基于YOLO算法的无人机航拍图像车辆目标检测系统研究*
2021-09-15向昌成黄成兵
向昌成 黄成兵 罗 平 王 朋
(阿坝师范学院计算机科学与技术学院 汶川 623002)
1 引言
随着无人机技术在生活中应用的不断深入,航拍在军事侦察、交通管制、国土资源、环境监测等军事与民用领域有着十分广阔的应用前景[1]。其中地面车辆目标检测技术作为智慧城市重要组成,为智能交通系统感知外界环境提供基础。城市车辆数量的增加催生我国智慧交通发展与构建。对于智慧城市交通的构建,通过航拍手段完成对车辆目标的跟踪与定位作为主要技术研究点,该点技术可以更加准确地传递城市交通信息与交通情况。
针对无人机航拍图像地面车辆目标实时检测问题,传统的SIFT算法复杂度高,处理时间长,难以满足实时性的要求。基于文献[2]可知,通过SIFT算法可以将矩形区域内的特征点进行成像,通过降维处理实现对相似度与距离、余弦相似度等数据的匹配,然后基于RANSAC算法完成对错误匹配点的剔除,改进的SIFT算法在尺度缩放、旋转、光照等情况下均有良好的匹配效果,该改进算法针对大视角变换误匹配率还比较高[2]。文献[3]着重针对地面车辆目标的自动监测效果进行研究,通过固定的无人机平台与无人机实际姿势情况进行控制,明确像素面积范围以及特征目标内的数学形态,进而对现场所出现的疑似目标进行剔除与更加准确的甄选,提高系统对于整体疑似目标的判断与追踪效果,算法可靠稳定具有很好的鲁棒性,但系统的准确率不高[3]。文献[4]将视觉注意力机制中的显著性模型同DPM相结合,对目标区域内的检测干扰情况进行排除,进而有效地缩小特征取值范围,解决图像中不同尺寸车辆目标检测的问题,但目标的检测率不高[4]。文献[5]中针对航拍图像与实际车辆目标进行追踪处理,通过手工标注的方法确定整个道路区域内的标准情况,然后针对区域内的阈值分割方法进行控制,然后针对弱小的车辆目标进行检测,有效地解决遥感图像道路内的分割困难情况,在弱小车辆难以出现检测问题的时候应当对目标进行提取与控制[5]。在对目标特征提取与检测的过程中要注意对特征训练的分离,而在这个过程中,由于人工提取的特征不足,就会导致信息之间的分类无法恢复,从而无法达到深度学习以及主流检测的效果,也就不能满足检测与识别需求,因此,现阶段深度学习就成为了主流方式内容[6]。通过交通视频可以准确地识别实际车况与道路情况,从而在应对众多因素影响的条件下保证其识别精度与检测效果[7]。深度学习的物体检测方法大致可以分为两类:第一类是基于区域建议的目标检测算法,也就是Faster RCNN[8];第二类是基于回归的目标检测算法,主要代表算法是Faster RCNN[9]。深度学习的卷积神经网络(Convolutional Neural Networks,CNN)以其局部感知权值共享的特点,成为目标检测领域的核心算法之一,使得深度学习算法在很多应用场景替代了传统的目标检测算法。基于区域建议的目标检测算法RCNN中将CNN的思路引入到检测内容中,针对高鲁棒性模型的训练完成对目标区域内的检测效果,保证检测区域的主流性,而通过RCNN的实行可以在样本信息中提取出神经网络样本,在无法更新的条件下实现对独立网络以及判断结果的输出控制,进而保证YOLO的核心检测思想与检测速度,降低无减率,而在YOLO的特点中,小目标效果本身存在一定的缺点,为了有效地改进这些缺点情况,基于文献[10]的内容可知,通过RPN结构可以完成SSD结合网络模型的建立与训练[10],而针对目标精度情况来看,测试速度与实际测试精度之间有所差异,因此就如同文献[11]中的内容,基于YOLOv2的网络构架中,检测精度与速度是基于检测方法与训练条件而生成的,而在训练过程中由于通过算法YOLO9000完成检测[11],因此可以更好地实现实时检测效果。根据物体检测过程中RCNN系列的高精度模式来看,检测速度与精度相较于Faster-RCNN更低,但是YOLO在使用过程中由于其速度的优势,在嵌入式系统的实现中使用更方便。
