基于最优模型选择的牧草地上生物量遥感估算研究
2021-09-17郭超凡陈泽威张志高
郭超凡,陈泽威,张志高
(安阳师范学院资源环境与旅游学院,河南 安阳 455000)
牧草地上生物量是指单位面积牧草地上组织所积累物质的质量,是衡量牧草生长发育状态和指导畜牧业生产管理的重要指标[1]。及时、准确的掌握生物量总量、分布及动态变化情况对于草地生态系统评估、全球碳循环研究和草地资源的可持续开发利用等都具有重要意义[2]。
牧草生物量监测方法主要包括直接收获法、产量模拟模型法和卫星遥感估测法等[2],其中卫星遥感估算方法凭借其宏观性、动态性和时效性特点,已成为区域和大尺度牧草生物量监测的重要技术方法[3-4]。卫星遥感估算是指基于影像像元且以植被指数为主要输入变量的数理统计回归方法,通过建立不同尺度数据之间的函数关系实现由点及面的转换。于璐等[5]将高分卫星影像与地面数据相结合,针对不同月份分别筛选最佳反演模型,分析出草场各营养含量月际动态变化规律。渠翠平等[6]对比分析了多种植被指数与草地生物量之间不同形式的拟合关系(线性、乘幂、指数),并利用最优模型完成了内蒙古科尔沁左翼后旗地上生物量与地上地下总生物量精准制图。大量的研究结果表明,卫星遥感估算方法可以较好实现草地生物量精确估算,但由于受遥感数据质量、植被的生长状态、地形以及模型差异等因素的干扰,不同植被指数在不同研究区生物量估算中表现出了不同的结果[7-8]。
基于植被指数构建单变量反演模型是目前生物量估算研究中常用且有效的方法。但在高植被盖度条件下,植被指数对于生物量变化的敏感性显著下降,即出现“过饱和”问题[9],制约模型估算结果的准确性。一些学者尝试通过寻求各种统计方法构建基于多植被指数特征的生物量估算模型。高明亮等[10]比较了多元线性回归模型与单变量非线性模型在植被生物量估算中的潜力,结果表明,多变量反演模型的精度和可靠性高于单变量模型。但是由于多元线性回归模型多存在着变量间多重共线性的问题,容易造成“过拟合”等现象,影响模型的稳定性和普适性[11]。基于机器学习算法构建多元非线性反演模型是近些年兴起的一种新型估算模型,这种方法能够有效地代表多变量复杂的非线性关系,充分利用传感器获得的光谱信息,提高估算精度[12]。其中,随机森林模型(Random forest,RF)由于建模过程简单且结果比较精确、对噪声和异常值敏感度较低,不易出现过拟合、不需要对变量的正态性和独立性等假设条件进行检验等优势被广泛应用于农业、林业、湿地等多个领域定量监测研究[13-14]。以上3种模型是生物量估算中最常见的模型,但3种方法的牧草生物量估算应用对比研究尚不多见。
