基于BILSTM的棉花价格预测建模与分析*
2021-09-13江知航王艳霞颜家均周堂容
江知航,王艳霞,颜家均,周堂容
(1.重庆师范大学计算机与信息科学学院,重庆市,401331;2.重庆市江津区农业工程建设服务中心,重庆市,402260;3.重庆市数字农业服务工程技术研究中心,重庆市,401331;4.重庆市江津区农产品质量安全中心,重庆市,402260;5.重庆市江津区圣泉街道农业服务中心,重庆市,402218)
0 引言
伴随着现代农业的迅速发展,国内外众多投资者和从业者的目光由房地产、金融等热门领域转向农产品领域。作为我国第二大经济作物的棉花也受到了广泛的关注。准确预测棉花波动和价格的走势已经成为了新的研究重点。国内外对棉价的预测进行了相当多的研究[1],人们最开始使用传统的数学模型,主要是用统计学相关的方法,即根据经验进行预测。而后基于简单智能预测方法进行预测,虽然克服了传统方法易受人为主观性影响的问题,但也易陷入局部极小点,导致预测精度不高等问题。为了降低这种风险,随着深度学习人工智能算法的不断迭代和技术的不断革新发展,使用深度学习进行语义分类[2],机器翻译[3],图像识别[4],价格预测[5]等研究等已经掀起了新一轮的技术浪潮。对于具有时间序列和非线性等特征的数据,一些先进的集成算法和深度学习算法由于具有高精度和良好的鲁棒性已逐渐成为价格预测问题的最佳选择。
吴叶等[6]采用平均影响值(MIV)、遗传算法(GA)与BP神经网络相结合的方法探究MIV-GA-BP神经网络模型对我国棉花价格预测的情况,以国家棉花价格指数为棉花价格波动的重要反映指标,试验认为该组合模型较之于单一模型,拟合精度良好。郭超[7]通过BP神经网络,搭建了棉花价格波动动态模型,检验发现,检测值与目标原值误差控制在较小范围内,训练所得的神经网络模型可以对棉花价格指数进行准确的预测,较好的揭示了棉花价格的系统结构和规律。闫庆华等[8]以2004/2005—2015/2016年国际棉花现货价格月度数据为依据,理论分析了国际棉花现货价格的波动情况,并使用ARIMA模型实证分析了短期内国际棉花现货价格的波动趋势,相对误差在5%以下。赵梅等[9]利用2003年1月—2014年12月的棉花价格指数月度数据,将月度数据划分为训练集和测试集,构建ARIMA和平滑ARIMA模型对2014年11月和12月的棉花价格进行短期预测,基于差异率进行对比分析,结论表明平滑ARIMA模型的预测棉花价格指数精度优于ARIMA模型,Hudson等[10]通过选取美国棉花价格波动的供需关系、棉花种植、产量、天气等影响因素,构建了ARCH/GARCH的回归模型,并进行了分析研究,Bailey等[11]通过随机时间序列方程分析了美国棉花现货价格与期货价格之间的相关性,并预测了当前现货市场的价格。
