基于改进tiny-YOLOv3的车辆检测方法*
2021-09-15王孝兰王岩松马明辉窦雪婷
王 硕 王孝兰 王岩松 马明辉 窦雪婷
(上海工程技术大学机械与汽车工程学院 上海 201620)
1 引言
随着人工智能的发展,自动驾驶引起了研究者的广泛关注[1],智能车辆是汽车行业未来发展的必然趋势。前方道路环境的感知作为自动驾驶车辆路径规划、决策控制的基础,成为智能车领域的研究重点。其中,车辆作为主要交通参与者,对其准确、实时的检测在环境感知中至关重要[2]。
车辆检测的方法主要分为基于传统算法和深度学习两种。传统的前方车辆检测算法可以分选取感兴趣区域[3]、从候选区域提取特征和建立分类器三个步骤。常用的特征有HOG[4]、haar-like[5]和LBP[6]等手工特征,并根据SVM[7]、Adaboost[8]等方法进行分类,完成车辆检测。但由于目标遮挡、光照变化以及背景干扰等因素影响,人为设计的图像特征鲁棒性差,难以表达所有情况下的目标特征,影响分类器的性能,传统算法无法满足日益复杂的交通环境。
随着深度学习技术的发展,基于深度卷积神经网络的车辆检测方法成为一个新的研究方向。该检测方法主要可分为两类,一类是基于区域推荐的两步方法,文献[9]提出的R-CNN方法首先使用区域推荐产生候选区域,针对每一个候选区域通过CNN提取特征,将特征送入SVM分类器来判断目标类别,最后利用线性脊回归器对候选区域的位置进行调整。随后,在此基础上何凯明等不断做出改进,提出SPP-net[10]、Fast R-CNN[11]、Faster R-CNN[12]与Mask R-CNN[13]等目标检测方法,在目标检测方面取得很好的检测效果。但由于两步法网络结构复杂,实时性难以保证而较难实现应用。另一类是基于回归方法的一步方法,代表有YOLO[14]、SSD[15]等。2016年Redom J提出了YOLO(You Only Look Once)检测算法,将检测问题作为回归问题处理,通过分割图像为若干个单元格,每个单元格直接负责预测目标位置信息与类别信息,更加准确地获取了图像局部信息,大大降低了背景的误检率,提升了检测速度。但是存在检测精度与召回率不高的问题,Redom等通过正则化、维度聚类等方法对YOLO进行改进,提出了YOLOv2[16],在VOC2007数据集上,测试速度为67帧/s时,mAP(mean Average Precision)为76.8%,效果显著。2018年4月,YOLO发布第三个版本YOLOv3[17],在COCO数据集上的mAP由YOLOv2的44.0%提高到57.9%,但是由于网络的加深,计算量增多,算法的实时性较差。而SqueezeNet[18]、MobileNet[19]、tiny-YOLO[20]等方法网络结构简化,拥有更少的卷积层,降低了计算量,可以有效地提高检测速度,但牺牲了检测精度。
