舰载云图像识别性能研究
2021-09-18宋达郭海波朱进李宁肖迪张思航
宋达,郭海波,朱进,李宁,肖迪,张思航
(中国舰船研究院,北京 100101)
0 引言
在过去的十几年间,得益于基础硬件计算能力的大幅提升与算法研究的逐步深入,基于深度学习的智能应用在各个领域如计算机视觉、语音识别、自然语言处理等得到了广泛的应用。在军事领域,如水下、水面目标识别、舰船智能运维、态势感知等场景也逐渐开始向智能化发展。由于需要进行广泛的样本学习并获取隐藏特征进行权重更新,深度学习任务大多依赖于强大的算力支持,在不同的硬件支撑平台上实现同样的深度学习任务往往会由于平台算力的差异而导致最终模型的性能有所不同。舰艇云平台资源有限、应用众多,如何优化资源配置而达到最佳效果是应用领域需要衡量的关键课题。业界对于深度学习算法性能的评估,在一定程度上也影响着深度学习的应用与技术发展。目前通用并公认的机器学习(深度学习)基准主要是MLPerf[1]。MLPerf 是一套用于测量和提高机器学习软硬件性能的通用标准,主要用来测量训练和推理不同神经网络所需要的时间。在国内,中国电子技术标准化研究院也制定了《人工智能 深度学习算法评估规范》[2],包含7 个一级指标和20 个二级指标,可在实施评估过程中,根据可靠性目标选取相应指标。本文基于舰载云平台研究在不同的虚拟机配置中,Resnet 模型执行目标识别任务时,每一次迭代更新所花的时间,分析国产化平台与商用平台舰载云中的目标识别应用性能。
1 实验数据及模型
1.1 MNIST 数据集
MNIST 数据集(Mixed National Institute of Standards and Technology database)[3]是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60 000 个示例的训练集以及10 000 个示例的测试集。本文使用MNIST 数据集作为目标识别任务的训练和测试样本。

