踪问题域的三大核心要素,但认知追踪的适用场景并不限于此。随着智能教育技术的发展,认知追踪可广泛应用于多主体协作学习、多步骤问题解决、多层次知识能力诊断等更开放、复杂、高阶的学习场景。为了不失一般性,本研究将“知识”和“问题”分别作为“技能”和“题目”两个元素的泛化概念,建立了以“学生(Student)—知识(Knowledge)—问题(Problem)”三个对象以及六类关系为核心的认知追踪概念框架(SKP,见图2)。
认知追踪概念框架旨在建立对认知追踪的数据化认知与概念化分析框架,从更广泛的意义上理解多场景认知追踪的数据元素及其关系,为如何基于数据的产生场景及教育意义进行数据处理提供分析工具,从源头解决当前普遍存在的数据处理不一致或欠规范问题。认知追踪概念框架包括三个对象和六类关系。
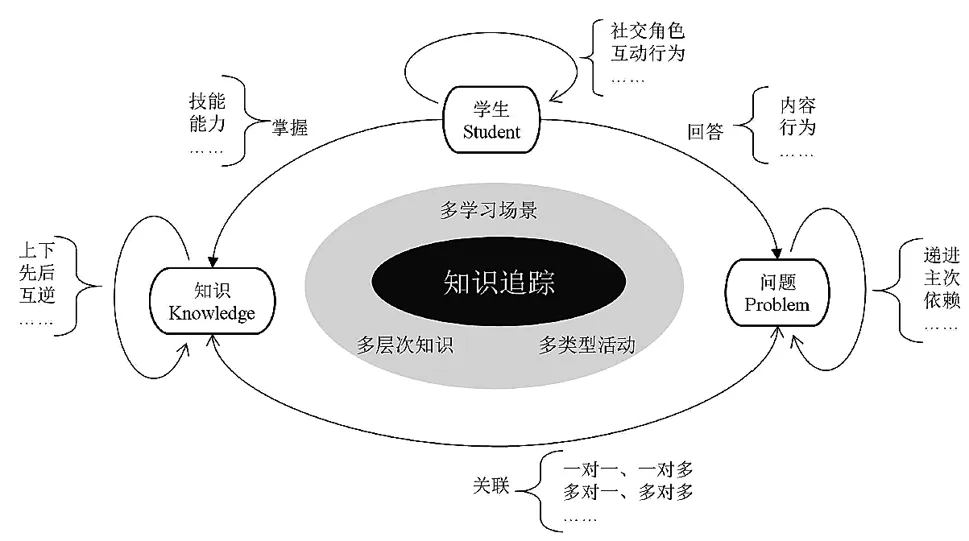
图2 认知追踪概念框架
1.基本对象
学生、知识和问题构成了认知追踪数据处理过程的三个基本对象。其中,学生对象包括个人基本信息及其在不同学习场景留下的学习行为信息;知识对象包括知识名称、类型、层次等基本属性,以及知识描述等信息;问题对象包括问题类型、难度、区分度等基本属性,以及题干、答案、提示、解析等内容语义信息。
2.交互关系
一是同类对象之间的交互,常被用作辅助信息融入认知追踪建模过程。其中,“学生—学生”交互关系主要体现在多主体协作学习场景,包括学生协作过程中形成的社交角色、互动行为和内容等信息;“知识—知识”交互主要用于描述知识结构或性质关系,包括知识图谱的上下位、先后修等关系,以及具有互逆性质的知识之间的关系等;“问题—问题”交互主要体现在问题序列背后的教学设计思想,如多个主干问题之间的递进关系、主干问题与支架问题之间的主次关系、多步骤问题之间的依赖关系等。
二是不同对象之间的交互,是认知追踪建模过程使用的主要信息。其中,“学生—问题”交互主要用于描述学生回答或解决问题过程中产生的各类内容或行为信息,包括作答内容以及请求提示、查看答案或解析过程等行为信息;“问题—知识”交互主要用于描述问题与知识之间的关联关系,包括一对一、一对多、多对一和多对多等,如一对一表示一个问题仅关联一个知识点,一对多表示一个问题关联多个知识点;“学生—知识”交互用于描述学生对简单技能、高阶能力等不同层次知识的掌握状态。
(三)基于认知追踪概念框架的特征分类