本研究以Sentinel-2遥感影像数据衍生获取的21种宽波段植被指数作为数据源,以青海省海晏县金银潭草原为研究区,对比分析了单变量模型、多元线性模型和基于随机森林算法的多元非线性模型在牧草地上生物量(湿生)估算研究中的应用价值,并从植被理化特征含义角度探讨了不同植被指数对于牧草生物量估算模型的影响,探索牧草生物量遥感估算的最优模型。研究结果以期为牧草生物量遥感监测提供理论依据,为草地的可持续发展及利用提供数据支撑。
1 材料与方法
1.1 研究区概况
研究区位于青海省海北藏族自治州海晏县境内,地理位置为36°53′30″~37°5′30″ N,100°47′30″~100°59′10″ E(图1),海拔3 000~3 600 m,年日照时间为2 980 h,年均温为1.7℃,年降水量为499 mm,日照时间长,昼夜温差大,多年月均最高温度为10.6℃,最低温度-13.5℃,年均蒸发量为1 581.8 mm,为典型的高原内陆型气候。全县牧草草地面积24.2万hm2,占县域总面积的49.35%,牧草资源丰富,草种类型多样,是环青海湖现代高效畜牧业重要生产基地、环湖地区重要畜产品集散地。成功列入国家现代农业示范区、国家级一二三产业融合发展试点县、国家畜牧业绿色发展示范县、全国草地生态畜牧业实验区。草地类型以高寒草甸类、高寒草甸草原类和温性草原3大类型草地为主。研究区包含冬春草场和夏秋草场,研究区内植被分布较为均匀,混杂分布着高山嵩草(Kobresiapygmaea)、草地早熟禾(PoapratensisLinn.)、矮嵩草(KobresiacuneataKukenth.)、紫花针茅(StipapurpureaGriseb.)、异针茅(StipaalienaKeng)、珠芽蓼(PolygonumviviparumLinn.)、条叶垂头菊(CremanthodiumlineareMaxim.)等物种。
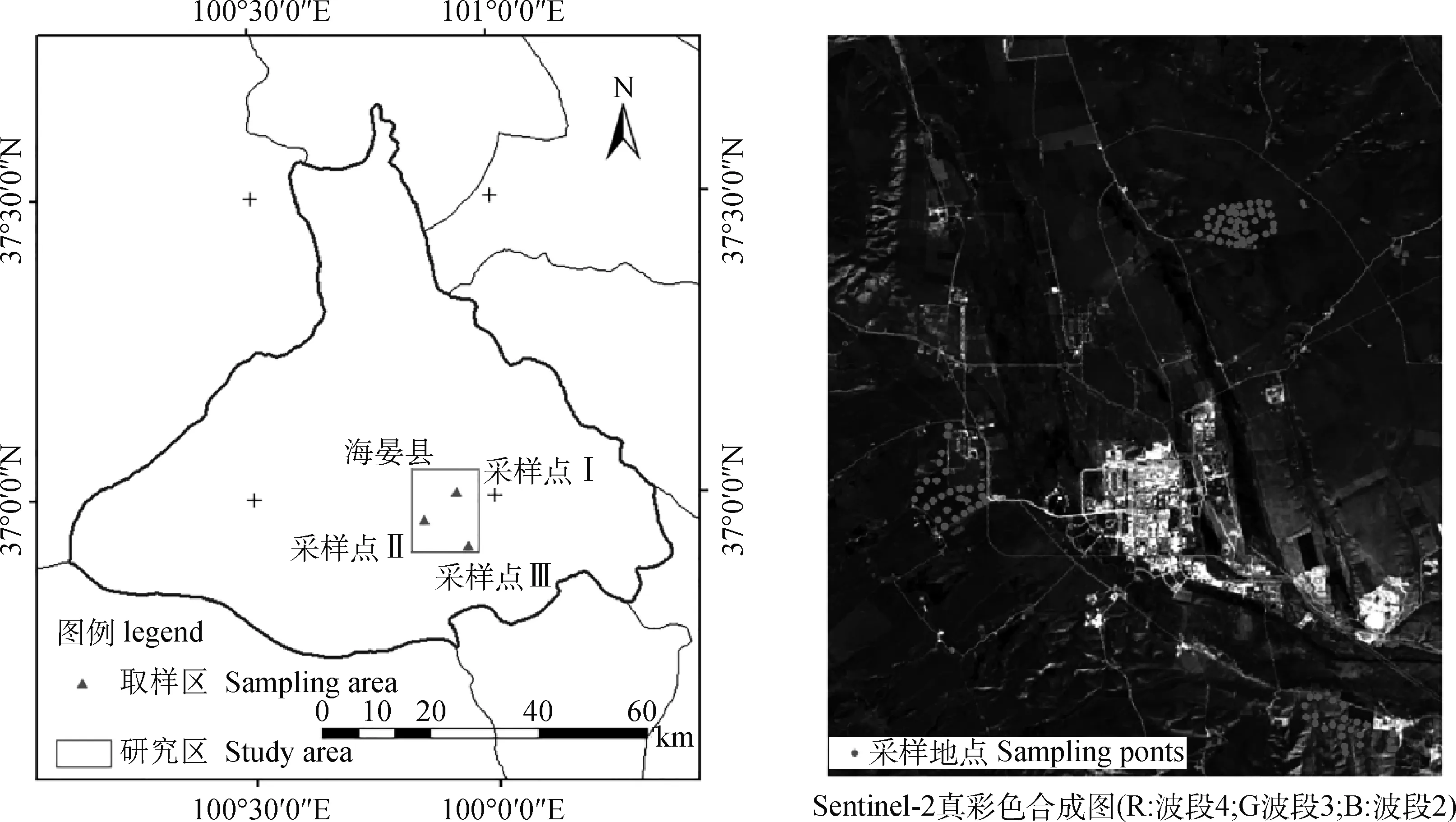
图1 研究区位位置及样点分布
1.2 采样点设置与生物量测定
地面生物量数据采集于2017年8月5,6日进行,根据研究区内牧草的生长状况选择3个采样区进行试验,包括1个夏秋草场(Ⅰ)和2个春冬草场(Ⅱ,Ⅲ),共97个样方(图1),样方尽可能代表整个研究区域的植被生长状况。样方规格为0.5 m×0.5 m,齐地刈割,挑出石子和动物粪便等牲畜不可食用部分称取鲜重并记录。记录内容包括样方编号、样方中心点GPS坐标、样本鲜重(Biomass)、照片编号。
