基于小生境遗传算法优化串级神经网络的台区理论线损预测
2021-09-14霍成军王玮茹陈广湘李蒙赞程雪婷但唐军
霍成军,王玮茹,余 昆,陈广湘,李蒙赞,程雪婷,但唐军
(1.国网山西省电力公司,太原 030025;2.国网山西省电力公司电力科学研究院,太原 030032;3.河海大学能源与电气学院,南京 211100)
中国台区线损约占全网总线损的20.2%,电能损失严重[1],不仅损害电网企业利益,亦不符合现阶段中国推行的低碳节能政策,亟需对台区的线损进行管理。台区线损由管理线损和技术线损组成。管理线损指因计量装置量测误差或人为因素导致的线损;技术线损指电能在导线上流通时部分电能转换成其他能量造成电能损耗。因管理线损和技术线损这二者的降损手段不同,故对台区的线损治理前,需确定台区的高线损是人为管理方面还是供电技术不合理造成,这可通过计算台区的理论线损值与统计线损值,并进行对比确定。若台区的理论线损值跟统计线损值相近,则台区的高线损由技术原因产生,若台区的统计线损远大于理论线损,则台区的高线损由管理原因造成[2]。统计线损值计算较方便,对于理论线损,因台区节点数目多、网架结构复杂,诸如电压损失法、等值电阻法、平均电流法、潮流法等传统的理论线损计算方法均不符合快速准确地计算台区理论线损的要求[3]。
因此,为了快速精确地计算出台区的理论线损,为供电企业制定合理的降损措施提供依据,迫切需要一种计算精度较高,计算速度较快的方法。许多机器学习模型具有良好的数据预测潜力,基于大数据的机器学习方法应用于台区理论线损计算正成为目前研究热点[4-7]。使用机器学习手段建立台区理论线损预测模型前,需要从海量的运行数据中提取出线损关键特征指标,作为线损预测模型的输入量。线损关键特征指标的质量决定线损预测模型的优劣。因此,研究台区线损关键特征指标和台区线损预测模型具有重大实用价值。
目前对基于大数据的线损预测模型研究已有些学者取得进展。文献[8]通过构建供电半径、低压线路总长度、负载率、居民用电比例这4个线损关键特征指标作为改进反向传播(back propagation, BP)神经网络的输入量,经算例验证了改进的BP神经网络线损预测模型优秀的预测能力。文献[9]基于深度学习的长短期记忆网络(long short-term memory,LSTM)模型,选择日期、售电量、最高温度、最低气温和节假日共5个特征指标作为线损预测模型的特征量,采集某市某月两个星期的相关数据,按照一定比例划分为训练集和测试集,仿真结果表明该线损预测模型具有一定准确度。以上2个线损预测模型的特征指标选取按照专家经验挑选。