基于人工神经网络和遗传算法的网络攻击检测
2021-09-16罗予东
罗予东,陆 璐
(1.嘉应学院 计算机学院,广东 梅州 514015;2.华南理工大学 计算机科学与工程学院,广东 广州 510641)
0 引 言
入侵检测是网络安全领域的一个重要问题[1],传统的入侵检测系统[2]基于正常的流量数据建立模型,把与正常流量存在明显差异的行为识别成异常行为,无需网络异常行为的先验知识,即可实现较好的检测准确率,但由于噪声数据和冗余数据的影响,此类传统方法存在误报率过高的问题。
目前主流的方法是将特征选择算法和机器学习技术结合,能够有效降低入侵检测的误报率,同时提高系统的处理效率[3]。宋勇等[4]提出了一种基于信息论模型的入侵检测特征提取方法,该特征选择算法提高了入侵检测的准确率。文献[5]首先应用K-近邻模型检测并删除离群数据,有效提高了网络攻击的检测效果。文献[6]提出一种结合极限学习机与改进K-means算法的入侵检测方法。文献[4-6]分别采用搜索算法、随机森林和极限学习机3种机器学习技术,在NSL-KDD和KDD-99等数据集上完成了验证实验,这两个数据集的分类数量较少,且数据分布不平衡的程度较低。
因此本文采用MLRM[7]作为机器学习技术,将MLRM与多目标遗传算法NSGA-II结合成封装特征选择算法。再把降维后的特征子集送入感知机训练,利用重引力搜索算法搜索神经网络的参数。本算法利用NSGA-II较强的多目标优化能力,并利用了多项式逻辑回归模型较强的不平衡数据分类能力,选择的特征子集对不平衡数据具有较强的判别能力,最终实现了较好的分类性能,另外通过GSA训练技术加快了感知机的训练速度。
1 封装特征选择算法
图1是封装特征选择算法的流程,将多目标遗传算法NSGA-II[8]和逻辑回归分类器[9]组合成封装式特征选择算法。

图1 基于遗传算法和逻辑回归的封装特征选择算法
1.1 多目标遗传算法NSGA-II
NSGA-II算法通过irank和idist两个指标评价解i的质量:irank表示解i的前沿排名,idist表示解i的密度。采用快速非支配排序方法[8]计算irank,采用拥挤度计算解的idist。拥挤度表示最近两个点在前沿上的平均距离,通过拥挤度指数可维持解在前沿中均匀分布。解i拥挤度的计算式为
(1)
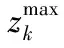
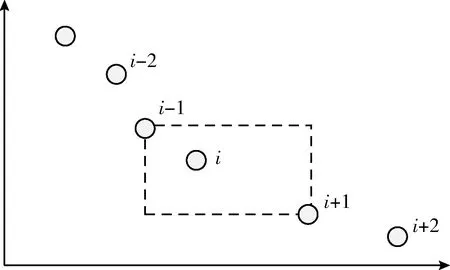
图2 拥挤度计算
NSGA-II的选择算子基于参数irank和idist实现,选择算子的规则为:选择前沿排名更高的解,如果两个解属于同一个前沿,则优先选择处于低拥挤度的解。图3是NSGA-II算法在第t次迭代的处理过程,遗传算子处理种群Pt,产生后代种群Qt,将Pt和Qt合并成大小为2N的种群Rt。使用非支配排序方法识别种群Rt中不同的前沿,采用精英机制将最优前沿的解保留到下一次迭代。