认知追踪数据集大多含有丰富的特征,对特征的概念化分类是对数据内涵理解及后续处理分析的认知基础。数据集虽然源于不同的学习平台和应用场景,其特征较为丰富,但均可按认知追踪概念框架统一分类,从而为在更高层次建立对特征含义的共识性理解提供可能。
三、关键问题
基于认知追踪概念框架,本研究汇总了上述35篇论文对三个高频数据集的处理方式及相关信息(见表一)。其中,数据集命名的字母表示原始数据集,数字表示经过处理后得到的子集,原始数据集的统计信息均来自官方网站,相关模型或论文对应的处理方式均引自原文。
由表一可知,除Statics在多个文献中的处理方式基本一致外,其他数据集在不同研究中的处理方式均存在明显问题,具体可分为三类:一是未明确说明处理方式;二是描述的处理方式相同但统计信息不一致,如数据集a-16使用a-4的处理方法(Sonkar et al., 2020),得到不同的统计信息;三是统计信息一致但处理方式不同,如a-7、c-2先后被同一团队的两篇论文使用(Minn et al., 2018; Minn et al., 2019),文中对数据处理的描述不同,但给出的统计信息一致。结合表一,本研究重点围绕以下五个问题展开讨论。
(一)数据重复
表一中近一半的研究工作涉及数据去重处理。ASS09、Alge05等数据集均存在大量的学习行为重复记录。虽然研究者无法从源头查证重复记录如何产生,但学生在学习平台的操作属于时序行为,学生不会在同一时间回答多个问题,产生多条记录。有研究(Xiong et al., 2016)表明,这些重复数据实为冗余信息,可直接删除。
一般而言,学生在学习平台上进行答题等操作后,后台数据库会生成语义丰富的学习行为记录,并在此基础上构建基于多特征的认知追踪模型(Sun et al., 2021),这是提升学习者建模能力的有效途径。因此,数据采集的特征丰富性、记录完整性是保障数据质量的基本要求,也是影响模型性能的关键因素。对于开放、复杂的智能学习环境以及大规模用户使用场景,如何高保真、高效地记录海量学习者的并发行为,是智能教育系统设计与实现需解决的基础性问题。
德州仪器(TI)是世界上最大的半导体公司之一。德州仪器始终致力于提供创新半导体技术,帮助客户开发世界最先进的电子产品。德州仪器的模拟、嵌入式处理以及无线技术不断深入至生活的方方面面,从数字通信娱乐到医疗服务、汽车系统以及各种广泛的应用,无所不在。
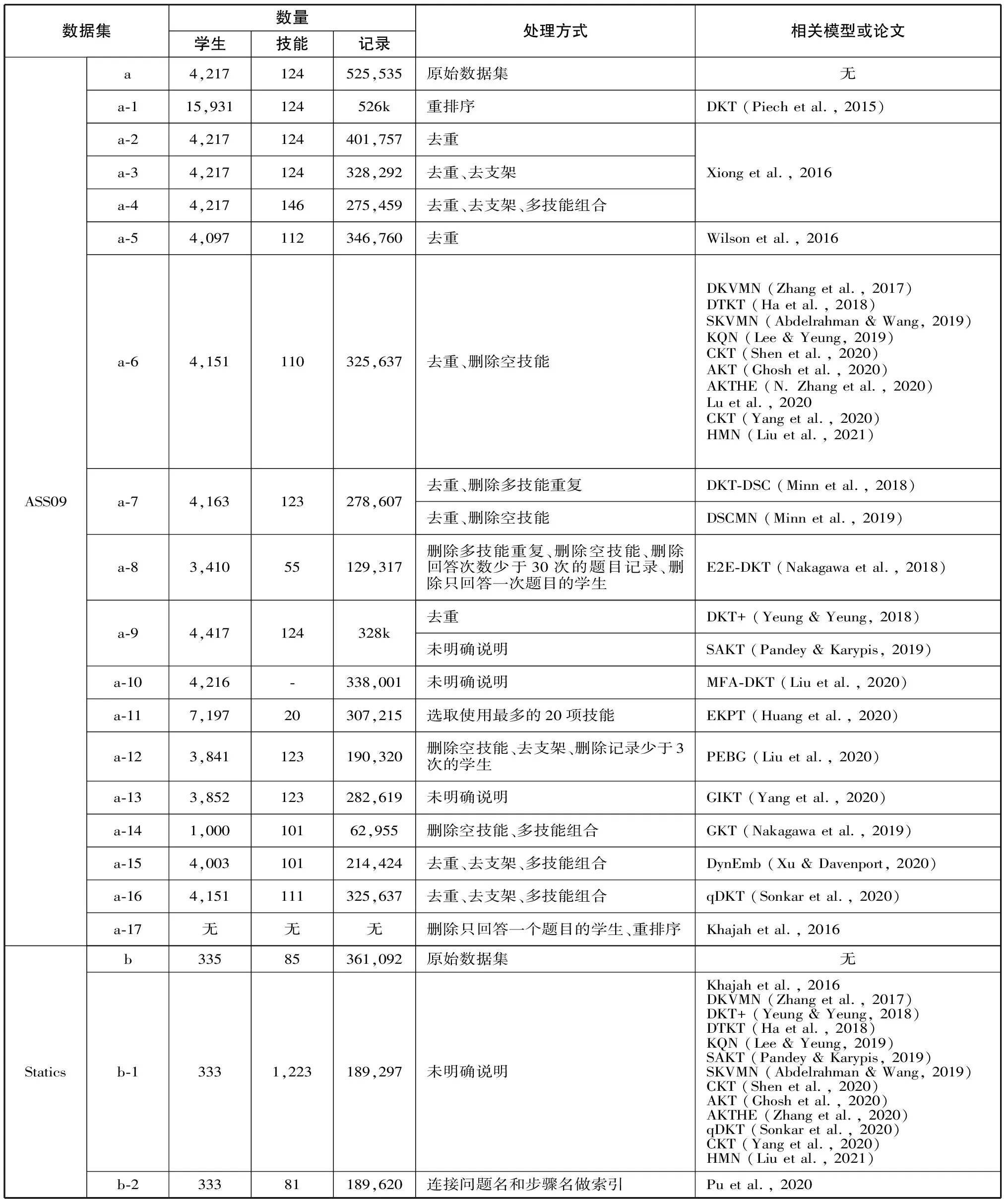
