基于改进FM算法和注意力机制的深度点击率预估模型
2021-09-15李兴兵续欣莹李小飞赵旭栋
李兴兵,谢 珺,续欣莹,李小飞,赵旭栋
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.太原理工大学 电气与动力工程学院,山西 太原 030024)
自2020年以来,在线广告的收入不断增长,已经发展成为一项千亿美元的业务。点击率预估(Click-through rate,CTR)在广告行业至关重要,主要目标是在适当的环境下向适当的用户提供适当的广告。广告的精准投放,依赖于预估目标受众对相应广告的点击率预估[1]。因此,广告点击率预估的效果和准确率成为人们关注的焦点。点击率预测是预测用户点击推荐项目的概率。它在个性化广告和推荐系统中起着重要的作用。目前已经有很多模型被提出来解决这个问题,如逻辑回归(Logistic regression,LR)[2],Poly2[3]模型,因子分解机模型(Factorization machine,FM)[4],梯度提升树(Gradient boosting decision tree,GBDT)+LR[5]模型。近年来,利用神经网络进行点击率估计也是这个领域的一个研究趋势,并引入了一些基于深度学习的模型,如Wide&Deep[6]模型,基于因子分解机的神经网络(Factorization machine supported neural network,FNN)[7]模型和DeepFM[8]等模型。特征学习对于CTR任务至关重要,对于排序模型来说,有效地捕捉这些复杂的特征非常重要。但是这些浅层模型,例如LR和FM等模型只对低阶特征相互作用建模有效,对捕捉高阶特征相互作用没有什么效果。基于深度神经网络的深度模型则利用多层非线性神经网络捕获高阶特征相互作用,而无法有效学习到低阶特征交互。因此,本文提出一种既能利用改进FM算法来有效学习到低阶特征又能利用深度神经网络(Deep neural network,DNN)[9]和注意力机制[10]学习到高阶特征交互的点击率预估模型——基于改进FM算法和注意力机制的深度点击率预估模型(Deep click rate prediction model based on attention mechanism and improved FM algorithm,DAHFM)。不仅增强了模型的可解释性,而且提高了点击率预估的准确率。本文的主要工作包括以下4个方面。
(1)提出了一种基于改进FM算法和注意力机制的深度点击率预估模型,通过大量实验判断其是否有效提升了点击率预估效果;
(2)全息简化表示(Holographic reduced representation,HRR)[11]的压缩外积被应用到FM中来改进FM算法从而更好地学习低阶特征,利用快速傅里叶变换降低算法的事件复杂度,使模型训练效果更快更好;
(3)利用DNN学习高阶特征,并构建合适的注意力网络来区分不同高阶特征的重要性,从而更好地利用高阶特征提高模型的准确率;
(4)应用不同数据集的实验结果表明本文提出的新模型DAHFM可以有效学习低阶和高阶组合特征,在一定程度上提高了点击率预估的效果。
1 相关工作
早期人们解决点击率预估问题的方法是构建LR模型[2],没有考虑特征间的相互关系,而且需要人工特征,但算法简单也易于调参。Poly2[3]是考虑了二阶特征的模型,它可以在一定程度上解决特征交叉组合的问题,但是此模型需要非常稀疏的特征向量作为输入,导致模型训练难度大,而且不容易收敛。2010年Rendle[4]提出FM,考虑了二阶特征的组合,模型的性能要优于线性模型,而且它的复杂性是线性的。其后,Facebook提出GBDT模型,由其中的集成决策树自动学习有效特征组合信息,然后联合LR做出预测[5],取得了不错的效果。近几年,随着深度神经网络的不断发展,其在文字、语音、图像等众多领域取得成功,人们提出了一些基于深度学习的模型来进行CTR预测。2016年谷歌提出的Wide和Deep[6]结合了LR和多层感知器(Multi-layer perceptron,MLP),其中Wide这部分采用了有比较强的记忆模型LR,而Deep端则使用了有一定泛化能力的MLP。FNN[7]同时结合了预训练的FM和MLP。2017年Guo等[8]提出的DeepFM可以同时学习到低阶和高阶特征信息,且FM部分和Deep部分共享输入和嵌入层,也加快了训练,提高了模型的效率。Wang等[12]提出的深度交叉网络(Deep & cross network,DCN)使用交叉网络而不需要人工就能自动提取显示组合特征,且网络结构简单,节省内存。Xiao等[13]提出的注意因子分解机(Attentional factorization machine,AFM)利用注意力机制对FM的二阶交叉特征进行加权有效地学习了组合特征。2018年Lian等[14]提出的xDeepFM通过一种新颖的压缩模型来模块化功能交互互动网络(Compressed interaction network,CIN)部分。2019年Song等[15]进一步提出AUTOINT模型,采用多头自注意力机制将高维稀疏特征映射到低维空间,然后自动构建特征交互。Liu等[16]提出的基于卷积神经网络的特征生成(Feature generation by convolutional neural network,FGCNN)使用卷积神经网络(Convolutional neural network,CNN)生成特征并将最新的深度分类器应用于扩展特征空间。Huang等[17]提出的FiBiNet通过双线性有效地学习特征相互作用功能。2020年Lu等[18]提出了一种双输入感知因子分解机(Dual input-aware factorization machine,DIFMs),它可以按位和向量两个层次上同时自适应地重新加权原始特征表示。Tao等[19]提出基于高阶稀疏特征交互的模型(High-order attentive factorization machine,HoAFM),将高阶特征交互注入到特征表示学习中,以建立具有表达性和信息性的交叉特征。杨妍婷等[20]提出一种基于增强型因子分解向量输入神经网络的广告点击率预测模型,在基于因子分解向量输入神经网络的基础上增加了新特征生成层,采用一种针对CTR数据的卷积操作,对数据进行通道变换后引入Inception结构进行卷积,将生成的新特征和原始特征结合,提升了深度网络的学习能力。2021年Deng等[21]提出DeepLight模型通过在浅层组件中显式搜索信息特征交互,修剪DNN冗余参数和密集的嵌入向量,加速模型训练。Zhu等[22]提出了一种新的解耦自注意力神经网络(Disentangled self-attentive neural network,DSAN)模型,通过解耦技术来促进学习特征的相互作用。本文采用改进的FM算法全息因子分解机(Holographic factorization machine,HFM)[23],将HRR用于FM中,因为HRR[11]可以表示压缩的外积,可以帮助模型获得更好地表示,从而更好地学习到低阶特征得到更好的实验效果。同时结合DNN学习高阶特征,利用注意力机制[10]处理来自不同层次的分层特征,然后自动选择出占优势的特征从而提升模型预测的准确率。
2 基于改进FM算法和注意力机制的深度点击率预估模型
本文所提出的DAHFM模型结构如图1所示。