图3 NSGA-II算法在第t次迭代的处理过程
1.2 逻辑回归分类器
封装式特征选择采用逻辑回归分类器MLR评价NSGA-II选择的特征子集。使用MLR和训练集评价该模型,然后将模型在测试集上进行测试。MLR模型中模态yj的逻辑定义为
(2)
通过下式降低J-1项的概率
(3)
通过差分运算估计概率πJ。通过计算最大似然,估计出(J-1)×(N+1)个项的系数
(4)
采用牛顿迭代法[10]计算式(4)的最大似然,首先建立牛顿法的梯度向量和Hessian矩阵,将梯度向量G表示为
(5)
式中:向量Gj与模态yj相关联,Gj的维度为(N+1)×1,Gj第i个元素的计算式为
(6)
设H为Hessian矩阵,H的维度为[(J-1)×(N+1)]×[(J-1)×(N+1)],H定义为
(7)
式中:Hi,j的维度为(N+1)×(N+1),Hi,j的计算式为
(8)
式中:X=(1,X1,…,XN)是观察样本ω的表示向量。如果i=j,那么σi,j=1,否则σi,j=0。
1.3 封装式特征选择设计
针对不平衡数据分类问题,将NSGA-II和MLR结合成封装特征选择算法。特征选择的目标是以最少的特征获得最高的分类准确率,属于多目标优化问题,算法1所示是特征选择算法的步骤,通过NSGA-II搜索多目标优化问题的帕累托前沿,通过MLR评价特征的质量。
算法1随机初始化N个染色体的种群Pt,每个染色体表示一个潜在的特征子集,假设总特征数量为n,特征子集为X={x1,x2,…,xn},其中xi∈{0,1},1≤i≤n。xi=1表示特征i被选择,否则被取消。首先通过MLR评估初始化种群的染色体,将准确率和特征数量作为两个目标函数。将MLR评估过的每个子集保存于列表L,避免重复评估相同的特征子集,由此加快处理速度。采用非支配排序方法将初始化种群排序,经过遗传算子(选择算子、交叉算子及变异算子)处理产生后代种群Qt。根据非支配排列程序的排序结果直接生成第1个后代种群,选择算子选择拥挤度低的染色体,交叉算子采用概率为pc的单点交叉,变异算子采用概率为pm的随机变异。将父种群Pt和后代种群Qt合并获得Rt,对种群Rt进行非支配排序处理和拥挤度排序处理,选出排名前一半的染色体建立下一代种群。特征选择算法的结束条件为:①当前种群与下一代种群相同;②达到预设的迭代次数G。
算法1:封装特征选择算法
输入:训练数据集,测试数据集
输出:帕累托次优解集
(1)i=0;
(2)Pt=NULL;
(3)Pt+1=NULL;
(4)Evaluate(L);
(5)InitPop(Pt);
(6)Evaluate(Pt,L);//评价种群
(7)NonDomSort(Pt); //非支配排序
(8)While()do
(9) if(i>0)then
(10)NonDomSort(Pt+1); //非支配排序
(11)CrowdDistanceSort(Pt+1);//拥挤度排序
(12)Pt=Pt+1;
(13) endif
(14)GenOff(Pt,Qt); //生成后代种群
(15)Evaluate(Qt,L); //评价种群
(16)Rt=Merge(Pt,Qt); //合并种群
(17)NonDomSort(Rt); //非支配排序
(18)CrowdDistanceSort(Rt);//拥挤度排序
(19)Gen(Rt,Pt+1); //产生下一代种群
(20)i++;
(21)endwhile
2 攻击检测算法
2.1 基于多层感知机的攻击检测
多层感知机MLP具有结构简单、训练难度小的优点,因此采用MLP检测网络的攻击类型,MLP包含一个输入层I、一个隐藏层H和一个输出层O。根据数据集的分类数量决定输出层的节点数量,例如:NSL-KDD数据集共有5个分类,输出节点数量为3,输出“000”表示正常样本,“001”表示DoS攻击,“010”表示U2R攻击,“011”表示R2L攻击,“100”表示Probe攻击。图4是MLP的网络结构,在MLP输入层和隐藏层之间的权重记为Vih,隐藏层和输出层之间的权重记为Who,偏置节点和输出节点间连接的权重B1,B2,B3称为偏置权重。因此MLP共有((I×H)+(H×3)+3)个权重参数。

