不平衡数据集文本多分类深度学习算法
2021-09-16王德志梁俊艳
王德志,梁俊艳
(1.华北科技学院 计算机学院,河北 廊坊 065201;2.华北科技学院 图书馆,河北 廊坊 065201)
0 引 言
在自然语言处理中,文本分类研究中主要分为二分类和多分类问题[1,2]。训练数据集的平衡性对深度学习算法的性能有重要的影响。文本多分类的训练数据集多是不平衡数据集。所谓不平衡数据集就是在同一个数据集中的某类数据的样本数量远远大于或者小于其它样本的数量。而少数类样本被错误分类的代价要比多数类样本错误分类造成的损失更大。文献[3]提出在卷积神经网络训练过程中基于标签权重修改损失函数结果,强化少数类样本对模型参数的影响。文献[4]提出基于词向量迁移的预训练任务选择方法,区分小类别样本,提升小类别分类准确度。文献[5]提出基于层次聚类的不平衡数据加权方法,根据密度因子确定采样频率,提升小样本权重。文献[6]提出基于差分孪生卷积神经网络的超平面特征图,利用样本与不同超平面的距离进行不平衡数据集分类的算法。目前研究中主要侧重于文本的二分类问题或者是通用性的低维特征向量的不平衡数据集的分类问题[7-10]。而基于高维度词向量的文本不平衡数据集多分类问题面临巨大的挑战。本文基于高维度向量聚类方法,提出一种混合式不平衡文本数据集采样方法,在保障大样本数据分类准确度的基础上,提升小样本数据分类的准确率,并通过实验验证了该方法的分类效果和准确率。
1 基于词向量的文本多分类特点
1.1 词向量的高维特性
在文本多分类处理中,首先需要对文本中各个词进行向量化表示,经典的方法有TF-IDF、skip-gram和CBOW等方法。文本数据集的词向量处理可以采用自定义模型训练方式或者采用经典的词向量模型,例如Word2vec、GloVe和FastText等[11]。但是,无论采用哪一种方式,当文本训练样本数据非常多时,训练所涉及到的基本词汇量也会不断增多。尤其是对非规范文本处理时(例如微博文本),会遇到大量新生词汇。