图1 MNIST 数据集Fig.1 MNIST dataset
1.2 Resnet
Resnet[4]依据CNN 模型和残差学习的理论将神经网络深度拓展到152 层,通过短路机制加入了残差单元,虽然在一定程度上增加了计算量,但对于深度学习网络退化问题有很好的缓解,可以对样本进行更复杂的特征提取。本文使用Resnet 作为目标识别任务的算法模型,其中 Batch size 为128。
1.3 PyTorch
PyTorch 是基于Torch的深度学习框架[5],主要是由Facebook的AI 研究实验室开发。本文使用的PyTorch版本为1.4.0,并在其上实现Resnet。
2 实验结果
训练耗时与收敛速率是评估深度学习模型性能需要特别关注的指
标[6],本文结合这2 个指标,衡量比较在商用服务器和国产服务器上,Resnet 在进行手写体识别时验证集准确率达到98%时,模型训练过程中每轮迭代的耗时情况。由于模型的随机梯度下降过程中收敛速度受初始化权重、正则化方法等因素影响,所以本文重复多次训练试验,取每次实验结果平均值作为最终试验结果。实验所使用的Dell 服务器和海光服务器参数对比如表 1 所示。

表1 商用服务器和国产服务器参数对比Tab.1 Comparison of parameters between commercial servers and domestic servers
2.1 商用服务器测试结果分析
基于商用服务器和国产服务器搭载的舰载云环境,本文按照CPU 核数以及内存的不同,创建20 台虚拟机,操作系统均为银河麒麟(4.4.58),在PyTorch 平台上使用Resnet 模型实现手写体识别,商用服务器上的表现结果如表 2 所示。
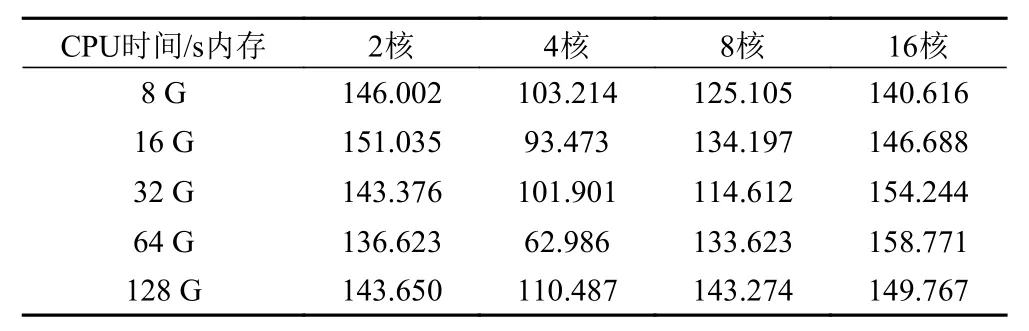