文献[10]使用灰色关联分析方法从待选的15个电气特征指标里提取出线损关键特征指标,建立自适应遗传算法优化BP神经网络的10 kV配电网线损预测模型,经仿真实验验证了模型具有良好的收敛性和泛化能力。文献[11]也是通过灰色关联分析法确定高损关键特征指标,并建立基于灰色模型和神经网络组合的线损预测模型。文献[10-11]建模对象为10 kV及以上电压等级电网。为解决传统BP神经网络计算精度不高问题,文献[12]采用基于门控循环单元的多层网络建立台区线损预测模型,经某市实际台区验证了所提模型的有效性。考虑台区间的不同特点,文献[13]根据台区特征运用密度聚类(density-based spatial clustering of applications with noise,DBSCAN)算法将台区分类,再使用随机森林模型分别预测各台区的线损率。文献[14]提出了一种基于对抗生成网络与BP神经网络的低压台区线损率预测模型,对抗生成网络能有效增加台区数据作为BP神经网络的训练数据,适用于台区原始数据量不够场景。上述文献在台区高损特征指标研究中并没有涉及分布式电源,而分布式电源并网对台区线损影响不可忽略。
当前对台区的高损关键特征指标选取及线损预测模型研究不够深入,现提出一种基于Pearson相关系数分析法和小生境遗传算法优化多级BP神经网络的台区线损预测模型。首先,分析台区线损影响因素并构建台区线损特征指标集合。然后,利用Pearson相关系数分析法从线损特征指标集合里提取出高损关键特征指标。最后构建小生境遗传算法优化串级BP神经网络(niche genetic algorithm optimize BP cascade neural network, NGA-BPCNN)台区线损预测模型,利用小生境遗传算法优化串级BP神经网络各层初始权重系数,加快神经网络训练速度,提高神经网络的预测精度。经实际工程案例验证了本文提取的高损关键特征指标和建立的NGA-BPCNN台区线损预测模型具有优秀的训练效率和预测泛化能力。
1 台区线损特征指标的建立
收集某市所有台区在2020年7—9月份期间的运行数据,经数据清洗后,得到112 138条有效数据,每条数据为某台区单日运行数据,包含线损率、供电半径、供电量、负载率、光伏上网电量、ABC三相电流等台区特征量,从容量类、电量类、运行类、网架类四个方面建立台区线损特征指标集。
1.1 容量类指标
台区的配变安装容量表征台区的供电能力,供电能力不足的台区存在技术线损大的问题。
配变在运行时会产生电能损耗,且该损耗大小跟配电容量近似正比关系,直接选取配变容量有名值进行计算,即
