油藏注采参数实时优化研究
——以滨南油田滨2断块沙二段油藏为例
2021-09-21王跃刚
王跃刚
(中国石化胜利油田滨南采油厂,山东滨州 256600)
滨一区滨2块位于东营凹陷西北边缘,滨南—利津二级断裂带东段,北依滨县凸起,东南临利津凹陷,西接滨二区。研究区面积约19 km2。滨2断块主力含油层段为沙二段,厚度约170~240 m,为一套砂泥岩组合沉积,纵向上整体为一正旋回,砂体由西向东,由南向北逐渐加厚,粒度逐渐变粗,泥质隔层发育稳定,总体由南向北隔层厚度减薄。滨2块油藏埋深2 100~2 560 m,主力含油层系沙二段含油面积3.8 km2,有效厚度12.5 m,平均孔隙度24%,平均渗透率806×10-3µm2,地质储量581.02×104t,是一个中孔高渗受断层控制的构造-岩性油藏。
滨2断块自1968年5月试采开发至今,主要经历了弹性开采、注水开发、加密井网、产量递减和注采调整等五个阶段,高峰期日产油能力201 t/d,1981年进入中高含水期,目前产量呈规律性递减。目前油井数21口,开井19口,水井数14口,开井13口,日产液能力262 t/d,日产油能力47.5 t/d,单井日产液13.8 t/d,单井日产油2.5 t/d,日注水204 m3/d,年产油1.5×104t,采油速度0.25%,综合含水81.8%,累计产油139.7×104t,采出程度17.68%,处于中采出程度、低采油速度和中高含水开发阶段。
为了优化滨2断块整体注采结构,提高区块最终采收率,提出了开展注采参数实时优化的需求。主要包括建立精细三维地质模型,开展历史拟合及剩余油分布规律研究,根据基于Eclipse数值模拟软件的生产优化控制模型,利用优化算法和数值模拟完成目标区块油水井动态调控参数的优化方案。优化完成注采参数实时调配,保障调整方案最优化。
1 精细三维地质模型建立