图1 DAHFM模型结构
图1中包括6大部分,分别为:(1)输入层,稀疏特征由输入层输入;(2)嵌入层,将高维稀疏特征转换成低维稠密向量输出;(3)HFM组件,利用HRR[11]算法改进FM,不仅可以建模一阶特征,还可以高效地获取二阶特征表示;(4)注意力层,加权平均来判断不同特征之间交互的重要性,突出优势特征;(5)隐含层,对输入特征多层次的抽象,使不同类型的数据得到更好的线性划分,从而更好地学习高阶特征;(6)输出层,将模型通过一系列操作得到的低阶和高阶特征信息通过Sigmoid函数做归一化输出。
2.1 输入层
点击率预估输入的稀疏特征首先需要经过独热编码[24]使其转化为独热向量,首先将用户的个人资料和商品的属性表示为一个稀疏向量。输入数据有两种值,第一种是数值,例如,[年龄=54]。第二种是分组分类值,例如,[职业=学生]或[专业=计算机]。分类值可以直接转换成二进制向量表示。通常情况下模型的输入是高维稀疏的,将x∈RD表示为稀疏特征向量,其中D表示特征空间的维数。对于CTR预测,这里假设y∈{0,1}表示用户是否点击了给定的项目。如果y=1则表明用户点击了该广告,y=0表明用户没有点击。
2.2 嵌入层
嵌入是指将高维稀疏特征转换成低维密集向量的常用技术[25]。嵌入层的输出可以看作K×F矩阵,其中每一列都是一个嵌入向量,K是嵌入层的维数,F是特征字节的个数。通过E=[e1,e2,…,eF]表示嵌入。其中:ei∈RK表示嵌入向量,K是一个超参数,表示嵌入的维数。
2.3 HFM组件
FM是因子分解机,它的数学表达式为
(1)
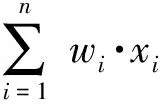
(2)
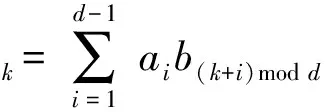
(3)
式中:★:Rd*Rd→Rd表示循环相关算子CCOR;⊗:Rd*Rd→Rd表示循环卷子算子CCOV。有了式(2)和(3)两个算子,假设有一个m,如果
m=a⊗b
(4)
a★m≈b+n
(5)
式中:n为噪声,式(4)和式(5)也被称作为相关性提取,CCOV和CCOR可以作为编码解码对,再引入联想记忆运算符,那么
m=a1⊗b1+a2⊗b2+a3⊗b3
(6)
这样计算任一b都会相对容易,比如希望计算b1,只需要计算a1★m就可以得到一个带有噪声的b1。最简单计算外积和压缩外积需要的时间复杂度都为O(n2),但是在这里,可以利用快速傅里叶变换(Fast Fourier transform,FFT)在O(nlogn)的运行时间内计算得到结果
a⊗b=F-1(F(a)⊙F(b))
(7)