为实现复杂环境下的前方车辆准确实时检测,本文提出了基于改进tiny-YOLOv3的车辆检测算法。以tiny-YOLOv3网络为基础,将前方道路图像中的车辆作为目标,改进网络结构,在保证原检测速度的同时提升检测精度降低模型大小,使其满足车辆检测的实际需求。通过对比试验,验证本文提出方法的有效性和准确性。
2 前方车辆检测模型
2.1 tiny-YOLOv3原理
YOLO算法将检测问题作为回归问题处理,在保证检测精度的同时提升检测速度。对YOLO网络进行简化,得到主干网络为7个卷积层与6个池化层的tiny-YOLO网络,在牺牲检测精度的同时,极大的提高检测速度。随后YOLO通过不断改进,已经发展到第三代YOLOv3,相应地也提出tiny-YOLOv3。
Tiny-YOLOv3采用13层的特征提取网络,在目标检测阶段原始图像经过缩放后划分为S×S的等大单元格,每个单元格负责预测中心落入其中的目标物体的位置信息与类别信息,具体包括B个候选框及其置信度分数,以及C种类别的条件概率。每个候选框预测5维信息,即坐标(x,y)、目标的宽w和高h与置信度,分别记为tx,ty,tw,th,obj_conf。置信度公式为
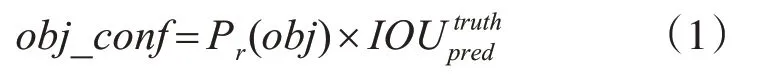
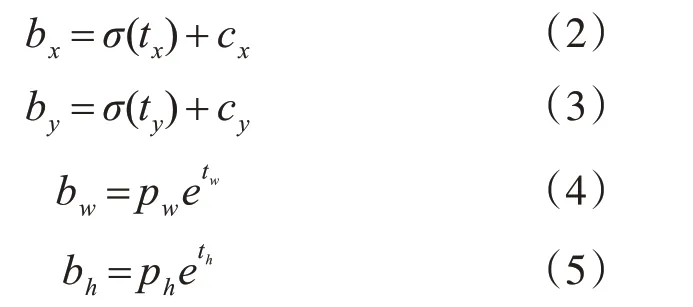
当多个候选框检测到相同目标时,tiny-YOLOv3使用非极大值抑制方法过滤阈值较低的候选框,得到最佳的目标候选框。
2.2 Inception模型结构
在传统的卷积神经网络中,大尺寸的卷积核的计算量很大,Google Inception Net提出的Inception结构通过多层小尺寸的卷积核来代替大尺寸卷积核,减少计算量与参数量达到简化模型和节省硬件资源的目的,其一种Inception v2模块结构如图1所示。一共包含四个通道,第一个通道通过1×1的卷积核提取特征,提高网络的表达能力;第二个通道先通过池化提取特征信息,再通过1×1的卷积核控制输出的升维和降维;第三个通道先使用1×1的卷积核减少参数,再使用3×3尺寸的卷积核提取特征;第四个通道与第三个通道类似,通过多加一个3×3尺寸的卷积核得到不同尺度的特征;最后将四个通道的输出通过聚合操作进行合并。Inception v2模块通过两个3×3尺寸的卷积核代替v1中5×5尺寸的卷积核,减少网络模型参数并加强非线性的表达能力,通过四个不同尺寸的特征提取操作增加网络对于不同尺度的适应性。