x1=SN
(1)
式(1)中:SN为台区配变额定容量,kV·A。
1.2 电量类指标
电量值间接体现台区传输电能的大小,电量值越大,说明台区导线上流通的电流越大,线损值相应提高。
(1)日有功供电量。台区线损大小近似跟用户有功功率的平方成正比,由于有功功率乘电流等于供电量,而采集供电量比采集有功功率方便,故采用供电量的有名值体现台区线损大小,即
x2=WP供
(2)
式(2)中:WP供供为台区的日有功供电量,kW·h。
(2)分布式电源上网电量占比。分布式电源出力曲线和典型居民负荷曲线变化趋势不一致,在正午时分布式电源出力达到峰值,居民用电较小,分布式电源可能会使台区的潮流转向,甚至使台区线损增加。选取分布式电源上网电量占比反映分布式电源对台区线损的影响。计算公式为
(3)
式(3)中:WDGi为台区内接入的分布式电源i的日上网电量,kW·h;M2为台区内接入的分布式电源的总个数。
(3)台区单相用户电量总占比。台区通常为三相四线制,存在大量单相用户,各用户并非均匀接入A、B、C相,同时用户用电习惯存在差异性,台区三相流通功率不平衡,使中性线产生电能损耗,为反映单相用户对台区线损的影响,提出单相用户电量总占比指标,计算公式为
(4)
式(4)中:W用-单相j为台区内单相用户j的日用电量,kW·h;W用-三相i为台区内三相用户i的日用电量,kW·h;M3为台区内单相用户总个数;M4为台区内三相用户总个数。
1.3 运行类指标
1.3.1 功率因数
功率因数体现了台区内流通的有功功率和无功功率宏观情况,功率因数越高,台区线损越小,考虑到光伏电源正逐渐接入台区,利用馈线首端功率计算功率因数已不符合实际情况,故对传统的功率因数计算公式进行改进,改进后,计算公式为
x5=
(5)
式(5)中:WP供为台区首端日有功供电量,kW·h;WDG为分布式电源上网电量,kW·h;QⅠ、QⅡ、QⅢ、QⅣ分别为第一、二、三、四象限台区首端日无功供电量,kW·h。
1.3.2 峰荷负载率
台区日负荷曲线中,高峰负荷和低谷负荷以及平时负荷各占1/3。为了降低采集数据过程中偶然偏差造成的影响,提出峰荷负载率来表征高峰负荷对线损的影响。
其定义为将采集到的96点台区首端功率和分布式电源出力分别相加,然后按从大到小排序,取前32个点,去除其中的最大值和最小值,将剩下的30个点取平均得到的功率数值与配变容量的比值。计算公式为
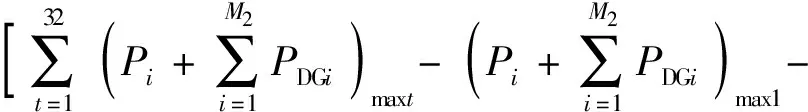
(6)
1.3.3 日负荷形状系数