为了更准确表示文本之间的关系,就需要对文本中的词进行高维度向量化,每个维度代表一个文本特征,只有词的向量维度达到一定规模时,才能够提供特征具有区分度的文本分类训练样本数据。谷歌公司基于大量通用新闻材料训练了具有300维的Word2vec词向量模型。Facebook基于通用的维基新闻材料训练了具有300维的FastText模型。这些高维度模型为文本多分类提供了坚实的词向量基础。
1.2 数据集不平衡性
高维度词向量模型只是为分词向量化提供了支撑,但是在文本多分类中,还需要大量的训练样本数据。由于目前文本多分类大量使用有监督学习方法,因此需要对训练数据进行样本标注。而大量的文本数据进行多分类标注是一个困难的事情,要想获得完全平衡的已标注文本分类训练数据基本是不可能的。而且随着分类数据的增多,也对训练数据集的平衡性提出了挑战。在实际文本多分类研究中,大量使用不平衡的训练数据集。其中,小样本数量标注数据的预测准确性,在特定应用领域中有重要作用。例如,在电子邮件中分类出具有诈骗性质的邮件,相对于普通邮件和广告垃圾邮件就属于小样本数量标注数据。数据集的不平衡性已经成为多数文本多分类的基本属性。
2 文本多分类混合式均分聚类采样算法(HCSA)
2.1 总体架构
为解决文本多分类训练数据集不平衡问题,可以采用欠采样(下采样)或过采样(上采样)方式进行数据集的预处理。其中欠采样以小样本数量为标准,对大样本数据进行减量提取,使大样本数量与小样本数量具有相同的规模,数据集总量减少。而过采样正好与之相反,以大样本数量为标准,对小样本数据进行复制增量,使小样本数量与大样本数量具有相同规模,数据集总量增加。但在文本多分类数据集中,由于分类标签是多个,如果仅基于最小样本和最大样本进行处理,都会导致数据集的不合理性,影响最终深度学习模型的训练结果。因此,本文提出一种基于聚类的均分混合式采样算法(HCSA)。其主要步骤如下:
(1)计算样本数据量均线
如式(1)所示,计算出所有不同分类样本数量的算数平均数,以此作为样本数据量均线。其中N表示分类标签数量,Xi表示每个分类中样本的总数量
(1)
(2)进行样本分区
以Lavg均线为基准,对每个分类样本进行分区。如式(2)所示,其中样本大于均线的为上区zup,样本数量小于均线的为下区zdn,并计算出与均线的差值di