表2 商用服务器上模型在不同虚拟机配置中每次参数迭代所用时间Tab.2 The time cost of each epoch of the model on the commercial server in different virtual machine configurations
在商用服务器上,相同CPU 核数不同内存的虚拟机所用的迭代时间和相同内存不同CPU 核数的虚拟机所用迭代时间的对比图如图 2 和图 3 所示。可以发现,对于商用服务器,并不是虚拟机配置越高每次迭代所花费的平均时间越短。由图 2 可知,对于不同内存的虚拟机,在CPU 核数为四核时,均表现为每次迭代用时最短,其在进行手写体识别的任务中,比两核、八核以及16 核所用的时间少。如图 3 所示,对于两核的虚拟机,内存为64 G 时用时最短;对于四核的虚拟机,内存为64 G 时用时最短;对于八核的虚拟机,内存为32 G 时用时最短;对于十六核的虚拟机,内存为8 G 时用时最短。在商用服务器上,对于一定核数而内存不同的虚拟机配置,在本次实验中其迭代用时的最大最小值之差如表3 所示。对于一定内存而核数不同的虚拟机配置,在本次实验中其迭代用时的最大最小值之差如表 4 所示。可以发现,由于虚拟机核数变化所引起的迭代时间的变化比由于内存变化所
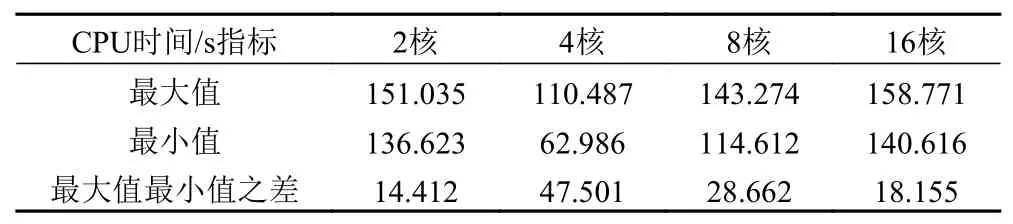
表3 使用商用服务器的一定核数的虚拟机中模型迭代用时最大最小值比较Tab.3 Comparison of the maximum and minimum model iteration time in a virtual machine with a certain number of cores using a commercial server
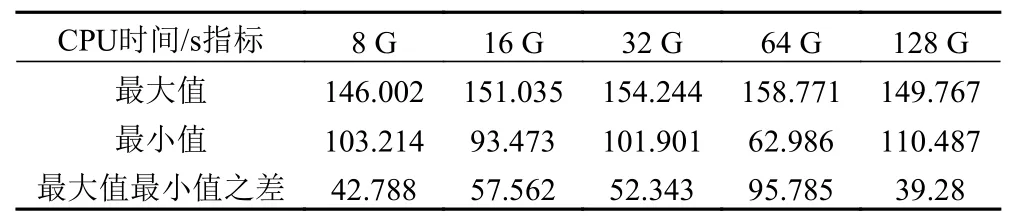
