改进DM-SVDD算法的异常检测研究及应用
2021-09-22张雪英李凤莲杜海文于丽君
王 杰,张雪英,李凤莲,杜海文,于丽君,马 秀
(1.太原理工大学 信息与计算机学院,太原 030024;2.山西中电科新能源技术有限公司,太原 030024)
近年来,很多领域的数据都具有不平衡数据的特点,即正常类样本的数据量远大于异常类样本的数据量,而异常类样本通常含有更重要的信息,如何提升异常类样本的检测性能[1],对于提高行业产品质量具有重要意义。多晶硅作为最主要的光伏产业材料之一,在铸锭生产过程中,如果工艺设计及环境条件保持不变,多数产品为正常产品,但由于每次生产所用配料的批次或成分的差异,会产生少数的异常产品,由此形成不平衡数据集。通过分析配料数据,对产品质量进行分类预测,可以有效地指导实际生产。
目前,工业上常用的异常检测方法为工艺试验[2],实现成本高且难度大。因此,近些年人们开始用机器学习的方法来解决异常检测问题,主要包括特征降维和不平衡数据分类两部分。在特征降维方面,数据维数过大会提高模型的复杂度,影响模型运行效率和检测准确率,对此,冯安然等[3]利用主成分分析(principal component analysis,PCA)在原有数据的基础上,通过线性组合重构出方差较大的低维主成分,但该方法只能捕捉数据的方差,缺乏对数据内在结构的刻画,容易丢失数据隐含的关键信息。而基于流形学习的扩散映射(diffusion maps,DM)[4]通过核函数得到扩散过程中的扩散距离,在保持扩散距离不变的条件下实现降维,取涵盖数据主要结构的特征值及相应的特征向量,使其在低维空间中仍保持稳定的全局关系,适用于异常检测时的特征降维[5]。在不平衡数据分类方面,支持向量机(support vector machine,SVM)作为传统的分类模型,在解决小样本、非线性问题时分类效果良好,但当样本不平衡率较大时,对于少数异常类的识别效果很差。而支持向量数据描述(support vector data description,SVDD)[6]有很强的单值数据处理能力,仅利用正类样本训练分类模型,适合实际生产过程中异常类样本较少导致的数据不平衡情况,在异常检测[7]领域已得到有效应用。因此,为充分利用DM和SVDD二者的优点,本文构建了基于DM-SVDD的异常检测新模型,并针对多晶硅数据中存在的字符型和数值型两种类型数据,引入欧氏距离和马氏距离改进扩散映射方法。最后,将所提模型用于多晶硅配料数据预测产品质量,实验结果中G-Mean最优提升15.73%,F-Score最优提升19.37%,验证了模型的有效性。
1 扩散映射与支持向量数据描述算法原理
1.1 扩散映射算法基本原理
扩散映射算法通过尽可能保持扩散过程中的扩散距离来实现降维,旨在通过样本点的局部关系定义全局关系。对于预处理后得到的N个维数为D的样本序列XS={x1,x2,…,xN},xi∈RD,i=1,2,…,N.
首先构造权重矩阵,对于给定的两个样本点xi和xj,利用Gaussian核函数来定义样本间的关联程度,即
(1)
式中:μ为高斯核的带宽,当μ一定时,数据点之间的距离越近,则关联性越强。进而在权重矩阵的基础上构造转移概率矩阵Km,利用加权的图Laplacian归一化方法,通过式(2)得到矩阵元素:
(2)
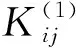
(3)
(4)
式(4):wk定义为数据点之间的度,表示以某一数据点为中心,与其他所有数据点之间的权重之和;φ(xk)表示构造扩散距离时马尔可夫过程的平稳分布。保持扩散距离不变,对矩阵Km进行特征分解,求解特征值以及对应的特征向量,取d个最大的特征值λ1,λ2,…,λd对应的特征向量υ1,υ2,…,υd作为低维嵌入结果,得到降维后的数据XDM=[υ1,υ2,…,υd]T.