从当前的研究成果来看,大多学者在棉价预测的特征选择上主要是基于政策、棉花产销、对外贸易、期货市场等因素进行的研究分析。研究表明[12-14],气候变化对农作物生产发育的影响是巨大的,不同的气候条件所产出的农作物商品质量和产量也具有较大的差异性,生产种植的变化从而引起其供需的变化,进而影响棉花价格。在棉花价格预测方法、网络模型的选择上主要采用较传统的简单智能预测方法和简单的神经网络结构模型,对于目前应用广泛的深度学习方法在棉花价格预测方面的应用研究甚少。针对目前棉花价格预测存在的问题,本文对于数据特征选择不仅考虑了影响价格的直接因素如进出口贸易、棉花产销等,也收集整理了气象气候条件和农产品生长生命周期中重要的降水、日照、湿度等数据,在对其进行数据处理后参与模型运算。在棉花价格预测模型的选择上,本文采用LSTM[15]和BILSTM[16]两种神经网络结构进行棉花价格回归预测问题的研究,并且为了避免在模型的训练过程中随机梯度下降(SGD)法在梯度下降过程中的频繁波动,可能得到局部最优值。试验采用SWA优化算法取SGD轨迹的多点简单平均值对SGD进行优化,避免了SGD在梯度下降过程中的频繁波动问题,使其模型能将Loss和损失值收敛至全局最优,进一步提高训练的稳定性。
1 模型构建
1.1 棉花市场的数理分析
1.1.1 非平稳性
在基于传统计量经济方法(如Arma/Arima[17]自回归模型)的时间序列预测问题中,需要原始数据具有平稳性的特征。因此本文对近4年的棉花价格指数进行了Dickey-Fuller(ADF)检验,其检验结果如表1所示。

表1 Dickey-Fuller(ADF)检验结果Tab.1 Dickey-Fuller(ADF)test result
如表1所示,ADF检验结果中的Test Statistic为-2.852 254,在1%和5%的置信区间下,无法拒绝原假设,P-value值较大。可以认为该数据是不稳定的。本文针对检验情况进行了差分处理,检验结果显示,二阶差分后的数据拒绝原假设,可以认为数据是平稳的。
1.1.2 高噪音性
棉花价格的数理特征之一是时间序列数据具有较强的白噪声。如果用统计模型来进行棉花价格预测,则需要对时间序列数据进行预处理,才能将其引入模型进行计算,否则就没有规则可循。而进行差分运算后,则难以表现市场原始数据规律。
1.1.3 多变量