1.3 遥感数据获取及预处理
研究所选用的遥感数据为Sentinel-2遥感影像,包含13个波段,其中心波长为490 nm,560 nm,665 nm和842 nm的4个波段空间分辨率为10 m,705 nm,740 nm,783 nm,865 nm,1 610 nm和2 190 nm的6个波段分辨率为20 m,其余443 nm,945 nm和1 375 nm的3个波段分辨率为60 m。影像过境时间为2017年8月4日。Sentinel-2数据下载网址:https://scihub.copernicus.eu/dhus/#/home。使用SNAP对影像进行预处理,经过辐射定标,大气校正后得到反射率数据。Sentinel-2数据各个波段的空间分辨率有所不同,本文使用最近邻插值法,将处理后的各波段重采样至10 m。
选取常用于牧草长势研究的21种植被指数。不同指数的计算公式见表1。计算各植被指数的值,并利用各样地记录的GPS定位坐标,提取对应样地的各类植被指数。由于Sentinel-2包含3个红边波段,而根据相关的研究表明705 nm和740 nm处的反射率与叶绿素含量均具有较高的相关性[16],因此本文分别选用中心波长在705 nm和740 nm的波段作为计算中的红边波段。同时,由于中心波长在2 190 nm处的反射率与植被水分相关性优于1 375 nm和1 610 nm处的反射率[17],因此,本文选取中心波长在2 190 nm的波段作为计算中的短波红外波段。
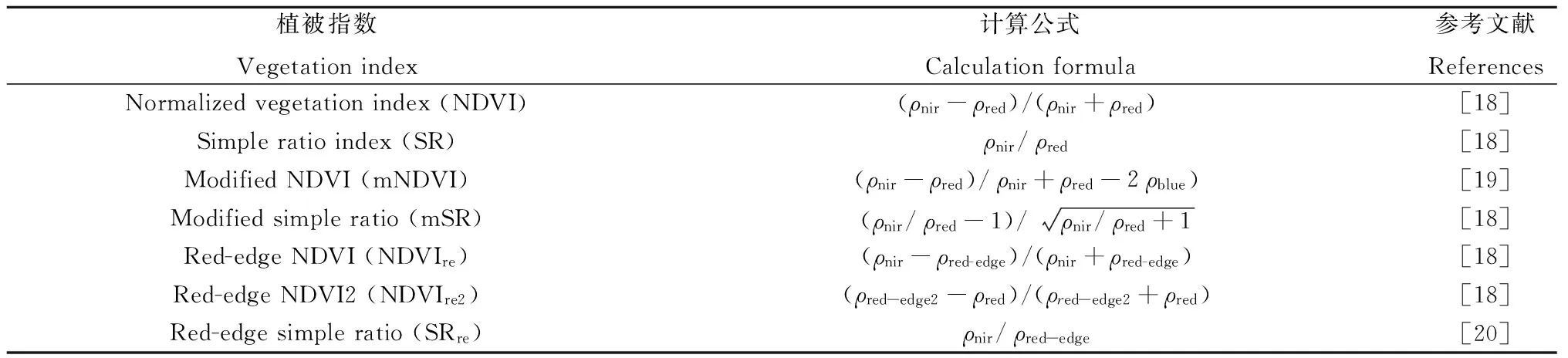
表1 植被指数公式
1.4 模型建立与精度评价
分别构建不同植被指数与对应生物量间的拟合模型,单变量拟合方程包含线性函数和非线性(二项式、指数、幂数和对数)函数,多元线性模型采用逐步线性回归方法,多元非线性回归模型采用随机森林模型。在多元回归模型中选择全局择优法,通过决定系数(R2)及赤池信息量准则(Akaike information criterion,AIC)对所有变量组合模型进行评价,筛选具有最大R2及最小AIC的变量组合[33]。
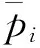
2 结果与分析
2.1 生物量数据分析