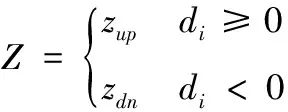
di=Xi-Lavg
(2)
(3)进行混合采样
对上区zup样本数据采用基于K-means聚类的欠采样方法,每个分类样本减少di个数据,实现每类样本数据量为Lavg。对于下区zdn样本数据采用基于K-means聚类的过采样方法,每个分类样本增加di个数据,实现每类样本数据量为Lavg。最终形成的新样本数据集样本数量为N×Lavg,从而实现不同分类样本数据量的均衡性。
通过上述步骤实现了多分类样本的均衡性,其关键步骤是上分区和下分区的不同采样方法。本文提出基于K-means聚类采样方法,对聚类小样本数据进行等比例扩充,对聚类大样本数据进行等比例缩减,从而保证各聚类样本数据特征的均衡性,为后续深度模型训练提供保障。
2.2 基于K-means聚类的过采样均线下数据
在不平衡数据集中,均线下数据属于小样本数据,需要增加数据样本数量。本算法采用基于K-means聚类的方法,对每类样本数据进行聚类,根据同类样本中聚类的分布情况,进行样本增加。聚类簇内数据越多,说明数据特征向量相似,增加的数据相对就少;聚类数据越少说明样本特征比较特殊,就增加相对多一些。
2.2.1 文本向量距离计算
在传统的K-means算法中多采用欧式距离进行空间中节点距离计算,但是在文本多分类中,要通过文本词向量空间距离来体现文本的相似度,因此采用欧式距离不适合。本算法采用文本余弦距离来计算多维空间中节点的距离,如式(3)所示
(3)
式中:x和y是多维词向量空间中的两个节点;向量空间维度n维;xi和yi表示两个向量在第i维空间的值。从公式中可以看出,对于两个文本向量,如果文本越相似,则Dis(x,y)越小,距离越近。当两个文本完全一致时,距离为0。当两个文本完全不相同时,距离最大值为1,即Dis(x,y)∈[0,1]。
2.2.2 基于轮廓系数的K-means聚类