图4 多层感知机的网络结构
2.2 人工神经网络的训练方法
目前大多采用反向传播算法直接训练MLP分类器[11],但该训练过程容易陷入局部最优。为解决该问题,本文将重引力搜索(gravitational search algorithm,GSA)和粒子群优化(particle swarm optimization,PSO)混合来提高MLP的训练效果,简记为HPSO(hybrid particle swarm optimization),提高算法的全局搜索能力,并避免陷入局部最优。图5是基于HPSO训练ANN的流程。
图5 基于HPSO的训练流程
(1)Agent表示
GSA的每个Agent对应一个可能解,将Agent表示为向量形式:{V11,V12,…,VIH,W11,W12,…,WH3,B1,B2,B3},每个元素对应ANN的一个权重参数。Agent的长度等于[(I×H)+(H+3)+3]。
Agent解的每个元素初始化为[-1,1]的随机数,然后随机初始化每个Agent的参数,包括:速度、质量、G0、惯性权重、学习因子。图6是随机初始化Agent的一个实例。
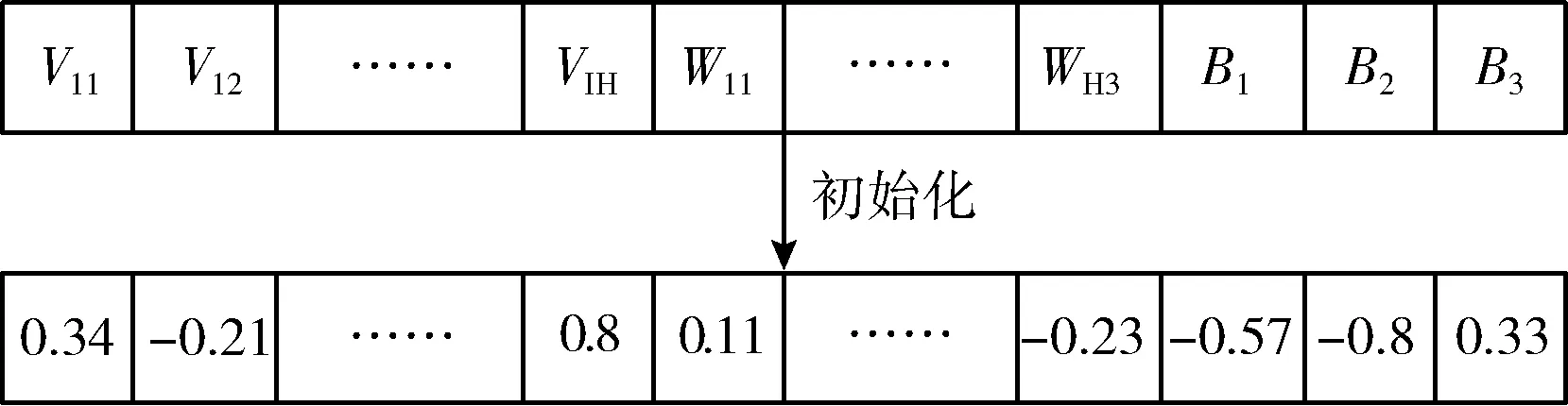
图6 随机初始化Agent的实例
(2)Agent的适应度评价
ANN采用以下的sigmoid激活函数
(9)
将网络攻击的识别准确率Det作为适应度函数,识别准确率的计算式为
(10)
式中:T表示被正确分类的样本数量,F为错误分类的样本数量。
(3)Agent更新
根据文献[12]的研究,采用对数曲线更新Agent的引力,可降低GSA陷入局部最优的概率,Agent的对数更新公式为