棉花价格指数的影响因素是多样且互相关联的,并不是以独立个体影响因子单独存在,在实际市场环境中,棉花价格除了受到基本的供需关系因素影响以外,还受到国际汇率、资金流动及进出口费额因素、气象因素、政策因素的共同影响。
综上,棉花价格预测具有多变量、非线性、高噪音、低频性等特点,因此本文选用Bilstm神经网络模型来预测棉花价格序列是最优选择。
1.2 LSTM和BiLSTM神经网络结构及原理介绍
长短期记忆网络(Long short-term memory,LSTM)实质上可以理解为一种特殊的RNN,主要是为了解决RNN网络在长序列训练过程中发生梯度消失和梯度爆炸的问题。相比于RNN,LSTM主要是引入了细胞形态(cell state)用于保存长期状态,而LSTM的关键就在于如何控制长期状态c,从而引用了控制门的机制,该机制可以去除或者增加信息到细胞状态的能力。通过sigmoid函数将门输出为[0,1]的实数向量。当门输出为0时,乘以该向量的任何向量都将得到0向量,即判定为不能通过。当输出为1时,乘以任何向量都不会改变其原值,即可以通过。神经元中加入了输入门(input gate),遗忘门(forget gate),输出门(output gate),以及内部记忆单元(cell),其网络结构图如图1所示。

图1 LSTM网络结构Fig.1 LSTM network structure
在LSTM神经网络训练学习的过程中,第一步是由遗忘门(forget gate)决定从细胞状态中丢弃哪些信息。该步骤会读取和输入数据点乘计算得到一个输出值,其决定了上一时刻的状态有多少会保留到当前时刻。计算公式如式(1)所示。
ft=σ(Wf×[ht-1,xt]+bf)
(1)
式中:xt——当前细胞的输入;
ht-1——cell的前一次输出;
Wf——遗忘门的权重矩阵;
bf——遗忘门的偏置项;
σ——sigmoid函数。
第二步,将确定哪些新信息将会被添加到网络结构或细胞状态中。计算公式如式(2)所示。
it=σ(Wi×[ht-1,xt])+bi)
(2)
式中:Wi——输入门的权重矩阵;
bi——输入门的偏置项。
(3)
式中:Wc——计算细胞状态的权重矩阵;
bc——计算细胞状态的偏置项。
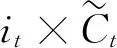
(4)
第四步,需要决定输出怎样的信息。计算公式如式(5)和式(6)所示。
Qt=σ(Wo×[ht-1,xt]+bo)
(5)
ht=ot×tanh(Ct)
(6)
式中:Wo——输出门的权重矩阵;
bo——输出门的偏置项。