在K-means聚类中K值代表聚类簇的数量。由于聚类属于无监督学习,因此无法提前确定最佳的K值。K值的大小直接影响到最终聚类的效果。因此,本算数采用动态调整的基于轮廓系统的K值选取与数据聚类,其步骤如下。
(1)K值与平均轮廓系统数S初始化
在有M个节点的向量空间中,聚类的簇数量K∈[1,M],即聚类的极端可能性是所有节点都在一个聚类中,或者每个节点独立一个簇,与其它任何节点无关。因此K值初始化为2,从最小可能聚类簇数开始。平均轮廓系数S由于还没有计算,因此取最小值-1,方便后面比较。随机选取两个节点作为初始聚类簇的质心节点。
(2)所有节点聚类
基于当前K簇,首先,每个节点i计算其与所属簇质心的距离,然后选取距离最小的簇为其所在簇。在计算完所有节点后,如式(4)所示,计算本簇中所有节点与质心的平均距离,然后选取到质心距离与平均距离最接近的节点作为新的质心。最后计算新质心与旧质心的距离,如果小于一定的值,结束聚类,否则开始新一轮以新质心为核心的聚类
hk_new=
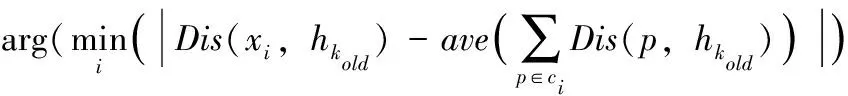
(4)
(3)计算每个节点的凝聚度
在聚类结束后,为了利用轮廓系数动态优化选取K值,首先计算每个节点xi的凝聚度。所谓节点的凝聚度就是此节点xi与同簇的其它节点的平均距离,其计算如式(5)所示。ci为节点i所在的簇
(5)
(4)计算机每个节点的分离度
所谓分离度是节点xi与其最近簇cm中所有节点的平均距离,如式(6)所示。而最近簇cm的计算如式(7)所示,就是用xi到某个簇所有节点平均距离作为衡量该点到该簇的距离后,选择最小平均距离的簇作为最近簇cm
(6)
(7)
(5)计算平均轮廓系数
凝聚度代表了簇内的密度程度,分离度代表了簇间的距离。理论上凝聚度越小,簇间距离越远,聚类效果越好,因此,基于式(8)计算所有节点平均轮廓系数S。公式中Si表示节点i的轮廓系数,S表示平均轮廓系数,它是所有节点轮廓系数之和的算数平均数,其取值范围为S∈[-1,1]。S的值越大代表聚类效果越好
(8)
(6)动态调整K值
增加K值,重复上述步骤(2)到步骤(5),计算出新一轮迭代中的轮廓系数。当迭代N次后,选取平均轮廓系数最大值的K作为聚类簇数,并以此时的聚类结果为最终结果。