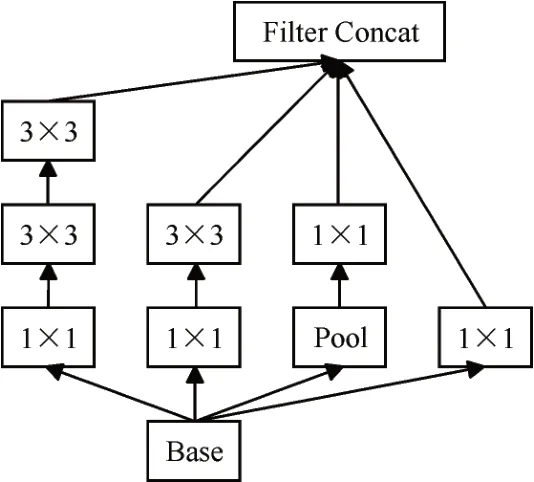
图1 Inception模块结构
3 算法改进
3.1 改进的tiny-YOLOv3网络
由于前方道路图像中的车辆尺寸与比例不固定,当目标较远时或车辆互相遮挡重叠时,极易漏检或将车辆判断为其他类的目标物体。tiny-YOLOv3网络作为针对多类别目标检测的一种简化网络,在检测前方道路车辆已经取得了较好的实时性,但网络的层数较少,很难对车辆目标特征有较好的提取效果,因此存在对小目标定位精度差、车辆目标识别率低、误检或重复检测等问题。为进一步加强对目标的检测能力,本文借鉴Inception模块对tiny-YOLOv3网络进行改进,用Inception v2模块替换tiny-YOLOv3的特征提取网络,并结合上下文相同尺度的特征图增加检测尺寸,提升网络特征提取能力的同时,降低模块参数,具体网络结构如图2所示。
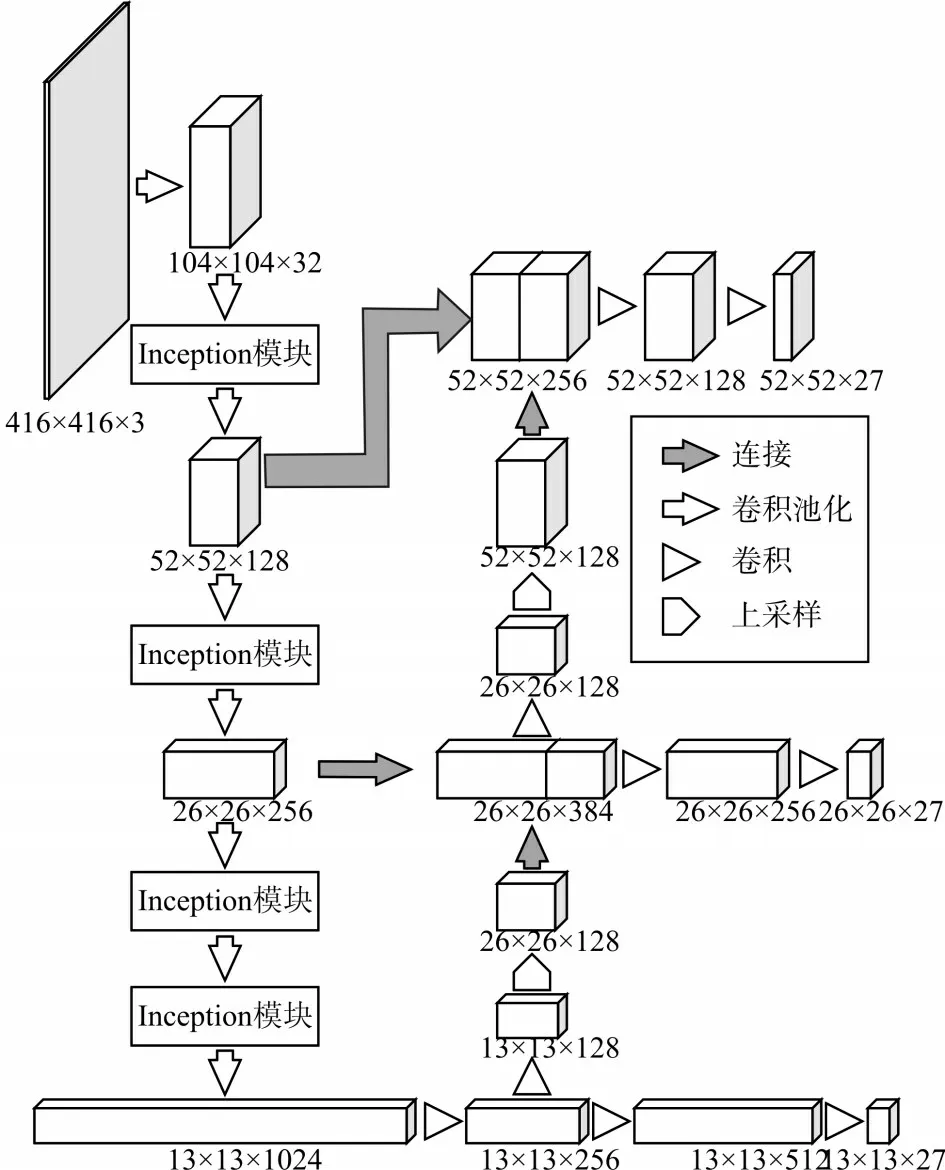
图2 INt-YOLOv3网络结构
网络的具体实现过程如下:当输入图片尺寸为416×416时,通过两组卷积层和步长为2的池化层后得到104×104×32的特征图。采用三个相同的Inception模块替代原网络中的卷积层和池化层,降低特征图尺寸和增加特征图通道数,分别得到52×52×128、26×26×256、13×13×512三个不同尺度的特征图;改变Inception模块中卷积层的步长为1得到13×13×1024的特征图;在原有的tiny-YOLOv3网络检测部分对13×13×128、26×26×128尺寸的特征图进行2倍上采样得到26×26×128和52×52×128的特征图,帮助网络学习细粒度特征,并结合上下文信息分别与特征提取部分26×26×256和52×52×128的特征图融合,得到26×26×384和52×52×256的特征图。获取13×13×512,26×26×256,52×52×128三组尺度的特征图,组成最终的特征表达。对三组尺度的特征图分别通过三个相同通道数的卷积层进行预测输出,卷积层的通道数为(5 +4)×3=27。本文称该网络结构为INt-YOLOv3。
3.2 网络训练
