基于SPSS 回归分析的颜色与物质浓度辨识模型
2021-09-17陈溥杨贶
陈 溥 杨 贶
(柳州铁道职业技术学院,广西 柳州 545616)
1 前言
世界是多姿多彩、五彩缤纷、光鲜亮丽的,我们在日常生活中经常会看见五颜六色的事物,这时便会有朋友好奇颜色为什么会有这么多种,即使是相同的颜色,又为什么会有深浅,大多数人都会说是浓度不同所导致的,的确深浅在我们看来,就是浓淡,亦是物质的浓度,那么如何根据颜色的深浅来确定物质的浓度呢,这使得研究颜色读数与浓度之间的关系就变得越来越重要。
比色法是目前常用的一种检测物质浓度的方法,即把待测物质制备成溶液后滴在特定的白色试纸表面,等其充分反应以后获得一张有颜色的试纸,再把该颜色试纸与一个标准比色卡进行对比,就可以确定待测物质的浓度档位了。由于每个人对颜色的敏感差异和观测误差,使得这一方法在精度上受到很大影响。随着照相技术和颜色分辨率的提高,希望建立颜色读数和物质浓度的数量关系,即只要输入照片中的颜色读数就能够获得待测物质的浓度。
2 模型的建立与求解
首先将附件中的采样数据导入SPSS,其次在SPSS 软件中对各组数据进行多元线性回归分析,得到各物质颜色读数与物质浓度的模型如下:(模型中的符号说明见下表)
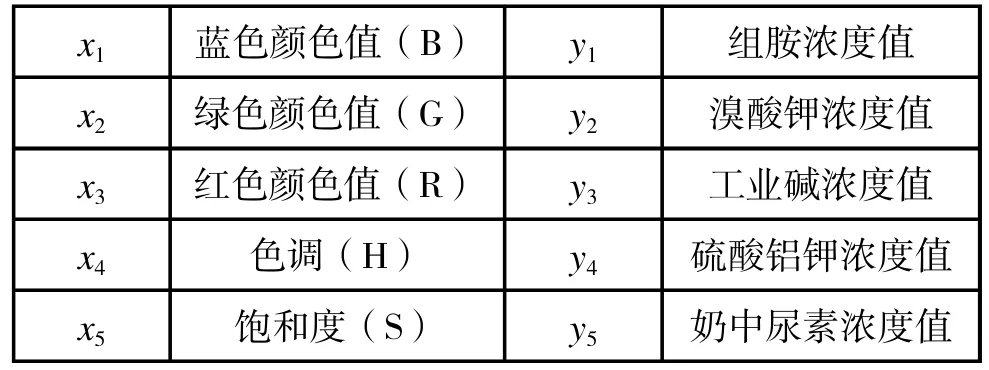
组胺的模型:
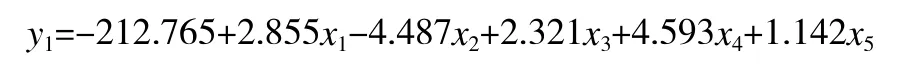
溴酸钾的模型:
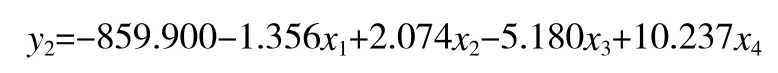