研究区构造模型的建立采用井震结合解释了沙二段4砂组各小层顶面构造,在顶面构造图以及断层分布的基础上,根据单井地层对比结果以及层序划分,依次绘制从4砂组上1小层顶面到4砂组下5小层底面共9个层面的构造图[1-5](见图1)。针对每个砂体的内部进行网格平面细分,纵向网格厚度为0.83 m,能够刻画砂体中的夹层分布。
研究区的沉积相模型首先从单井的沉积相识别开始,根据研究的测井曲线特征以及沉积相分析,采用神经网络判别储层类型,再通过辅助手工单井调整的方式完成单井相的划分。在此基础上,根据研究区前期的物源方向研究,以及单井砂体的分布特征,采用序贯指示高斯模拟的方法,完成沉积相模型的建立。提取各砂层组的砂岩计算每个砂层组的砂体厚度以及油层有效厚度。在沉积相模型的基础上,采用相控建模方式,建立孔隙度模型,并对每种沉积岩相的孔隙度范围进行约束和控制。提取模型中的储层岩性中砂岩和细砂岩,分别作出各砂层组的有效孔隙度分布。在沉积相模型和孔隙度模型双重控制约束的基础上,分岩相建立孔隙度约束下的渗透率模型;分岩相根据阿奇公式以及油水界面J函数的确定,结合现场探井的实验室数据,完成针对每种沉积岩相和孔隙度约束下的饱和度模型。在模型中根据研究范围以及油水界面,结合模型中的孔隙度、净毛比、饱和度模型全面计算了研究区的地质储量。通过模型计算,储量为581.02×104t,储量分布与沉积相、储层厚度、孔隙度以及饱和度的分布具有很好的对应性。
2 历史拟合及剩余油分布规律
本次数值模拟利用Petrel建模软件输出的地质模型,选用黑油模型,用Eclipse软件进行数值模拟。滨2断块油藏流体性质差异不大,基本一致,采用一套流体系统,原油体积系数1.15;饱和压力8.38 MPa;地层原油密度0.797 g/cm3;脱气原油密度0.884 g/cm3;地下原油黏度4.37 mPa·s。油水相对渗透率利用滨65、滨97、滨124井样品分析资料,经过处理形成该工区共有的相渗曲线。数值模拟研究时间从该油藏投入正式开发时间1986年1月起,至2020年4月,以每个月为一个研究时间步长,合计412个时间步长。本次数值模拟共研究该区59口井的生产历史。利用Eclipse的Schedule模块处理射孔数据、动态历史、井轨迹、层位关系、时间步设定等文件,生成该区的动态模型。