表一 样本文献数据集统计信息及处理方式比较
(二)数据顺序
数据顺序指学习行为记录输入模型的先后。通常,认知追踪建模会以学生真实答题顺序组织数据,这有利于模型捕捉数据中蕴含的学生认知状态变化规律,从而获得精准的预测结果。但也有部分研究考虑模型输入的答题序列长度对齐、按相同技能或学生重组答题序列等因素对数据进行专门处理,截断或打乱学生答题行为数据的原始顺序。例如,表一的数据集a-1,将题目对应技能按编号重新排序后再输入模型(Piech et al., 2015)。
从智能教育系统视角看,学生的学习行为序列可能蕴涵了特定的教学策略或设计思想。例如,ASSISTments平台依据掌握学习理论设计和组织题目序列,学生按题目预设顺序作答反映了一种预期的认知状态变化模式或规律,即连续答对多道相同技能的题目意味着该生大概率掌握了该技能。其次,教育心理学研究发现(Rohrer et al., 2015),学生做数学题的过程中,不同技能的题目交叉出现比连续出现更有助于提升学习效果。
(三)支架题目
支架题目(Xiong et al., 2016)的设计思想源于支架式教学理论,旨在帮助学生穿越最近发展区,把认知引到更高水平。在学习平台上,支架题目与主题目所考察的技能相同或相近,但通常难度较低。表一中,部分研究认为,认知追踪的建模过程不应同等对待支架题目,因此直接删除了支架题目(Xiong et al., 2016; Liu et al., 2020; Xu & Davenport, 2020; Sonkar et al., 2020)。实际上,支架题目作答行为是学生做题序列的有机组成部分,从数据真实性和完整性角度看,保留支架题目数据有利于更准确地建模学生认知状态的变化。
对智能教育系统而言,支架是一种广泛用于多种学习场景的导学策略,其形式不限于题目,包括推进、提示、暗示等,目的是推动学生思考、保持学习动力。在认知追踪应用场景中,支架题目的设计也体现了这一思想。当学生遇到难题时,引导其解决支架类问题可有效促进学习。因此,支架题目作答行为数据通常隐含了学生认知水平提升这一重要信息。以ASSISTments平台为例,若学生答题记录既包含主题目,又包含支架题目,且连续答对多个支架题目,这意味着学生经历了最近发展区的认知发展过程,并从支架题目的引导中掌握了相应的技能。
(四)技能缺失
