基于SSD算法的智能定员检测研究*
2021-09-15陈响洲杨余旺沈兴鑫
陈响洲 杨余旺 沈兴鑫
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
生产线上,为了保证生产的效率和安全,对人员进行人数限制自然也是生产安全的一个重要组成部分。随着生产线规模的不断加大,安全问题逐渐凸显,为了弥补人工监控的低下效率和节约人工资源,生产线定员检测成为一个关键问题。
生产线定员检测本质上属于目标检测范畴,目标检测是计算机视觉领域的一个重要研究方向。随着近年来深度学习的快速发展,采用基于深度学习的算法进行目标检测已成为计算机视觉领域的重要方法。
在目标检测领域,传统的目标检测方法通常采用区域选择、特征提取、分类器分类的步骤流程进行检测[1],但是,传统的目标检测方法存在着两个主要的缺陷[2]:1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;2)手工设计的特征对于多样性的变化并没有很好的鲁棒性,因此,传统的目标检测的速度和准确度均较低。近年来,深度学习的快速发展给目标检测领域注入了活力,在准确度和速度方面均取得了突破。Girshick等[3]提出的R-CNN算法采取聚类的方法对图像分组,得到多个候选框的层次组,在PASCAL VOC2007上的mAP比传统目标检测方法高出31.7%。Purkait[4]提 出 的SPP-NET算 法 解 决 了R-CNN区域提名时的偏差问题,大大加快了检测速度。Ren等[5]提出了Faster R-CNN算法引入了多任务损失函数,简化整个网络的训练和测试,提高了检测的速率。Redmon等[6]在YOLO算法基于回归思想,将目标检测任务转变为回归问题,实现了一个可以一次性预测多个Box位置及类别的卷积神经网络,使检测速度有了明显的提升。
虽然这些算法在目标检测的速度或精度上分别取得了很高的成绩,但是无法同时满足高精度和实时性要求,所以难以应用于实际生产。之后,Liu等[7]在YOLO和Faster R-CNN的基础上提出了SSD算法,在精度和速度方面取得平衡,为实际应用奠定了基础。SSD算法是目前最优秀的目标检测算法之一,仅仅使用一个全卷积网络就能同时完成分类和定位任务。该算法融合了YOLO的回归思想和FasterR-CNN的anchors机制,在提高mAP的同时兼顾速度,两者同时取得了优秀的成绩。SSD算法凭借高实时性和高准确度的特点被广泛应用在实际生产中。高英杰等[8]基于SSD算法实现对水下目标的检测分析;陈亮杰等[9]通过SSD算法对仓储物体进行检测;杨建等[10]则是在方坯号识别系统中通过SSD算法进行分析检测。
本论文提出了一种基于SSD算法的生产线定员检测算法,该算法使用ResNet101卷积神经网络和添加卷积层提取图像特征,解决了传统SSD算法小尺寸目标检测率低的问题,准确率相比传统SSD算法提高了5.3%。
2 基于SSD算法的生产线定员检测
本章主要从SSD网络结构、图像特征提取网络、损失函数、训练阶段和检测阶段五个方面介绍算法的原理和实现。
2.1 SSD网络结构
SSD是基于一个前向传播卷积神经网络进行提取不同尺寸的特征,产生一连串大小固定的边框,以及相应包含目标实例的概率,最后进行一个非极大值抑制来得到最佳的预测值,完成对目标的检测和定位。SSD使用通用分类网络作为基础网络,然后在这个基础网络的基础上增加附加的卷积层,传统SSD网络结构图如图1所示。SSD结合多尺度特征响应图共同检测,保证了不同尺寸特征信息量的保留。
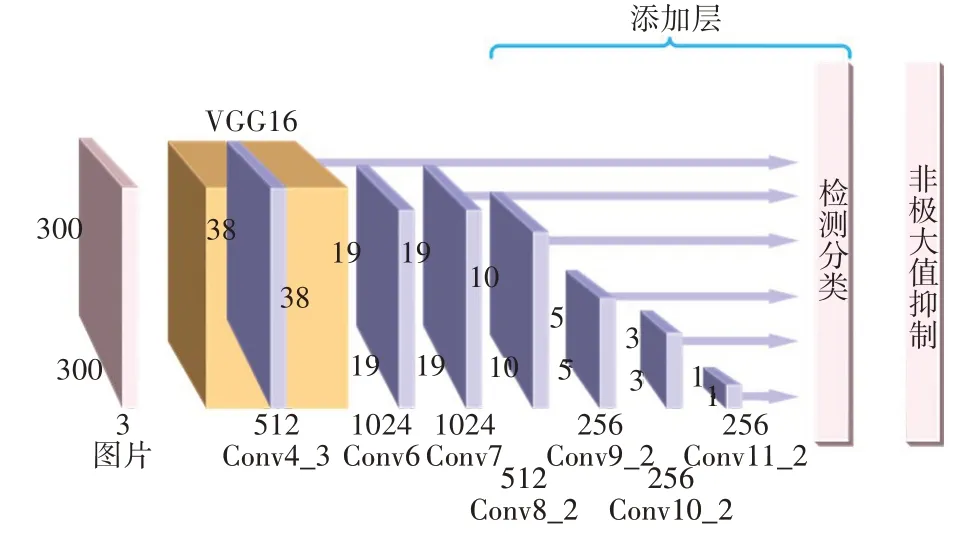
图1 传统SSD网络结构图
2.2 图像特征提取网络
SSD算法的图像特征提取网络通过不同分辨率的特征提取层提取多尺度特征,然后产生一连串大小固定的边框和相应包含物体实例的概率。
目 前 主 流 的 卷 积 神 经 网 络 有AlexNet[11]、GoogleNet[12]、VGGNet[13]、ResNet[14]等。传统SSD算法采用VGG16网络和附加卷积层进行图像特征提取。但由于传统的SSD算法使用VGG16网络中的Conv4_3低级特征层去检测小尺寸目标,而低级特征层卷积层数较少,特征提取并不充分,因而导致缺乏高层语义特征,所以传统的SSD算法对小尺寸目标检测的准确度难以令人满意。
2015年,ResNet在ImageNet上打败VGG等其他卷积网络,成为冠军。为了改善传统SSD算法对小尺寸目标的检测效果比较差的问题,所以便需要提高浅层的特征提取能力。Resnet-101相比VGG16而言,增加了残差模块,特征提取能力有了很大的提升,所以在本文中选择了ResNet101网络和附加卷积层进行提取图像特征,网络结构图如图2所示。
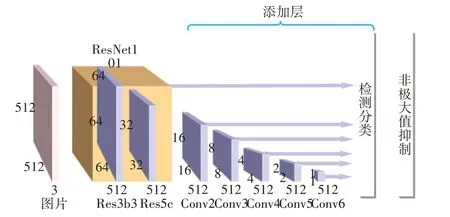
图2 SSD_ResNet网络结构图
为了加快网络的收敛速度,将所有图像大小统一设置为512×512和300×300两种,便于后期的数据分析处理。同时为了保证与SSD_VGG16模型对应的各个特征提取层的特征图大小大致相仿,各个模型选取的特征提取层如表1所示。