工业碱的模型:
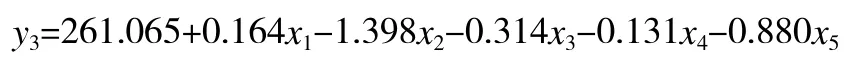
硫酸铝钾的模型:
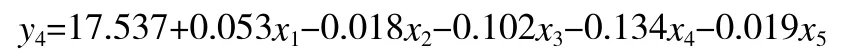
奶中尿素的模型:
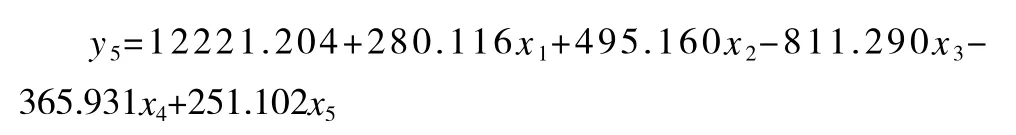
3 模型的误差分析
根据以上所得各物质的颜色读数与浓度的模型,将采样数据中各颜色读数代入模型,求得所对应的各物质的浓度模型值yi,之后与所对应的浓度采样值Yi进行比较,代入下面平均相对误差的计算公式:
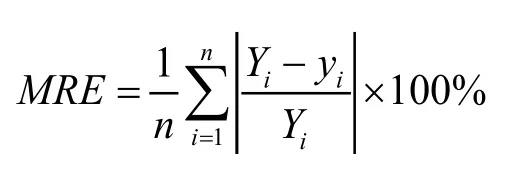
计算得到各物质模型的平均相对误差如下表:

