个性化电影推荐算法综述
2021-09-14张正风强承魁段素峰
张正风 强承魁 段素峰
摘要:大数据时代,各类影视资源纷纷涌现,“信息过载”问题在影视行业愈发凸显,有效的电影推荐算法是解决这个问题的关键。本文首先总结了电影推荐的主流推荐算法,主要有协同过滤、基于内容的推荐和混合推荐三类算法,然后比较分析了几种推荐算法的优缺点。最后,针对推荐算法的发展方向,又对基于上下文的推荐算法进行了简单的介绍。
关键词:电影推荐;协同过滤;基于内容的推荐;混合推荐
Abstract:In the era of big data, all kinds of film and television resources have emerged, and the problem of "information overload" has become increasingly prominent in the film and television industry. Effective film recommendation algorithm is the key to solve this problem. This paper first summarizes the mainstream recommendation algorithms of film recommendation, including collaborative filtering, content-based recommendation and hybrid recommendation, and then compares and analyzes the advantages and disadvantages of several recommendation algorithms. Finally, according to the development direction of recommendation algorithm, the context based recommendation algorithm is briefly introduced.
Key words:Movie recommendation; collaborative filtering; content-based recommendation; hybrid recommendation
1引言
近年來,影视行业搭乘互联网的快车,发展迅速,数量和种类增长快速。面对令人眼花缭乱的海量影视资源,“电影过载”问题日益凸显,用户需要花费大量的时间寻找自己感兴趣的电影,并且用户对观影的要求也更加多样化。如何提升用户满意度,进而增加用户黏度是视频门户网站当前面临的巨大挑战。由此可见,提升个性化电影推荐算法性能的研究具有重要意义。
2电影推荐算法研究
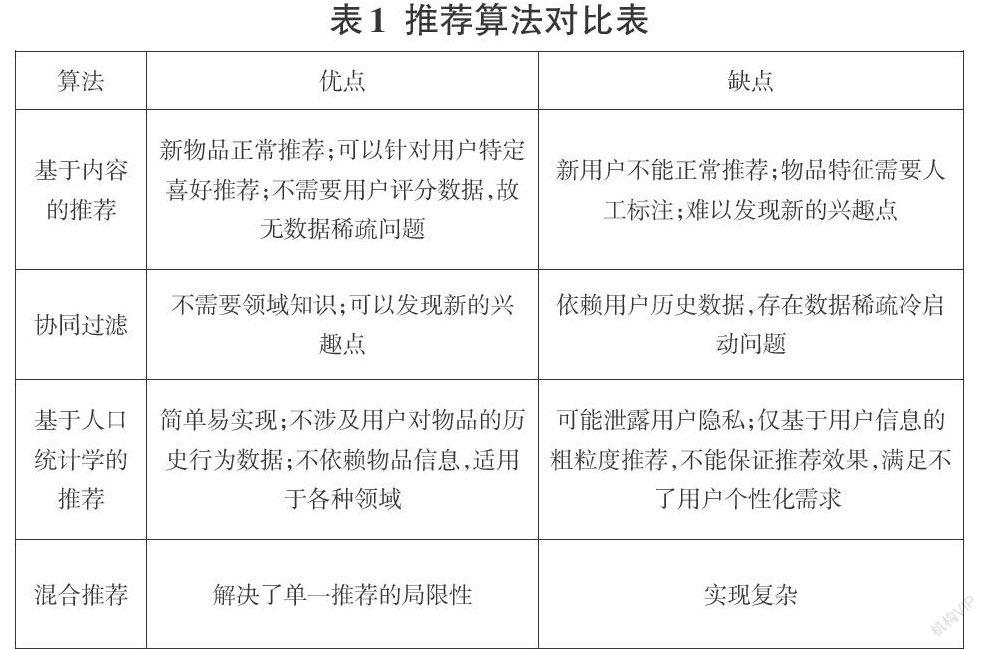
推荐系统能在大数据时代有效的解决信息获取泛滥的问题。在日常生活中,辅助人们做出决策。传统推荐算法通常分为四类:协同过滤推荐、基于内容的推荐、基于人口统计学的推荐和混合推荐。
