高速铁路非正常事件下初始延误场景聚类研究
2021-09-18张俊张欣愉叶玉玲
张俊 张欣愉 叶玉玲


摘 要:在高速铁路日常行车组织工作中,及时准确地把握高速铁路非正常事件下的延误特征和事件分级是后续运行调整决策的基础。文章面对高速铁路非正常事件扰动,基于多源历史数据提取并分析初始延误场景参数特征,筛选初始延误时长和线路列车服务频率作为两个聚类指标,并应用轮廓系数论证FCM模糊聚类对当前场景的适用性。根据最终聚类结果,区间和车站非正常事件分别被聚为4类和3类。提出的聚类指标易于量化,非正常场景聚类分级结果能为实际延误管理工作提供有效支撑。
关键词:高速铁路;非正常事件;延误管理;场景分析;FCM聚类
中图分类号:U292.4 文献标识码:A
Abstract: During the daily train organization of high-speed railway(HSR), grasping the delay characteristics and event classification timely and accurately is the basis of subsequent rescheduling decisions. Faced with the disturbance of HSR abnormal events, this paper first extracts and analyzes the parameter characteristics under primary delay scenarios based on multi-source historical data, then selects the primary delay and line service frequency as two clustering indicators, and validates the applicability of Fuzzy C-Means(FCM)clustering to current context via silhouette coefficient. According to the final clustering results, the abnormal events of section and station have been classified into 4 levels and 3 levels respectively. The proposed clustering indicators are easy to quantify, and the clustering results of abnormal events can provide effective support for the actual work of delay management.
Key words: high-speed railway; abnormal event; delay management; scenarios analysis; FCM clustering
0 引 言
在高速鐵路网络化运营发展背景下,列车、站点和线路之间的相互关联性不断加强,受运输组织方案复杂性、实时列车调度动态性和场景因素的不确定性影响[1],日常运输过程中的非正常事件不可避免。做好非正常事件的分级工作有助于完善延误管理体系、辅助运行调整决策。现行铁路相关规范标准主要依据伤亡人数、经济损失、中断行车时间等指标对突发事件进行了分级,但是这些标准多针对恶性强扰动的突发事件,而对于日常运输组织过程中相对高频弱扰动的非正常事件则不具备适用性。因此,开展高铁非正常事件延误场景聚类研究对提升日常运输组织管理水平具有较为重要的现实意义。
高速铁路非正常事件引起的列车运行延误包括初始延误和连带延误两种[2],初始延误为受非正常事件直接影响产生的时刻表偏差,连带延误则是在延误传播过程中为疏解行车冲突而产生的时间代价[3]。相关文献表明连带延误与初始延误场景特征之间存在一定的相关性[4-5],因此本文以高速铁路非正常事件下的初始延误场景为对象,研究初始延误场景属性参数的分布特征,综合比选K-means、FCM模糊聚类和DPC密度聚类等聚类方法,分别对车站、区间非正常事件延误场景进行聚类研究,实现延误分级管理。
1 数据采集
1.1 数据来源