表4 使用商用服务器的一定内存的虚拟机中模型迭代用时最大最小值比较Tab.4 Comparison of the maximum and minimum model iteration time in a virtual machine with a certain memory using a commercial server
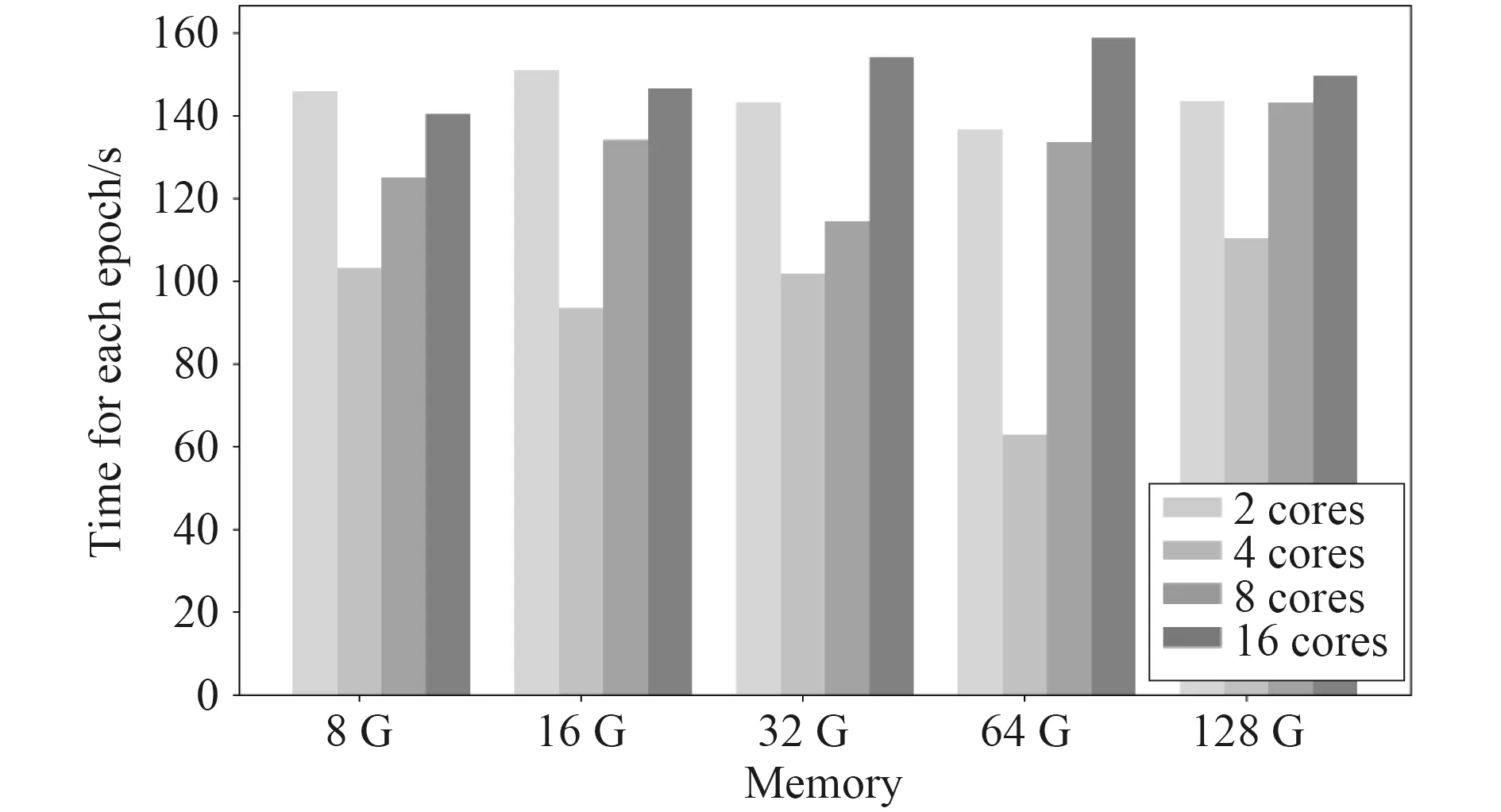
图2 商用服务器上相同CPU 核数不同内存虚拟机平均迭代用时对比Fig.2 Comparison of the average iteration time of virtual machines with the same number of CPU cores and different memory on commercial servers
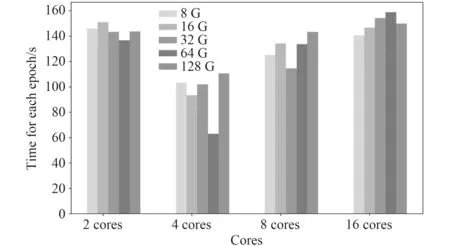
图3 商用服务器上相同内存不同CPU 核数虚拟机平均迭代用时对比Fig.3 Comparison of the average iteration time of virtual machines with the same memory and different CPU cores on commercial servers
引起迭代时间的变化大,迭代用时对于虚拟机核数的变化比较敏感,而对于非四核配置的虚拟机,其对于内存的变化是不敏感的,若要通过改变内存来提升虚拟机上目标识别任务的性能,需要先找到一个“最佳CPU 核数”,并在此基础上对内存进行调优,而这个“最佳CPU 核数”应当取决于云平台虚拟化技术以及所使用的深度学习并行算法。
2.2 国产服务器测试结果分析
在国产服务器上,同样,当ResNet 手写体识别的验证集准确率达到98%时,停止学习,计算这期间每一次迭代更新所用的平均时间作为一次测试结果,之后继续取10 次测试结果的平均值来衡量其目标识别性能。国产服务器上的表现结果如表 5 所示。