由于牧草生物量会受到草地类型、放牧强度等多种因素的影响,不同采样点的草地生物量差异很大。因此本文根据研究区草地的分布状况设置了3个采样区。其中采样区I属于夏季牧场,由于长时间的放牧,旅游资源的开发,草地植被高度较矮,生物量最小值仅为40 g·m-2;采样区II、采样区III属于冬季牧场,草地一直处于保育状态,生产力处于一年最高阶段,生物量较高,平均值达763~810 g·m-2。3个采样区共包含了100个采样点,剔除部分异常值后剩余97个采样点(如图1所示)。这些样点数据为研究植被冠层光谱特征与生物量的关系奠定了基础(表2所示)。

表2 不同样区及生物量统计结果
2.2 单变量植被指数模型
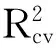
不同植被指数具有不同的生态学意义,可以从不同角度反映植被的理化特征。但由于植被生物量累计是多因素共同耦合作用的结果,因而在不同植被理化特征的影响下,植被指数的拟合效果也各不相同。本研究构建的21种植被指数模型中,反映牧草叶面/冠层水分含量的植被指数(如NDWI,GVMI,NDII,NDPI)均具有较高估算精度,与牧草叶绿素关系密切的植被指数CIgreen,CIre同样具有较好的表现。但能够消除影像土壤背景的植被指数OSAVI与反映牧草冠层结构的植被指数mNDVI,mSR精度相对较低,这说明影响牧草生物量估算精度的主要因素是水分和叶绿素。同时,近年来的一些研究成果表明包含红边波段的植被指数对于叶绿素变化十分敏感,而叶绿素是绿色植物光合作用的重要成分,因此这类指数在一些研究中能够较好的反映植被的生物量[18]。而本研究发现引入红边波段的指数并未显著提高生物量的估算精度(如NDVIre所对应的R2和RMSE与NDVI结果相当),甚至一些指数模型所对应的精度出现了明显降低(如SRre所对应的R2和RMSE分别为0.53和274 g·m-2,精度远低于SR对应的0.70和238 g·m-2),可能原因是植被的红边特征(705 nm)对于水分的变化敏感性差,而在本试验中水分是牧草湿生物量的重要主导因素。
不同模型预测值与实测值1∶1关系如图2所示,不同指数模型均一定程度上受到“过饱和”问题的影响,当模型达到饱和点时,预测精度大幅下降,植被指数对牧草生物量变化的敏感性减弱(如图2所示,当NDVI模型中实测值到达700 g·m-2左右时,样本点数据明显偏向1∶1等值线右侧),在牧草生物量累积较多时导致估算结果偏低。在单变量模型中,“过饱和”问题已成为制约植被高生物量估算准确性的一个重要因素。