(8)
式中:F和F-1分别为傅里叶变换和傅里叶逆变换,⊙为哈达玛乘积,也就是矩阵对位相乘。最终选取快速傅里叶变换的实数值作为输出。通过FFT可以将HRR的计算时间复杂度压缩为O(n),提高了模型的效率。再看CCOV和CCOR的计算,发现它们就是在把外积压缩为向量表示,一方面可以节省大量内存,另一方面,相较于FM直接内积求和,压缩外积可以获得更多的信息,得到更强的特征表达,因而获得更佳的效果。此处将HRR替换FM中的内积的形式,得到HFM表达式
(9)

m=α12(v1⊗v2)+α13(v1⊗v3)+…
(10)
式中:αij表示特征对(xi,xj)的交互,因此只需要计算v1★m,就可以得到v2,v3,…,vn的组合信息。利用HFM组件对RK的嵌入向量进行操作,得到2K个v,最后使用式(9)计算得到结果并输入到下一层。
2.4 隐含层
这部分的输入是上文定义的嵌入E。实际上,这里连接嵌入向量
H0=contact(e1,e2,…,eF)
(11)
这里采用了一个前馈神经网络,所有隐藏层的大小相同。设Hk表示隐藏层,其中k=1,2,…,L。Hk∈Rd,其中d是超参数。隐含层神经网络的结构如下
H1=Relu(W(0)H0+b(0))
(12)
Hk+1=Relu(W(k)Hk+b(k))
(13)
隐含层最终的输出是把不同层的输出连接起来作为一个总的输出。隐藏单元是高阶特征交叉,它比低阶相互作用包含更全面的信息。随着层越来越深,隐藏的单元会呈现更高阶的特征。那么总的输出表达式为
OutL=[H1,H2,…,HL]
(14)
式中:L是网络的深度。然后将隐含层的输出送入注意力层。
2.5 注意力层
注意力机制的核心思想在于:让不同输入特征对结果的贡献程度不同,主要突出更加重要的特征。本文采用一种使用注意力机制的解决方案处理隐含层输出的高阶组合特征,实现高阶特征整合。不同层的分层权重可以定义为
α′k=〈h,Relu(WaHk+ba)〉
(15)
(16)
式中:Wa∈Rd×e,d表示每一层隐藏单元的数目,ba∈Re,h∈Rd,e表示注意力网络中隐藏单元的数目。利用Softmax函数的特性来对注意力机制的得分进行归一化处理,使用Relu[26]函数作为激活函数。α代表层与层之间的层次关系。于是注意力层的输出就可以定义为
(17)
Sigmoid函数表达式为
(18)
2.6 输出层
经过HFM得到的低阶特征信息和经过注意力层输出的高阶组合特征信息经过Sigmoid函数输出,最终得到组合预测模型表达式
p=Sigmoid(HFM(x)+OutA)
(19)
式中:HFM(x)代表HFM组件的输出,OutA表示注意力层的输出。
2.7 模型分析
本文所提出的模型DAHFM在输入层和嵌入层上与DeepFM类似,学习低阶特征和高阶特征两部分共享同样的输入,不仅节省了内存而且提高了模型的训练效率。由式(1)可知,FM的算法时间复杂度为O(n2),但本文采用的HFM算法时间复杂度由式(7)、式(8)和式(9)可知,通过快速傅里叶变换可以将HRR的计算时间复杂度压缩为O(n),相较于传统的FM效率更高,算法的复杂度也更加小。这样不仅节约了整个模型的计算资源,也降低了模型训练的计算代价。DNN与注意力机制的结合不仅可以有效学习到高阶组合特征,而且对不同高阶特征重要性进行区分,更加利于高阶特征的表达,使得模型的准确率更好。对模型整体来说,DAHFM模型不仅分别有效学习了低阶特征和高阶特征,而且也降低了时间复杂度,提升了训练效率和模型点击率预估的效果。
2.8 损失函数和模型过拟合解决方法