日负荷形状系数表征台区功率波动情况,功率波动可能对台区线损产生不利影响,比如负荷在某时刻同时用电,在另一时刻用电大幅降低,负荷波动大,台区负载过大会导致线路损耗增大,负载太小会使配变不经济运行。台区普遍存在功率三相不平衡状态,常规日负荷形状系数指标没考虑台区功率三相不平衡特征,对传统的日负荷形状系数进行改进,改进后的计算公式为
(7)
式(7)中:IAi、IBi、ICi分别为台区首端i时刻采集到的A相电流、B相电流、C相电流,A。
1.3.4 三相不平衡系数
据统计三相负荷不平衡可引起台区线损率升高2%~10%[15],可见台区三相负荷不平衡程度对线损影响严重,基于三相电流的日负荷变化曲线,对传统三相不平衡系数计算公式进行改进。改进后的计算公式为
x8=
(8)
1.4 网络类指标
不同的供电半径和网络类型对线损均有影响,故建立供电半径和网络类型指标来分析网络类指标。
(1)供电半径。选取供电半径来表征台区首端与台区最末端用户之间的距离,根据台区首端和末端用户的GPS坐标,对传统供电半径计算方法进行改进,改进后计算公式为
(9)
式(9)中:x、xi分别为台区配变、用户i的GPS坐标中的经度;y、yi分别为台区配变、用户i的GPS坐标中的纬度。
(2)网络类型。台区线路分为电缆线路、架空线路、架空绝缘线路、混合线路,不同线路类型对线损影响不一样,故提出网络类型指标表征线路类型对台区线损的影响,即
(10)
2 基于Pearson相关系数法的台区线损关键特征指标提取
2.1 变量间相关性的计算
Pearson相关系数法[16]可以定量的衡量不同变量之间的相关性,两个变量之间的相关系数定义为两个变量之间的协方差和标准差的商。
台区线损率y和配变容量x1、日有功供电量x2、分布式电源上网电量占比x3、台区单相用户电量总占比x4、功率因数x5、峰荷负载率x6、日负荷形状系数x7、三相不平衡系数x8、供电半径x9、网络类型x10分别为参与相关性分析的变量,计算上述变量间的Pearson相关系数公式为
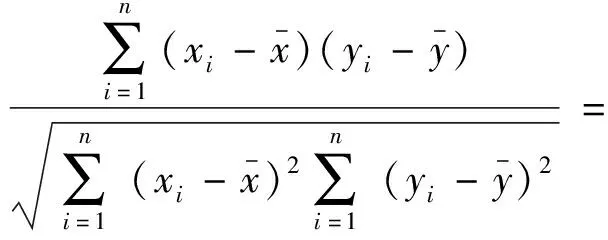
(11)
式(11)中:r的取值范围在[-1,+1]之间,当r>0时,表示两个变量呈正相关;当r<0时,代表两个变量呈负相关。故变量之间相关性强弱由r的绝对值表征。文中选取相关系数r的绝对值进行比较。并根据相关系数判断准则[17],将相关系数r>0.3的线损特征指标确定为关键特征指标。
2.2 提取流程
由于台区线损特征指标的量纲不同,因此在进行相关性分析前,对特征指标数据进行中心化和标准化,转化为无量纲样本数据[18]。
