基于Spark大数据处理的电影推荐系统设计与实现
2021-09-13朱炳旭叶传奇王君洋李应霆李玉进
朱炳旭 叶传奇 王君洋 李应霆 李玉进

摘 要:文章指出,该系统的开发设计是使用了互联网著名且优化过后的MovieLens数据集当作基础,以网络中某个电影评分网站的数据业务框架作为前提,其中包括离线推荐和实时推荐体系,总体采用了协同过滤算法和基于内容的推荐算法实现混合推荐的目的。实现了前端可视化页面、后台业务处理、算法的设计与实现、环境的安装与部署等多种操作方式。
关键词:推荐系统;混合推荐;协同过滤;Spark;ALS;机器学习
0 引言
随着网络碎片化管理视频的时代到来,不断产生的用户数据,促使基于用户的智能推荐影片的系统的实现非常重要。一个完善的推荐系统能够为用户提供实时需要的信息,正是如此推荐系统面对海量产生的数据信息,从中快速推荐出满足用户喜好的物品,对于一些“选择恐惧症”和没有明确需求的人是一道福音。
以电影网站作为业务应用场景,实现基于统计的推荐、基于LFM的离线推荐、基于模型的实时推荐、基于内容的推荐等多个模块代码实现,并与各种工具进行整合互接,构成完整的项目,实现对大数据框架的整合以及典型机器学习前沿学习算法的应用[1-3]。
1 推荐系统总体技术要求
1.1 系统框架要求
该推荐系统是基于Web开发的B/S系统,该前端架构是通过AngularJS框架用户可视化工具开发实现,该后端是通过Spring框架进行综合业务服务的实现。
(1)系统采用的开发工具:IDEA;编程语言:Java、Scala。
(2)由于业务处理请求在数据的存储模块有着差异,进行区别采用了不同的数据库,采用MongoDB管理平台内业务数据库并当做主数据库;采用Elasticsearch当做模糊搜索服务器实现匹配查询操作和基于内容的推荐;采用Redis当做缓存数据库实现实时推荐模块里对数据进行提取。
(3)系统基于Spark平台,运用到了Spark部分生态组件。实时推荐部分中实现基于模型的推荐算法,采用Flume进行日志收集业务以及Kafka进行消息缓冲操作,使用Spark Streaming当做实时的推荐系统,接受Kafka对缓存的数据处理后合并更新到MongoDB数据库。
1.2 系统架构
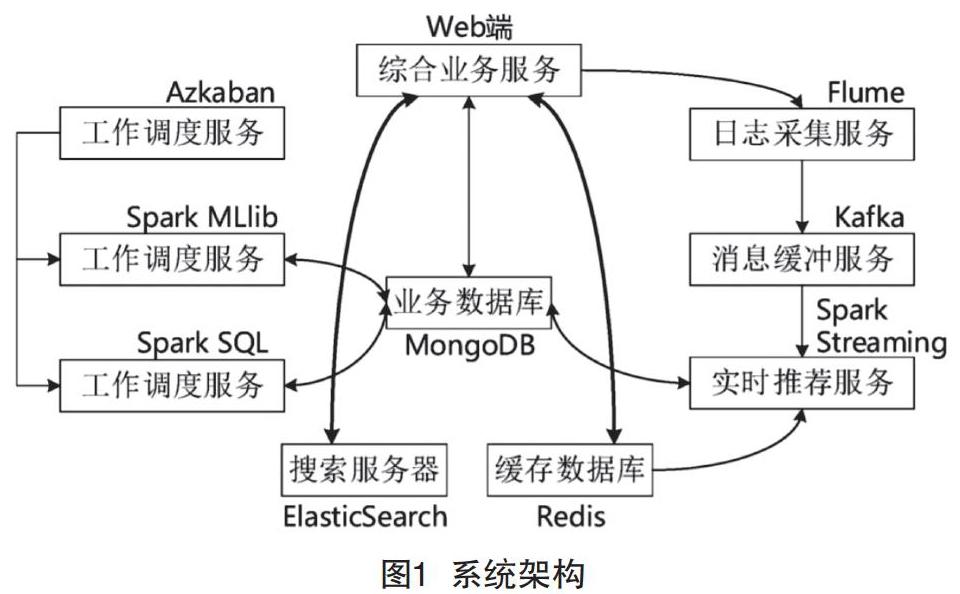
该推荐系统的整体业务的实现将Web端由前端AngularJS用户可视化框架和后台响应业务请求的Spring框架组成,并结合MongoDB数据库和Spark生态服务部分组件完成[4-6]。系统架构如图1所示。
2 电影推荐系统的结构设计
系统的結构设计可以分为4个模块:系统初始化、离线推荐、实时推荐、业务实现。
(1)系统初始化部分。在系统的初始化中主要任务是经Spark SQL将初始化后产生的数据加载进MongoDB和ElasticSearch里面。