通过表格中的数据可以看出,只有组胺模型的平均相对误差小于10%,在可以接受的范围内,另外四种物质模型的平均相对误差较大,超出了可接受范围,模型失效。[1]
4 模型的改进
对于四种物质的失效模型,考虑更优的建模方法,运用SPSS 软件计算四种物质采样数据中五个影响指标(B、G、R、H、S)两两之间的相关性系数,得到的相关性系数结果如上表1~4。
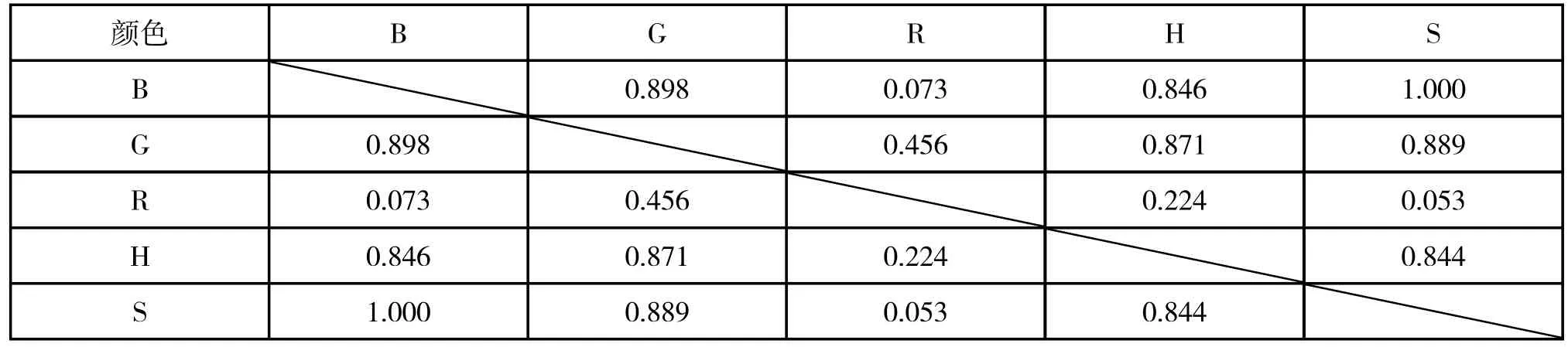
表1 溴酸钾
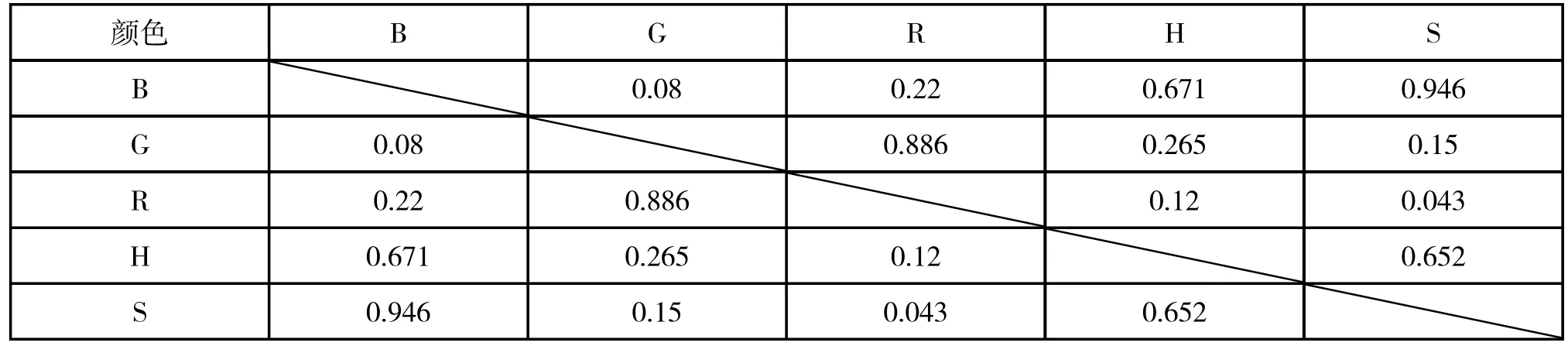
表2 工业碱
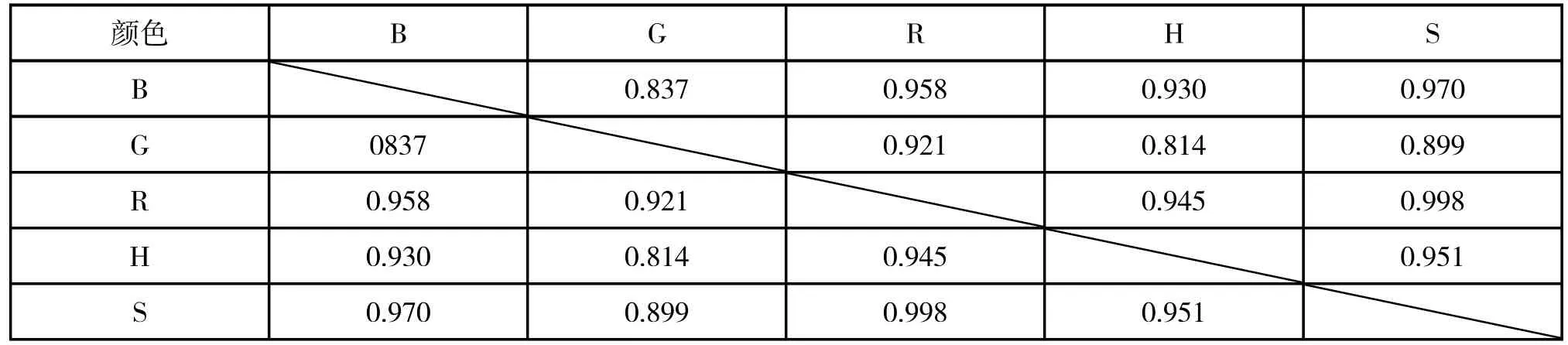
表3 硫酸铝钾