为了对模型的权重和参数更好地学习,本文使用对数损失函数LogLoss作为模型的目标函数,其公式表示如下
(20)
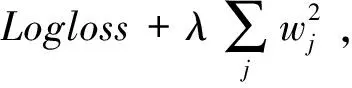
3 实验
本次实验的实验环境是Windows 10操作系统,I5处理器,基于Python3,Tensorflow2.0框架。为了验证本文所提模型DAHFM的性能,本节在两个公共数据集上进行了大量的实验来证明所提模型的总体性能,并与现有的一些模型进行了比较。
3.1 数据集和评价指标
本文使用两个数据集,第一个是Criteo数据集,它包含一个在线广告服务的7天点击日志,有超过4 500万个样本,每个样本包含13个整数特征和26个分类特征。第二个是MovieLens-1M数据集,MovieLens-1M数据集含有来自6 000名用户对4 000部电影的100万条评分数据。其中评分得分数值从0到5,在分类过程中,将评分小于3的样本视为负样本,因为分数低表示用户不喜欢这部电影。同时将评分大于3的样本视为阳性样本,并移除中性样本,即评分等于3的样本。对于这两个数据集,将数据随机分为训练集(70%)、验证集(20%)和测试集(10%)。本次实验采用LogLoss和AUC[30]作为评价指标,其中LogLoss的计算公式见式(20),AUC是指ROC曲线下面积,它是随机选择的正样本比随机选择的负样本更高分数的概率。AUC的大小与模型性能的优劣呈正相关。
3.2 实验对比方法简介
在实验中,将本文所提出的模型DAHFM与其他7个不同方法的模型进行了比较,以下是这些模型的简介。
LR:LR[2]是工业应用中最广泛使用的线性模型。它易于实现,训练速度快,但不能捕捉非线性信息。
FM:FM[4]使用因子分解技术来模拟二阶特征相互作用。对于稀疏数据具有很好的学习能力。
AFM:AFM[13]是捕捉二阶特征相互作用的最先进的模型之一。它通过使用注意机制来区分二阶组合特征的不同重要性,从而扩展了FM。
Wide&Deep:Wide&Deep[6]包括Wide和Deep部分,其中Wide部分模拟线性低阶特征相互作用,Deep部分模拟非线性高阶特征相互作用。然而,大部分仍然需要特征工程。
DeepFM:DeepFM[8]结合了FM模型和DNN模型在特征学习方面的优势。可以同时学习低阶和高阶特征交互,而且显著减少了特征工程工作量。
DCN:DCN[12]将Wide&Deep中的Wide部分替换为由特殊网络结构实现的Cross,自动构造有限高阶的交叉特征,并学习对应权重,不需要手动特征工程。
AutoInt:AutoInt[15]提出了一种基于自注意力神经网络的新方法,它可以自动学习高阶特征交互,并有效地处理大规模高维稀疏数据。
3.3 实验参数设置
Dropout大小设置为0.5,优化器为Adam[31],激活函数是Relu[26],学习率为0.001。
3.4 对比实验及结果
表1中AUC1、AUC2和LogLoss1、LogLoss2分别表示模型在Criteo和MovieLens-1M数据集上的AUC和LogLoss。
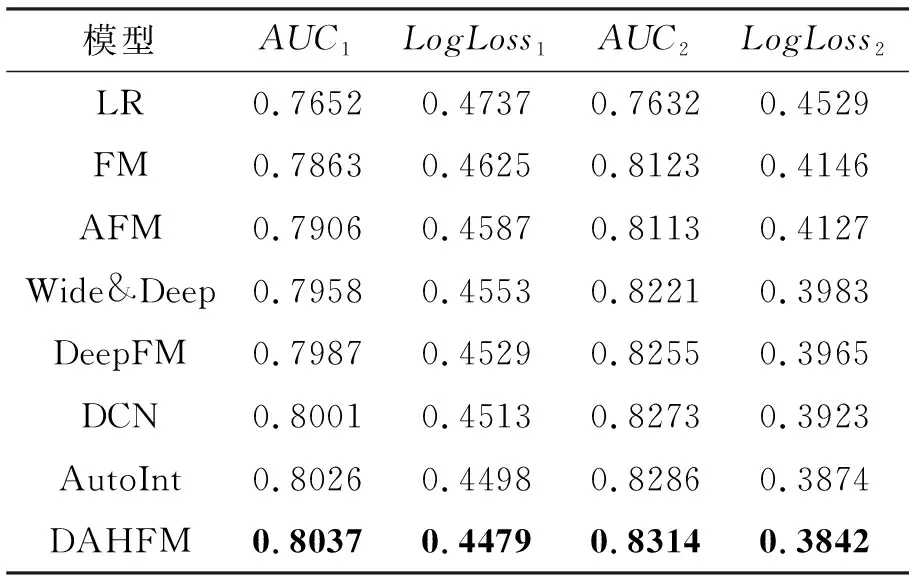
表1 不同模型在两个数据集上的表现
由表1可知,作为唯一一个不考虑特征交互的模型,LR与其他模型相比表现最差。说明同时并适当地学习高阶和低阶特征交互作用,可以提高点击率预测模型的性能。由图2和图3可以直观地看出,与其他模型相比,DAHFM在Criteo数据集和MovieLens-1M数据集上的表现也更好。由此可见,同时有效学习高阶和低阶特征信息,提高了点击率预测模型的性能。