LSTM是一个单向的循环神经网络,模型实际上只接收到了“上文”的信息,而没有考虑到“下文”的信息,在实际应用场景中,输出结果可能需要由前面若干输入和后面若干输入共同决定,获取到整个输入序列的信息,而BILSTM网络就可以同时保存双向数据信息。一个完整的BILSTM网络包含输入层,前向LSTM层、反向LSTM层和输出层。
图2所示,在Forward层从1时刻到t时刻正向计算一遍,得到并保存每个时刻向前隐含层的输出,wf表示为前向LSTM层。该步骤数学表达公式如式(7)所示。
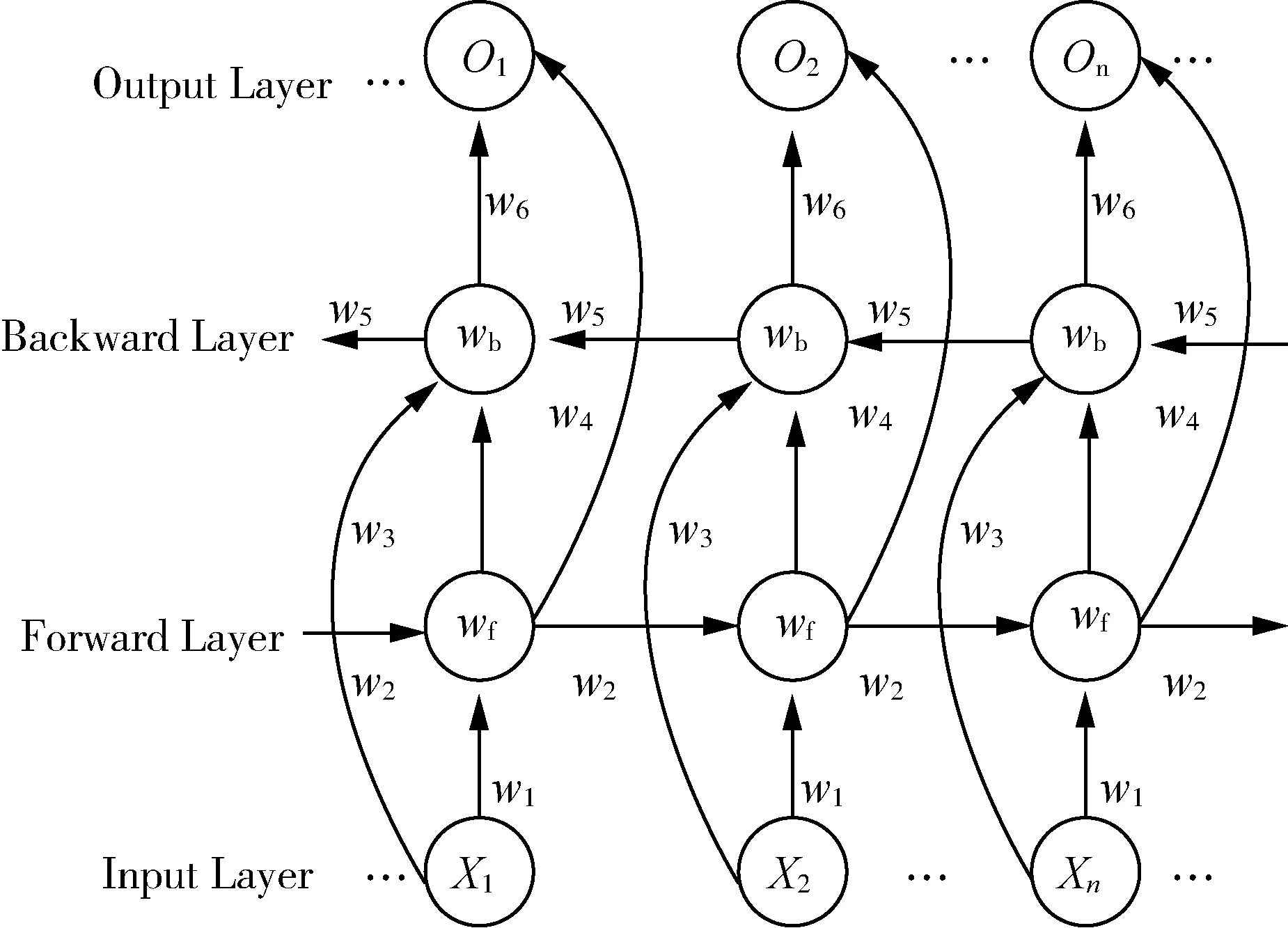
图2 BILSTM网络结构图Fig.2 BILSTM network structure
ht=f(w1xt+w2ht-1)
(7)
在Backward层沿着时刻t到时刻1反向计算一遍,得到并保存每个时刻向后隐含层的输出,表示为后向LSTM层。该步骤数学表达公式如式(8)所示。
h′t=f(w3xt+w5h′t+1)
(8)
最后,在每个时刻将正向层和反向层在相应时间的输出结果进行组合从而获得最终输出,该输出结合了双向输入序列的信息。该步骤数学表达公式如式(9)所示。
ot=g(w4ht+w6h′t)
(9)
1.3 神经网络搭建
本文所有试验均基于Windows操作系统下,试验通过搭建CPU版本的Keras框架,利用该框架下内置神经网络结构进行模型搭建。编程环境为Python3.7,三方扩展库包括Numpy、Pandas、Matplotlib、Keras、Sklearn等。在本文试验中采用LSTM、BILSTM神经网络与全连接层的连接方式,对棉花价格进行回归预测试验,同时添加Dropout机制避免过拟合现象,提升模型泛化能力,模型采用MAE作为损失函数,SGD优化器进行训练,然后采用SWA算法对传统SGD优化器进行优化训练。
Dense网络:又称为全连接层,主要用于综合隐藏层提取的特征数据。
ReLu函数:称为线性整流函数(Rectified Linear Unit),是一种神经网络中最为常用的激活函数(activation function)主要目的是为得到神经网络更为丰富的假设空间,防止梯度消失,加速梯度下降的收敛速度。
SGD优化算法:主要用于对样本进行梯度更新,在反向传播时不断更新其权值。
正则化Dropout:主要用于防止过拟合使其不依赖某些局部特征,强化模型的泛化能力。
BILSTM、LSTM模型网络结构和神经元个数分别如图3(a)和图3(b)所示。

(a)BILSTM神经网络模型