图2 单变量植被指数模型交叉验证的预测值与实测值之间的1∶1关系图
2.3 多元线性回归
在多元线性回归中,利用AIC准则对植被指数进行评估和特征波段选择,选择的特征波段及变量所对应的模型贡献占比如图3所示。其中,反映植被水分含量的NDPI占比最大,达到了32.95%,且同样反应植被水分特征的NDII1与NDWI同样占有较高比重(模型贡献占比分别为12.63%和7.89%),说明多元线性回归模型中水分对于生物量的变化起主导作用。其次反映植被绿度的指数(CIgreen,CIre,MTCI和NDVIre)在模型中贡献占比和达到31.89%,说明了植被绿度在生物量估算模型中效果仅次于植被水分。而反映植被盖度(MTVI2,WDRVI)和消除大气背景影响(EVI)的植被指数在模型中贡献占比分别为9.75%,1.79%,相对于植被水分与绿度而言效果并不明显,在模型中起到一定辅助作用。
图3 不同植被指数的贡献占比
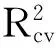

表3 不同植被指数模型的精度对比
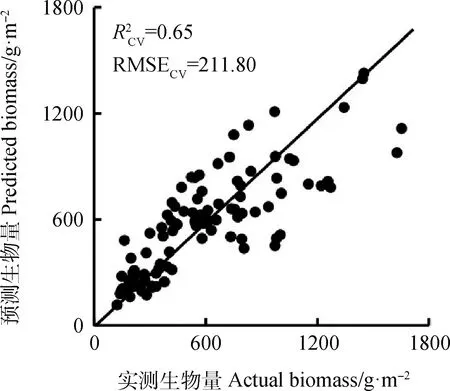
图4 预测值与实测值的1∶1关系图
2.4 随机森林回归
随机森林回归中,首先通过统计分析软件R自带的“random Forest”包进行植被指数选择,选择的植被指数及其所对应的模型贡献占比如图5所示。在该模型中共有13个植被指数入选,且各植被指数之间贡献占比较为均衡。其中反映植被水分特征的指数NDWI占比最高,为10.4%,其他反映植被水分特征的指数均具有较高的占比(GVMI2和SR的模型贡献率分别为7.61%和7.17%),说明植被水分在该模型中起关键作用。其次,反映植被叶绿素含量的指数(mNDVIre,NDVIre2,mSR,CIgreen,CIre)模型贡献率和达到了39.24%,说明牧草绿度/叶绿素含量变化对模型具有较大影响。此外,其他反映植被盖度(WDRVI,MTVI2)、消除大气背景影响(EVI2)、消除土壤背景影响(OSAVI)等因素的植被指数在生物量反演中同样具有重要意义。总的来说这些选取的植被指数组合从各个方面反映了植被的理化特征,进而反映出牧草生物量状态。这些入选指数间不仅仅是高相关性,还具有较好的互补性,能够综合的反映牧草的生物量状况。
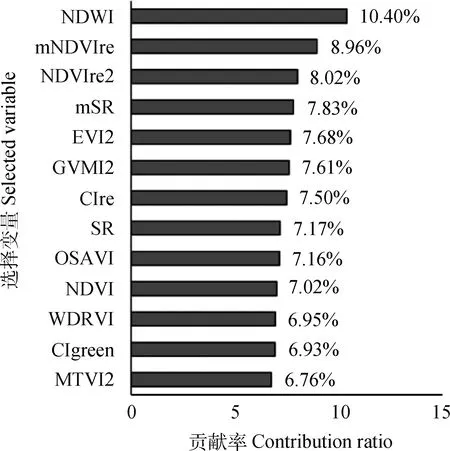
图5 不同植被指数的贡献占比
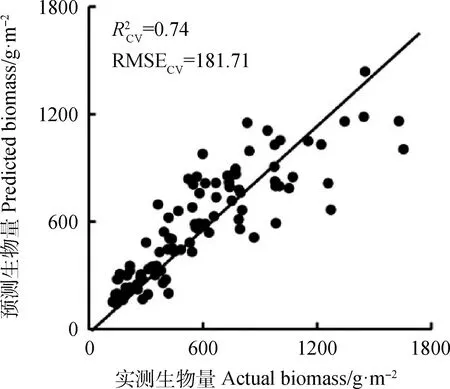