2.2.3 均线下数据过采样
在对数据集的每类数据进行完聚类后,如式(2)所示,Lavg均线下的分类数据集需要增加|di|个数据,从而达到均线数据量。第i类数据集增加数据量如式(9)所示
(9)
Ni,j表示数据集中第i类数据中聚类后第j簇需要增加的数据量。Xi表示第i类数据集的总量,Mi,j表示第i类数据集中聚类后第j簇的数据量,Ki表示第i类数据集聚类的簇数量。从公式中可以看出,在聚类后,聚类簇中数据量越多在本类数据中增加的数据量就越少。不同类别数据之间,距离均线Lavg越远,整体的增加数据量越多。在同一簇中数据的增加方法,采用随机复制法。其过程就是,首先对簇中Mi,j个数据进行编号,其编号范围为[1,Mi,j],然后在此数据范围内进行随机抽签。如果Ni,j≤Mi,j,则随机抽签Ni,j个不重复数据复制。如果Ni,j>Mi,j,随机抽签Ni,j个可重复数据复制。
2.3 基于K-means聚类的欠采样均线上数据
在不平衡数据集中,均线上数据属于大样本数据,为了防止分类模型过拟合与提升训练速度,需要减少数据样本数量。与小样本数据处理方式类似,大样本数据也采用基于轮廓系数的K-means动态聚类方法,对每类样本数据进行聚类,根据同类样本中聚类的分布情况,进行样本减少。聚类簇内数据越多,说明数据特征向量相似,减少的数据相对就多;聚类数据越少说明样本特征比较特殊,就减少相对少一些。其第i类数据集减少数据量如式(10)所示
(10)
Qi,j表示数据集中第i类数据中聚类后第j簇需要减少的数据量,|di|表示Lavg均线上的第i类数据集需要减少的数据个数。在同一簇中数据的选取方法,采用随机选择法,就是在Mi,j个数中随机选取|Xi-Qi,j|个数。
3 文本多分类卷积神经网络