图2 不同模型在Criteo上的表现

图3 不同模型在MovieLens-1M上的表现
3.4 超参数
本节研究在Criteo数据集上DAHFM模型的不同超参数对点击率评估结果的影响。这里选取AUC作为评价指标。主要对以下超参数依次实验:(1)Dropout;(2)隐藏层数量;(3)注意力网络的层数。
3.4.1Dropout
Dropout指的是一个神经元在网络中保留的概率。它是一种折衷神经网络的精度和复杂性的正则化技术。这里将Dropout分别设置为1.0、0.9、0.8、0.7、0.6、0.5。如图4和图5所示,当Dropout在0.6到0.9时,所有深度模型都能达到各自的最佳性能。实验结果表明,在模型中设置合适的Dropout可以增强模型的鲁棒性,从而提升了模型的性能,使最终的点击率预估效果更好。

图4 不同深度模型在不同Dropout下的AUC

图5 不同深度模型在不同Dropout下的LogLoss
3.4.2 隐藏层数量
如图6和图7所示,增加隐藏层的数量可以在一开始提高模型的性能,但是如果隐藏层的数量不断增加,会出现过拟合现象,从而使模型的性能下降。这也说明了设置合适的隐藏层数量对模型的性能提升是有益的。

图6 不同深度模型在不同隐含层数量下的AUC

图7 不同深度模型在不同隐含层数量下的Logloss
3.4.3 注意力网络的层数
表2中AUC1和AUC2分别表示模型在Criteo和MovieLens-1M数据集上的AUC。
由表2可以看出,随着注意力网络层数的增大,模型性能可以继续提高。但注意力网络层数过大会造成过拟合使得预测的准确率降低,这也证明了适当的注意力网络层数会提高模型的性能,提高点击率预估的准确率。
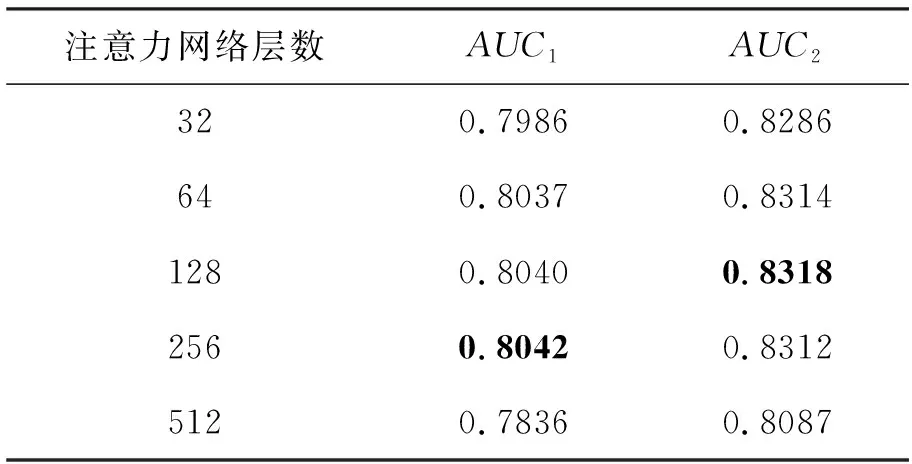
表2 不同注意力网络层数下DAHFM在两个数据集上的AUC
4 模型关键组件效果分析
4.1 实验设置
本文提出的DAHFM模型可以划分为3大部分,第一部分是HFM[23]组件,第二部分可以理解为DNN[9],第三部分为注意力网络(Attention net),故模型关键组件可以分为以下几类:
(1)HFM[23]组件单独作为一个模型;
(2)DNN[9]模块单独作为一个模型;
(3)HFM组件+注意力网络作为一个模型,简写为AHFM;
(4)DNN+注意力网络组成一个模型,简写为ADNN;
(5)HFM组件+DNN构成一个模型,简写为DHFM。
表3中AUC1、AUC2和LogLoss1、LogLoss2分别表示模型在Criteo和MovieLens-1M数据集上的AUC和LogLoss。