图3(a)为BILSTM神经网络价格预测模型,其结构如下。
结构第一层为LSTM层的初始神经元个数为128。结构第二层为BILSTM,初始神经元个数为128,激活函数使用ReLu。结构第三层为全连接层,神经元个数为128,激活函数使用ReLu。结构第四层添加正则化Dropout,参数按0.25比例随机置0。结构第五层为全连接层,神经元个数为64,激活函数ReLu。结构第六层添加正则化Dropout,参数按0.25比例随机置0。结构第七层为输出层,输出维度为1,激活函数使用PReLu。
LSTM神经网络模型采用同样的网络结构和神经元个数,网络优化器和损失函数与BILSTM模型均保持一致。不同之处为该模型将BILSTM神经网络舍弃,用LSTM神经网络进行模型预测训练和论证。图3(b)即LSTM价格预测模型,其结构如下。
结构第一层为LSTM,初始神经元个数为128。结构第二层为LSTM,初始神经元个数为128,激活函数使用ReLu。结构第三层为全连接层,神经元个数为128,激活函数使用ReLu。结构第四层添加正则化Dropout,参数按0.25比例随机置0。结构第五层为全连接层,神经元个数为64,激活函数ReLu。结构第六层添加正则化Dropout,参数按0.25比例随机置0。结构第七层为输出层,输出维度为1,激活函数使用PReLu。
2 数据准备及预处理
2.1 数据来源
本文选取了棉花日价格指数、种植面积、单位产量、棉花产量、纱产量、进口量、进口费额、出口量、出口费额、汇率(美元)、平均本站气压、日最高本站气压、日最低本站气压、平均气温、日最高气温、日最低气温、平均相对湿度、小型蒸发量、大型蒸发量、日照时数、平均地表气温、日最高地表气温、日最低地表气温等变量。数据主要来源于中国棉花协会,国家统计局,中国海关,中国国家气象局,中国人民银行数据中心板块,均为国家官方机构或研究机构开放共享的官方统计数据,统计数据时间周期为2016—2019年。这些变量共同组成了本文原始数据集。
2.2 数据预处理
原始数据集有可能会存在缺失值、异常值的情况,本文对原始数据进行插值补全,排序等操作,从而得到了更加有效完整的数据集。在将棉花数据喂入网络模型时,由于其产量、价格指数、进出口费额等参数作为特征输入时,与其他特征量纲差距过大,如其指数和费额多在千万量级,而气象特征多在几或几十量级。需对数据集进行归一化操作,主要目的是为了消除各特征变量大小的影响以及不同量纲带来的影响,归纳统一样本的统计分布性。归一化后的数据可以加快模型训练阶段的求解和收敛的速度,也可以提高预测的精度。避免由于不同量纲导致的部分特征变量贡献率过大,即将数据统一映射到[0,1]的区间上。归一化方法有很多,本文选用Min-max归一化(Min-max normalization)进行处理,数学方法如式(10)所示。Min-max归一化是对原始数据的线性转换。其中x为原始输入数据,min为样本数据中的最小值,max为样本数据中的最大值。