针对部分答题记录缺失对应的技能信息,相关研究一般直接删除记录(Zhang et al., 2017; Ha et al., 2018; Abdelrahman & Wang, 2019; Lee & Yeung, 2019; Ghosh et al., 2020; Gan et al., 2020),或填充一个固定值(Piech et al., 2015; Khajah et al., 2016; Wilson et al., 2016)。前者虽然保证了数据的真实性,但会丢失大量有用信息,尤其是缺失记录占比较高对模型性能影响较大。后者为了处理简单,把所有技能缺失记录填充为一个新值,这会带来大量数据噪声,导致模型学到更多的错误模式。
技能缺失折射出智能教育领域普遍存在的一个难题——智能化知识组织与资源标注。对学科知识的精细化组织,以及资源内容的深层次加工和语义化标注,是构建智能教育知识基础设施的核心任务。教育知识图谱正是该方向的研究热点,即在传统人工构建知识体系、标注知识资源的基础上,利用数据和知识双向驱动的方式往半自动或自动化方向发展。因此,对于技能缺失问题,简单删除记录或者填充固定值的做法都不合理,应考虑如何有效利用数据集的已有信息,运用相应策略补全缺失值。
(五)多技能题目
1.问题描述
在智能导学、自适应学习等认知追踪应用场景中,一道题通常不只关联一项技能,而是关联多项技能,此类题目可被称为多技能题目(Xiong et al., 2016)。例如,一道求矩阵点积的题目可能关联向量运算、多项式运算等技能。认知追踪建模首先需要对特征进行编码,研究者通常采用机器学习领域主流的独热编码方式处理单技能题目(one-hot encoding),但对多技能题目的编码尚未达成共识。
2.典型方法
多技能题目的编码方法可分为两种:一是使用拆分策略,即将“一条包含多技能的记录”拆成“多条只含单技能的记录”;二是采取组合策略,即将“同一道题目包含的多个技能”组合为“一个新的技能”并重新编码。以两条答题记录为例(见图3左):第一行记录了某学生回答第11题的信息,该题与编号为21、22号的两项技能相关,学生回答正确;第二行记录了该生回答第12题的信息,该题对应编号为21、22和23等三项技能,学生回答错误。
若按拆分策略处理,研究者会得到拆分格式数据,原始样本数据第一行记录被拆分为两行,除技能编号不同外,其余信息都相同。同理,拆分原始样本数据第二行可得到三行数据(见图3右上)。若按组合策略处理,研究者会得到组合格式数据,原始样本数据第一行技能(21,22)被视为一种新的技能,并被编码为31。同理,第二行技能被编码为32(见图3右下)。