2.1基于协同过滤的推荐算法
协同过滤是推荐算法中的经典,也是当前应用最广泛的推荐算法,其思想可以概括为“物以类聚,人以群分”[1],是“集体智慧”的体现。例如,用户想要看电影,但没有明确观影对象时,通常会让兴趣类似的朋友推荐电影,这就体现了协同过滤的思想。协同过滤分支众多,通常来说可分为三类。
(1)基于用户的协同过滤推荐算法
此算法原理简单,就是从用户的角度出发,从大量用户中寻找与目标用户有相似兴趣的用户群进行推荐[2]。下面以基于用户的电影推荐为例,介绍一下推荐的流程。如图1,当对张三推荐时,张三和王五都看过电影《算死草》和《百变星君》,而张三和李四没有相同的观影记录,显然张三和王五的观影偏好更相似,故将王五观看过的电影《少林足球》推荐给张三。
(2)基于物品的协同过滤推荐算法
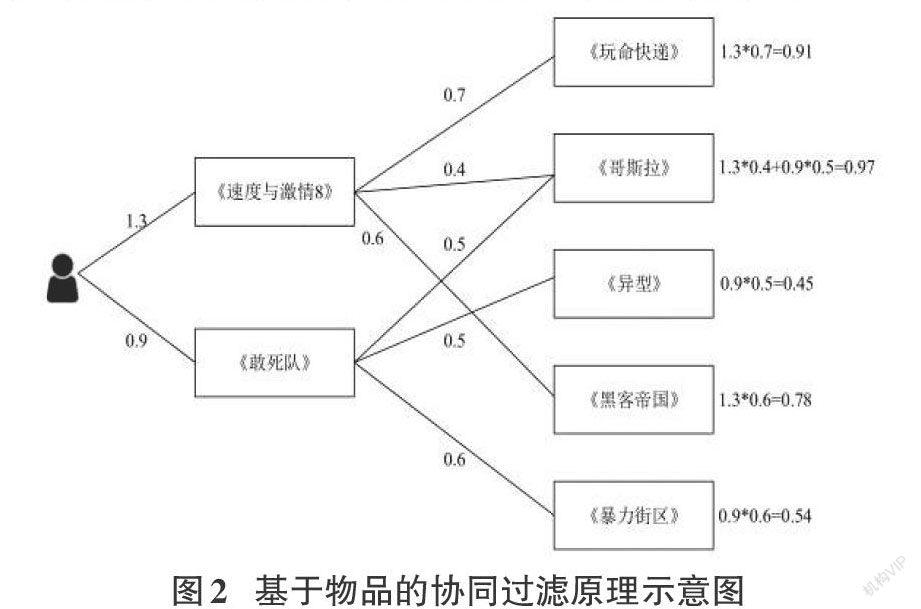
基于物品的协同过滤[3]从物品的角度出发,通过寻找与目标用户有关系的物品的相似物品进行推荐,一定程度上缓解了上述问题。如图2是一个基于物品推荐的简单例子。在这个例子中,用户喜欢《速度与激情8》和《敢死队》两部电影,然后推荐系统会分别找出与这两部电影最相似的三部电影,根据公式计算用户对每一部电影的感兴趣程度。例如,计算用户对《哥斯拉》的兴趣度。因为这部电影和《速度与激情8》以及《敢死队》的相似度分别为0.4和0.5.考虑到用户对《速度与激情8》的兴趣度是1.3,对《敢死队》的兴趣度是0.9,所以用户对《哥斯拉》的兴趣度为1.3*0.4+0.9*0.5=0.97。将用户对每一部电影的兴趣度计算出来,选择兴趣度最大的电影推荐给用户。
2.2基于内容的推荐算法
基于内容的推荐算法是最早被使用的推荐算法,是在信息检索和信息过滤的基础上发展而来,其原理就是根据用户有过消费行为物品的类别、标签、评论等相关信息找到与之相似的物品推荐给用户,原理简单,可解释性强[6]。因为基于内容的推荐算法只需根据物品特征计算相似度,且不需要其他用户信息,故不存在冷启动和新物品推荐问题。该算法主要用于文本领域。拿使用此算法的视频推荐系统为例,如图3所示,当给用户A推荐电影时,因为,用户A喜欢电影A,所以系统通过比较电影A、电影B和电影C的类型和主演,发现电影A和电影C都属于“喜剧”类型,且主演都有王宝强,故认为电影A与电影C更相似,所以将电影C推荐给用户A。
2.3基于人口统计学的推荐算法
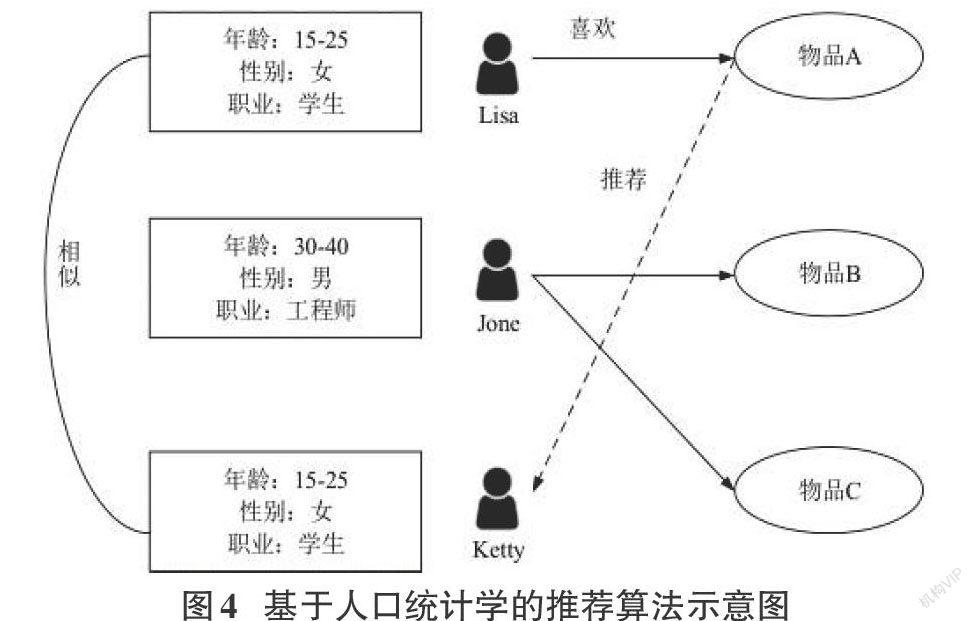
此推荐算法简单、容易实现。简而言之,就是根据用户的基本信息进行推荐。通常,用户的基本信息包括年龄、职业、民族、性别和家庭地址等数据。根据用户的基本信息将用户划分成不同类别,同一类的用户相似,同属于多个类的用户相似度更高[8]。如图4是一个简单的基于人口统计学推荐系统原理图。在这个例子中,Lisa和Ketty年龄相仿、性别相同且都是学生,因此认为Lisa和Ketty的兴趣有高度的相似性,可以认为Ketty很可能喜欢Lisa喜欢的物品A,所以可以推荐给Ketty。通过这个例子可以看出,基于人口统计学的推荐算法仅需要用户的基本信息,所以可以应用到各种领域的推荐系统中。