(10)
根据我国棉花市场的相关要求,所获取的棉花市场日交易数据均为工作日交易数据,因此其他特征均依照日交易价格指数日期进行处理,从而构建出了更加完整科学的数据集。数据集总共包含棉花市场共24个特征指标,共27 513条数据。
3 试验与分析
3.1 确定评价指标
本文所采用的模型预测性能评价指标均采用平均绝对误差(MAE)和均方根误差(RMSE)来对试验结果进行对比分析[18]。其中MAE是绝对误差的平均值,RMSE是预测值和实际观测之间平方差异平均值的平方根,其数学表达计算公式如式(11)和式(12)所示。
(11)
(12)
3.2 时间序列转监督学习
在使用BILSTM和LSTM神经网络进行时间序列预测问题的试验时,其实质在于将时间序列的问题转变为有监督学习的问题,从仅仅是一个序列,变成成对的输入和输出。
表2中左半部分为棉花价格指数部分数据,右半部分则演示为基于前两个时刻,即Var(t-1),Var(t-2)表示为输入变量X为t-1时刻的价格指数和t-2时刻的价格指数。得到输出Y时刻的价格指数,即Var(t)。则当前天,前一单位历史特征为监督学习标签序列整体滞后一个单位,前两单位历史特征为监督学习标签序列整体滞后两个单位,以此类推。根据多次试验结果的对比,本试验中取历史特征为18个单位为最优值,表示参考前24,48,72……18×24个交易日数据作为历史数据特征,即将该月前18个月的价格特征作为输入参与模型运算。在本文的试验中,主要使用了python第三方库pandas科学计算包中的series_to_supervised()函数完成多元变量时间序列的转换。
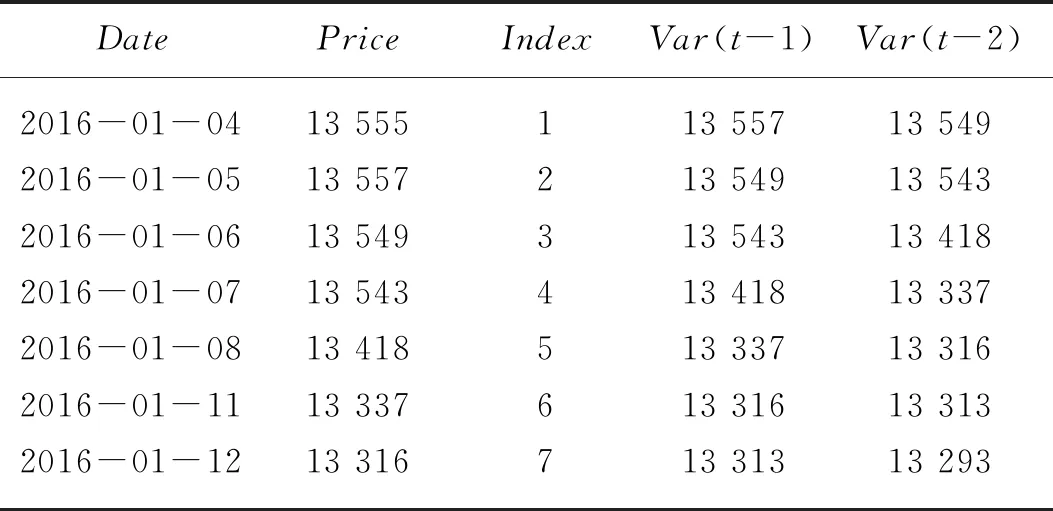
表2 棉价指数转化为有监督学习问题示例Tab.2 Example of converting cotton price index into supervised learning problem
3.3 BILSTM模型实证分析