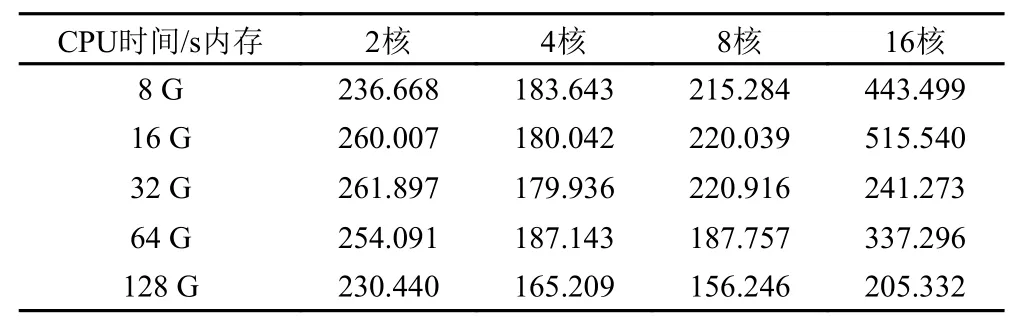
表5 使用国产服务器的模型在不同虚拟机配置中每次参数迭代所用时间Tab.5 The time cost of each epoch in different virtual machine configurations using the domestic server model
在国产服务器上,相同CPU 核数不同内存虚拟机所用的迭代时间和相同内存不同CPU 核数的虚拟机所用迭代时间的对比图如图 4 和图 5 所示。可以发现,对于国产服务器,同样并不是虚拟机配置越高每次迭代所花费的平均时间越短。由图 4 可知,对于不同内存的虚拟机,在CPU 核数为四核时,每次迭代用时均处于较低水平,对于8 G,16 G,32 G 和64 G的虚拟机,在CPU 核数为四核时,得到最短迭代用时,而128 G的虚拟机在核数为八核时取到了最短的迭代用时,也是这20 台虚拟机最短的迭代用时。如图 5 所示,在虚拟机的核数不同时,内存均在128 G 时得到了最短的迭代用时。
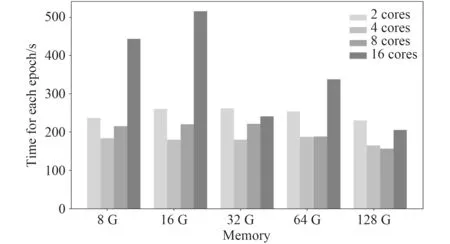
图4 商用服务器上相同CPU 核数不同内存虚拟机平均迭代用时对比Fig.4 Comparison of the average iteration time of virtual machines with the same number of CPU cores and different memory on commercial servers
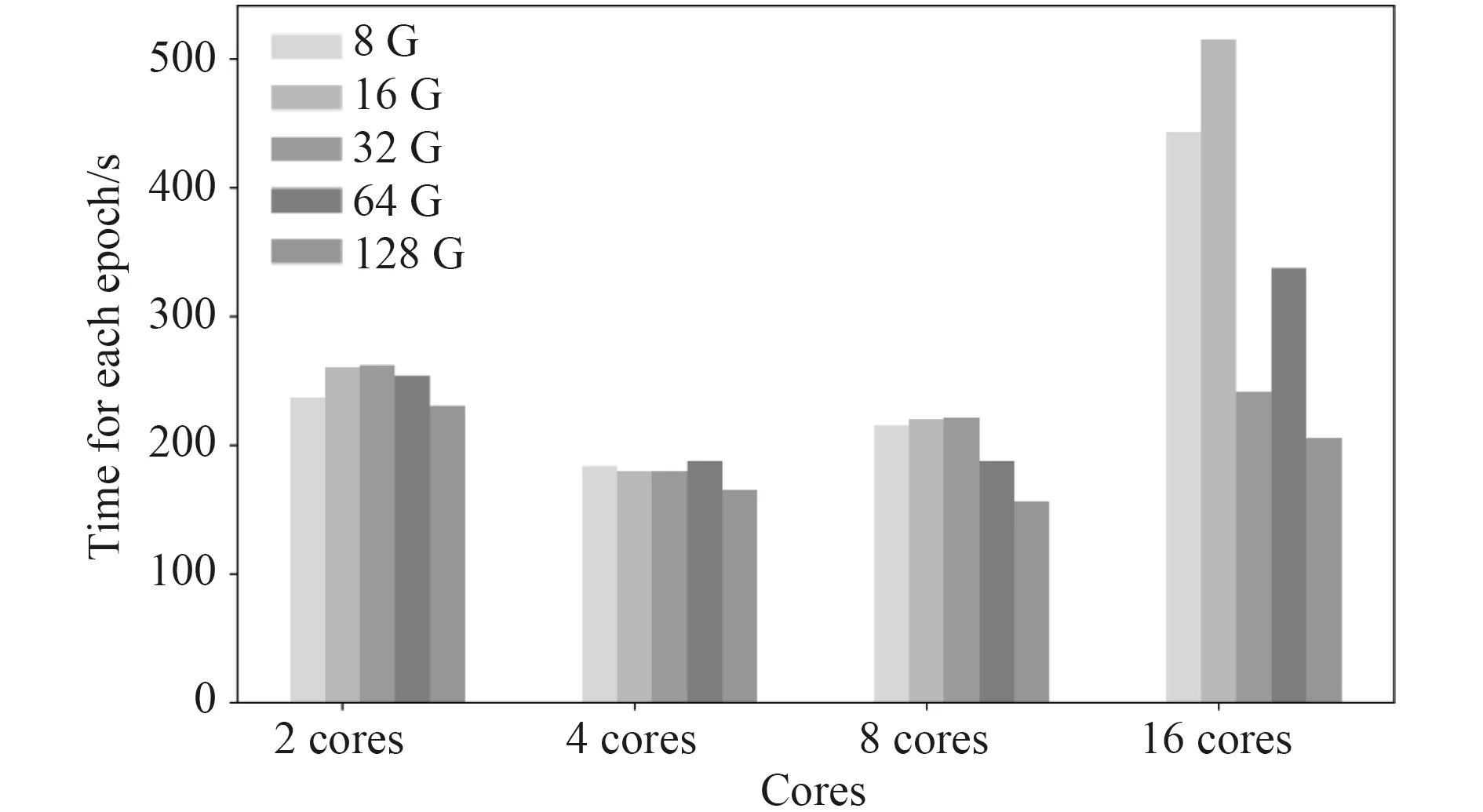