区块瞬时生产指标包括日产油、含水等。本次模拟油井采用定液生产,区块产量指标拟合好坏主要受油井含水变化规律的影响。区块及单井拟合情况较好,可作为下步方案预测的基础(见图2)。
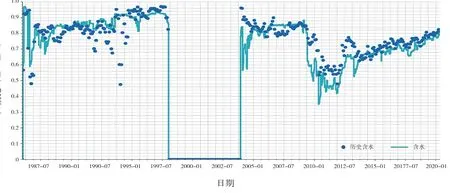
图2 滨2块含水拟合曲线
平面上剩余油分布主要受构造高低、储层厚度、注采井网完善程度、边底水活跃程度及储层物性等多因素综合影响。一般来说,构造高部位剩余油富集;储层厚度大的区域因原始物质基础丰富而剩余储量多;注采井网不完善区油层水淹轻,剩余油相对富集;注采井网完善,储层物性好的区域油层水淹严重,剩余油少;边水活跃油藏边部区域油层强水淹,无潜力可挖;底水活跃油藏水锥现象普遍,采油井附近油层中下部水淹严重,顶部仍然富集一定的剩余油,剩余油主要分布在井间。从层内来看,油层顶部剩余油较为富集;受重力分异影响,水淹程度由下向上逐渐减弱,油层顶部水波及程度较低,是剩余油的主要挖潜区(见图3)。
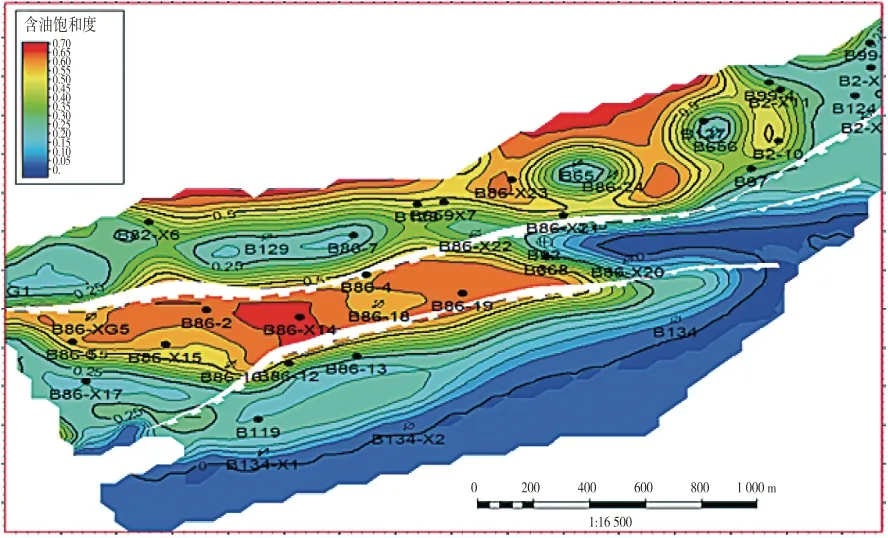
图3 沙二段4砂组上1小层剩余油饱和度
3 基于Eclipse数值模拟的油水井动态参数快速优化软件
筛选出适合油水井动态调控参数优化软件的优化方法,能适应基于数值模拟软件开展目标区块的动态调控优化。研制的动态调控优化程序能够调用和兼容Eclipse软件系统,程序按模块化设计,主要框架结构为:初始化模块、数据接口模块、参数优化模块、数模软件运行控制及优化目标值计算模块和优化结果输出模块等五个模块。
3.1 初始化模块设计
初始化模块主要完成三项功能:文件及工作目录设置、成本计算配置以及优化参数配置等。
3.1.1文件及其工作目录的设置
完成DATA数据文件名、SCH文件名、FIELD场数据文件名、初始计划文件名、注水门限文件名、产液门限文件名以及注水压力门限文件名的设置。这些文件名都保存在CStirng类变量中。