1.2 支持向量数据描述算法基本原理
SVDD算法通过核函数将正常类数据映射到高维空间中,进而在高维空间中构造闭合超球面进行异常检测,见图1.

图1 支持向量数据描述模型Fig.1 Support vector data description model
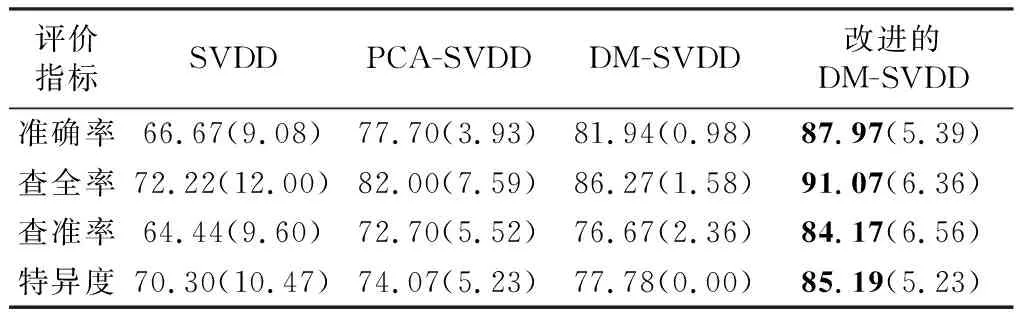
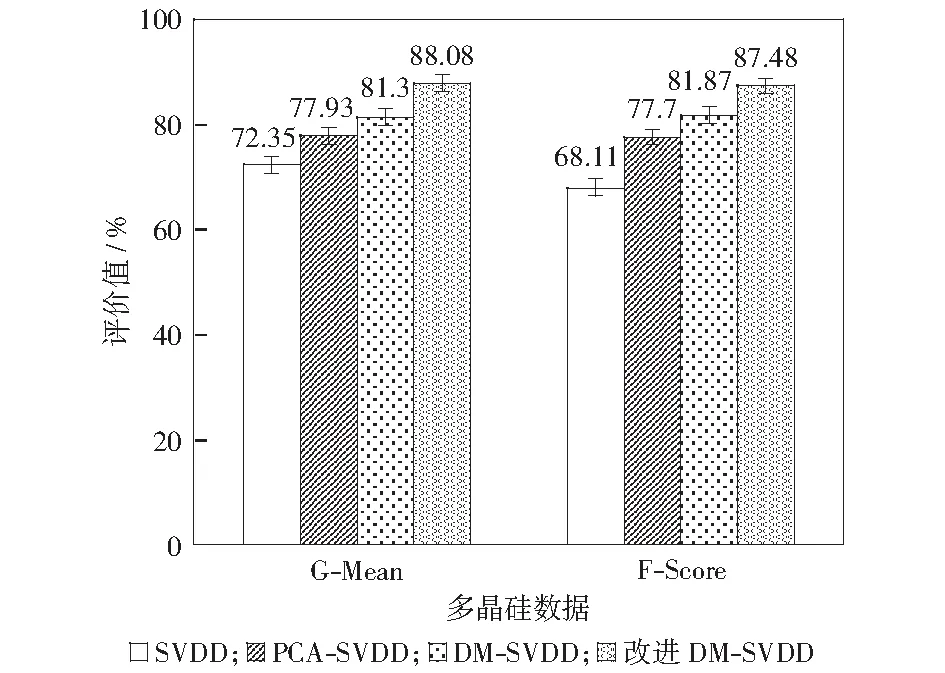
利用降维处理后XDM的部分正常类样本数据X={x1,x2,…,xl},0 (5) 式中:R和a分别为对应高维特征空间中超球面的半径和球心;ξi为松弛变量;C>0为惩罚参数;φ(·)为映射函数。通过求解Lagrange对偶问题可将上式转换为式(6): (6) 运用二次规划求解式(6)可得Lagrange乘子αi,进而可求得对应超球体的球心a和半径R,得到超球面的信息。从而可得决策函数为: 方案一:逻辑模块用或门,温度模块采用10K的NTC热敏电阻MF58,NTC热敏电阻由特殊配置的金属氧化物陶瓷材料制成,电阻随温度升高而下降。 f(x)=‖φ(x)-a‖2-R2. (7) 对于未知的样本点x,计算它到球心a的距离,即公式(7)中的‖φ(x)-a‖.当f(x)≤0时,即目标点位于球形边界内,判为正常类样本;反之,则为异常类样本。 本文实验所用数据来源于山西中电科新能源技术有限公司近月实际生产的多晶硅数据,包含正常类样本123组,异常类样本16组,不平衡率为7.69%. 结合多晶硅装料工艺的实际情况,通过分析生产中的配料数据来进行异常产品检测模型的构建和性能分析。多晶硅配料数据见表1,其数据特征包括:原生料、提纯料、循环料等表示质量的数值型数据,其中循环料包括破碎料、头料和尾料。铸锭过程中,若选用不同批次的配料,最终硅锭的质量会产生差异。因此,本文将表示批次的字符型数据数值化处理后参与实验,如表1中破碎料批次、头料批次、尾料批次。表中的少子寿命值表示在铸锭生产后,由少子寿命仪测得的硅锭中少数载流子存活时间,根据实际生产经验,少子寿命值小于5.8 μs为异常类产品,反之则为正常类产品。 表1 多晶硅数据Table 1 Polysilicon ingot data 本文采用K折交叉验证的方法将包含正常类和异常类的139组样本数据划分为训练集、验证集和测试集。训练集仅包含正常类数据,验证集与测试集包含正常类和异常类两种数据,来进行异常检测模型的构建和性能分析。 基于上述多晶硅数据,建立改进的基于DM-SVDD算法的异常检测模型,见图2,其过程叙述如下。 图2 DM-SVDD模型流程图Fig.2 Flow chart of DM-SVDD model 1) 改进降维处理方法。