基于注意力机制的篮球场景语义分割的研究
2021-09-14刘振旅牛芳琳
刘振旅 牛芳琳


摘要:针对传统篮球场景分割方法鲁棒性弱和分割精度不高的问题,以篮球场景分割和运动员精确定位目的,提出了一种基于DeepLabv3+改进的篮球场景语义分割模型。该模型在DeepLabv3+网络的基础上设计了一个相对复杂的解码器,使用多次特征融合的方式来更好的还原图像的语义信息,引入了卷积块注意力机制,优化了通道权重和位置信息,降低了模型的计算复杂度,提升了边缘敏感度。实验结果表明,本文的模型要比FCN的全卷积模型提高21.8%,比DeepLabv3+提高1.9%。在分割速度上,可以达到每秒处理6张图片。提高了对于篮球场景的语义分割精度。
关键词:篮球场景;语义分割;DeepLabv3+;注意力机制;解码器
Abstract: Aiming at the problems of weak robustness and low segmentation accuracy of traditional basketball scene segmentation methods, for the purpose of basketball scene segmentation and accurate positioning of players, a semantic segmentation model of basketball scene based on DeepLabv3+ is proposed. The model designs a relatively complex decoder based on the DeepLabv3+ network, uses multiple feature fusion methods to better restore the semantic information of the image, introduces the convolution block attention mechanism, and optimizes the channel weight and position information , Which reduces the computational complexity of the model and improves the edge sensitivity. The experimental results show that the model in this paper is 21.8% higher than the FCN full convolution model, and 1.9% higher than DeepLabv3+. In terms of segmentation speed, it can process 6 pictures per second. Improved the accuracy of semantic segmentation for basketball scenes.
Keywords: basketball scene; semantic segmentation; DeepLabv3+; attention mechanism; decoder
近年来,篮球运动在国内外风靡,职业联赛中,运动员的对抗非常激烈,比赛中难免出现漏判和误判的现象。公平的判罚对于篮球比赛是至关重要的,裁判的判罚往往左右着比赛的走势。那么如何改善这一情况成为一大难题,CBA中有前场裁判和后场裁判以及摄像回放,虽然摄像回放很清楚,但是如果每个镜头都通过回放来判断,那么比赛会变得无比的复杂和费时,不具备时效性。所以对于运动员的行为判别研究非常有必要的。当前运动员属性的识别方法还是对于属性的存在性进行研究,而没有获取人和球属性的位置信息。需要获取运动 和球的位置也就是精确定位,这是属性判断的前提,那么对于篮球场景的语义分割是非常有意义的。
深度学习因其对图像特征的提取能力和对复杂问题的拟合能力,广泛应用于各个领域,而语义分割是深度学习的关键任务之一。Long等人将全连接层替换成全卷积层,提出了FCN[1],第一次实现了端到端、像素到像素的图像分割,从此打开了语义分割的大门。同年Chen等人提出了Deeplabv1[3],将90年代的空洞卷积引入语义分割领域,在不增加参数的情况下增大了感受野。受到目标检测算法R-CNN中的SPP[4]成功的影响Zhao等人提出了结合空间金字塔的模型PSPNet[5], Chen等人也提出了Deeplabv2[6],将SPP和空洞卷积相结合,形成不同空洞率的空间金塔结构,实现了多尺度特征的提取。不久,Chen[4]等人又提出了Deeplabv3[7], v3采用了Xception作为特征提取网络,大大的减少了参数计算量,同时去掉了的条件随机场后处理,实现了真正意义上的深度学习语义分割模型。Chen等人受到了SegNet[2]编码解码结构的思想,提出了含有解码器的模型Deeplabv3+[8]。该模型在多个数据集上取得了惊人的成绩,展现了极强的泛化能力。
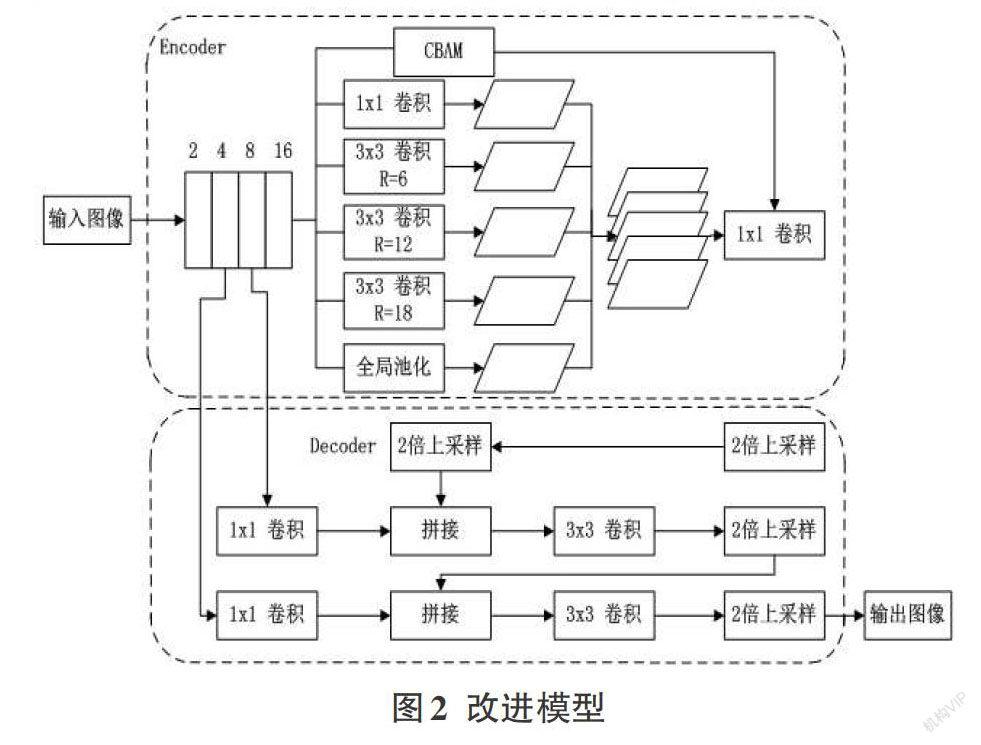
对于传统方法的研究,视频镜头分割存在复杂程度高,耗资多,变化大,难以自动提取等特点,本文则是将深度学习语义分割引入篮球场景,结合卷积块注意力机制,提出了一种基于DeepLabv3+改进的篮球场景语义分割模型,對于运动员进行实时分割和精确定位。
1传统的Deeplabv3+模型
Deeplabv3+的原始模型如图1所示。模型主要由编码器和解码器两大结构组成。其中编码器分为DCNNS提取网络和ASPP空间金字塔结构两部分。解码器包括一次特征融合和两次上采样。模型训练时,初始图像首先进入到编码模块中,经过DCNNS提取网络将图片的分辨率减少到原来的1/16。再把提取到的特征张量导入到ASPP结构中,该结构是结合了不同空洞率的空间金字塔结构。然后通过1×1卷积实现通道压缩,防止预测结果向底层特征倾斜。在解码器中,采用和四倍双线性插值还原和特征提取网络的图片进行一个拼接特征融合,再通过一个四倍双线性插值来实现图片输出。构建不同空洞率的空间金字塔结构改善了多尺度特征的提取,实现了感受野和分辨率的平衡。