针对无人机航拍图像中的车辆目标检测问题进行研究,有研究人员应用SSD方法是车辆目标检测[12],网络划分思想是基于卷积网络中的多个尺度内容进行预测控制的,在不同尺寸目标中,一定程度上为了实现对目标精度的提高,就需要进行分类预测,但算法在TensorFlow运行环境搭建,不能实现实时运行处理。文献[13]针对YOLO算法进行对多尺度特征层的检测与处理,在原基础上进行检测与设计,通过对网络模型的训练与不同方法速度的控制,检测得出高准确率与高召回率的车辆目标效果。对于一些遮挡严重的车辆,检测效果尚未达到最佳[13]。文献[2]将深度学习算法YOLOv2引入混合交通的车流量检测中,并在嵌入式平台RK3399上实现了该算法。由于YOLOv2是NVIDIA Titanic-X GPU中实时检测的主要算法流程,但是根据RK3399中的长时间检测算法,可以进一步调整其检测速度与算法的效果[14]。因此,本文在保证一定检测效果的同时降低了计算时间,满足实时处理的要求,以YOLOv3目标检测网络为基础实现地面车辆目标检测技术,在GPU服务器上对地面车辆目标进行离线训练,通过自学习和迭代优化网络神经元权重,并进行合理的参数调节以自动学习车辆特征,得到针对特定应用场景的网络模型;然后在嵌入式GPU平台上部属训练好的网络模型,进而完成对无人机地面车辆目标的自动检测与识别,提高无人机航拍精度,并在基于GPU的嵌入式GPU系统上对1080P的高清航拍视频达到实时处理的应用。
2 YOLO v3目标检测网络模型
针对无人机航拍图像与车辆的实际目标目的来看,优先采取YOLOv3检测算法作为地面车辆目标算法,在大尺度变化条件下应当针对地面车辆的实际高度与尺度变化情况进行控制,对检测算法的尺度不变性要求较高,同时,地面车辆目标在无人机航拍大视场图像中属于小目标,特征提取的质量则直接影响分类器是否能找到目标。YOLOv3在解决这些问题上具有优势,YOLOv3在多个尺度的特征图上检测目标,能减弱目标尺度变化对检测性能带来的影响。传统的YOLOv3的网络架构如图1所示。
YOLO本身属于回归问题,而以小网格的形式实现对图片的划分,进而预测不同目标边框,有效的S*S*(B*5+C)个张量。基于YOLO在图1中所呈现出的流程架构图,每个小网格中所预测的概率大概在20类左右,而基于一张图像可以完成对图像的980个概率预测,49个网格中的大部分区域内是没有物体的,因此图像本身在大部分区域内的预测概率就为0,在长期变量的条件下,对这些问题的解决,可以保证在不同位置中物体存在概率的确定,其概率为Pr(Object)。从某区域内的实际情况来看,在不同概率的预测中,某一位置的非条件性预测概率为Pr(Object)与条件概率的乘积。pr(〖class〗_i)=pr(〖class〗_i|object)*pr(object)针对不同位置情况来看,Pr(Object)的更新应当基于物体本身存在的Pr(Dog|Object)进行更新。而在最后一层预测网络概率与边框情况来看,基于逻辑激活函数条件,对于其他层来说,主要使用ReLU函数。YOLO的网络损失函数是基于平方误差进行表示的,通过对尺度因子λ的引入,提高对类概率与边框误差的加权,进而更好地反映出大边框补偿条件下的影响效果。