(11)
式中:Gmin和Gmax分别为初始化引力常量的最小值和最大值,a为加速度,t为当前的迭代次数,T为预设的最大迭代次数。
为了加快GSA的搜索速度,设计如下的速度更新公式
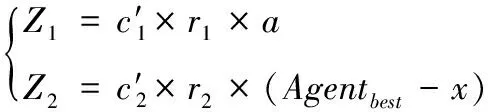
(12)
式中:c′1和c′2为加速度系数,Agentbest为目前为止的最佳Agent,x为个体最佳位置,a为Agent的加速度,r1和r2为[0,1]范围的随机数。
Agent的速度更新公式为
vt=(ω×vt-1)+Z1+Z2
(13)
式中:ω为惯性权重,vt为Agent在第t次迭代的速度。
图7是攻击检测算法的总体流程。
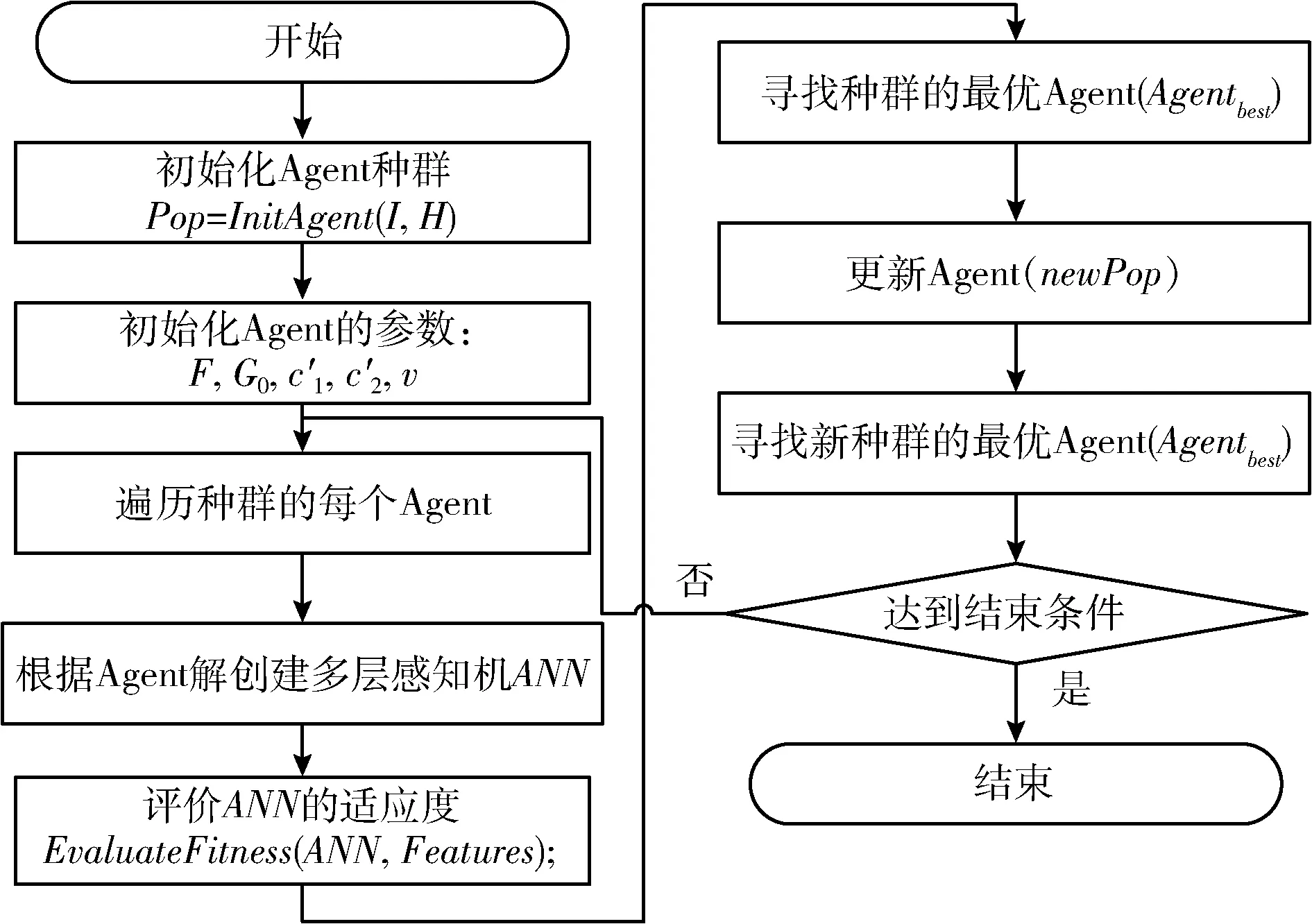
图7 攻击检测算法的流程
3 实验与结果分析
3.1 数据集简介
基于NSL-KDD和CIC-IDS 2017两个公开数据集完成算法的验证实验。KDD99数据集与其扩展数据集NSL-KDD是应用最为广泛的网络入侵数据集,但这两个数据集的版本较为老旧,所包含的攻击类型较少。因此本文也在近期的CIC-IDS2017数据集上完成了验证实验,该数据集采集了真实的网络攻击流量,且包含更多的攻击类型。
NSL-KDD数据集是经典KDD-99数据集的扩展数据集,其训练集共有125 973个样本,测试集共有22 543个样本。数据集共有41个特征和5个分类,表1是NSL-KDD数据集每个类别的分布情况,表中每个分类的所占比例显示,该数据集是一个不平衡的数据集,正常样本大约占了半数,DoS数据大约占了三分之一。