中心化处理过程为
(12)
(13)
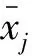
在中心化处理的基础之上,对样本数据进行标准化处理。采用标准差对指标样本数据进行标准化处理,令第i个台区的第j个指标的标准差为Sj,对x′ij进行标准化变换,计算公式为
(14)
(15)
基于主因子分析法的台区线损关键特征指标提取流程图如图1所示。

图1 台区线损关键特征指标提取流程图
2.3 高损关键特征指标提取
依据第1节中收集的台区运行数据和线损特征指标定义,建立台区高损特征指标数据集,共112 138条数据。表1列出经计算后的某10个台区高损指标数据。
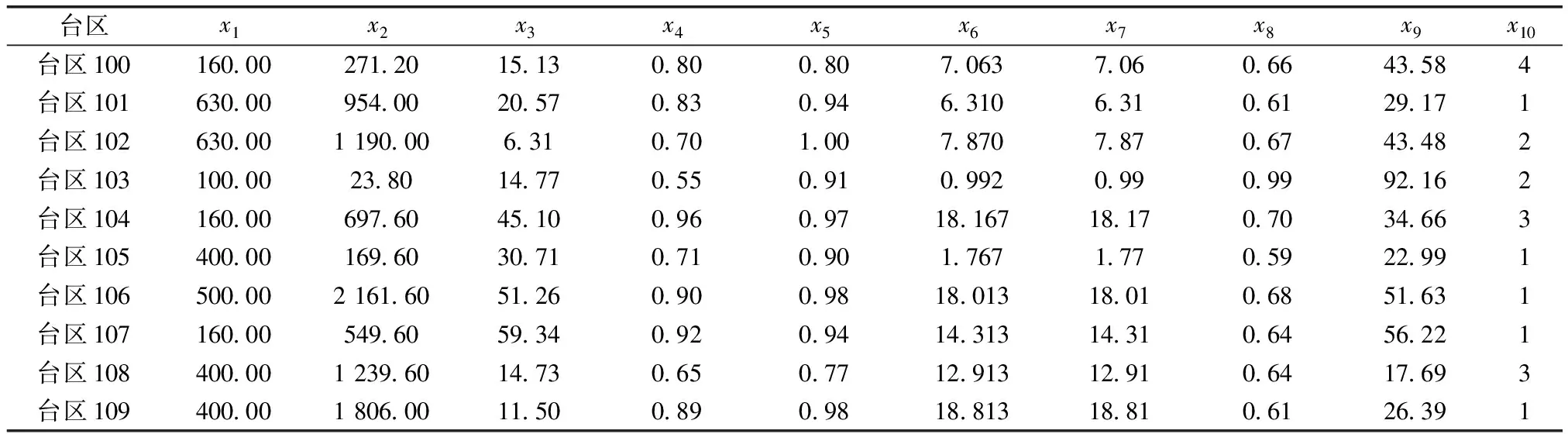
表1 部分台区的高损特征指标数据
再根据Pearson相关系数法计算线损率与线损特征指标之间的相关系数,得到相关系数矩阵如表2所示。
由表2可知,x1、x2、x4与y的相关系数分别为0.011、0.003、0.023,均小于0.3,x3、x5~x10与y的相关系数分别为0.331、0.363、0.525、0.348、0.336、0.611、0.482,均大于0.3。根据相关系数判断准则[3],将相关系数小于0.3的配变总容量、日有功供电量、台区单相用户电量总占比三个指标剔除,将相关系数大于0.3的7个指标:分布式电源上网电量占比、功率因数、峰荷负载率、日负荷形状系数、三相不平衡系数、供电半径、网络类型确定为台区线损关键特征指标。

表2 台区高损特征指标的皮尔逊相关系数计算结果
3 基于NGA-BPCNN台区线损预测模型的构建
BP神经网络的初始权重系数选取合理性将影响台区线损预测模型的训练速度,摒弃常规随机生成神经网络初始权重系数方式,采用遗传算法进行全局寻优得到神经网络初始权重系数,加速台区线损预测模型收敛。
3.1 采用适应度共享技术的小生境遗传算法
小生境遗传是对遗传算法的改进,能够提高种群多样性,预防遗传算法早熟收敛[19],采用基于适应度共享技术的小生境遗传算法优化BP神经网络的权重系数。
Goldberg[20]提出了一种基于适应度共享的小生境技术。在这种机制中,定义了共享函数[记为fs(d)],反映了在小生境中个体间的密切程度,个体间越相似,其共享度越大。共享适应度定义为
(16)
式(16)中:fi为第i个个体的原始适应度;n为该小生境中的个体数。共享函数fs(d)表示为
(17)
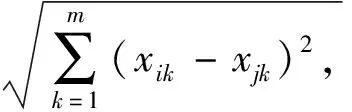
i=1,2,…,n;j=1,2,…,n