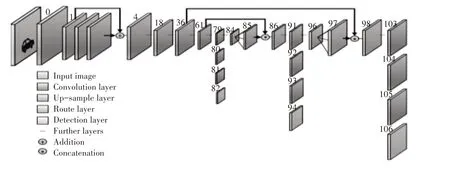
图1 YOLOv3的网络模型
2.1 k-means的锚节点聚类算法
YOLO算法和Faster RCNN算法在训练过程中,使用了锚节点机制进行目标的初步预测。Faster RCNN算法需要手动设置锚节点框的尺寸大小和个数作为网络的训练参数,而YOLO通过对训练数据集使用k-means聚类算法,得出锚节点框的尺寸大小和个数,送入网络进行训练,使得网络更容易学习到目标特征,网络训练时间得到大幅缩减。标准的k-means算法将距离作为聚类的准则,这使得大目标比小目标产生更多的错误,而本文采用k-means+YOLO聚类方法,对数据集中的目标大小进行聚类,来得到锚节点的预设置参数。使用如下的函数作为聚类的准则:
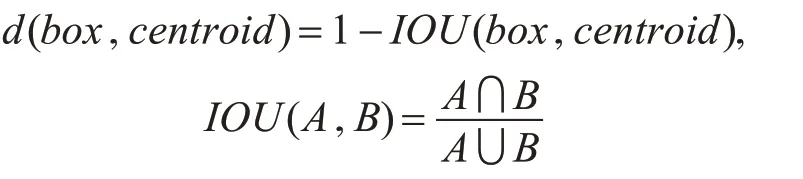
2.2 边界框的预测
边界框的预测跟YOLOv2中一样,仍使用维度聚类方法,先在样本上使用k-means聚类得到锚节点。使用逻辑回归而不是Softmax对每个框进行分类,这是考虑到自然场景图像中物体之间重叠很常见,使用Softmax在每一个框上只能给出最大的类别,导致重叠的漏检,使用多个单独的逻辑回归(主要用到了sigmoid函数)预测替代了之前的Softmax分类。最终有三个分支输出做预测,输出的特征图大小分别为13*13,26*26,52*52,每个特征图使用三个锚节点,13*13的特征图使用(116×90)、(156×198)、(373×326)这三个锚节点;26*26的特征图使用(30×61)、(62×45)、(59×119)这三个锚节点;52*52的特征图使用(10×13)、(16×30)、(33×23)这三个锚节点。
2.3 检测模块
YOLOv3在三个不同的尺度上进行目标的预测,最后预测出三维的张量代表边界框。在COCO数据集上,我们在每个尺度上预测的三个候选框的张量是N×N×[3*(4+1+80)]。共可以检测80类目标。
3 实验设计与实现
3.1 实验数据集的获取
使用无人机平台对某城镇附近场景进行视频拍摄制作数据集。通过无人机可以实现对每隔1s提取一帧的视频拍摄,而在3000张图片中,拍摄的彩色图片尺寸为1920×1080。在对图片记性标记的时候选择Labelimage软件进行标记,每隔图片所选用的文件格式为.xml。图片数据集在增强之后,通过对图片的数据量变换与训练增强,保证图片集本身的效果,提高网络模型的泛化能力,并且通过增加噪声数据,提升网络模型的鲁棒性。本文主要使用的数据增强方法有旋转、缩放、裁剪得到近30000张图片,大小为1000×600。将27000张图片作为训练样本,将其制作成voc数据集的格式。将剩余的3000张图片作为测试集。
3.2 网络模型训练
在YOLO算法的骨架网络Darknet-53使用正态分布初始化模型参数。在ubuntu操作系统下,基于darknet框架采用darknet53骨干模型和Xavier初始化方法,在imagenet1000分类数据集上进行预训练,得到预训练权重darknet53.con.74。然后,从训练集图片顺序打乱,将训练集的图像输入到网络当中进行运算得到模型的预测结果,根据预测结果和真实标注值计算预测误差,使用链式法则和反向传播方法进行对误差的求取,然后通过对参数梯度与下模型参数的控制,完成整体的训练迭代过程。对以上步骤进行迭代,直到误差收敛时完成训练,保存模型参数文件(.weights文件)。