本文针对所用多晶硅数据中的数值型数据和字符型数据,将字符型数据数值化处理后,提出综合使用欧氏距离和马氏距离两种距离度量方法改进DM算法中的K近邻标准。 D(xi,xj)2=(xi-xj)T(xi-xj) . (8) 由于马氏距离[8]对于给定的样本集,综合考虑了各样本点之间的关联性,对于不同类型的相似样本具有较好的区分度,有利于提高最终的分类精度,故利用马氏距离度量方法计算数值型数据特征之间的距离。马氏距离度量方法如式(9)所示,S为对应的协方差矩阵。 DM(xi,xj)2=(xi-xj)TS-1(xi-xj) . (9) 综合两种度量方式计算的结果,确定距离样本点最近的K个近邻点,根据样本点间的距离构造新的近邻图改进DM算法的降维过程。 2) 优化模型参数。为得到误差最小的异常检测模型,将数据集划分为:训练集、验证集和测试集三部分。实验过程中,选取训练集数据训练得到初始化的检测模型,之后运用验证集数据进行模型检验。本文采用蒙特卡洛寻优算法进行最优参数选择,相比于传统的网格寻优算法,蒙特卡洛寻优算法是一种全值估计方法,可以更好地处理非线性问题,结果精确可靠;该方法在给定区间内随机选取参数,用随机抽样代替了系统搜索,大大降低了时间复杂度。 3) 构建异常检测新模型。在SVDD算法中,高斯核泛化性能优于其他多项式核函数[9],故本文采用高斯核函数,运用验证集数据优化模型后得到的最优参数,构建误差最小的基于改进DM-SVDD算法的异常检测新模型。 4) 测试模型。将测试集的数据输入改进的DM-SVDD异常检测模型中,通过计算式(7)所示的目标函数,比较样本点到模型球心的距离,得到最终的检测结果。 为了评价本文提出的改进DM-SVDD模型用于异常检测的性能,实验采用多晶硅配料数据,对比传统的异常检测模型,得到三折交叉验证的测试结果;同时为验证所提模型对于异常类样本检测的准确率,使用测试数据进行检测,得到直观的测试结果。模型最优参数的选取采用蒙特卡洛方法寻优结果,核函数选择高斯核函数,在MATLAB R2014b环境下进行实验。惩罚参数C=1/(nv),v∈(0,1],其中v控制了支持向量的上限比例,故搜索区间设置为[0.1,1],由于核参数σ>0,通过实验发现当σ>16时,结果基本保持不变,故搜索区间设置为[0.125,16]. 由于不平衡数据的准确率易偏向于正常类样本的正确检测结果,本文除了采用准确率(racc)±标准偏差、查全率(re)±标准偏差、查准率(rP)±标准偏差、特异度(Sp)±标准偏差4个指标进行模型评价外,还采用了针对不平衡数据分类的评价指标F-Score和G-Mean[10],分别如式(10)和式(11)所示,为实现查全率和查准率的折中,F-Score中参数α设置为0.5. (10) (11) 利用多晶硅配料数据,训练得到最优的改进DM-SVDD异常样本检测模型,将测试集数据输入模型进行检测分析,同样采用传统SVDD算法、PCA-SVDD算法以及未改进的DM-SVDD算法分别进行模型的训练和检测。