卷积神经网络(CNN)是机器学习中的经典神经网络模型,在多个领域中都得到成功的应用。针对自然语言分析,CNN一般采用一维模型结构,可以修改为并行的文本分类卷积神经网络TextCNN,其模型结构如图1所示。可以有多个并行的卷积层对输入的文本进行处理,最大池化层可以采用步长为3、4和5的方案进行数据处理,目的是提取不同单词间隔的文本特征信息,最后通过平铺层进行特征信息的汇总。为了保障模型的运行效率,本文根据词向量高维度特性,设计的TextCNN模型采用具有3个并行卷积层的一维卷积模型结构,如图2所示。模型中卷积层输入维度为(50,300)结构,输出为(50,256)。卷积层激活函数采用“relu”函数,输出层激活函数采用“softmax”函数,优化器采用“adam”,损失函数采用“catego-rical_crossentropy”。

图1 TextCNN网络模型结构

图2 TextCNN模型参数
4 不均衡微博灾害数据集
文本多分类算法一般都是针对特定文本数据集进行优化。本算法的优化主要针对微博灾害数据集。此数据集来自于CrisisNLP网站(https://crisisnlp.qcri.org)。其提供了2013年至2015年的2万1千多条灾害相关的微博数据,并人工对这些数据进行了多分类标注。其标注样本数据情况见表1。标注包含受伤、死亡、失踪、查找、人员安置、疏散等9类信息。其中最大分类样本数量约是最小样本分类数量的13倍,5种分类在数据集均线下,4种分类在数据集均线上,属于典型的不平衡文本数据集。在数据集预处理方面,由于在微博文章中要求内容不能超过140个单词,因此在文本向量化前需要先进行关键词提取,为了保证提取的关键词能够代表文章的目标分类,经统计分析最终选取文章平均词语量50作为参数,即词频统计前50的单词作为文章的关键词。
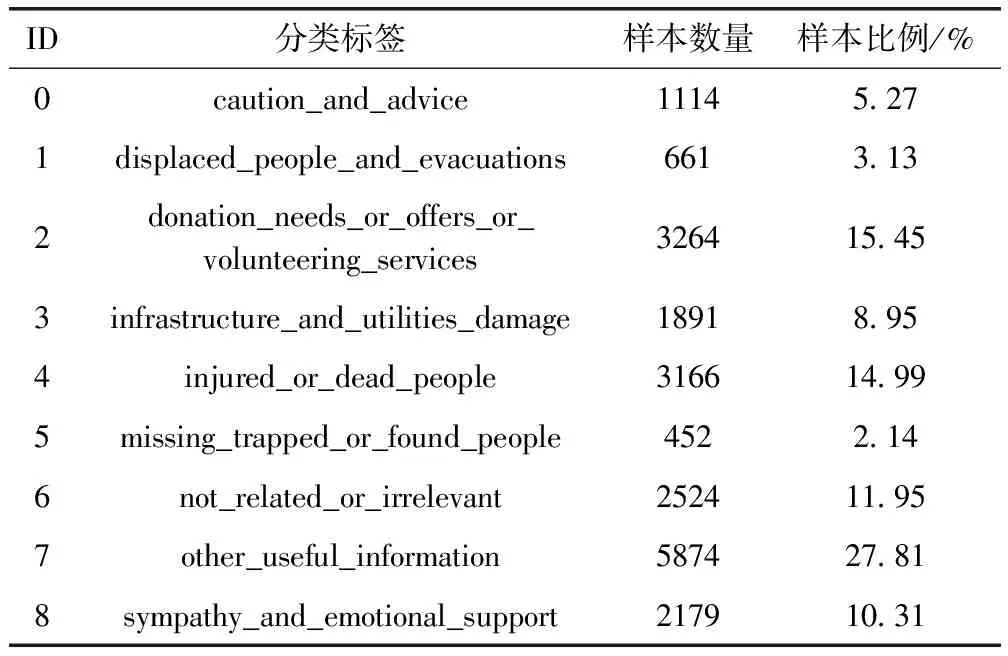
表1 微博灾害数据集标定情况
5 实验数据分析
5.1 实验条件
本实验基于个人工作站,其软硬件配置见表2。本实验基于Word2vec模型对微博灾害数据集进行分词向量化,每条文本维度为(50,300)。其中,50代表此文本中的关键词,如果关键词个数不足50,补零进行处理。300代表每个词的维度,即词特征向量空间为300维。实验中共使用21 125条微博数据,其中90%用来进行模型训练,10%用来模型测试。TextCNN模型数据输出维度为(9,1),表示分类为9个。