表3 关键组件在两个数据集下的表现
4.2 实验结果分析
由表1和表3可知HFM的性能比FM的性能好,其中在Criteo数据集和MovieLens-1M数据集上HFM的AUC分别比FM提高了0.8%和0.5%,而且LogLoss分别降低了0.7%和0.6%;这也验证了HFM算法是优于FM的。从图8和图9可以看出AHFM的性能优于HFM,ADNN的性能优于DNN,DAHFM的性能也比DHFM好。这也说明加入了注意力网络的模型是优于没有加入注意力机制的。证明了合适的注意力网络能够有效提升模型的性能,增强模型的点击率预估能力。从图8和图9也可以直观地看出后4个深度模型DNN、ADNN、DHFM、DAHFM的性能优于前两个浅层模型AHFM和HFM,这说明了深度神经网络的优越性,它能够学习到浅层模型学习不到的高阶特征,虽然DNN和ADNN只学习到了高阶而没有学习到低阶特征,但他们的性能也比HFM和AHFM的性能好,这充分证明了高阶组合特征的重要性。但是低阶特征也不能忽视,由表3可知,DAHFM模型的性能优于其他的消融模型,因为它不仅学习到了低阶特征而且也充分重视了高阶特征组合对模型性能的影响,使用深度神经网络对高阶特征建模,又加入注意力网络区分不同高阶组合特征的重要性,突出更加有用的高阶交叉特征,不仅增强了模型的性能也提高了模型的可解释性。通过消融实验也证明了HFM组件,DNN和注意力网络对模型性能的重要性,融合了这3部分的DAHFM模型也明显优于其他的消融模型。

图8 关键组件在两个数据集下的AUC
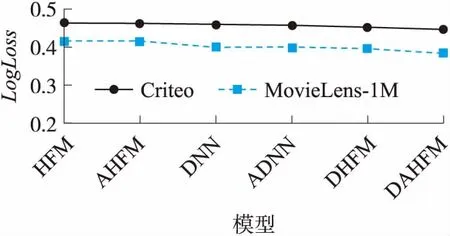
图9 关键组件在两个数据集下的LogLoss
5 结束语
针对目前点击率预估模型难以充分学习低阶特征也难以有效模拟高阶交叉特征的非线性关系,本文提出了一种基于注意力机制和深度学习的点击率预估模型DAHFM。首先通过改进的FM算法HFM对低阶特征信息进行学习,通过实验证明HFM算法相对FM更好地学习了低阶特征。其次,利用深度神经网络来学习高阶特征信息,并加入注意力网络区分不同高阶组合特征的重要性,提高了高阶特征学习的效率。最后,构建同时学习低阶特征和高阶组合特征的模型来对广告点击率做预估。在Criteo和MovieLens-1M数据集上的大量实验结果表明了相对其他浅层和深层模型,DAHFM的性能更加优异,点击率预估的效果也更好。
模型关键组件效果分析实验也表明,无论是低阶还是高阶特征的学习都对模型的性能以及点击率预估的准确率至关重要。因此下一阶段的研究将更加注重对特征的学习,不断研究新的特征学习方法来优化和改进现有模型,从而提高点击率预估效果。