3.3 网络参数的评估
每次训练结束后,用测试集测试网络的性能,将采用PASCALVOC07的评估方法评价检测结果。保存结果在log.txt中,包含训练epoch次数,训练误差,学习率等。分析检测评估结果,从网络架构、网络参数、训练流程等方面对网络进行优化式改进。最终挖掘网络对地面汽车目标检测方面的性能。经过70000次训练之后,损失在3.5左右不再变化,停止训练。
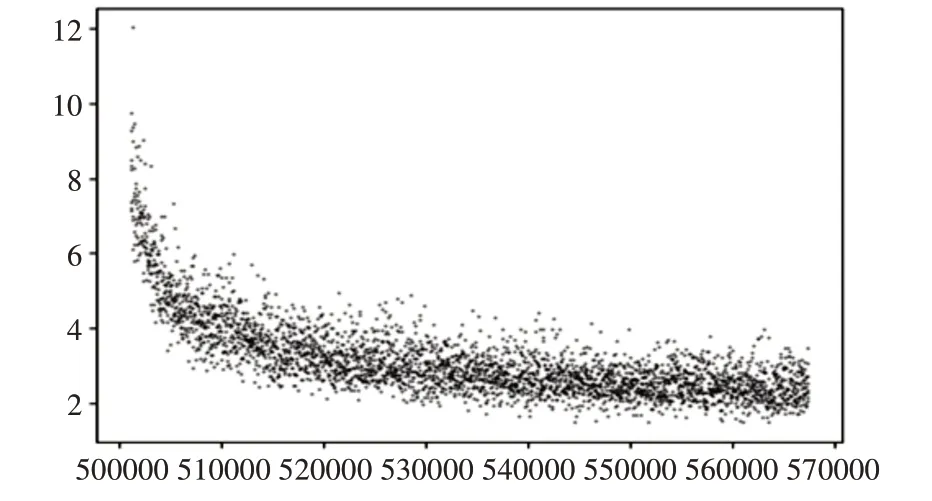
图2 网络训练损失函数趋势图
3.4 网络检测结果
将测试集图像数据输入到训练好的网络模型中,进行网络性能测试。通过对主要准确度的评价,进行对准确度AP评价,明确其召回率与准确度对立关系,指标升降存在差异,而后对准确率与召回率曲线下的面积进行控制,为其算法指标准确度AP进行控制,在多个类别中完成mAP的平均值。AP@0.5为在IOU=0.5阈值时的指标。网络测试结果为在IOU=0.5时的召回率83.25%和准确度67.14%,处理时间35.8ms。

图3 基于YOLOv3网络模型的检测结果
4 硬件配置
4.1 网络训练服务器
深度学习开发平台主要有GPU服务器组成,硬件配置为CPU:Intel Xeon Gold 5118(12核,2.3GHz),内存:64G DDR 4,硬盘:512GB固态硬盘+4TB SATA,GPU:NVDIA TITAN V*2,显示器:24英寸液晶显示器*2。操作系统:Windows7 SP1 64位、Ubuntu 16.04 lts,安装cuda 10.1,cudnn 7.5.0并行计算库,安装Darknet环境。
4.2 网络检测嵌入式系统
本文检测时采用NVIDIA TX2嵌入式平台,它也可以作为一个可开发的工具箱,在硬件配置上,支持2.5Gbps/Lane的CSI摄像头传输,支持与其他设备的802.11ac的无线连接和蓝牙连接,配有8GB的内存和32GB的外部存储器。在性能上,NVIDIA TX2平台包含了一个四核2.0GHz的64位ARMv8 A57处理器,一个双核2.0GHz的ARMv8丹佛处理器,256核的Pascal GPU,6核心的处理器和GPU共享8G的内存,可以面对不同的应用场景需求。在以NVIDIA TX2平台为核心的目标系统中搭建Darknet,植入最终训练好的网络参数文件,输入无人机航拍的视频图像,运行YOLOv3算法,实现25帧/s的地面车辆目标识别与检测。
5 结语
本文设计了一种基于YOLOv3深度学习网络模型的无人机航拍图像地面车辆的目标检测嵌入式GPU系统。采用YOLOv3网络模型目标检测算法,在GPU服务器上实现了从输入图片到输出结果的端到端的网络模型训练和优化。首先在预设置参数阶段采用了kmeans_YOLO聚类算法对数据集进行聚类,实现对锚节点参数的设置,然后采用了网络特征提取框架,针对网络训练与预测速度进行加快,减少参数量,有效地实现对图片的提取,得到最终训练好的网络模型,提高了地面车辆目标的检出率,在IOU=0.5时的召回率为83.25%,准确度为67.14%。在NVIDIA TX2平台上实现了25帧/s的检测速率,基本满足地面车辆目标检测的需求。为以后深度学习的目标检测在智能交通、智能安防和无人机上的应用提供了基础。