3.1.2成本计算配置
因为注采优化的目标是净现值,净现值的计算中要用到“油价”、“污水处理成本”和“注水成本”等参数,净现值的计算公式为:
净现值=产油量*油价-注水量*注水成本-污水量*污水处理成本
3.1.3优化参数配置
根据对优化算法的筛选,软件采用的优化算法是:拉丁超立方采样+进化计算+同步扰动,为便于用户控制软件运行时间,用户能在界面中输入优化用的相关参数:
开始时间:为优化的起始时间,最终通过修改Eclipse相关文件的内容实现;
时间步长:输入Eclipse运行的时间步长,以月为单位。一般设置为1个月、3个月、6个月等,也是通过修改Eclipse相关文件的内容实现;
优化时长:优化的时间总长度,该值应该是时间步长的整数倍;
种群大小:为偶数,不低于4,设置越大,优化所需时间越长,优化效果越好。
3.2 数据接口模块设计
数据接口模块主要实现程序和Eclipse软件所使用的数据体数据读取和修改,由CDataPort类来实现这些功能。该接口类主要实现:
(1)注采变量门限值的读入;
(2)Eclipse注采计划的更新;
(3)目标函数(净现值)的读取。
3.3 参数优化模块设计
参数优化算法为:拉丁超立方+进化计算+同步随机扰动[6-8]。
3.3.1拉丁超立方采样
对于每一个不确定参数,实现拉丁超立方采样有三个要点:一是参数的概率分布,二是参数的分段情况(即bin),三是拉丁超立方采样的点数。采用拉丁超立方产生单变量值的流程如图4所示。首先对变量值分段,然后产生随机的段号,确定参数值所在的段号,最后按照某种概率,在该段内随机产生一个值,即所求的单变量值。
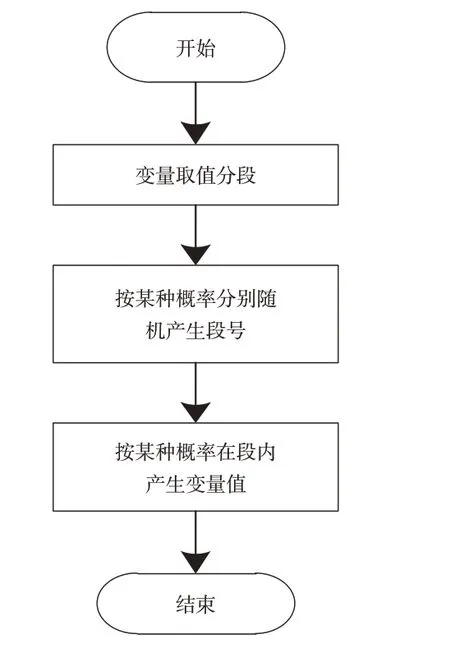
图4 拉丁超立方产生单变量值流程
3.3.2进化计算