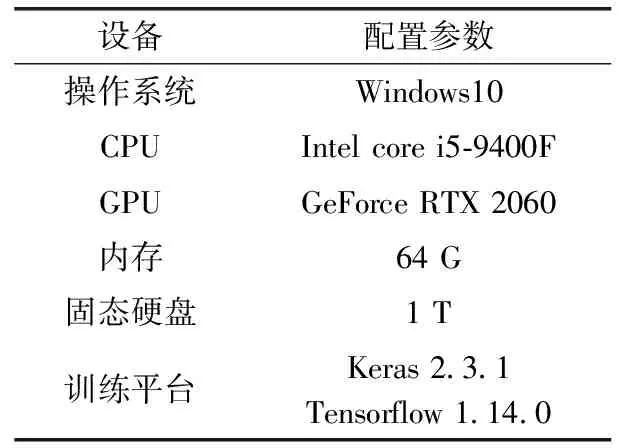
表2 实验配置条件
5.2 评价指标
机器学习算法的评价指标通常采用准确率(Acc)、精确率(P)、召回率(R)和F1值。在文本多分类中,准确率、召回率和F1值可以采用算术平均(Pm、Rm和F1m)和加权平均(Pw、Rw和F1w)计算两种方法,其计算如式(11)、式(12)所示

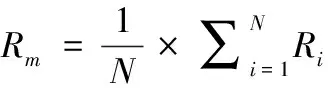
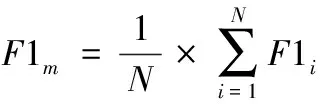
(11)
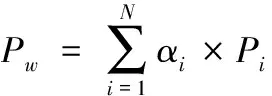
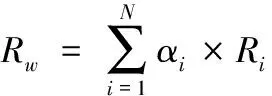
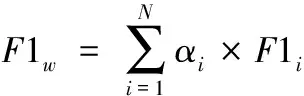
(12)
其中,Pi为每个分类的精确率,即“本类正确预测的数量/所有预测为本类的数量”;Ri为召回率,即“本类正确预测的数量/所有本类的数量”;F1i是“2*(Pi*Ri)/(Pi+Ri)”。αi为不同分类样本占总样本的比例,N为分类总数。
5.3 实验结果分析
为验证本算法性能,进行了4种方法进行实验数据对比。第一种是常规方法,未对数据集进行欠采样或过采样;第二种是随机欠采样方式,以最小分类数据集数据量为标准,其它分类数据集进行随机欠采样;第三种是随机过采样方式,以最大分类数据集数据量为标准,其它分类数据集进行随机复制过采样;第四种是本文提出的HCSA采样方法。4种方法实验结果的混淆矩阵,如图3所示。
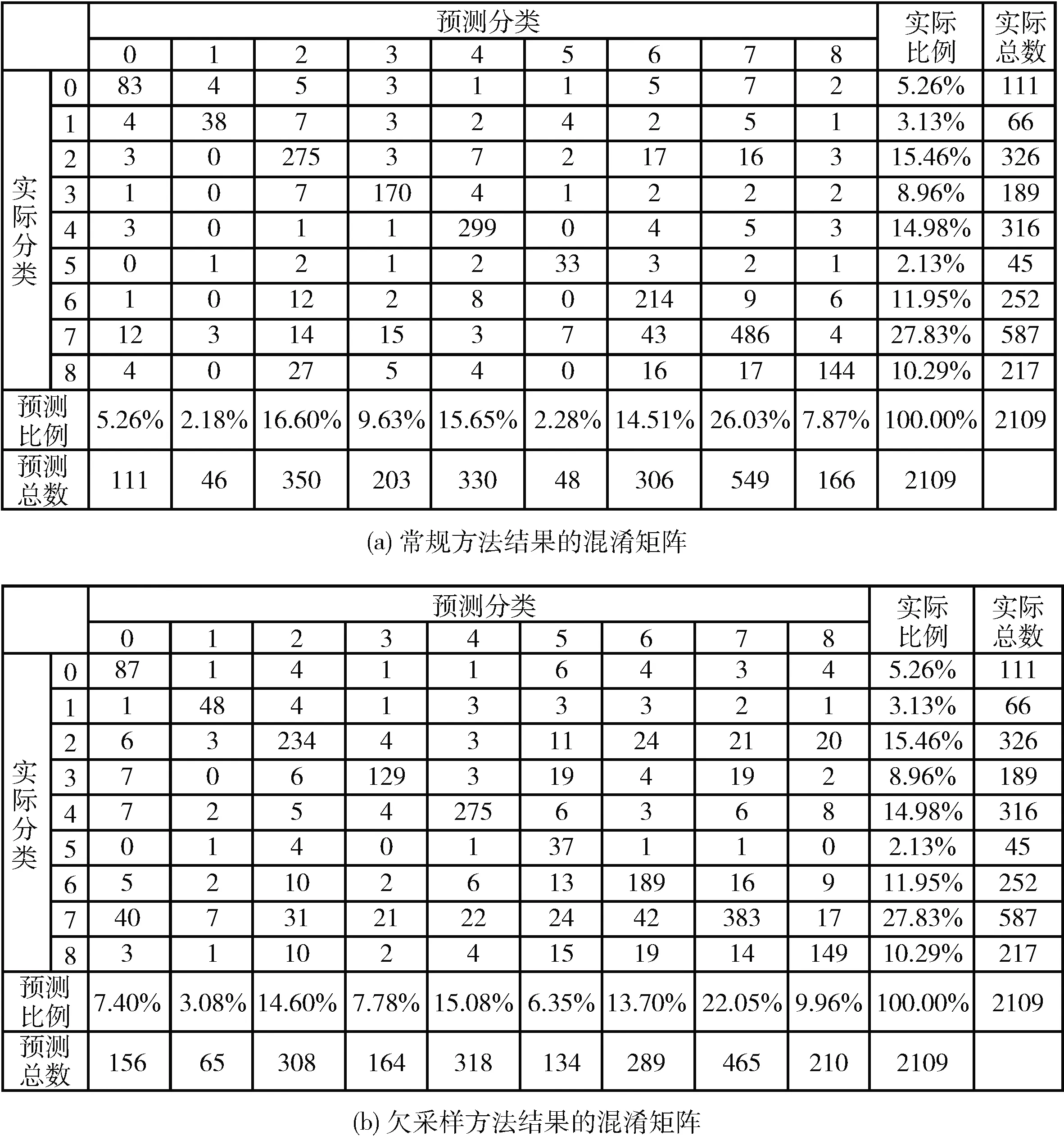
图3 预测结果混淆矩阵
基于各方法的混淆矩阵计算出对应各分类数据集的评价指标值见表3。从表中数据可以看出,分类5为最小数据集,在F1值中HCSA算法值最大,小样本的预测精确率和召回率都有提升。分类7为最大数据集,在F1值中HCSA算法值最大,精确率和召回率性能都没有下降。