图6 预测值与实测值的1∶1关系图
2.5 牧草生物量反演及制图
综上分析,基于随机森林回归构建的牧草生物量反演模型较单变量指数模型和多元线性模型具有明显优势,因此将该方法应用于整个研究区生物量反演制图。剔除城区、道路和水域等非植被区域获取的研究区生物量反演制图结果如图7所示。结果反映出研究区牧草生物量分布具有明显的空间差异性。生物量最高的区域是优质牧草种植基地,同时远离城区的牧草生物量较高,而城区周边的牧草生物量明显较低,可能是由于城区周围多为夏季牧场,牛羊放牧制约了牧草生物量的累积,此外旅游开发以及人为活动也会在一定程度影响牧草的生长。
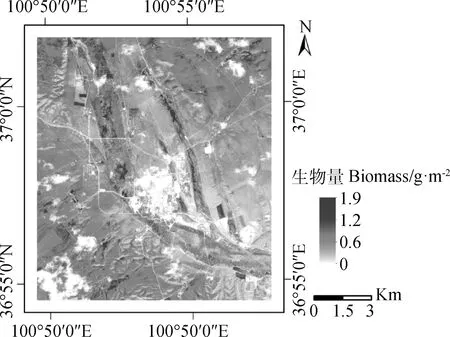
图7 研究区牧草生物量估算结果图
3 讨论
通过模型对比发现:随机森林模型和多元线性回归模型精度明显高于单变量指数模型,其中随机森林模型精度最高。由于单变量指数模型只运用单个表示某一特征的植被指数进行建模,未充分利用Sentinel-2数据丰富的光谱信息,容易造成重要信息的丢失。同时单变量模型容易受到“过饱和”问题影响,对于高盖度区域牧草生物量的估算结果较差[15];多元线性回归模型集合了多个指数特征,在一定程度上提高了模型精度,但其由于受到共线性问题的影响,制约了模型普适性和稳定性[34];随机森林模型可以综合不同含义的变量特征,且有效缓解“过饱和”与共线性问题[35],因此在所有模型中表现出了最优的精度和稳定性。很多研究利用该方法进行水质元素含量以及农作物、牧草理化参量的估算并取得了较好的效果[36-37]。
通过入选波段对比发现:单变量模型中CIgreen和NDWI指数与牧草生物量具有最优的拟合关系。同样,多元线性模型和随机森林模型的入选变量中也包含CIgreen和NDWI指数。另外,多元回归模型中相同的入选波段还包括CIre,MTVI2,GVMI2,WDRVI,NDVIre(NDVIre2)和EVI(EVI2)。说明一些关键的指数在牧草生物量估算研究中具有普适性,这些具有普适性的指数从叶绿素含量、水分含量、植被盖度和消除影像背景噪声等方面反映了牧草的理化特征,进而反映出牧草生物量状态。而其他入选波段的差异性则说明不同模型对于特征变量的综合能力存在差异。此外,本文的研究结果表明,无论是单变量模型还是多变量模型,植被指数和生物量非线性拟合模型精度高于线性拟合,这可能是由于受到“过饱和”问题的影响,随着生物量的增加,植被指数的敏感性逐渐下降。
4 结论