表1 NSL-KDD数据集的基本信息
CIC-IDS2017数据集包含5天时间内所采集的50 GB原始网络流量数据,该数据集利用CICFlowMeter软件[13]共提取了80余个特征,数据集的攻击流量细分成14种攻击类型:DoS黄金眼、Heartbleed、DoS Hulk、DoS Slowhttp、DoS Slowloris、SSH-Patator、FTP-Patator、Brute Force攻击、SQL注入攻击、XSS攻击、渗透攻击、Bot攻击、端口扫描攻击和DDoS。表2是CIC-IDS2017数据集每个分类的分布情况,表中每个分类的所占比例显示,该数据集是一个极为不平衡的数据集[14]。

表2 CIC-IDS2017数据集的基本信息
3.2 实验方法设计
实验环境为PC机:配置Intel Core i7 4790S处理器,3.2 GHz主频,16 GB内存,Windows 10操作系统。基于C++编程语言实现攻击检测算法。
(1)性能评价指标
首先通过分类准确率评价攻击检测的准确性,另外采用精度、召回率、F-measure、MCC(Matthews correlation coefficient)及AUC(area under curve)评价攻击检测算法的综合性能。
精度的计算式为

(14)
式中:TPi为正阳性样本,FPi为假阳性样本。
召回率的计算式为

(15)
式中:FNi为假阴性样本。
F-measure的计算式为
(16)
MCC的计算式为
------------------
(17)
------------------
式中:TNi为真阴性样本。
AUC的计算式为
式中:TPR为真正率,FPR为假正率。
(2)对比方法介绍
共采用了6个攻击检测或识别算法与本文算法比较,将本文算法简记为MGA-LR。GA-SVM[15]采用遗传算法对流量数据集进行降维处理,通过过滤式特征选择算法删除一部分冗余特征,再利用支持向量机将流量数据样本分类。GA-ANN[16]采用遗传算法对流量数据集进行过滤式特征选择,通过降维处理删除一部分冗余特征,再利用人工神经网络和支持向量机的混合模型将流量数据样本分类。PSO-ANN[17]采用粒子群优化算法对流量数据集进行降维处理,将基尼指数和决策树融合完成封装式特征选择,再对流量数据样本进行分类。GS-ANN[18]将重引力搜索算法和模糊分类器结合成封装式特征选择算法,再利用人工神经网络对流量数据进行分类。GSPSO-ANN[19]将重引力搜索算法和粒子群优化算法结合对流量数据进行降维处理,再利用多层感知机对流量数据进行分类。本文MGA-LR算法将多目标遗传算法和多项式逻辑回归分类器组合成封装式特征选择算法,再用特征集训练多层感知机,实现对网络攻击的检测与识别。
(3)实验方法与参数设置
将每个数据集随机均匀分成两个子数据集Dataset1和Dataset2。数据集Dataset1用于特征选择处理,Dataset1的50%作为训练集,另外50%作为测试集。数据集Dataset2用于分类处理,Dataset2的60%作为训练集,10%作为验证集,30%作为测试集。实验首先对网络流量数据集进行预处理,使用Weka软件[20]将数据样本和特征转换成整型数值,再将整型数值归一化至[0,1]范围。然后采用封装式特征选择算法对数据进行降维处理,并删除冗余的特征。将特征子集和训练数据送入多层感知机进行训练,利用训练的神经网络识别测试数据的类型。
通过试错实验搜索GSA算法和GA算法的最佳参数,最终相关参数的取值见表3。NSL-KDD和CIC-IDS2017数据集的GSA种群大小分别为50和80,交叉率分别为0.6和0.7。NSL-KDD和CIC-IDS2017数据集的GA种群大小分别为50和100。