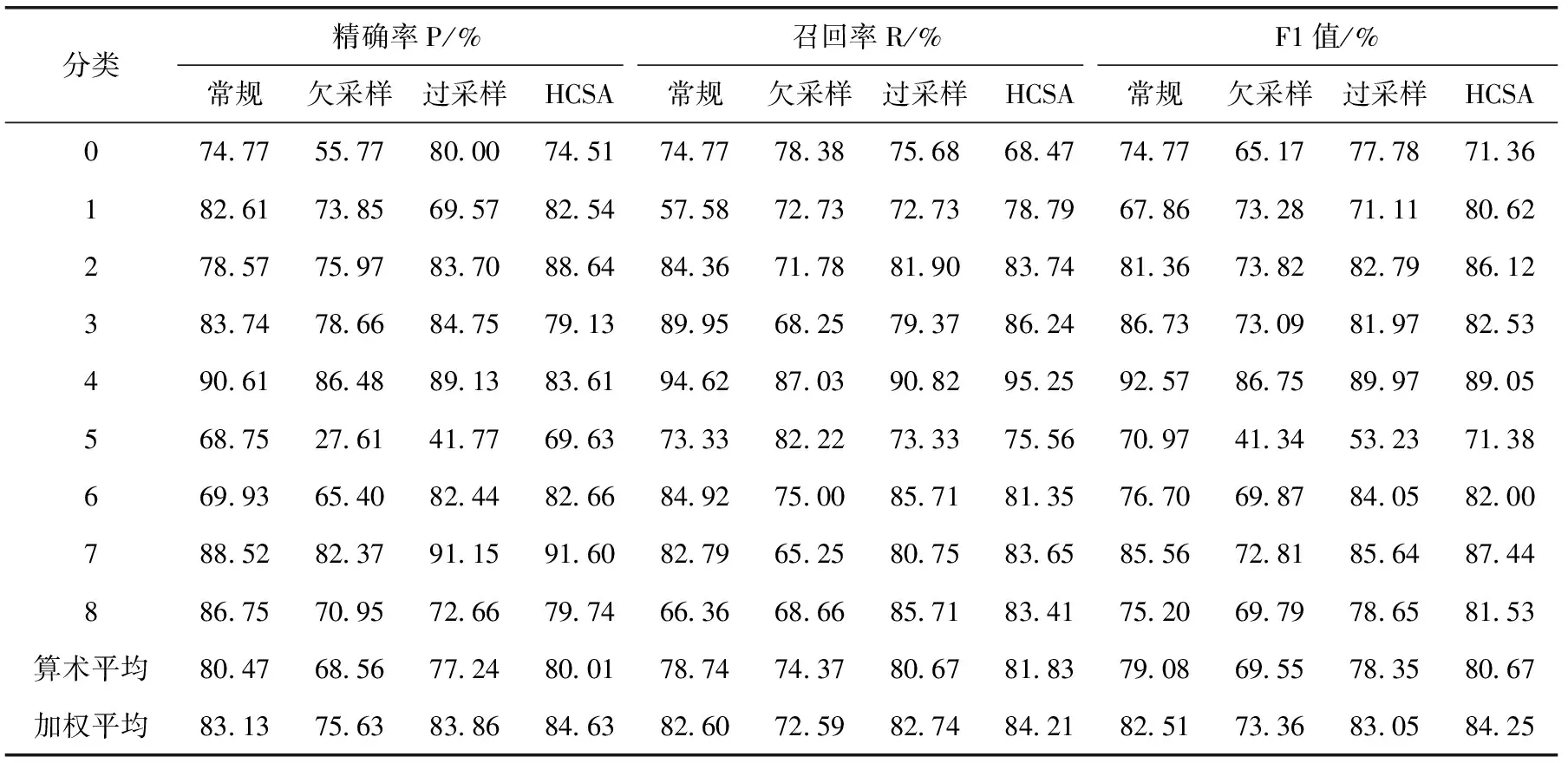
表3 各方法评价指标值
图4和图5展示了各方法的算数平均值和加权平均值指标数据。从图中可以看出,HCSA算法的准确率和F1值最高,过采样与常规方法性能相近,欠采样方法指标值最低。欠采样由于随机丢弃了训练样本数据,导致性能下降严重。而过采样虽然增加了训练数据,但是由于是随机复制,没能保证一定增加文本向量空间中小特征向量。另一方面,过采样由于存在大量的复制数据,导致TextCNN模型在训练中出现了过拟合现象。说明,虽然增加了训练数据数量,但是如果增加的不合理,会导致模型过拟合,不能提升模型的预测性能。而在HCSA算法中,由于进行了聚类,对小样本中小特征向量提高了复制的比例,因此能够提升小特征的预测准确率。对大样本数据,为了防止过拟合,进行了训练数据集抛弃。但是没有导致指标值像欠采样一样下降非常多,这是由于在数据抛弃时,是基于聚类结果,聚类的数据越多,抛弃的比例就增多。这样最终保证各类特征在数据集中分布平衡。
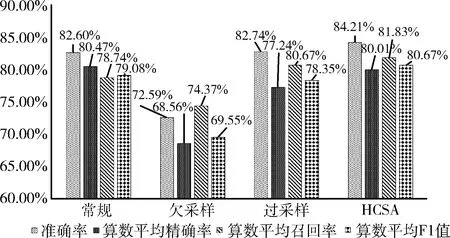
图4 算数平均指标值
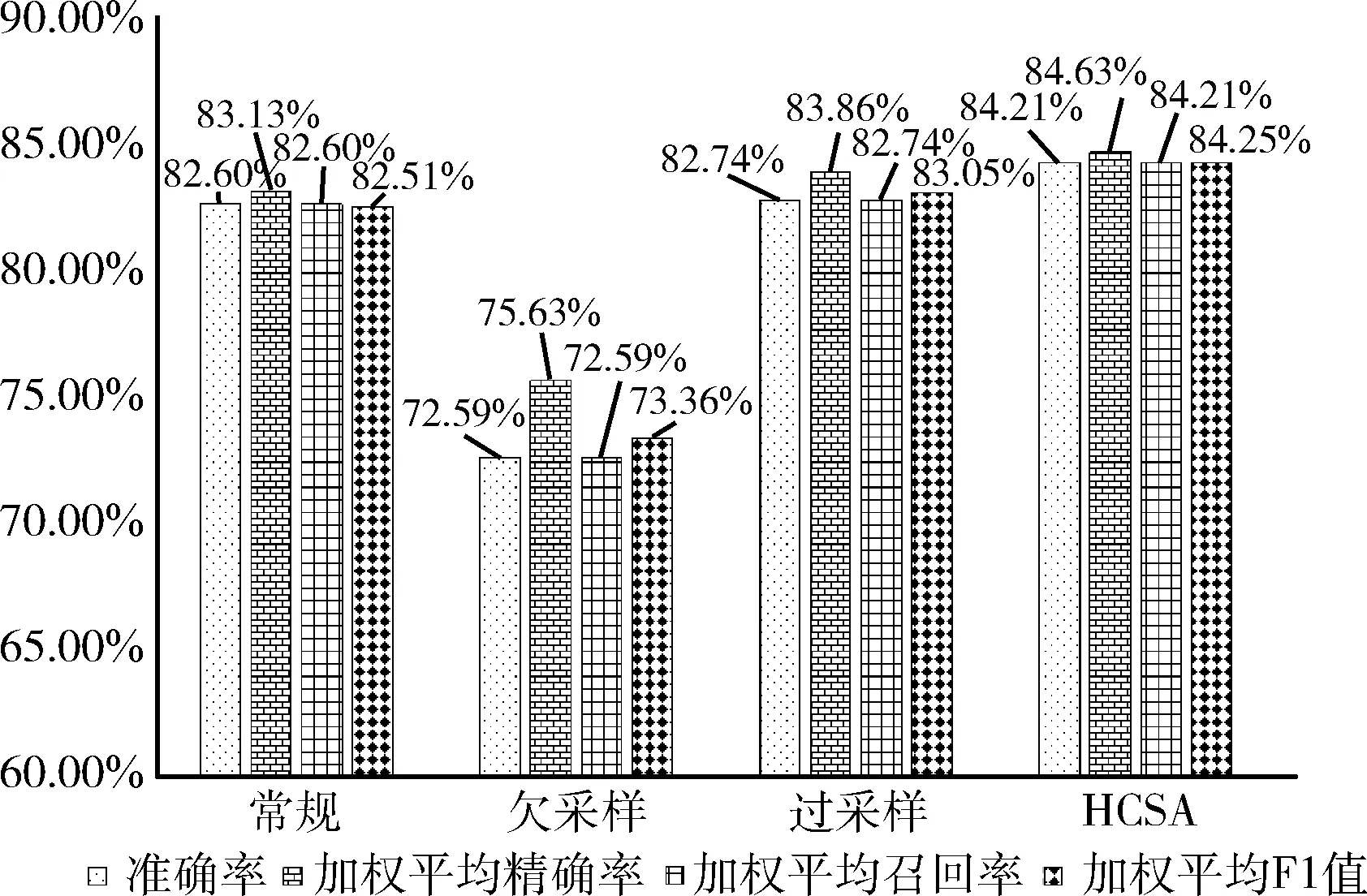
图5 加权平均指标值
上面的实验结果可以看出,通过在HCSA算法中引入动态聚类方法,能够进一步基于文本的高维特征对数据集进行区分,为欠采样和过采样提供基础,最终实现文本训练数据集中数据在高维向量空间中特征向量的平衡分布,为提高文本多分类性能提供支持。
6 结束语
本文在文本不平衡数据集的多分类算法中,引入基于轮廓系数的动态K-means聚类方法对不平衡数据集进行聚类,并利用聚类簇采用混合式采样方式,实现文本数据集的平衡分布。以微博灾害数据集为例,验证了HCSA算法在TextCNN模型上的性能。通过实验验证此算法相对常规方法、过采样和欠采样方法在准确率和F1值等方面都有性能提升。下一步工作可以针对文本高维空间的聚类方法进行优化,提升算法的执行速度,进一步提升高维度文本向量的聚类效果,提高基于文本不平衡数据集的多分类准确性。