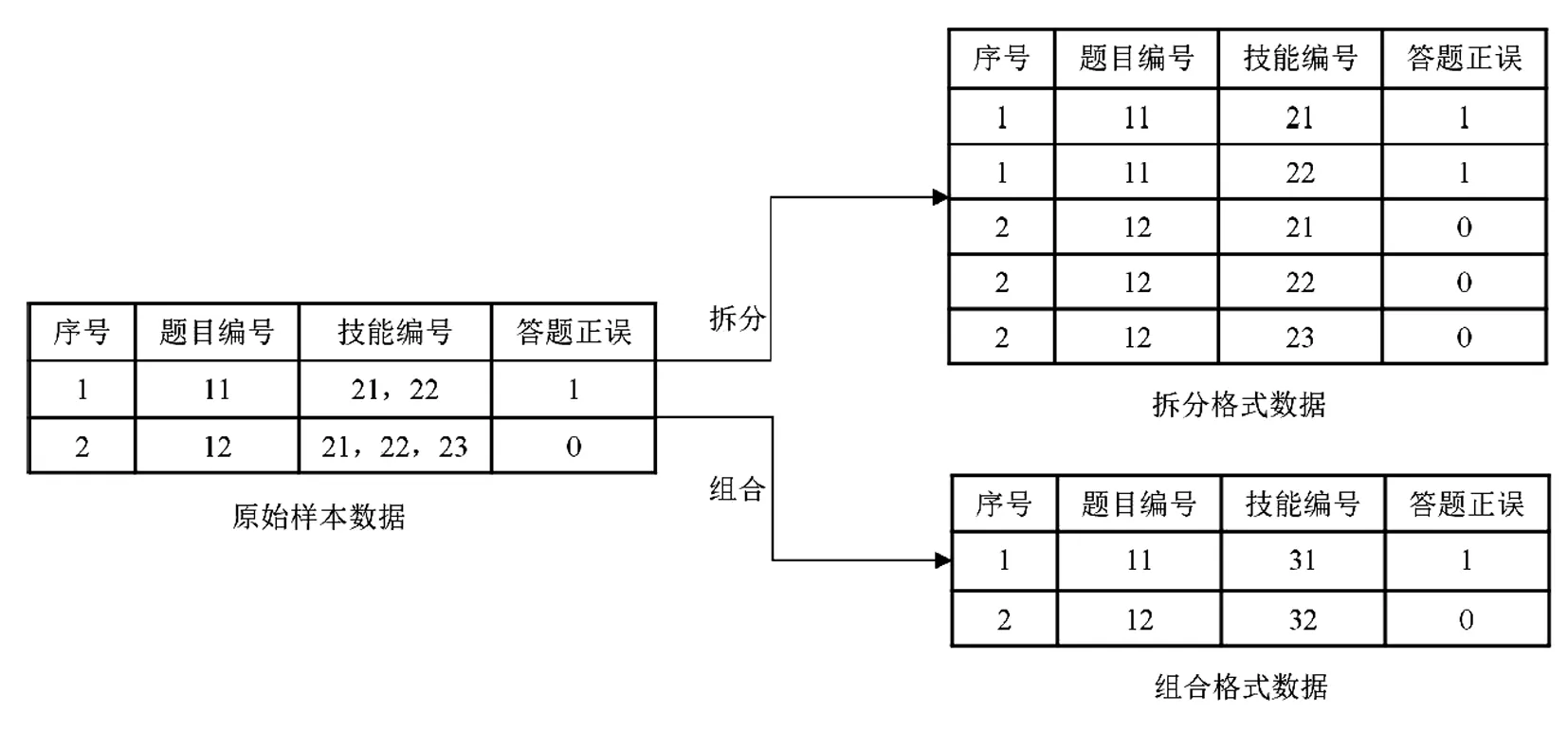
图3 多技能题目的两种编码方法示例
对于拆分格式数据,以深度神经网络为代表的模型容易学到两项技能交替出现的模式,由此带来额外且显著的性能优势(Khajah et al., 2016),但同时也造成数据冗余,因此近年的研究逐渐转向组合方式(Nakagawa et al., 2018; Choffin et al., 2019; Xu & Davenport, 2020; Sonkar et al., 2020)。组合格式数据虽然保证了一条记录描述一道题,但同时也造成技能间关联信息的缺失。例如,两个组合而成的新技能31和32,虽然都包含了技能21和22,但重新编码后无法体现这一关联信息。
3.多热编码方法
从模型输入编码角度,以上两种数据处理方法均采用基于技能编号的独热编码。为解决这两种方法存在的固有弊端,研究者提出多热编码方法(multi-hot encoding),即通过构建一个矩阵,保存题目和技能之间的交互关系,然后通过内积运算得到题目对应的多热编码,模型输出可采用多个技能对应预测概率的平均值。
多热编码方法的优势包括:一是既保存了题目和多个技能的原始对应关系,又可以表示不同题目与多个技能之间的关联性,有助于模型发现组合技能和其他技能的关系,更具可解释性;二是每个时间步只需输入一道题的记录,而不是用多个时间步处理同一道题,更符合认知追踪序列化建模的内在逻辑;三是减少数据重复出现的同时保证了信息的完整性,并能够与拆分、组合两种格式的数据相互转换。
四、启 示
作为人工智能与教育交叉的产物,认知追踪诞生于“小数据+传统机器学习”主导的20世纪90年代(以BKT为代表),暴发于“大数据+深度神经网络”(以DKT为代表)引领的新一代人工智能时代,成为智能教育不断演进的缩影。数据驱动是认知追踪的固有基因,贯穿了从学习行为数据采集、处理、建模到应用等整个生命周期。本研究从认知追踪数据产生及利用的场景、模态、模型、范式、价值等方面剖析其研究趋势,也得出对未来智能教育发展的启示。
(一)场景拓展:从自主学习到多模式混合学习