使用拉丁超立方得到的初始参数作为进化计算的第一代种群,再使用非梯度类的进化计算进行优化,这样做的好处是在优化初期,尽量扩大搜索范围,使优化算法不至于很快陷入局部极值点。进化算法是由CGa类来实现,其基本流程参见图5。首先对新种群计算适应度,然后判断是否满足退出优化算法的条件,一般设定为进化代数是否达到设定的总进化代数。如果满足退出条件,则退出优化算法,输出最优个体;如果不满足,则以当前种群作为父代,通过选择、交叉和变异操作,产生新的种群,再计算其适应度,直到满足退出条件。
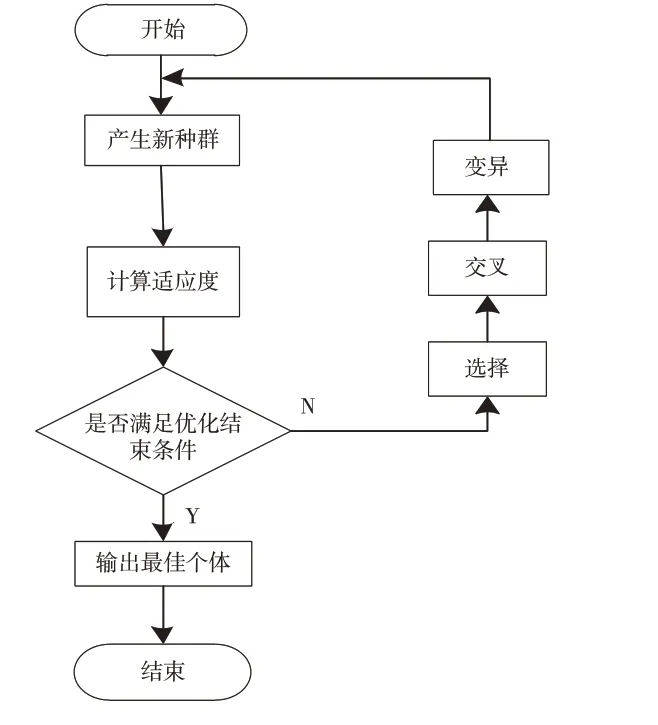
图5 进化计算流程
3.3.3同步扰动随机逼近算法SPSA
在优化计算后期,为了尽快收敛,采用适合多变量寻优的同步扰动随机逼近(SPSA)算法,通过估计目标函数的梯度信息来逐步逼近最优解。每次梯度逼近只用两个目标函数估计值,与优化问题的维数无关,从而大大减少了用于估计梯度信息的目标函数的测量次数,因此SPSA算法常用于解决高维问题以及大规模随机系统的优化。
SPSA求解采用“近似梯度”来不断修正搜索方向,以逐步接近最小值。该方法的特点是能够求解大量参数的最优化问题,运算量相对大幅减小。软件中使用CSpsa类来实现SPSA功能。
3.4 数模软件运行控制及优化目标值计算模块
从优化模块得到注采参数后,即投入模拟器运行,当Eclipse运行结束后,通过接口模块中的函数,得到目标函数值。
3.5 优化结果输出模块
优化结果的输出就是把每一个时间步得到的优化的注采制度数据保存在指定文件中,最终形成所有时间点的注采制度。
4 方案设计
根据剩余油分布规律,设计了两套方案,预测至2025年5月1日,方案设计见表1。

表1 方案设计
基础方案:在目前产液量和注水量下预测5 a。
优化方案:优化间隔时间设为3个月,预测5 a。
单井注水(0~200 m3/d)优化注水,产液量(0~100 m3/d)优化产液。
5 注采方案优化
完成了目标区块油水井动态调控参数的优化[9-13],确定了油水井最优日产液量和日注水量(见表2~3),基础方案和优化方案预测指标对比见图6~8,优化方案累计产油25.21×104m3,比基础方案增加14.81×104m3,采出程度提高3.01%(见表4),优化后驱替更均匀,剩余油饱和度更低(见图9~10)。