对比4种模型的测试结果和运行时间,见表2和表3. 表2 测试结果及标准偏差Table 2 Test results and standard deviations % 由表2和表3可知:本文提出的改进DM-SVDD算法所构建的模型不仅降低了运行时间,且准确率达到87.97%,在4种算法中检测性能最优,同时改进的DM-SVDD模型在保证查全率最优的前提下,相较于其他3种模型,查准率最优提升了19.73%,特异度最优提升了14.89%.在保证正常类样本检测准确率较高的同时,提升了异常类样本的检测准确率。 表3 运行时间对比Table 3 Comparison of running time s 为准确评价模型对于两类样本的分类性能,比较G-Mean与F-Score结果如图3所示。由图3可知,改进的DM-SVDD算法使G-Mean最优提升了16.83%,F-Score最优提升了19.37%. 图3 G-Mean与F-Score比较结果Fig.3 Comparison of G-Mean and F-Score 为进一步说明本文所提模型对于异常类样本检测的准确率,运用训练得到的改进DM-SVDD异常检测模型对测试数据中14组数据进行检测,其中正常类样本数据3组,异常类样本数据11组,检测结果如图4所示。图中水平直线代表判别阈值,表示模型训练得到超球面后,球面距离球心的距离;样本2-5、7-14的检测输出大于判别阈值,判断为异常类样本,样本1、6的检测输出小于判别阈值,判断为正常类样本,除样本3存在误差以外,其余测试结果均与实际情况相符,表明改进的DM-SVDD模型能够有效实现产品的异常检测。 图4 改进DM-SVDD模型测试结果Fig.4 Test results of the improved DM-SVDD model 本文提出了一种改进的基于DM-SVDD的异常检测新模型。DM主要用于特征降维,针对数据中存在的数值型和字符型两种类型数据,采用两种距离度量方法改进降维过程;SVDD主要用于不平衡数据异常检测。实验结果验证本文所提模型在多晶硅铸锭异常检测中的有效性,可用于指导类似的实际工业生产,发挥降低生产成本,提高产品质量的作用。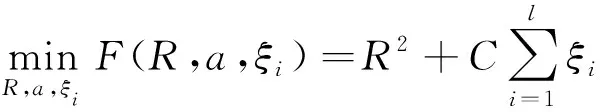
2 改进的DM-SVDD异常检测模型
2.1 数据集

2.2 改进的DM-SVDD异常检测模型

3 实验设计及结果分析
3.1 实验设计及评价指标
3.2 实验结果分析


4 结束语