(2)离线推荐部分。首先,经Azkaban操作离线的统计请求对离线推荐服务进行调度,然后在预先设好的运行时间周期实现任务的触发执行操作。其次,实现离线统计服务在MongoDB业务数据库,其进行数据的加载,使电影的“平均评分统计”“评分个数统计”以及“最近评分个数的统计”的统计算法运行处理得到结果,然后将计算结果回写入MongoDB;实现离线推荐服务在MongoDB进行数据的加载,然后利用基于ALS的协同过滤算法进行处理,把“用户推荐结果矩阵”“影片相似度矩阵”写入MongoDB。
(3)实时推荐部分。通过Flume在总体的服务架构下得到的运行日志里面读取信息,查看更新日志,然后让更新后的信息实时转发给Kafka;Kafka接收到日志信息后,经KafkaStream对获得的日志信息实现过滤处理操作,从而获得产生用户的评分数据流“UID | SCORE | TIMESTAMP”,并转入进其他的已经备好的Kafka队列中;Spark Streaming通过实现对Kafka队列的监听,可以及时接收到Kafka过滤后产生的有关用户的评分数据流,然后在Redis中的最近评分队列中实现融合存储操作,实时推荐算法接受并实现最新推荐结果的计算预测;算法处理结束后,将新产生的推荐结果和之前MongoDB业务数据库中原有的数据进行合并。
(4)业务部分。第一,推荐系统的成果演示功能中在MongoDB和ElasticSearch里让最终的离线推荐、实时推荐以及内容推荐产生的所有结果实现混合,进而总体得到对应的数据。第二,信息查询业务功能连接MongoD进行电影信息的查询功能处理。第三,在电影评分功能当中,接收前台UI响应用户进行的评分操作,后端服务对数据库日志进行记录之后,把数据推送到Redis群当中,并且把之前设定好的日志框架输出到Tomcat的日志当中。第四,系统的检索功能ElasticSearch搜索服务器进行电影信息的模糊查询操作。第五,电影标签功能中主要是用户可以通过客户端对电影的标签进行手动添加。推荐效果如图2所示。
3 结语
通过设计并实现一个简单的个性化电影推荐系统,对大数据平台下Spark数据处理、机器学习基础以及推荐算法的架构有了进一步的学习,同时也初步了解了推荐算法的一些具体流程,本系统包含了电影的实时推荐离线推荐、热门电影推荐、基于ALS算法的协同过滤推荐、基于模型的推荐、基于内容的推荐、基于统计的推荐、用户注册登录和电影展示等功能。未来的学习研究任务将kmeans和深度学习等模型结合进行推荐,从而提高推荐的准确率和多样性。
[参考文献]
[1]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2]史爱武,李险贵.基于Spark和微服务架构的电影推荐系统设计与实现[D].武汉:武汉纺织大学,2021.
[3]雷畅.基于Spark的电影推荐系统的设计与实现[D].武汉:华中科技大学,2020.
[4]张志威.个性化推荐算法研究综述[J].信息与电脑(理论版),2018(17):27-29.
[5]林子雨.大数据技术原理与应用:概念、存储、处理、分析与应用[M].北京:人民邮电出版社,2017.
[6]刘祥,熊晓明,王艺航,等.一种基于Spark的电影推荐系统及方法,CN:110717093A[P].广东:广东工业大学,2020.
(编辑 傅金睿)