(18)
式中:σshare为小生境半径;di,j为个体i、j间的海明距离,具体用个体基因型计算;xik表示个体i第k维基因;m表示每个个体总基因数。
3.2 串级BP神经网络
面对大数据,对于单一常规BP神经网络,为了精确拟合出目标值,往往需要增加隐藏层的神经元数量和隐藏层数,但这会导致梯度消失问题使得模型训练效果变差,甚至不能成功训练出模型。基于集成学习思想和梯度提升树原理,对常规BP神经网络进行改进,提出一种串级BP神经网络模型,如图2所示。其中,综合多个子模型的线损预测结果作为最终模型输出结果,体现了集成学习思想;第n个子模型的拟合目标为实际目标跟第n-1个子模型预测值之差,这体现了梯度提升树思想。

图2 NGA-BPCNN模型结构示意图
图2中,除了第一个子模型的输入目标值为原始数据外,其他子模型的输入目标值均为相应上级子模型预测结果跟目标值之差,即残差,记为ΔY,计算公式为
ΔYi+1=Y-Yi
(19)
式(19)中:Y为目标值;Yi为第i个子模型预测输出值。
串级BP神经网络输出值YC为各子模型输出值之和,即
YC=Y1+Y2+…+Yn
(20)
3.3 NGA-BPCNN台区线损预测模型生成步骤
第一步确定串级神经网络结构。包括:①子模型个数; ②每个子模型输入层维度,输出层维度;③各子模型隐藏层神经元个数(考虑到三层 BP 神经网络能以任意精度逼近任何非线性函数,而且层数越少,神经网络计算速度越快,因此本文中串级神经网络的子模型隐藏层层数均为1)。
第二步确定各子模型隐藏层、输出层的激活函数。
第三步设计染色体编码格式。采用实数编码方式,染色体编码格式为[Q1,Q2,…,Qn]。
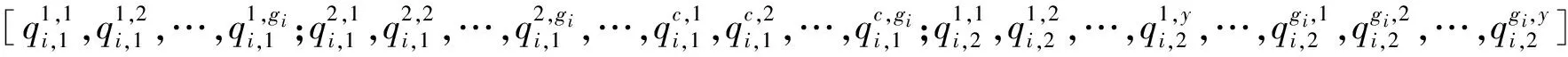
(21)
第四步定义适应度函数。
第五步设置小生境遗传算法超参数。种群数P、交叉率α、变异率β、进化代数D、小生境半径σshare、收敛精度ε。
第六步利用小生境遗传算法搜索最优的串级神经网络初始权重系数。小生境遗传算法寻优步骤:①初始化种群,计算种群适应度;②采用精英保留策略,提取出适应度最优的M个个体;③对种群里的个体进行遗传操作产生子代,计算子代适应度;④将预先保存的M个个体混入种群里,应用小生境技术,调整种群各个体适应度;⑤采用竞标赛机制,提取出P个个体组成新种群;⑥重复②~⑤步直到满足收敛精度ε或迭代次数D次,获得最优个体,得到最优的初始权重系数。
第七步BPCNN台区线损预测模型训练。基于最优初始权重系数,对BPCNN训练,得到线损预测模型。