YOLO系列算法采用候选框的思想,通过在数据集上进行聚类确定候选框,提升检测精度。以矩形框的平均交并比IOU作为相似度对前方车辆目标训练集的所有目标标注使用K-means聚类方法获得候选框的尺寸。使用递增的方法选择k值,得到IOU与k的关系如图3所示。考虑到网络的计算量,且改进的tiny-YOLOv3网络中使用在三种尺度上进行预测的方法,最终采用k=9的聚类结果,9个候选框尺寸分别为(20,25),(35,39),(66,46),(50,71),(92,81),(141,116),(99,173),(199,183),(228,325)。在每个尺度上的每一个单元格借助三个候选框预测三个边界框。
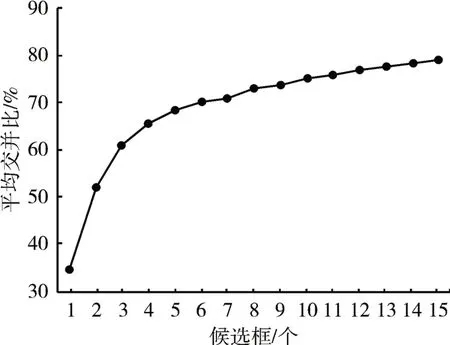
图3 K-means聚类
以开源的深度学习框架Darknet为基础,改进的tiny-YOLOv3网络结构为模型,结合聚类分析和多尺度训练的方法,训练车辆检测器。训练时模型的初始学习率设为0.001,在25000和35000次迭代后,学习率乘以0.1,动量系数为0.9,权值衰减系数为0.0010,最大迭代次数为50000次。每训练10批次随机选取新的图片尺寸进行训练,使模型对于不同尺寸的图像具有更好的检测效果。采用图像随机调整曝光、饱和度、色调等方法对数据进行扩充。
4 实验结果与分析
4.1 实验平台与数据集
实验平台配置为Windows 10操作系统,Inter Core i5-8400处理器和16GB内存,搭载NVIDIA GeForce GTX1070Ti显卡,配置英伟达CUDA9.0和GPU加速库CUDNN7.0,配置OpenCV 3扩展库,深度学习框架为Darknet。
本文采用的车辆检测数据集为KITTI数据集。KITTI数据集包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中包含车辆和行人等各种目标,还包括光照变化、背景斑杂和树木房屋等对目标各种程度的遮挡与截断等情况。根据实际应用场景,本文对KITTI数据集原有的8类标签信息进行处理,保留实验需要的4个类别标签,即:Van,Car,Truck和Tram,同时选取该数据集中7481张图像作为实验数据,根据实验需求将其标注为PASCAL VOC2007数据集格式,其中80%作为训练集,20%作为验证集。
4.2 实验结果与分析
本文采用均值平均精度(mAP)、交并比IOU、模型大小和检测帧率四个评价指标。部分衡量指标计算公式如下:
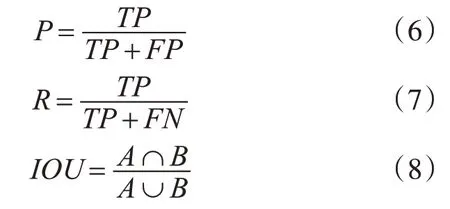