回溯认知追踪的发展史,从贝叶斯认知追踪到深度认知追踪,可谓是经历了一场从应用创新到模型创新的研究思潮变化。以贝叶斯认知追踪方向为主的研究共同体,注重从具体教学场景切入,尤其是结合各类智能导学系统开展以个体自主学习为主要模式的应用创新。反之,侧重深度认知追踪方向的研究人员专注于模型创新,特别是近年受益于人工智能技术的不断创新与突破,新模型不断涌现。未来,一方面随着认知追踪建模技术的沉淀与成熟,回归教育应用是必然趋势;另一方面,构建相互融通的学习场景、灵活多元的学习方式、弹性多能的组织管理是人工智能赋能教育的主要目标(黄荣怀等, 2019; 曹培杰, 2020)。认知追踪也将顺应智能教育的整体发展趋势,突破当前以个体自主学习为主的应用场景,拓展到多空间融合、多主体协同、多模态交互等更加复杂多元的学习场景。
(二)模态跨越:从单一学习行为到多模态数据融合
长期以来,大多数认知追踪模型仅基于学生答题结果这一单一的学习行为数据。近年来,部分学者开始使用更多语义丰富的特征,如认知追踪概念框架下学生对象的属性信息、问题对象的属性信息、“学生—问题”交互信息等,构建基于多特征的认知追踪模型(Sun et al., 2021),以提升其预测能力。当前,智能感知、可穿戴设备、物联网等技术的发展,以及自然语言处理、计算机视觉、语音识别、生理信息识别等智能技术的不断成熟,有助于实现面向智能学习环境的多模态、细粒度、高价值学习大数据的自动采集,使多模态学习分析成为驱动智能教育研究的新趋向(王一岩等, 2021)。在这一趋势下,认知追踪将会跨越单一行为模态,逐渐发展成为行为、心理、生理等多模态数据融合驱动,从多维度、多层次洞察学习者,构建更加精准的学习者模型。
(三)模型白化:从深度学习算法黑箱到可解释分析
从贝叶斯认知追踪到深度认知追踪,变的不仅是技术路线,认知追踪的预测准确率也得到显著提升(AUC值提升近30%)。但是由于神经网络固有的“黑箱”特性,难以通过模型内部的变量或参数理解学习者认知建模的具体原理,无法揭示模型可能学到的有教育意义的信息(如学习者在答题过程中的学习率、猜测率、失误率等),降低了对模型预测结果的增值利用或信任程度。当前,深度神经网络技术已广泛应用于智能教育领域。教育注重揭示教育现象或行为之间的因果关系,未来智能教育在研究如何构建更精准、高效机器学习模型的同时,会更加强调对模型决策过程的可解释分析(刘三女牙等, 2021)。深度神经网络隐层白化、因果推理计算等人工智能领域的最新技术进展(Chen et al., 2020),将有助于揭示深度认知追踪模型内部的工作机理,实现对学习者的错因追溯、归因分析等更具教育价值的服务。