NGA-BPCNN台区线损预测模型建立流程如图3所示。
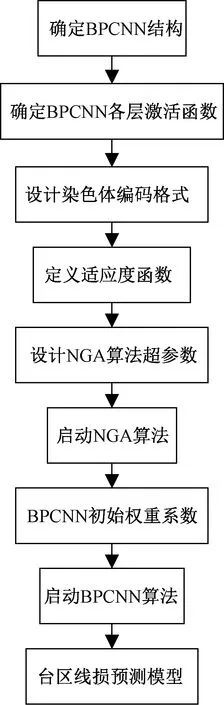
图3 NGA-BPCNN台区线损预测模型训练流程图
4 算例分析
由第2.3节的112 138条台区高损特征指标数据建立台区线损预测模型的原始数据集。
4.1 模型衡量指标
采用平均均方差MSEav、相对误差RE、平均相对误差REav作为衡量线损预测模型性能指标。
(22)
(23)
(24)
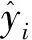
平均均方差MSEav将作为小生境遗传算法的适应度函数。
4.2 模型参数设置
4.2.1 串级神经网络结构确定
采用实验法和控制变量法来确定串级神经网络的子模型个数和隐藏层神经元个数。固定隐藏层神经元个数、各层激活函数、串级神经网络迭代次数,改变子模型个数,以平均均方差MSEav最小为目标,求出使MSEav最小时的子模型个数。
由图4可知,随着子模型个数的增加,模型预测效果越好,但是训练时间大幅增加,综合考虑预测精度和训练时间,选择3个子模型组成串级神经网络。
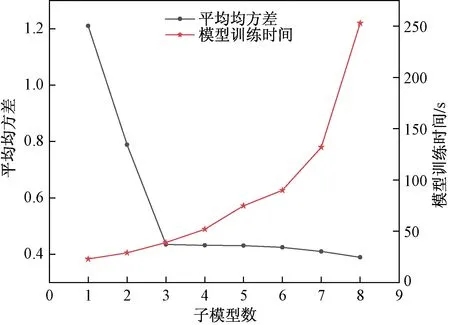
图4 子模型个数和平均均方差、训练时间关系
由确定的子模型个数,固定各层激活函数、串级神经网络迭代次数,同理以平均均方差MSEav最小为目标,求出使MSEav最小时的隐藏层神经元个数。由图5确定子模型隐藏层神经元个数选取为13。
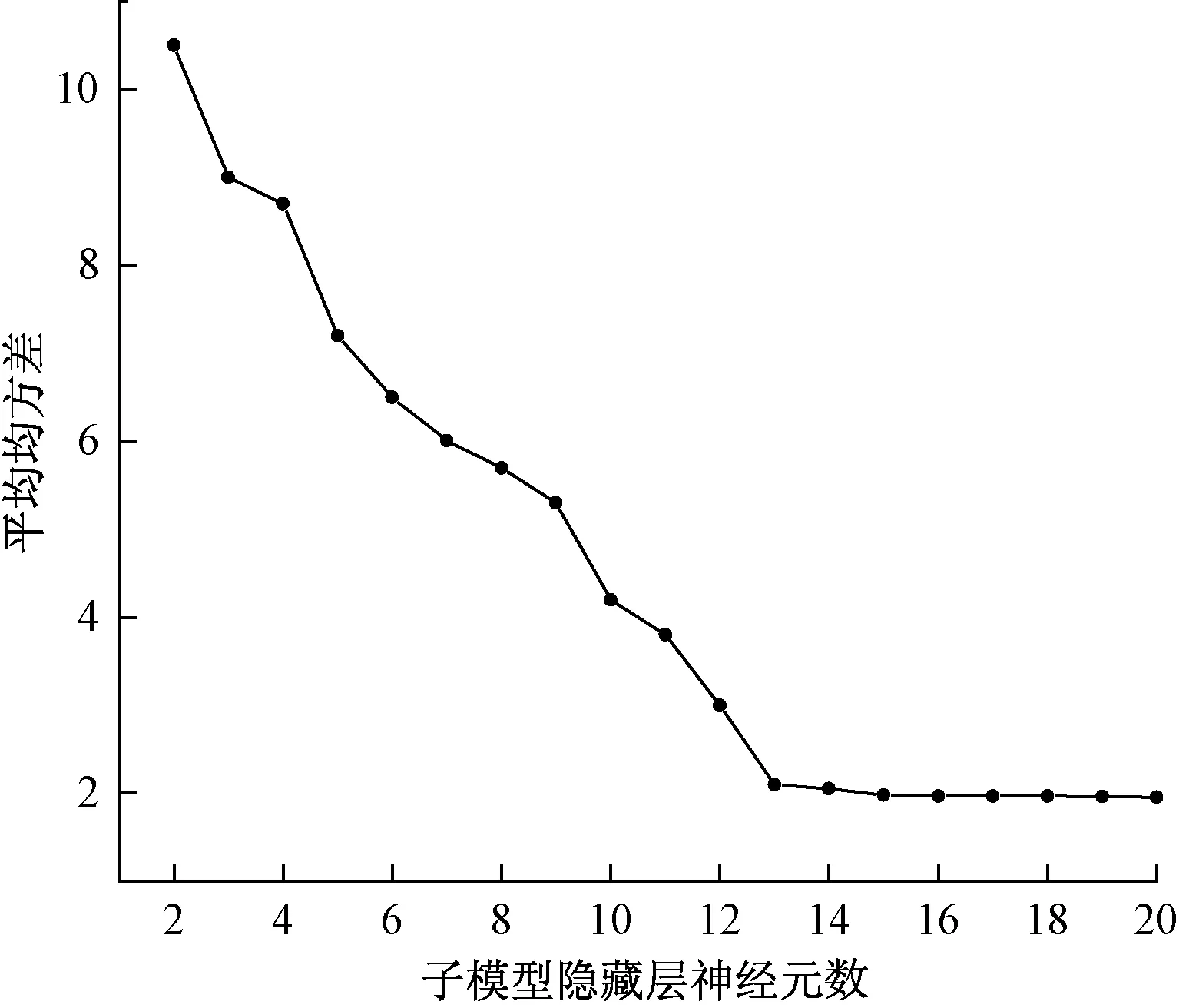
图5 子模型隐藏层神经元个数和平均均方差关系
4.2.2 串级神经网络激活函数确定
经过多次测试,子模型各层激活函数相同,隐藏层使用tanh函数,输出层使用relu函数。
4.2.3 小生境遗传算法超参数设置
遗传算法的超参数设置合理性将影响其对串级神经网络的初始权重优化速度和优化效果,但目前在超参数的选取上并没有统一标准,多是采用经验法、试凑法得到。基于试凑法,经过大量仿真,最终确定小生境遗传算法超参数:设置种群数P=100、交叉率α=0.8、变异率β=0.6、进化代数D=300、小生境半径σshare=2.1、收敛精度ε=0.000 1。
4.3 NGA-BPCNN台区线损预测模型预测结果
将112 138条数据按7∶3比例划分为训练集和测试集,即训练集有78 496条数据,测试集有33 642条数据。使用训练集训练台区线损预测模型,然后用测试集验证训练完的模型,测试模型是否具有实用性以及是否过拟合。