图5 商用服务器上相同CPU 核数不同内存虚拟机平均迭代用时对比Fig.5 Comparison of the average iteration time of virtual machines with the same number of CPU cores and different memory on commercial servers
在国产服务器上,对于一定核数而内存不同的虚拟机配置,在本次实验中其迭代用时的最大最小值之差如表 6 所示。对于一定内存而核数不同的虚拟机配置,在本次实验中其迭代用时的最大最小值之差如表 7所示。由于虚拟机核数变化所引起的迭代时间的变化比由于内存变化所引起的迭代时间的变化大,迭代用时对于虚拟机核数的变化比较敏感。同样在国产服务器上,若要通过改变内存来提升虚拟机上目标识别任务的性能,也需要先找到一个“最佳CPU 核数”,并在此基础上对内存进行调优,而这个“最佳CPU 核数”应当取决于云平台虚拟化技术以及所使用的深度学习并行算法。
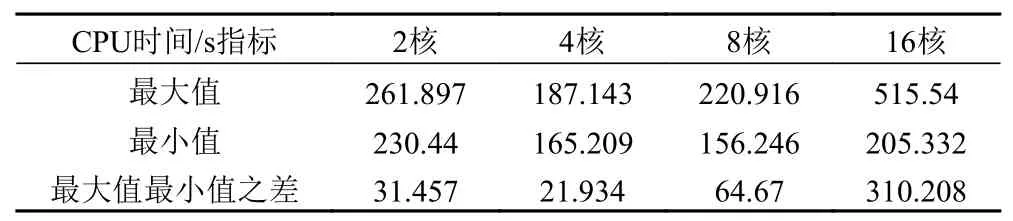
表6 使用商用服务器的一定核数的虚拟机中模型迭代用时最大最小值比较Tab.6 Comparison of the maximum and minimum model iteration time in a virtual machine with a certain number of cores using a commercial server

表7 使用商用服务器的一定内存的虚拟机中模型迭代用时最大最小值比较Tab.7 Comparison of the maximum and minimum model iteration time in a virtual machine with a certain memory using a commercial server
2.3 商用服务器与国产服务器测试结果对比
将表 2 和表 5 中的数据差值统计如表 8 所示,为模型在不同服务器及不同虚拟机配置下的所用迭代时间差。