表1 各模型特征提取层对比表
2.3 损失函数
SSD损失函数是置信度损失(confidence loss)和位置损失(location loss)的加权和,其表达式如下:
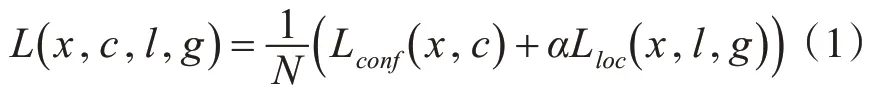
其中式(1)中N是与真实框(ground truth)相匹配的候选框数量;而α参数confidence loss和location loss加权比例,默认α=1。
置信度损失(confidence loss)是多类Softmax损失,其表达式如下:
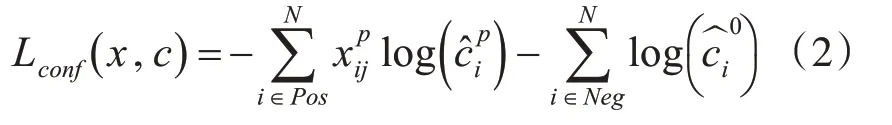

位置损失(location loss)是真实框和候选框参数之间的smoothL1损失,其表达式如下:
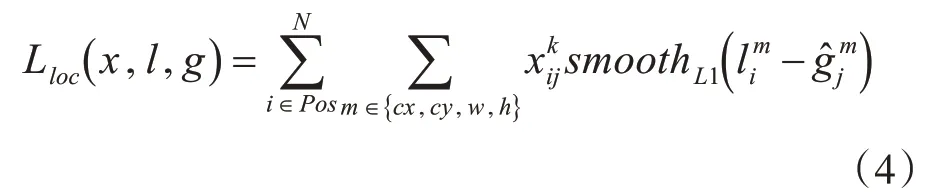
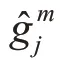

