大数据分析中的计算智能研究现状与展望
2021-09-13潘泽波
潘泽波
摘 要:伴随着科学技术的快速发展,大数据技术以及相关应用已经得到众多行业工作者的关注与认可。如何分析大数据,如何更有效地挖掘大数据的潜在价值,也同样成为技术自身成长的关键节点。文章针对大数据分析中的计算智能研究展开初步分析与探讨,希望可对行业工作者起到一定借鉴作用。
关键词:大数据应用;大数据技术;计算智能
0 引言
计算智能是人工智能技术不断发展与延伸的重要成果,计算智能源于自然智慧与人类智慧,其主要目的在于解决一系列传统逻辑程序所无法解决的复杂难题。计算智能运行过程中,不需要去创建对应的数学模型,也不需要相关知识体系作为内涵表达,而是依靠大量数据,对输入信息进行综合分析与处理。计算智能的这一特点,使其与大数据分析工作有着天然的共性,大数据应用借助计算智能,可以快速完成图像处理、模式识别、知识获取、经济管理与智能控制等诸多工作,其所取得的实际成效,更是让大数据技术应用进入全新时期,而大数据技术的发展,也让计算智能迎来全新的机遇与挑战[1]。
1 大数据技术概述
大数据并不是一个新鲜事物。早在20世纪70年代,国外行业工作者为实现对经济领域各项数据的快速统计,监督各类企业的生产状况,并预估经济宏观走势,发现经济生活中的不稳定因素,开始大数据应用的初步探索。但是,当时的计算机软件与硬件条件均与实际应用需求之间存在巨大差距。现如今,大数据技术与应用已经初步成熟,其定义也拥有多种描述,从直观角度分析[2],大数据是指数据规模达到PB乃至EB级别的大量数据,并且,这个数据量无法利用传统的逻辑方法与软硬件实现快速分析处理与感知管理。在大数据应用过程中,需要采用全新的数据处理模式,提高实际工作的决策力、洞察力与流程优化能力。因此,大数据本身已经成为一个宽泛的概念,其同时涵盖数据的采集、处理、分析与解释等众多技术与手段。
2 大数据分析中的计算智能方法
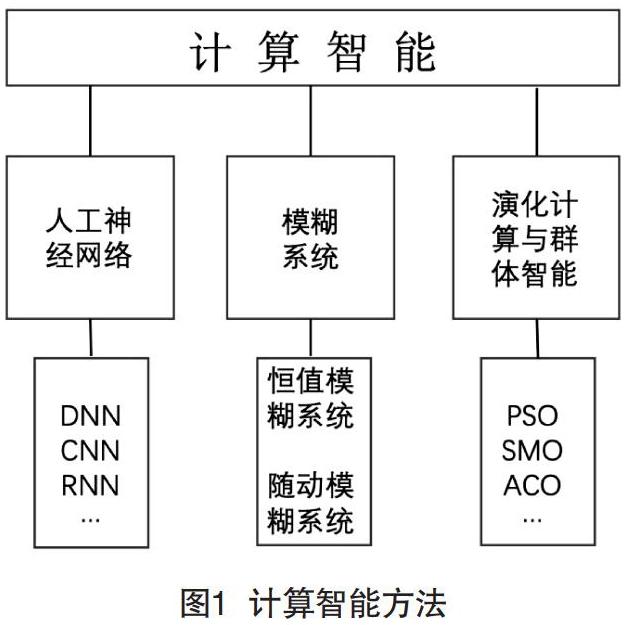
随着人工智能技术的快速发展,计算智能已经逐步演变为3个主要分支,分别为人工神经网络、模糊系统与演化计算。这3个相对成熟的分支亦可相互融合,并由此产生全新的数据利用与开发模式。因此,计算智能从其运用特性角度分析,在大数据分析与应用中有着巨大的发展空间。计算智能方法详细如图1所示。
2.1 人工神经网络
人工神经网络是一种对动物神经系统特征进行模仿的分布式并行数据信息处理模型,而这一模型又同时具备较强的自适应能力、较好的容错性与映射能力,并同时具备分布存储的特性,是计算智能分支中最为重要的一种核心模式。对于神经网络模型应用而言,数据不需要具备任何概率分布特征,与传统统计学与逻辑思维相比,实际限制很少。在人工神经网络中,感知器是一种最为经典的在线学习模型,并根据预测结果的正确性来决定相关样本的权重[3]。当前,感知器在线学习算法涵盖投票感知、均值感知、权重多数感知、被动主动感知、置信度权重感知与核感知器算法,而这些手段的存在,让人们在数据生产与采集层面的能力日益增强,数据规模与维度也在不断扩大。人工神经网络的存在也同样解决高维数据所存在的两项基本问题:其一,应用过程不再关注数据的全部属性,数据中的冗余信息与噪音将会被彻底排除;其二,将数据进行有效简化,消除高维数据在性能应用层面的约束,在不提高计算代价的前提下,提高其实际应用效率。
2.2 模糊系统
大数据应用体系下,所采集的数据在精度与状态层面存在随机化与非线性的特点,并存在自然环境等各类不可控因素干扰。因此,大数据本身是一种相对模糊的数据,例如电商网站、社交网络等,这些站点用户所发表的内容带有很强的个人倾向,而不是传统逻辑层面的好与坏,喜欢与不喜欢,这种内容在意图层面十分模糊且自带不确定性,难以用语言进行细节化分类。此外,大数据所对应的不同事物之间也带有明显的过渡性与不分明性,逻辑层面不再是非此即彼的现象,这一过程虽然对传统逻辑思维有着极大的挑战,但是对于计算智能的模糊系统而言,其利用模糊聚类方法,却可以快速找到数据的巨大潜力与价值。模糊聚类方法是一种非监督性质的学习模式,可以快速找到数据中的隐含信息,维持数据在空间与时间层面的准确性[4]。提高模糊聚类算法的策略在于采样、在线处理与分布式计算,并快速找到不同算法的适用场景,针对性地提供必要的选择策略。基于核的模糊聚类算法需要同步完成如何选择核、如何确定策略适用场景,并进行深入分析与探讨。