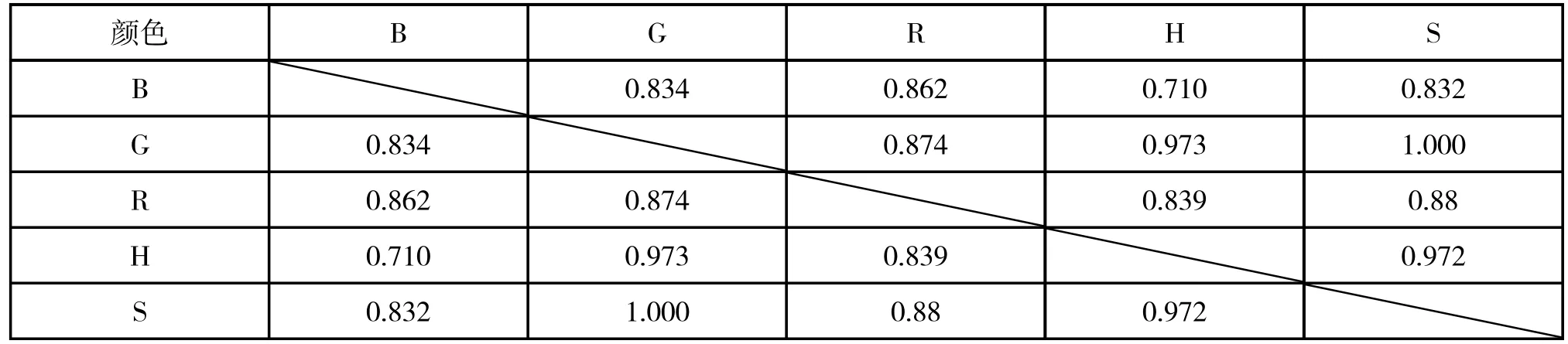
表4 奶中尿素
在各种物质中,选取五个影响指标两两之间相关性系数最大的三对指标进行两两组合(对应的指标数据两两之间做乘法运算,得到新的组合数据),两两之间相关性系数最小的指标不进行组合(对应的指标数据取各自的平方,得到新的数据),从而各物质均得到一组新的五个组合指标,并且得到其所对应的数据如表5~8。
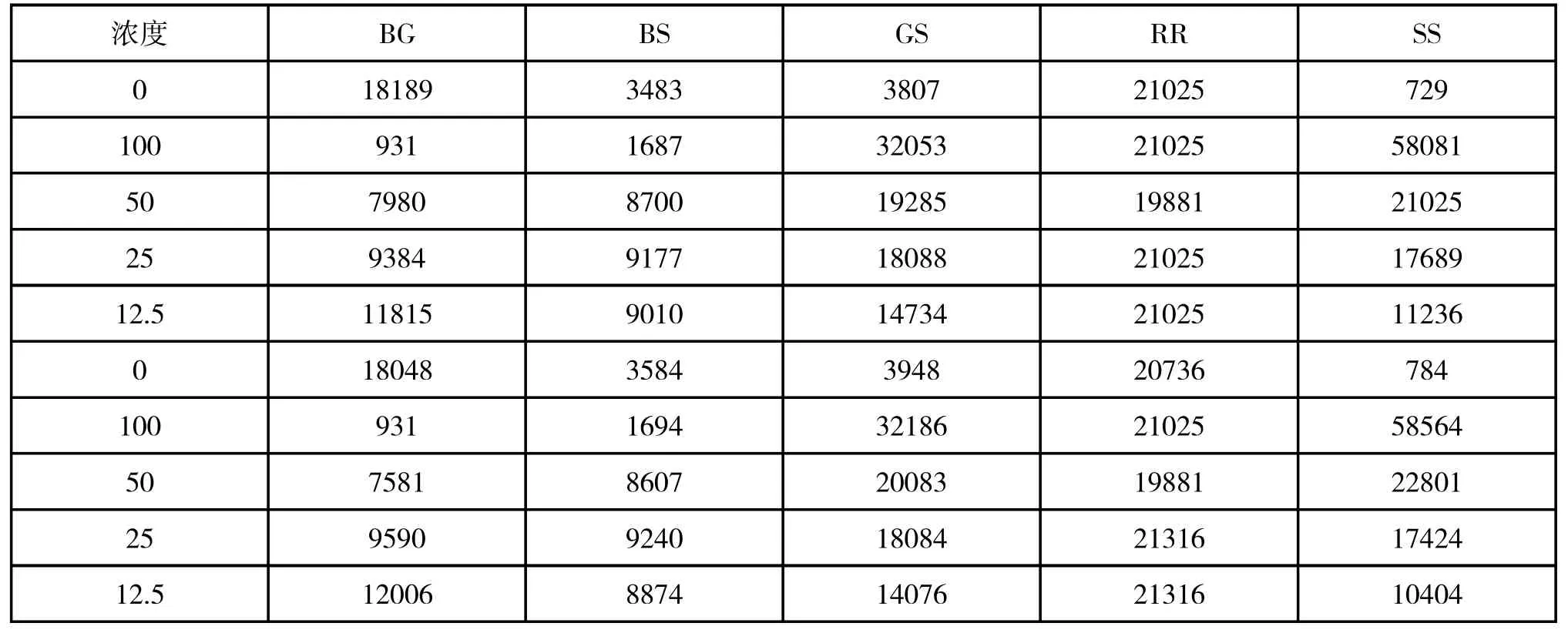
表5 溴酸钾
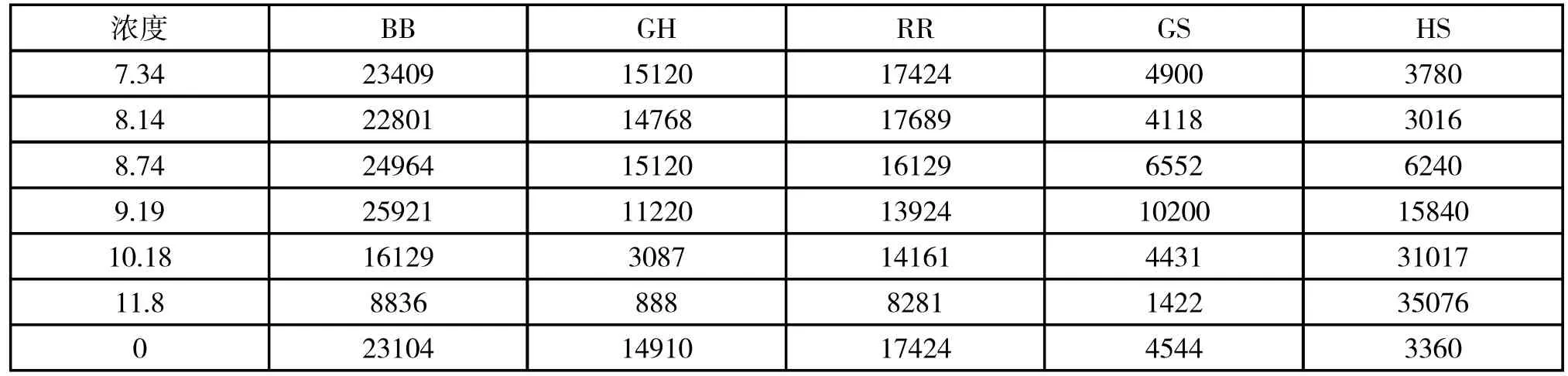
表6 工业碱
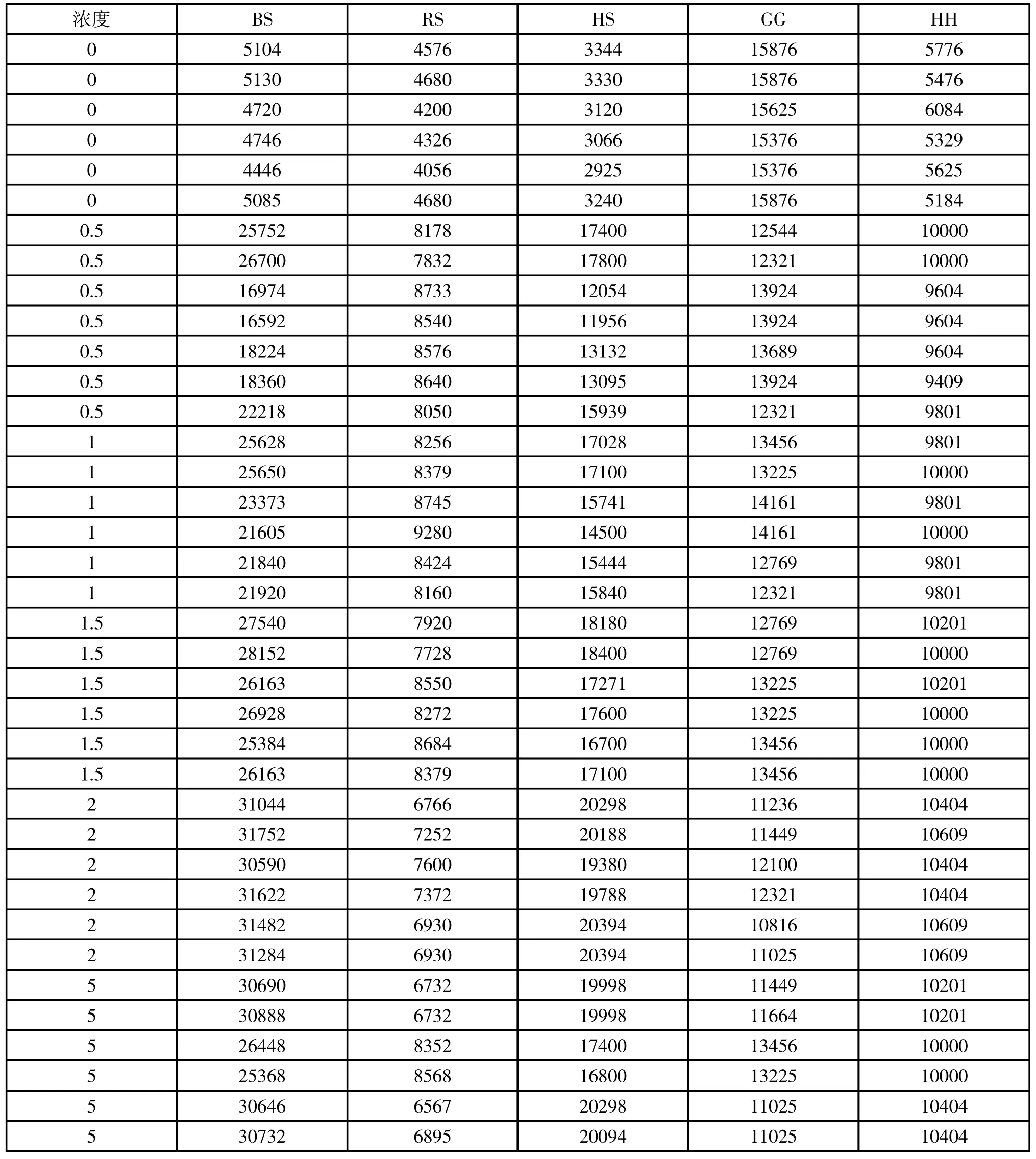