以本文所研究的前方车辆目标类别为例,式中TP表示正确预测车辆目标类别的数量,FP表示将负样本预测为正样本的数量,FN表示将正样本预测为负样本的数量,P表示准确率,R表示召回率,准确率与召回率越高则算法越具有优越性,A表示预测的目标尺寸,B表示目标的真实值,IOU越高则算法定位越精确。
表1显示了YOLOv2、tiny-YOLOv2、tiny-YOLOv3与本文提出的INt-YOLOv3方法的实验结果。这些方法均使用本文选取的KITTI数据集进行训练与测试。从表中可以看出,本文提出的INt-YOLOv3获得了89.66%的mAP,相对于tiny-YOLOv3网络准确度提升了5.75%。对比tiny-YOLOv2、tiny-YOLOv3卷积网络层数相对较少,车辆特征提取不足,而INt-YOLOv3网络通过增加网络宽度与检测解决了这个问题,因此对车辆特征的表达能力优秀。
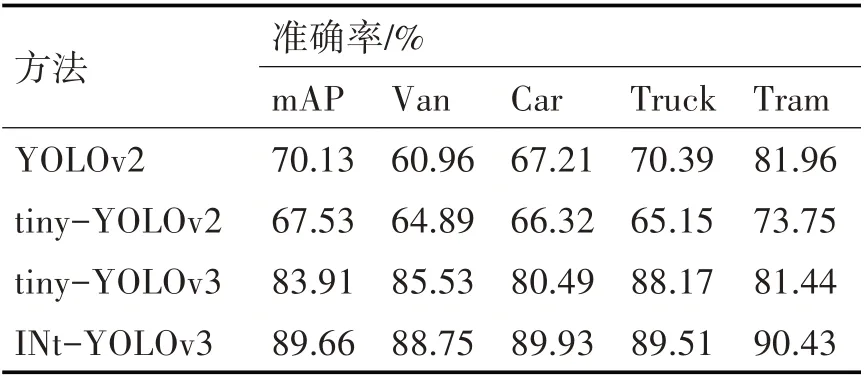
表1 不同方法在KITTI测试集上的测试结果
为了验证文中设计的INt-YOLOv3网络的定位准确性,利用平均交并比作为指标进行评测。本文在数据集上分别训练了YOLOv3网络和tiny-YOLOv3网络作为INt-YOLOv3网络的对照,并使用数据集中测试集测试平均交并比。对比结果如表2所示。
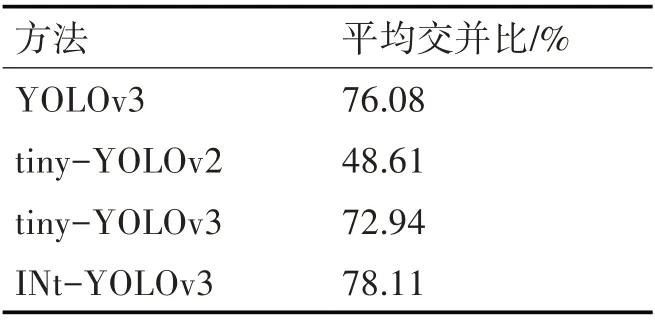
表2 平均交并比测试结果
结果表明,相比较于YOLOv3网络,INt-YOLOv3网络平均交并比提高了5.24%;相比较于tiny-YOLOv3网络,INt-YOLOv3网络平均交并比提高了8.38%。这说明,在测试集上INt-YOLOv3产生的候选框与原标记框的交叠率更高,对车辆定位的精度更好。原因在于,通过对数据集的K-means聚类分析选择合适尺寸的候选框以及网格尺寸的改进,可以更好地提升模型的定位精度。
使用预设网络参数在训练阶段得到网络模型的权重,在输入为416×416时比较YOLOv2、YOLOv3、tiny-YOLOv2、tiny-YOLOv3与本文提出的INt-YOLOv3方法的模型大小和检测帧率。
其结果如表3所示,通过对比发现,本文提出的方法检测帧率远超实时性要求,仅比原方法降低了5 f·s-1,但模型大小减少了11MB,反映了本文提出的方法复杂度更低,网络模型参数更少,对硬件要求低,更便于部署使用到实际场景当中。
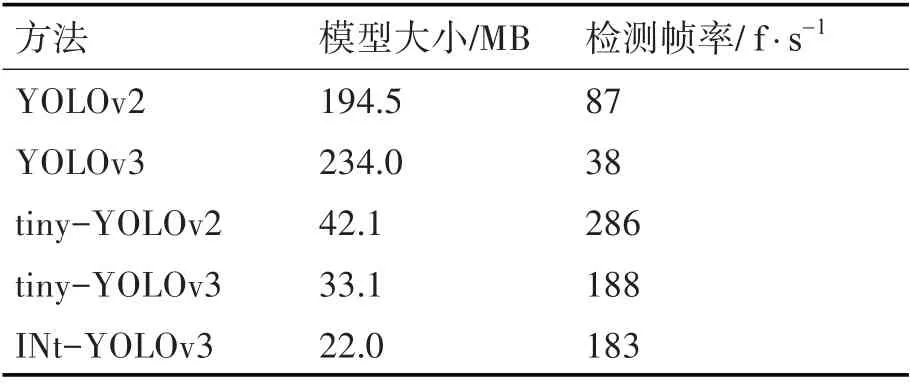
表3 不同方法模型大小与检测帧率