表3 优化算法的基本信息
3.3 实验结果与分析
(1)特征选择结果
表4是不同算法选择的特征数量,GSPSO-ANN处理NSL-KDD数据集之后,仅保留了4个显著特征,是降维效果最好的算法。GA-ANN和MGA-LR均属于基于遗传算法的特征选择算法,两者的区别在于GA-ANN是过滤式的特征选择算法,而MGA-LR是封装式的特征选择算法,两个算法删除的维数十分接近。GA-SVM将特征判别能力作为主要目标,通过单目标遗传算法完成寻优处理,因此删除的特征数量较少。

表4 数据集的特征选择结果(特征数量)
(2)流量检测准确率
网络安全算法的首要目标是将每个网络数据实例分类,图8(a)、图8(b)分别为NSL-KDD数据集和CIC-IDS2017数据集的平均分类准确率。观察NSL-KDD数据集的结果,GA-ANN通过7个特征获得了约87.7%的分类准确率。MGA-LR通过6个特征获得了更好的分类准确率。GSPSO-ANN仅通过4个特征即获得了接近95%的分类准确率,在降维效果和准确率两个方面较为平衡。总体而言,本文MGA-LR算法在准确率性能上表现出明显的优势。观察CIC-IDS2017数据集的结果,GA-ANN通过15个特征获得了约81.5%的分类准确率。GSPSO-ANN仅通过11个特征即获得了接近84%的分类准确率,在降维效果和准确率两个方面较为平衡。总体而言,本文MGA-LR算法在不同程度的不平衡数据集上均表现出明显的优势,其原因在于NSGA-II具有较强的多目标优化能力,多项式逻辑回归模型也具有较强的不平衡数据分类能力,因此所选择的特征子集对不平衡数据具有较强的判别能力。
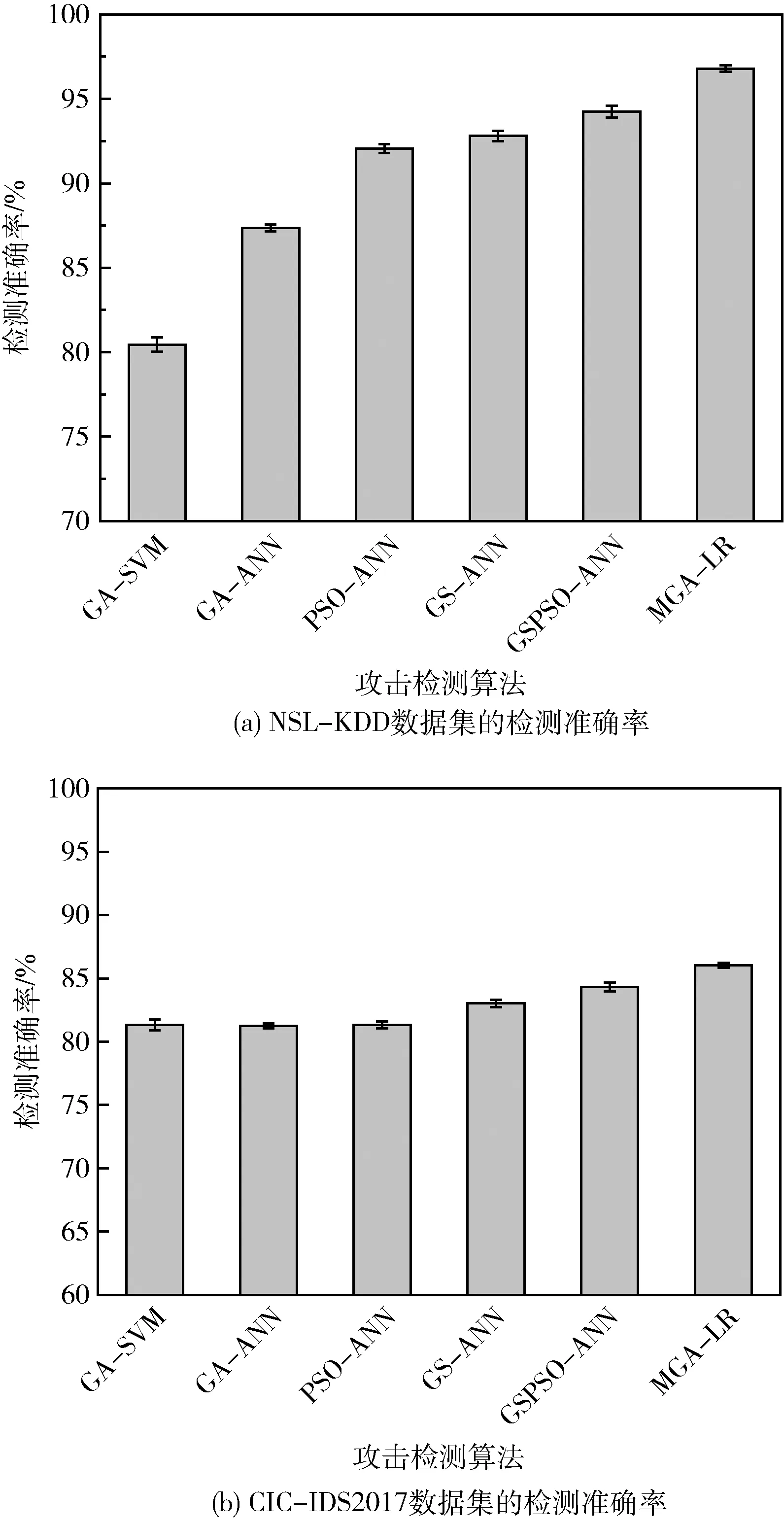
图8 检测准确率的结果
(3)攻击检测性能