表7 硫酸化钾
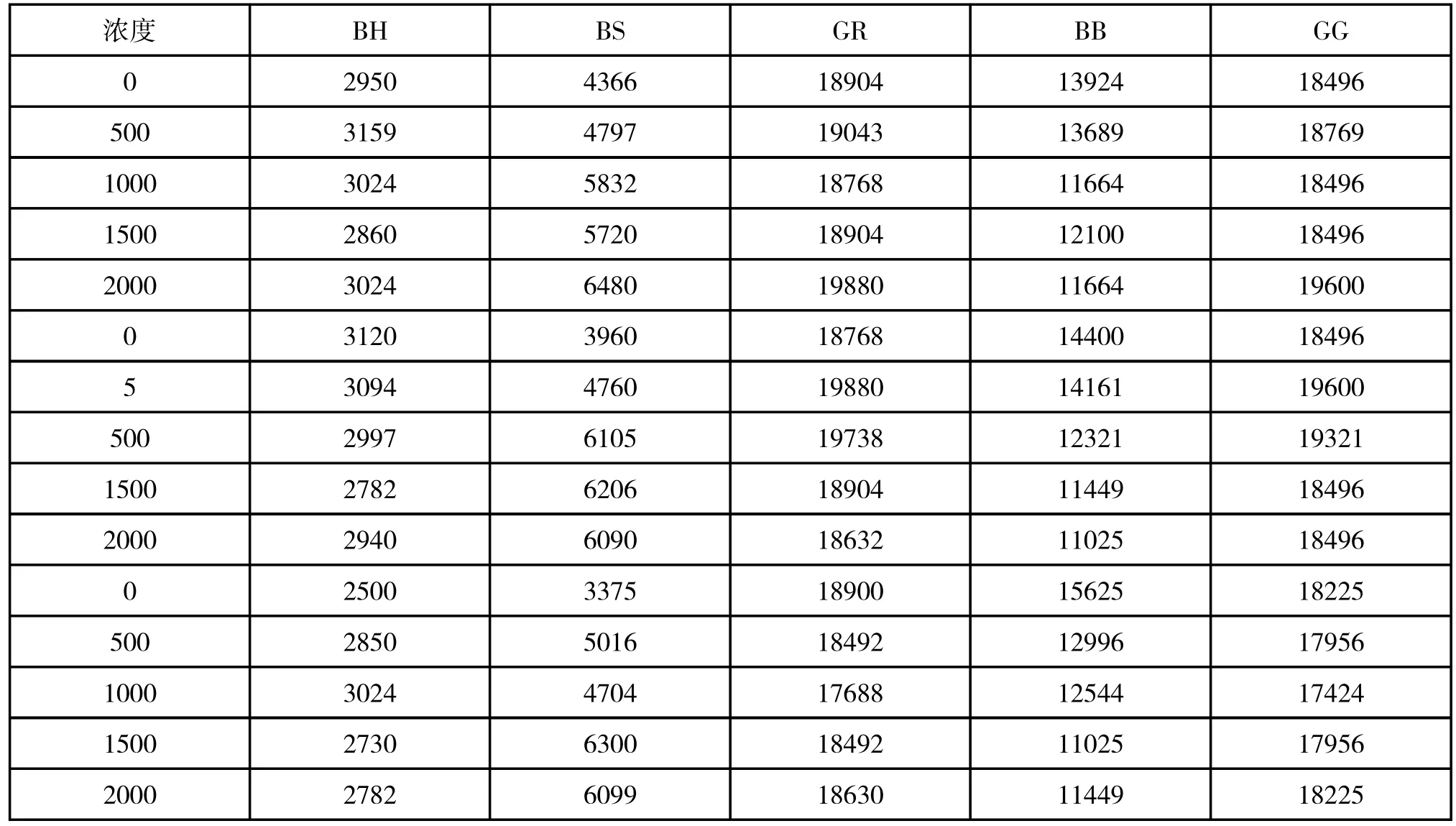
表8 奶中尿酸
将数据导入SPSS 软件,并对各物质新组合的数据进行多元线性回归分析,得到了各物质下颜色读数与物质浓度的模型如下:
溴酸钾的模型:
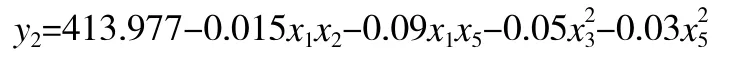
工业碱的模型:
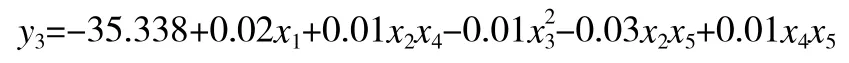
硫酸化钾的模型:
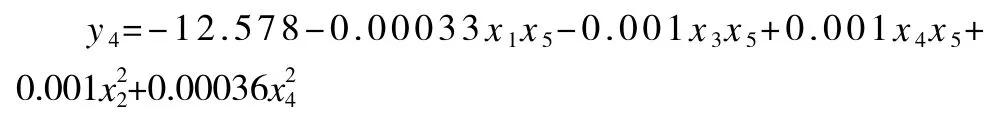
奶中尿酸的模型:
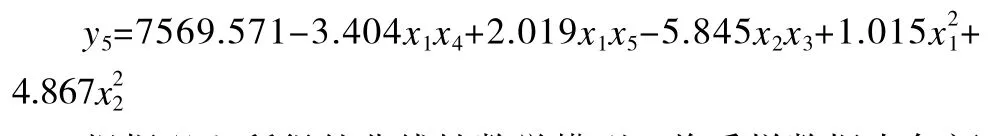
根据以上所得的非线性数学模型,将采样数据中各颜色读数代入上述模型,求得所对应的各物质的浓度模型值yi,之后与所对应的浓度采样值Yi进行比较,代入下面平均相对误差的计算公式:
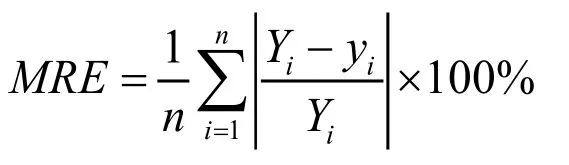
计算得到以上四种物质模型的平均相对误差如上表9所示。

表9
从表中可以看出,四种物质模型的误差均小于10%,由此可见,改进后的非线性模型与之前由多元线性回归分析所得的模型对比,有了很大的优化。[2]
5 结语
本文运用SPSS 软件对采样数据进行了多元线性回归分析,建立了颜色读数和物质浓度的数学模型,并对所建立的模型进行了误差分析和改进,得到了优化后的非线性数学模型,根据颜色读数来预测物质浓度,在实际应用中有一定的参考价值。