本文研究所需数据内容主要包括延误信息数据和运行图数据两种。其中,非正常事件信息来源于高速铁路安监系统平台相关数据,选取2018至2019年时段内部分高铁线路的延误记录信息进行分析,延误信息数据以文本形式记录了产生非正常事件的线路、车次、位置、处置策略及实际影响等信息;运行图数据则根据调图文件获取对应高铁线路区段上的时刻表信息,主要用于提取初始延误产生时刻对应的线路运输服务状况。
1.2 数据预处理
(1)延误信息数据处理
为便于后续聚类研究,需要有针对性地提取其中与初始延误相关的参数,并对其中部分参数进行一定的修正。通过文本提取共筛选出以下6类属性:
①所处线路:初始延误所处的高铁线路名称;
②发生时刻:产生初始延误的时刻,采用24h制;
③事件致因:造成非正常事件的原因,主要包括车载设备故障、车站设备设施故障、区间设备设施故障、异物入侵、环境影响、旅客异常和超员报警7类;
④事件位置:发生在车站或区间,0-1变量,0表示区间,1表示车站;
⑤应急措施:非正常事件发生后采取的应急措施,主要包括车站超停、车站临停、区间临停、始发晚点、局部限速、区间封锁、投用热备车组以及相关组合措施等;
⑥初始延误时长:首列受非正常事件影响的车次产生初始延误,不同于事件持续时长,单位:min。
(2)时刻表数据处理
时刻表数据主要用于提取初始延误场景下的列车服务频率(单位:列/h),结合前述延误信息中的所处线路、发生时刻和事件位置,从既有时刻表信息中计算对应时空位置的列车服务频率,形成对非正常事件延误场景特征参数的补充。
2 场景特征分析
2.1 初始延误分布
通过数据采集和处理,共获取有效初始延误场景样本501条。在高速铁路非正常事件初始延误时长分布上,根据处理后的样本数据可知该时长从1~175min不等。据统计,33.1%的初始延误在10min以下,35.5%的初始延误位于(10,20]min区间内,13.5%的初始延误位于(20,30]min区间内,8.2%的初始延误位于(30,40]min区间内,40min以上的初始延误占比约9.6%。
2.2 发生时刻及事件致因分布
综合考虑非正常事件的发生时刻和事件致因进行分析。在发生时刻分布上,高速铁路非正常事件多集中于8:00~20:00时段内,8:00之前以及20:00之后非正常事件的数量占比较少,同时在12:00~16:00时段内的平均初始延误相对其他时段较高;在事件致因分布上,车载设备故障的发生概率最高,异物入侵、车站和区间设备设施故障的发生概率次之,其他事件致因的发生概率较小。
2.3 发生位置及处置措施分布
在501起高速铁路非正常事件样本中,有303起分布在区间,占比约60.5%;有198起分布于车站,占比约39.5%。其中,区间非正常事件以采用区间临停措施和区间临停+局部限速组合措施这两种为主,累计占比为81.4%;车站非正常事件以采用车站超停、始发晚点和区间临停措施为主,累计占比约72.6%。
2.4 事件致因与初始延误相关性
对不同事件致因下的初始延误影响进行分析,如表1所示。在7类非正常事件致因中,旅客异常和超员报警的发生概率最小,分别为1.2%和1%,对应的平均初始延误也最低;环境影响导致的行车异常概率也极小,约为1.6%,但是其对应产生的平均初始延误较高;车站设备设施故障和区间设备设施故障发生的概率较高,但前者产生的平均初始延误高于后者;车载设备故障发生的概率最高,约为54.5%,对应的平均初始延误较低。
3 聚类方法比选
3.1 聚类指标
从初始延误场景特征参数集合中选取量化且独立的数值型属性作为聚类指标。已量化的参数有初始延误、发生时刻、发生位置、服务频率这4种,其中由于服务频率是基于所处线路、发生时刻和事件位置综合得出,因此剔除发生时刻指标,而发生位置為0-1逻辑变量,因此本文将分别针对区间和车站延误场景,根据初始延误时长和服务频率指标进行二维聚类。
3.2 聚类方法
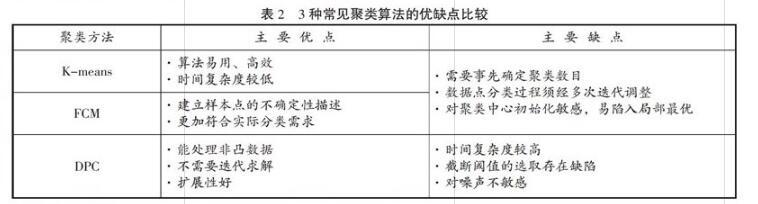
为寻找适用于当前应用场景指标样本集合的聚类方法,在对常用的K均值聚类(K-means)、模糊均值聚类(FCM)和密度峰值聚类(DPC)算法的适用性和优缺点进行分析,如表2所示。其中FCM是对传统K-means硬聚类算法的改进,两者均属于优化迭代型算法;DPC则是属于基于密度的空间聚类算法[6]。
3.3 聚类方法适应性
(1)聚类轮廓系数
轮廓系数(Silhouette Coefficient)可用于对聚类方法及聚类数量合理性进行综合验证[7]。轮廓系数综合考虑了各个分类簇的内部聚合程度以及不同簇之间的分离程度,可对不同聚类数目或聚类算法的结果优劣进行评价。轮廓系数计算步骤如下:
①对于分类结果,根据所采用的距离公式计算样本i到同簇C中其他样本的平均距离a,即样本i的簇内不相似度;
②计算样本i与其他簇C中所有包含样本的平均距离b,即样本i的与簇C的不相似度,进而可得样本i的簇间不相似度b,计算公式如下:
b=minb|j=1,2,…,K (1)
③根据前两步计算得出的样本i的簇内不相似度a和簇间不相似度b,则样本i的轮廓系数S为:
=?圯s= (2)
(2)聚类方法适应性
根据轮廓系数对样本i的聚类结果合理性进行分析。若s越接近于1,表明样本i的分类越合理;若s越接近-1,表明样本i越应当归类至其他簇C中。以区间非正常事件样本进行测试分析可得,对于K-means和FCM而言,聚类数为4时的样本轮廓系数中的负值数量及数值大小均低于聚类数为5时的样本轮廓系数分布,对应的聚类效果也较优;同时根据两种算法的轮廓系数分布可知,当聚类数量为4时,FCM的聚类效果优于K-means聚类。对于DPC而言,由于部分孤点的存在导致不同类别的数量差异过大,且轮廓系数中的负值达到-0.65,从其轮廓系数分布表现来看不如K-means和FCM聚类,代表性FCM和DPC轮廓系数分布如图1所示。综上,选择FCM作为高铁延误场景聚类算法。
4 聚类结果分析
4.1 初始延误场景聚类
通过应用FCM聚类并结合轮廓系数分布验证,样本数据集中303起高速铁路区间非正常事件被聚为4类,198起车站非正常事件被聚为3类。图2展示了区间延误场景的4类样本数据的分布和迭代优化过程,图3展示了车站延误场景下3类归一化后样本数据点的模糊隶属度分布。
4.2 非正常事件延误场景聚类结果分析
如表3所示,对区间非正常事件而言,第4类、第1类和第2类的占比较高,对应的比例依次为37.3%、28.7%和25.7%;对车站非正常事件而言,第3类和第1类的占比均较高,对应的比例分别为41.9%和38.4%。在服务频率和初始延误的参数特征的取值分布上,各类型的非正常事件有着明显不同于其他类型事件的主要分布区间,且不同类型非正常事件之间既互补又存在一定的交叉融合。高速铁路非正常事件聚类结果如表3所示。
5 结 论
本文基于历史非正常事件记录,提取延误场景相关的参数并分析相关特征分布,基于此筛选聚类指标并通过算法比选最终采用FCM进行聚类研究,分别分析了车站和区间各级非正常事件场景特征和行车影响,能为相关延误预测和动态行车调度提供参考。
后续研究将进一步结合事故致因和应急措施细化延误分级和特征识别工作,并对比基本运行图和实际运行图数据分析不同场景下的连带延误的传播特性[8],以期充分解析高速铁路列车延误的传播机理,并为动态列车调度提供辅助决策。
参考文献:
[1] Goverde R M P. Railway timetable stability analysis using max-plus system theory[J]. Transportation Research Part B: Methodological, 2007,41(2):179-201.
[2] 袁志明. 复杂线路列车晚点控制优化策略及方法[D]. 北京:中国铁道科学研究院(博士学位论文),2016.
[3] 文超,彭其渊,陈芋宏. 高速铁路列车运行冲突机理[J]. 交通运输工程学报,2012,12(2):119-126.
[4] Carey M, Kwieciński A. Stochastic approximation to the effects of headways on knock-on delays of trains[J]. Transportation Research Part B: Methodological, 1994,28(4):251-267.
[5] 张琦,陈峰,张涛,等. 高速铁路列车连带晚点的智能预测及特征识别[J]. 自动化学报,2019,45(12):2251-2259.
[6] 王洋,張桂珠. 自动确定聚类中心的密度峰值算法[J]. 计算机工程与应用,2018,54(8):137-142.
[7] 朱连江,马炳先,赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用,2010,30(S2):139-141.
[8] 孟令云,Goverde R M P. 基于实际数据分析的列车晚点传播过程构建方法与实例[J]. 北京交通大学学报,2012,36(6):15-20.