上文测试了算法框架每个阶段的性能,该小节对攻击检测算法的总体性能进行实验测试。图9(a)、图9(b)分别为NSL-KDD数据集的统计性能指标,图10(a)、图10(b)分别为CIC-IDS2017数据集的统计性能指标。观察NSL-KDD数据集的结果,MGA-LR通过6个特征获得了较好的统计分析结果,但在MMC和AUC两个综合性能指标上,本文算法仍然具有一定的优势。比较NSL-KDD和CIC-IDS2017两个数据集的统计分析结果,数据集的不平衡程度越高,总体检测性能越低。本文利用NSGA-II较强的多目标优化能力,利用多项式逻辑回归模型较强的不平衡数据分类能力,选择的特征子集对不平衡数据具有较强的判别能力,最终实现了较好的分类性能。

图9 NSL-KDD数据集的统计性能指标

图10 CIC-IDS2017数据集的统计性能指标
(4)算法时间性能
时间效率是网络攻击检测算法的另一个关键性能指标,表5、表6统计了不同检测算法处理NSL-KDD和CIC-IDS2017数据集的平均时间及标准偏差,其中训练时间为全部训练过程的总时间,测试过程则是检测每个数据实例的时间。本文算法采用了结构简单的感知机神经网络,且利用HPSO对神经网络进行训练,加快了训练速度。由于本文采用的感知机具有结构简单的特点,因此算法的检测速度也较快。

表5 NSL-KDD数据集的时间性能/s

表6 CIC-IDS2017数据集的时间性能/min
4 结束语
为了提高网络攻击检测的准确率,设计了基于人工神经网络和遗传算法的混合网络攻击检测算法。该算法利用NSGA-II较强的多目标优化能力,利用多项式逻辑回归模型较强的不平衡数据分类能力,所选择的特征子集对不平衡数据实现了较强的判别能力。此外,采用结构简单的感知机神经网络,且利用HPSO对神经网络进行训练,加快了训练速度。实验结果显示,本文算法对于不同程度的不平衡数据集均表现出较好的识别性能,优于其它同类型的方法。