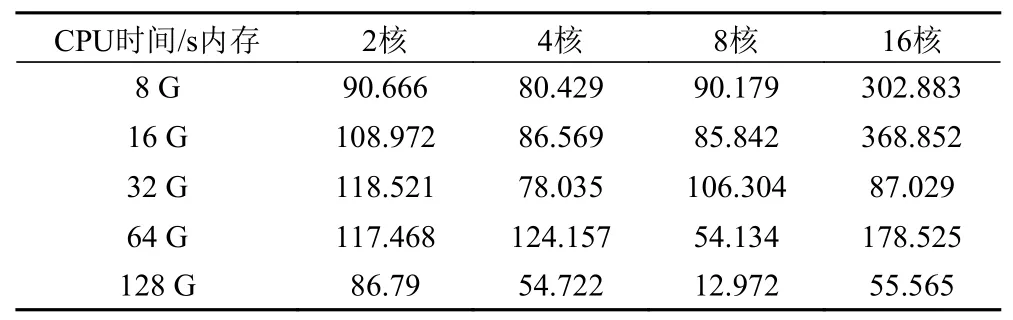
表8 国产服务器上模型在不同虚拟机配置中每次参数迭代所用时间Tab.8 The time cost of each epoch of the model on the domestic server in different virtual machine configurations
如表 8 和图 6 所示,模型在国产服务器和商用服务器中不同虚拟机配置下的所用的迭代时间基本是在使用较大的内存配置时,差距最小,但是差值与内存、CPU 核数的变化并不具有线性关系。
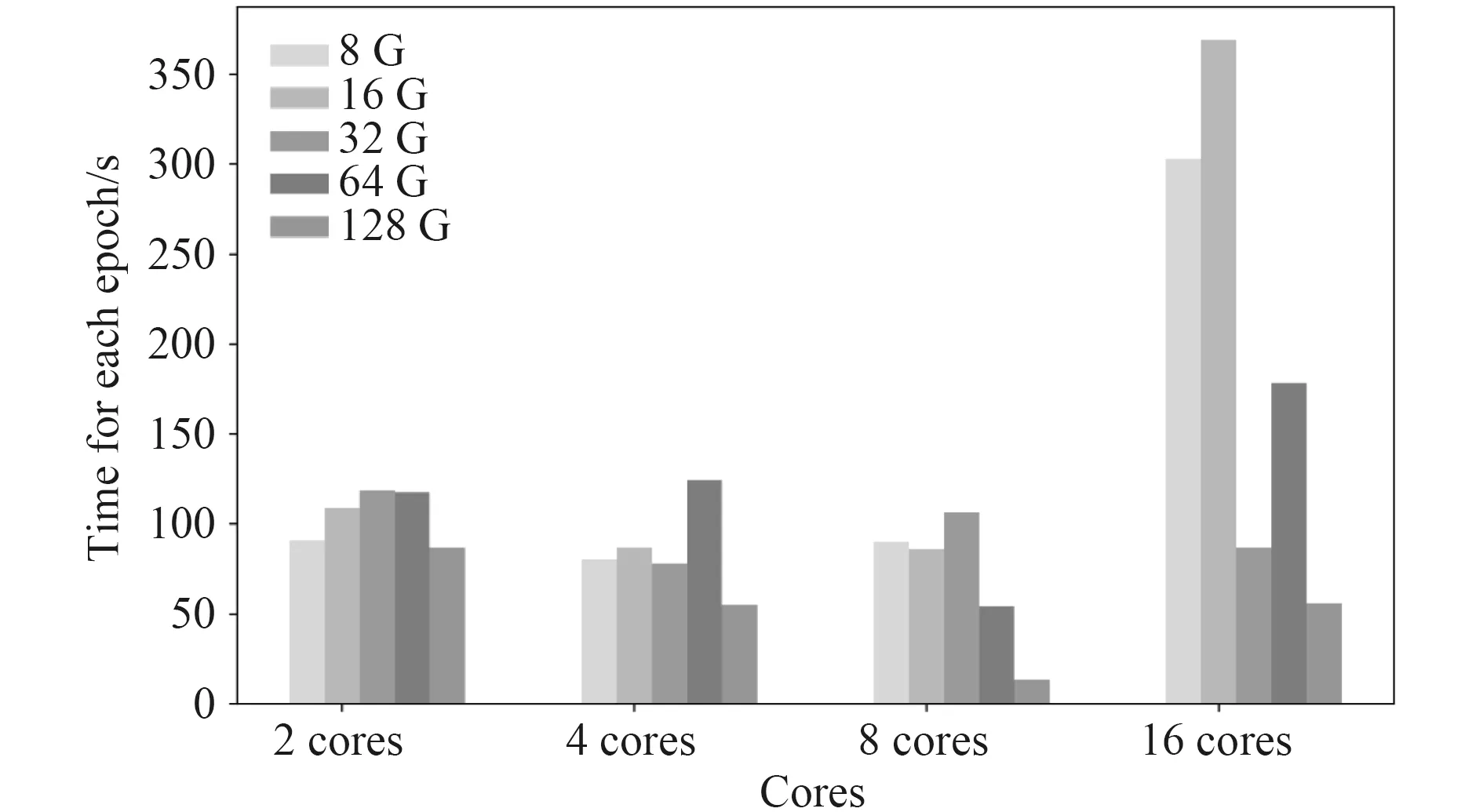
图6 国产服务器上模型在不同虚拟机配置中每次参数迭代所用时间Fig.6 The time cost of each epoch of the model on the domestic server in different virtual machine configurations
3 结语
本文针对基于舰载云虚拟机运行目标识别任务的性能优化问题,分别在国产和商用服务器搭载的舰载云上建立不同CPU 核数以及内存配置的虚拟机,并运行使用Resnet 模型的手写体识别应用,对比分析国产和商用服务器上不同配置的虚拟机在进行目标识别时每次参数迭代更新的平均时间,有如下结论:在国产服务器实验环境中的迭代时间明显低于商用服务器,使用较大内存配置的虚拟机时,这种差距会较为减少;无论是国产化环境还是商用环境,平均的迭代更新时间对于虚拟机的配置,相比较于内存,对于CPU 核数的变化更为敏感,针对不同的智能应用应当存在“最适合的”CPU 核数或是完全可以满足应用的CPU 核数,达到该条件之后,其上的内存配置调优才更有意义。另外,对于智能应用,如何在包括且不限于GPU,FPGA 等异构平台上优化智能应用,充分使用计算资源,也是需要进一步研究的重要课题。
