基于改进KMV模型的上市公司信用风险度量
2021-09-14郭晓旭王永茂
郭晓旭 王永茂


摘 要:本文主要研究KMV模型的改进问题,使其能够更准确有效地预测软件和信息技术服务业上市公司的违约风险。对违约点重新设定,采用动态粒子群算法,对权重和学习因子做线性变化策略,将其转化为求解標记*ST、ST和未被标记公司之间违约距离差距的最大值问题,来找到违约点的最优系数组合,实现对上市公司的信用风险度量与评估。
关键词:信用风险度量;KMV模型;动态粒子群算法;权重因子
0 引言
随着信息产业价值的突显,软件和信息技术服务业作为新兴产业迎来了蓬勃发展。国家先后出台的一系列政策,给予了这个行业较为全面的政策支持。企业想要更好地生存和发展需要引入大量资金,但由于我国存在着社会信用体系不够完善,公司信息不够透明等问题,银行和金融机构不能准确地评估公司信用情况,造成了软件和信息技术服务业公司融资难的困境。因此,需要建立信用风险度量模型对软件和信息技术服务业的上市公司进行信用风险评估。
1 预备知识
1.1 KMV模型参数估计
2 实证分析
2.1 传统KMV模型
本文选取软件和信息技术服务业截至2019年6月30日在A股、创业板、中小板各个板块单独上市的193家上市公司作为研究样本。按照股票代码排序,序号为1~193。其中,有8家上市公司被中国监证会标记为*ST,有2家上市公司被标记为ST。
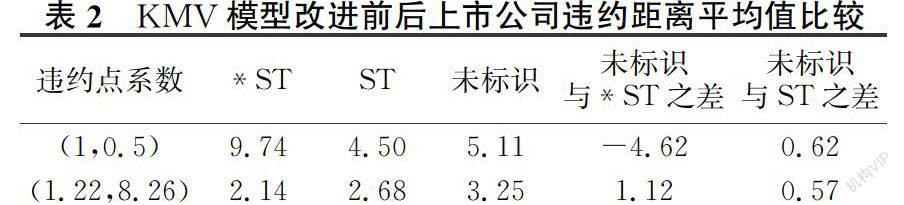
借助MATLAB,求解传统KMV模型违约点系数组合为(1,0.5)时的193家上市公司的预期违约距离。发现编号为77、172和173的上市公司预期违约距离分别为-184、-2449和-1070,与其他值相差过大,于是作为异常值将其剔除。从表1可以看出,*ST标识的上市公司的违约距离平均值要比未标识公司的违约距离平均值大,二者相差4.62,这意味着*ST标识公司发生违约的概率比未标识公司要小得多,这样的研究结果显然不符合证监会把财务不佳、投资有风险的公司作*ST和ST标记的实际情况。这说明传统KMV模型并不能有效区分和评估软件和信息技术服务业上市公司的信用风险。因此,还需要进一步对KMV模型进行改进。
2.2 改进的KMV模型
本文基于动态粒子群算法对KMV模型的违约点进行修正,将KMV模型中的违约点最优系数求解问题转化为求ST、*ST和未标识上市公司之间违约距离差距的最大值问题,以寻求适合软件和信息技术服务业为上市公司的违约点,改进后的KMV模型的流程图如图1所示。
借助MATLAB,经过10个初始粒子的20次迭代寻找,发现改进后的KMV模型适用于软件和信息技术服务业上市公司的最优违约点系数组合为(1.22,8.26)。即,软件和信息技术服务业的上市公司的违约点应设定为:
改进后的KMV模型的信用风险度量效果如表2所示。当违约点系数组合为(1.22,8.26)时,*ST和ST标识公司的违约距离比未被标记的公司要小,即*ST和ST标记公司的违约概率要比未标记的公司大。改进后的KMV模型更能有效地区分和评估*ST和ST和未标识的上市公司的信用风险。
图2是KMV模型改进前后上市公司的预期违约距离对比图。其中,黑色折线表示传统KMV模型,蓝色散点表示改进的KMV模型。红色“+”表示*ST标识公司,绿色“o”表示ST标识公司。可以看出,改进后的KMV模型求解的违约距离都在[0,6]范围波动,修正了传统KMV模型求解的个别上市公司违约距离数值过大异常波动的问题。同时KMV模型改进后,带有*ST、ST标识的上市公司的违约距离普遍偏低,更符合实际情况。同时还可以看出,171号“*ST中安”的预期违约距离为0.7693,是软件和信息技术服务业所有上市公司中预期违约距离最小,发生违约的风险最高的,因此需要格外警惕。
2.3 改进前后模型的比较
利用R软件作ROC曲线,如图3所示。图中蓝色实线表示传统KMV模型,AUC值为0.659;红色虚线表示改进后的KMV模型,AUC值为0.784。当违约点系数组合从 (1,0.5) 修正到 (1.22,8.26) 时,ROC 曲线向左上方移动,AUC 的数值从 0.659 显著增加到 0.784,接近于 0.8。这说明经过动态粒子群算法改进的KMV模型比传统KMV模型更加理想。对*ST和ST标识的上市公司的区分效果更加优良,对软件和信息技术服务业上市公司的信用风险度量和评估效果更加有效。
3 结束语
本文在研究软件和信息技术服务业上市公司信用风险度量问题时,在 KMV 模型基础上,根据国内实际情况,采用动态粒子群算法进行优化,以是否被中国证监会标记作为判断准则,寻找违约点的最优系数组合为(1.22,8.26),重新定义了违约点。由此可见,改进后的KMV模型具有一定的实用性,能够更准确有效地求解上市公司预期违约距离和评估上市公司违约风险。但是模型仍有不足的地方,比如模型严格的假设条件,未将信心不对称时的道德风险纳入考虑,违约点系数组合适用范围太窄等。因此,今后应该进一步对此进行深入研究。
参考文献
[1]马若微.KMV模型运用于中国上市公司财务困境预警的实证检验[J].数理统计与管理,2006,25(5):593-601.
[2]章文芳,吴丽美,崔小岩,等.基于KMV模型上市公司违约点的确定[J].统计与决策,2010,(14):169-171.
[3]贾利.基于KMV模型上市公司违约点的选择[J].商,2016,(3):182-183.
[4]安东尼·桑德斯著.信用风险度量——风险估值的新方法与其他范式[M].北京:机械工业出版社,2001:13-14.
[5]王星予,余丽霞,阳晓明,等.商业银行信贷资产证券化信用风险研究——基于修正的KMV模型[J].收藏,2019,(3):53-66.