为了更加直观地检验INt-YOLOv3网络的有效性,本文选取测试集中图像以及道路采集图像进行了检测效果测试,选取KITTI中3张图片的检测结果进行对比,图4(a)、(c)和(e)为tiny-YOLOv3的检测结果,图4(b)、(d)和(f)为INt-YOLOv3的检测结果。对比图(a)、(b)和(c)、(d),tiny-YOLOv3和INt-YOLOv3能够很好地检测出大目标,但INt-YOLOv3检测出远距离的车辆,具有更好的小目标检测能力;对比图(e)和(f),tiny-YOLOv3对被遮挡的车辆错误检测,并漏检左侧背景颜色相同的Van,而INt-YOLOv3全部正确检测。图5为道路采集的两张图片检测结果对比,对比tiny-YOLOv3的检测结果图(a)、(c)和INt-YOLOv3的检测结果图(b)、(d),INt-YOLOv3比tiny-YOLOv3能更好地检测出小目标与被遮挡目标。综合以上检测结果,对于图像中较大尺度的无遮挡车辆,两种网络具有相近的检测能力,对于较小尺寸的车辆与被遮挡车辆,tiny-YOLOv3会出现漏检、错检和重复检测。但本文提出的INt-YOLOv3能够很好地解决问题,正确地检测出车辆。因此,INt-YOLOv3具有更好的检测性能。

图4 tiny-YOLOv3和INt-YOLOv3在KITTI数据集上的对比结果

图5 tiny-YOLOv3和INt-YOLOv3在采集图像上的对比结果
通过以上实验可以看到,改进后的算法在精度、交并比、模型大小和检测帧数四项指标上具有更好的表现,尤其在mAP上具有明显优势,相比原tiny-YOLOv3在本数据集上提高了5.75%;检测速度仅下降了5 f·s-1,并且模型大小仅有22MB,相对tiny-YOLOv3减少三分之一。这是因为本文增加了网络宽度和检测尺度,提升了网络的特征提取能力,同时减少参数,网络模型更小,更便于部署。
5 结语
本文提出了基于改进tiny-YOLOv3的前方车辆检测方法:INt-YOLOv3。该方法使用Inception模块替代原卷积层提取特征,并控制卷积层步长替代原池化层完成降维,通过增加网络宽度,提升网络特征提取能力,并减少网络参数;将上下文特征融合,增加检测尺度,同时利用K-means聚类方法自动生成候选框,增强特征图的表征能力,提高了模型的定位精度和tiny-YOLOv3网络在前方车辆检测的准确率,并且在检测速度几乎不变的情况下减少模型大小,更便于模型在移动端的部署。但是,INt-YOLOv3仍存在某些复杂环境下精确识别困难的问题,下一步的重点应放在增强模型的鲁棒性和识别效果上。