(四)范式转变:从数据驱动到数据与知识联合驱动
智能教育深受人工智能技术进展影响,其发展史就是一部与人工智能技术共舞的历史。自1956年达特茅斯会议首次提出人工智能概念以来,人工智能历经知识驱动、以知识工程为代表的AI 1.0时代,到数据驱动的、以深度学习为代表的AI 2.0时代,当前正处于从数据驱动到“数据+知识”联合驱动的技术转型期,双轮驱动的智能技术研究范式正在成为趋势,AI 3.0时代正在来临(张钹等, 2020)。随着技术的进步,智能教育也将突破过去以外显学习行为识别为代表的浅层次感知技术瓶颈,进一步实现对学习情景、意图或状态的深层次理解。同时,知识图谱增强的认知计算方法将赋予机器更强的推理和决策能力,能够在“师—机—生”交互、群体协作等复杂的认知活动中提供更具策略性的学习支架与教学辅助。认知追踪将在建模能力、解释分析、因果推断等方面受益于知识图谱技术,“数据+知识”联合驱动也将成为认知追踪与智能教育的主要研究范式。
(五)价值回归:从技术意识垄断回归教育价值本位
在人工智能与教育的深度融合过程中,过度关注技术带来的效益而忽略了教育本身的需求,造成了人工智能对教育的意识垄断(杨欣, 2021)。作为智能教育发展的缩影,认知追踪同样染上了浓厚的人工智能意识垄断色彩。如同当前如火如荼的智能搜题、智能解题、智能批阅等智能教育应用,以深度认知追踪为代表的认知追踪研究直接顺从了教育领域的既得利益,在线答题与技能掌握成为认知追踪难以摆脱的“人设”,模型改进与性能提升成为部分研究者孜孜不倦的“唯一”追求。随之而来的是古德哈特定律的应验,更多的研究者会根据深度认知追踪的发展态势和标准优化自己的行为,强化认知追踪的技术意识垄断。未来,研究者亟需回归教育价值本位,从教育的角度推动认知追踪和智能教育创新发展,适应未来社会强调以人为本、注重关键能力与核心素养培养的时代主题。
总之,智能时代的教育革命已然来临,大数据及人工智能技术加持下的认知追踪必将突破当前研究边界,开拓新的学术方向,并将带动认知追踪研究及应用回归教育本源。具体而言,我们首先需从认知追踪数据产生的学习场景与教育意义出发,建立对认知追踪概念框架与数据处理的共识,破解当前普遍存在的“重模型、轻数据”问题;其次,顺应智能教育的发展潮流,推动认知追踪研究与应用转型:从个体自主学习到多模式混合学习、从单一学习行为到多模态数据融合、从深度学习算法黑箱到可解释分析、从数据驱动到数据与知识联合驱动,以及从技术意识垄断回归教育价值本位。