2.3 计算智能在大数据应用中存在的问题与未来的研究方向
计算智能虽然可以为大数据应用快速处理各类非确定性的复杂问题,但是,其本身也为大数据分析过程带来诸多问题:
数据规模的大量膨胀让分析时间变长,计算复杂度迅速提升,原本可以适用的策略也在落后。
数据的产生是持续性的且不断变化,很多数据无法直接进入计算机的存储空间,更无法快速保存其历史样本,这就导致其分析过程无法像传统批量算法应用过程构建=合理的无偏训练集。
随着人们数据采集与生产层面的能力不断增强,数据属性更显多维度,而传统的简化与分组方式,也逐渐无法应对数据稀疏与复杂的特点[5]。
针对以上问题与挑战,大数据应用与分析的未来研究方向可分为以下几点:
(1)提高計算智能算法的可拓展性与业务容纳能力,保证其在问题规模扩大时,算法或模型可以有效提高数据在时间与空间层面的质量。针对技术的发展,可以将这些策略分为4种,分别为:在线优化算法、随机化算法、基于哈希策略的算法以及大规模集群分布式算法。
(2)进一步发展分而治之的策略,将复杂问题逐步简化,减少大规模复杂问题的处理时间,提高处理质量,依靠子问题的解决实现全部问题的快速解答。
(3)进一步发展粒计算理论与模型,实现对问题的多层次与多角度分析,并保证粒度间的灵活性,为各类复杂问题寻找更为有效的全新解决模式。
(4)提高对数据集规律的排查能力,可通过降低部分子集数据准确性,用以提高数据分析在时空层面的消耗,并利用子集来寻找大数据所蕴藏的深层规律。
(5)针对持续性输入数据,可利用概率分布随机取样的方式,对持续性流数据进行在线处理,并推进各类结果的快速融合,当数据分布发生变化时,也要确保其分析结果的稳定性,并快速完成降噪工作。
(6)提高对数据规律变化的应对能力,建立数据动态分析模式,针对大数据的演化机制,提升数据的利用价值。
(7)进一步降低数据中的弱约束规则,提高对各类数据源中冗余信息的处理效果,确定各类事件的空间位置关系、时间先后关系以及触发关系等。
(8)提高对低价值密度数据的应用能力,检测数据中的异常模式,针对数据异常现象,建立应用策略。
(9)提高数据分析对各种领域知识的结合能力,使其形成更为精准的领域模型,建立更为准确的数据分析方式,提高数据分析结果的可解释性[6]。
3 结语
综上所述,大数据技术在为计算智能提供巨大机遇的同时,也让相关理论发展面临严峻挑战,而未来计算智能的发展,也需要结合大数据应用过程中所展露出的实际问题与需求进行进一步调整,进而提高计算智能在大数据分析中的潜力,展现数据内在价值。现如今,大数据分析工作中的计算智能策略依旧处于探讨与技术摸索阶段,很多问题依旧困扰着技术与应用发展,需要做进一步研究。
[参考文献]
[1]邱宇,王持,齊开悦,等.智慧健康研究综述:从云端到边缘的系统[J].计算机研究与发展,2020(1):53-73.
[2]于洪,何德牛,王国胤,等.大数据智能决策[J].自动化学报,2020(5):878-896.
[3]杨扬,刘圣,李宜威,等.大数据营销:综述与展望[J].系统工程理论与实践,2020(8):2150-2158.
[4]郭平,王可,罗阿理,等.大数据分析中的计算智能研究现状与展望[J].软件学报,2015(11):3010-3025.
[5]吴俊杰,刘冠男,王静远,等.数据智能:趋势与挑战[J].系统工程理论与实践,2020(8):2116-2149.
[6]WEI W,MOHSEN G,SYED H A,et al.Guest editorial:special section on integration of Big Data and artificial intelligence for Internet of Things[J].IEEE Transactions on Industrial Informatics,2020(4):2562-2565.
(编辑 王雪芬)