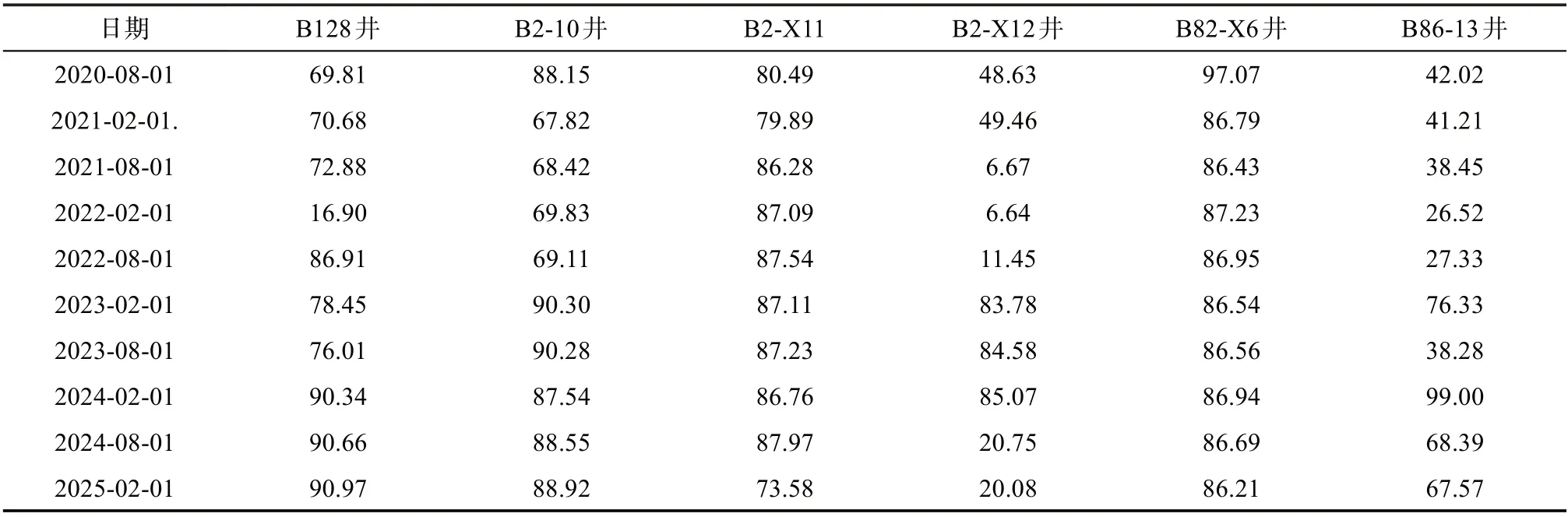
表2 油井优化日产液量 m3/d
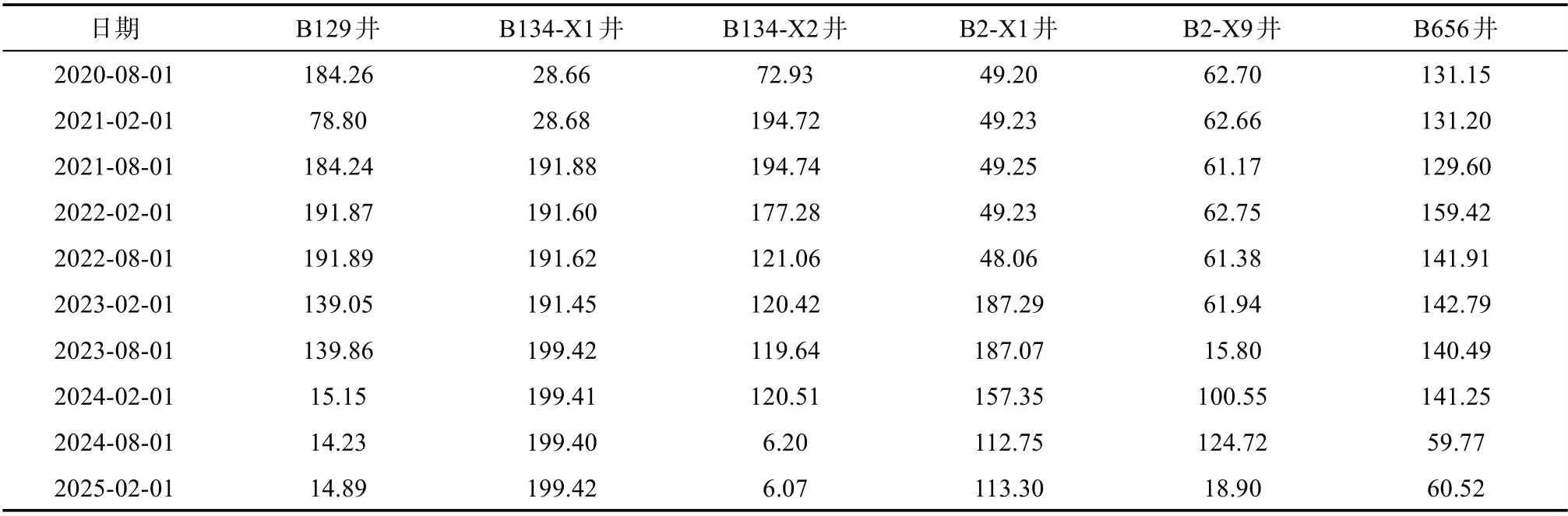
表3 水井优化日注水量 m3/d
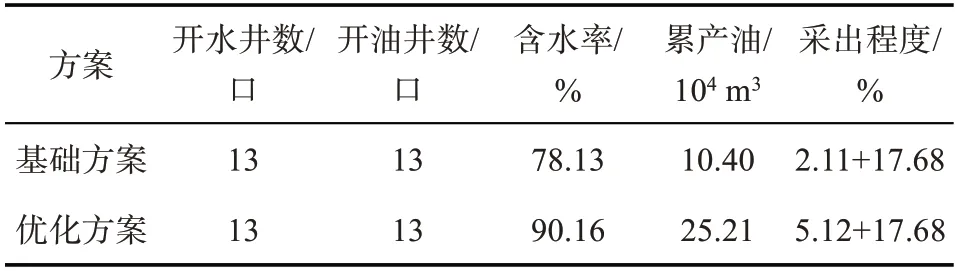
表4 优化前后方案指标预测对比
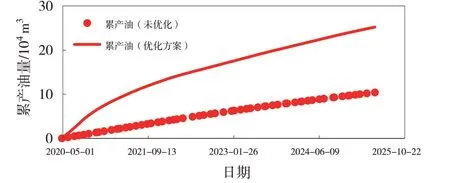
图6 优化前后累产油对比
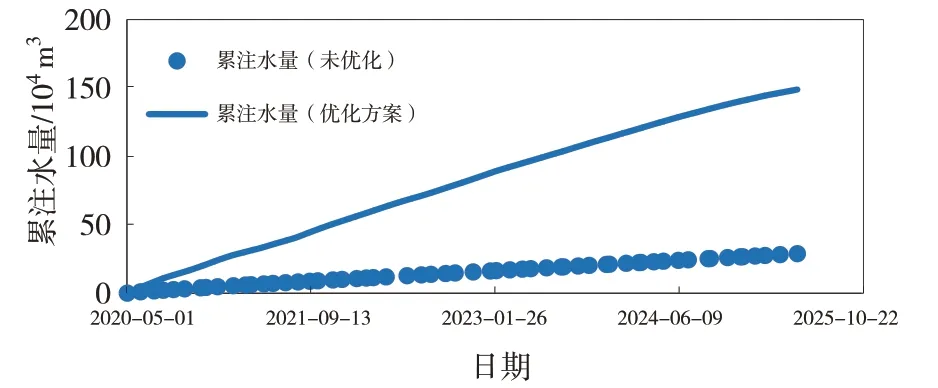
图7 优化前后累注水对比
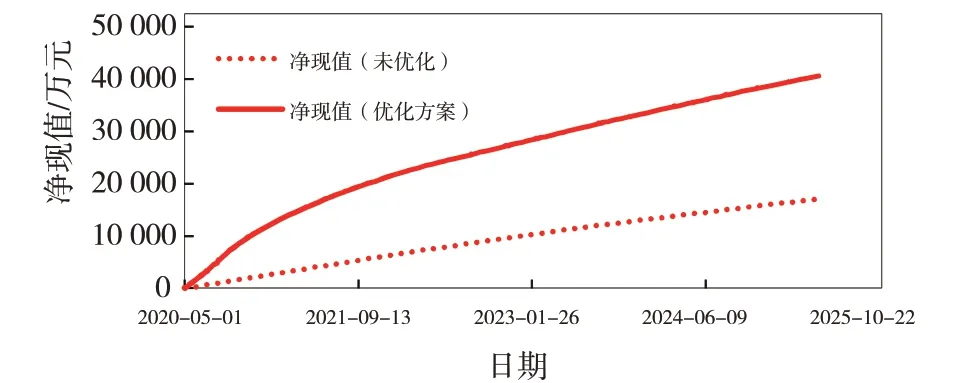
图8 优化前后净现值对比
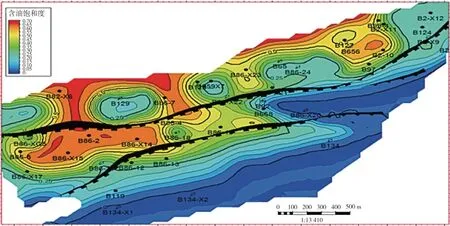
图9 基础方案剩余油饱和度
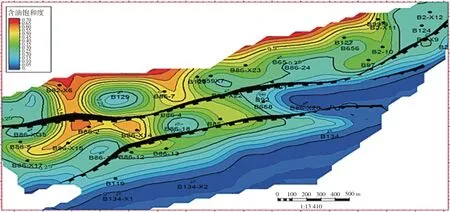
图10 优化方案剩余油饱和度
6 结论与认识
(1)在精细地质综合研究的基础上,建立了精细三维地质模型,完成了研究区块油水井数值历史模拟,模型历史拟合率90%,动静态模型吻合。
(2)根据数值模拟和剩余油分布研究结果,该区块采出程度低,剩余油潜力大,构造高部位是下步挖潜的主要区域。
(3)建立了基于系统控制理论和Eclipse数值模拟软件的生产优化控制模型。针对该模型变量维度高、计算一次目标函数时间长、目标函数非线性等特点,从众多算法中筛选出最优化算法,程序运行验证了算法的有效性和科学性。
(4)利用油水井动态优化控制模型和优化算法软件完成了研究目标区块油水井动态调控参数的优化,优化方案预测累计产油量为25.21×104m3,比基础方案累计产油量提高14.81×104m3,采出程度提高3.01%,预测经济效益2.3亿元。