模型在训练集的输出值如图6所示,测试集上模型输出值如图7所示。为方便显示,均只显示了部分数据样本。对于训练集,平均均方差为0.12、平均相对误差为3.2%;对于测试集,平均均方差为0.26、平均相对误差为8.3%。根据模型在训练集和测试集上的衡量指标,模型在测试集上的效果比在训练集上的效果差些,不过,这是合理的,只能使得模型在测试集上的效果尽量贴近训练集,但是,从整体上看,模型在测试集上的结果满足工程要求的,具有应用于工程的价值。
4.4 不同线损预测模型性能对比
为了更客观验证本文提出的线损预测模型的训练效率和泛化能力,用同一训练集对NGA-BPNN、文献[9]的LSTM深度学习模型、文献[10]的AGA-BPNN模型与本文模型进行训练,训练精度均为0.001,再用同一测试集验证各模型的泛化能力。由表3可知,本文所提模型在相同训练精度下迭代次数最少,收敛速度最快。各模型在部分测试集上的效果如图8所示。从图8可见,本文所提NGA-BPCNN模型在4个模型中表现最好。如表4所示,NGA-BPCNN模型在测试集上的平均均方差为0.31、平均相对误差为9.2%;NGA-BPNN模型在测试集上的平均均方差为0.67、平均相对误差为15.4%;LSTM模型在测试集上的平均均方差为0.43、平均相对误差为11.5%;AGA-BPNN模型在测试集上的平均均方差为0.38、平均相对误差为10.14%。由表5可知,本文所提NGA-BPCNN模型在测试集上预测相对误差小于5%的样本数目在四个算法中最多,大于10%的样本数目最少。综上,NGA-BPCNN模型具有优秀的训练效率和预测泛化能力。
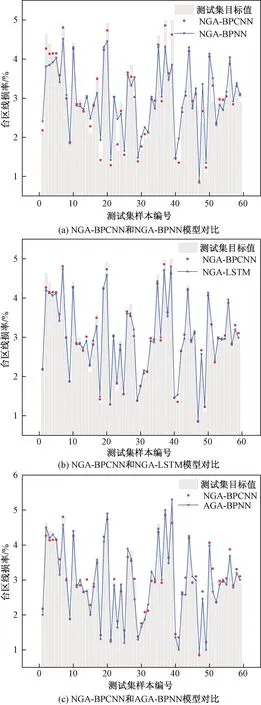
图8 不同模型预测效果对比
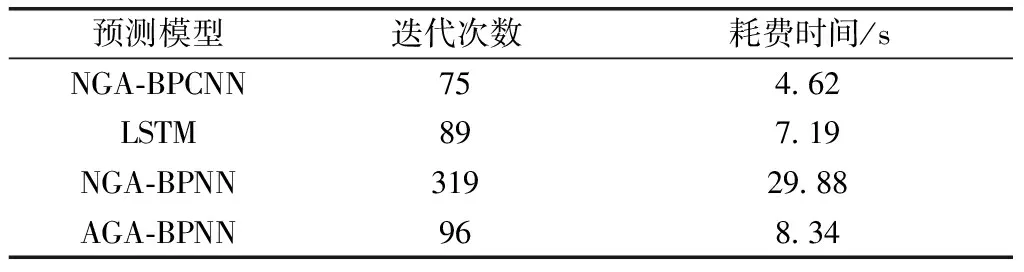
表3 不同算法在训练集上训练速度比较
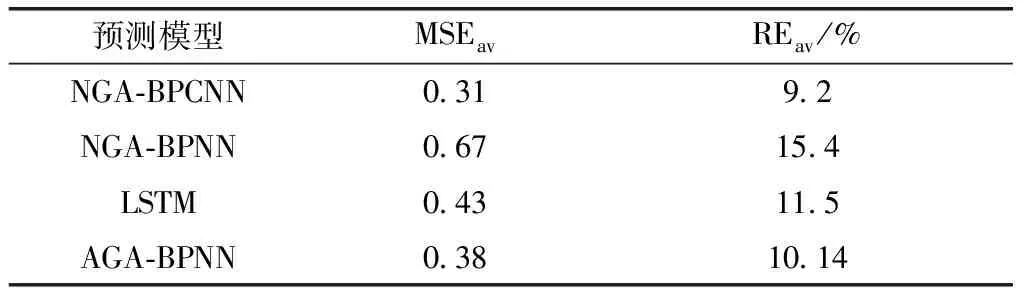
表4 不同算法在测试集上平均均方差、平均相对误差比较
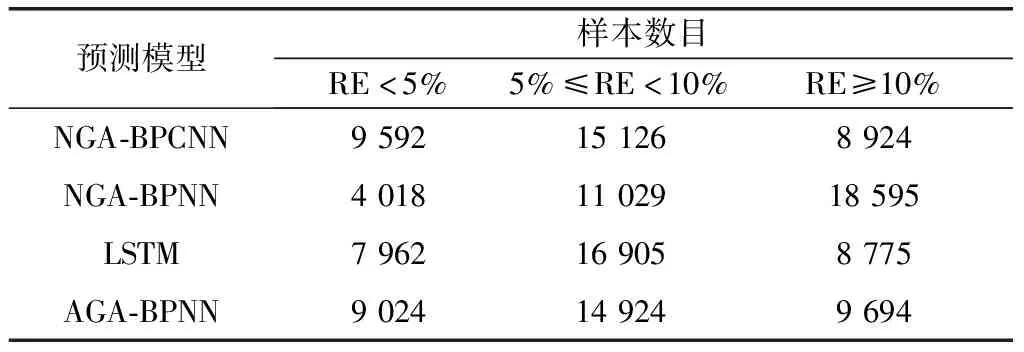
表5 不同算法在测试集上的预测相对误差分布比较
5 结论
首先从理论上提出台区线损特征指标集合。然后利用Pearson相关系数法,从10个台区线损特征指标里提取出7个高损关键特征指标作为线损预测模型的输入。基于集成学习和梯度提升树思想提出NGA-BPCNN台区线损预测模型,经过实验仿真,表明该模型具有优秀的训练效率和预测泛化能力,亦表明本文所提取高损关键特征指标的有效性,具有实际工程应用价值。