其中式(4)中smoot hL1可表示为
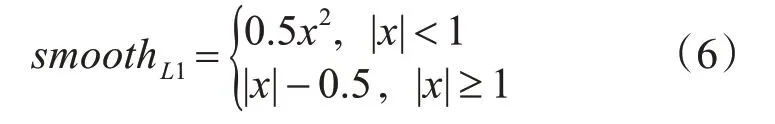
2.4 训练流程
SSD网络的训练系统结构框图如图3所示,训练过程主要由输入、特征提取、预测器、区域候选框匹配四个模块组成。训练流程如下。
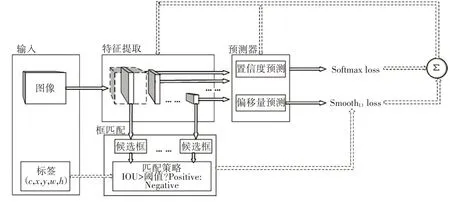
图3 SSD网络的训练系统结构框图
1)输入训练图片,进行前向传播;
2)设置不同长宽比,不同尺度的区域候选框;
3)真实框(ground truth)和区域候选框匹配,保证每个真实值都至少有一个对应的区域候选框;
4)预测器输出每个区域候选框的类别置信度预测和位置偏移量预测;
5)计算损失函数并反馈调节对应权重。
重复步骤1)到5),直到训练目标函数误差趋于稳定停止。
2.5 检测流程
输入图片后,经过前向网络传播,所有区域候选框会产生类别概率预测值和位置偏移量预测值,根据设定好的阈值,删除概率预测值低于阈值的框,即认为这些框中没有目标,是背景。然后经过非极大值抑制[15]去除多余框,留下最终的检测结果。
3 实验结果与分析
本章主要从实验环境、实验数据集和实验结果与分析三个方面对算法有效性进行试验验证。
3.1 实验环境
本文实验在Ubuntu16.04操作系统下基于Caffe深度学习框架完成,采取双GPU进行训练,运行环境基本配置为
GPU型号:NVIDIA GeForce GTX 1050 Ti;
CPU型 号:Intel E5-2670;
内 存:128G;
显 存:4GB×2;
驱动版本:425.31;
CUDA版本:CUDA 10.0。
3.2 实验数据集
本文实验所需数据均为模拟生产线环境下通过摄像机采集获得的人员视频,然后为防止样本重复,以30s为间隔切割生成图像,并采用图像标注工具Label Img进行标注,创建一个人员数据集,其包含4500张图像。将人员数据集分为训练集、验证集和测试集,训练集约占60%,验证集约占15%,测试集约占25%。
3.3 实验结果与分析
由于实验设备的限制,本实验设置Batch_size为16。同时由于数据集仅有人一类,所以设置num_class为2,初始学习率为0.001。
为了验证本文算法的有效性,在人员数据集上分别输入两种不同大小的模型,训练并测试得到生产线人员准确率mAP(mean Average Precision),实验结果如表2所示。
由表2实验结果表分析可知,在相同的图像大小的情况下,SSD_ResNet模型的mAP明显高于SSD_VGG模型的mAP,这种情况在图像大小为512×512的情况下尤为明显,因此说明浅层更具有表征能力时,对小目标效果就会更好。同时,在相同的卷积网络提取特征的情况下,由图像大小为512×512得到的模型的mAP高于由图像大小为300×300得到的模型的mAP。

表2 实验结果表
由于篇幅所限,仅给出SSD_ResNet_512模型的部分生产线人员检测测试图,如图4、图5所示。在图4、图5中可以明显看出,该模型对于不同姿态的人员和不同大小的人员都有准确的检测。

图4 生产线人员检测测试图A

图5 生产线人员检测测试图B
在基于SSD目标检测算法的基础上,本文使用ResNet卷积网络在生产线人员数据集上,图像大小为512×512的情况下训练得到的模型mAP达到了87.7652%,基本符合生产线定员检测的要求。
4 结语
本文提出了一种基于SSD目标检测算法的生产线定员检测,通过在ResNet101网络和添加的卷积层上选取适合的特征层进行提取多尺寸图像特征,然后产生一连串大小固定的边框和相应概率,最后使用非极大值抑制法得到最佳的预测值,实现对生产线人员数量实时监控,并且在实验中SSD_ResNet模型取得了最高87%的mAP,从而满足生产线定员检测的要求。然而,本文算法对于人数较多的生产线环境下,容易出现漏检现象,推测很可能是由于人员遮挡率过高所引起。因此,针对人员遮挡问题,下一步采取基于多目摄像头的目标检测方法进行进一步研究。