本文将2016年1月4日—2019年9月的棉花价格指数及其他特征向量用于训练和验证,采用五折交叉验证方式,将数据集分成五份,轮流将其中4份做训练1份做验证。增强模型的泛化能力。将2019年10月为模型测试集。本试验中,每一层权重初始化都采用Glorot正态分布初始化方法,减少loss陷入局部最优的概率。在训练过程中,增加了学习率衰减的操作,即训练过程中若训练Loss值在50轮内无下降,则将学习率×0.1,避免由于学习率过大而跳过全局最优值。以此更为精细的调整网络。
图4中反应了BILSTM模型在训练过程中每次迭代后的训练集和验证集的损失情况。
(a)损失值
可以看到在模型迭代至100次时,损失值大幅度减小,迭代至300次时,损失值减小至0.021 5,训练误差和验证误差均已趋于平稳,差值较小,表明此模型的泛化水平和拟合效果较好,未出现过拟合和欠拟合的情况。根据训练集和验证集的迭代数据显示,模型在一定程度上能够找到全局最优值,且能够得到较好的收敛。因此模型的各项参数和权重得以确定,接下来调用keras框架中的.fit()方法对2019年10月的24个工作日的价格指数展开预测,并与真实值进行拟合对比。
图5展示了该模型在预测集上的效果,可以看到模型预测值与真实结果拟合状况较好,棉花价格在一个较小的波动区间内变化,走势较为平滑。综合来看,本次试验中,真实值与预测值之间的MAE为60.773,RMSE为70.249,该模型与真实价格波动走势基本一致,这反映出BILSTM网络在基于时间序列回归预测问题的可行性。同时由图4可见,在模型收敛至接近全局最小值时,更新比较频繁,造成Cost Function在接近全局最优值产生震荡,导致准确度会稍显下降。
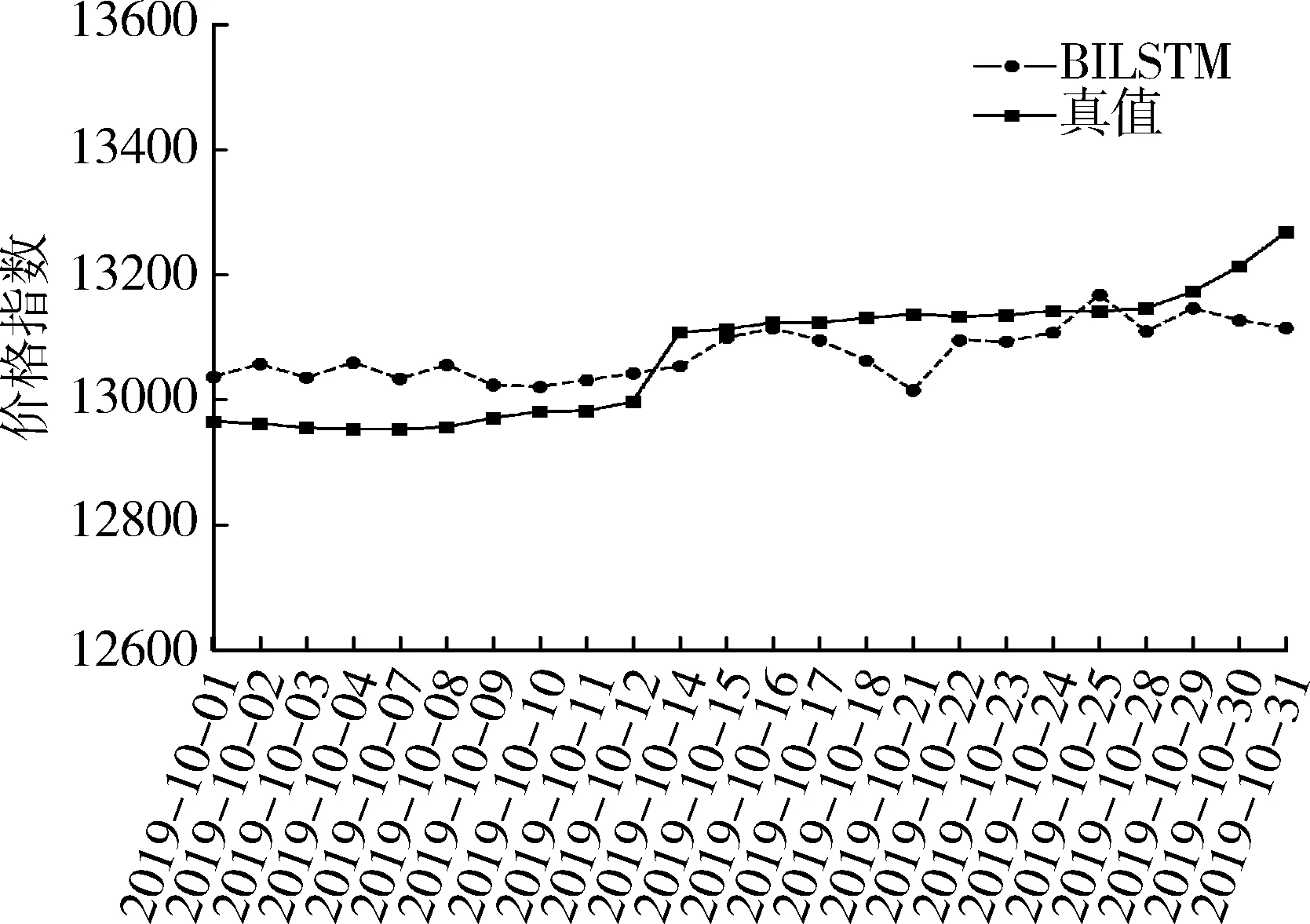
图5 BILSTM模型测试集结果Fig.5 BILSTM model test set results
3.4 LSTM模型实证分析
为保证不同模型间具有可对比性。该模型均采用BILSTM模型中所用的数据集、损失函数、评价指标和训练过程。同样的将2016年1月4日—2019年9月的棉花价格指数及其他特征向量用于训练和验证,采用五折交叉验证方式,将2019年10月为模型测试集。
图6反应了该模型在训练过程中每次迭代训练集和验证集的损失情况,可以看到在模型迭代至100次时,损失值大幅度减小,迭代至300次时,损失值减小至0.024 8,训练误差和验证误差均已趋于平稳,差值较小,表明此模型的泛化水平和拟合效果较好,未出现过拟合和欠拟合的情况。根据训练集和验证集的迭代数据显示,模型在一定程度上能够找到全局最优值,且能够得到较好的收敛。因此模型的各项参数和权重得以确定,接下来同样调用keras框架中的.fit()方法对2019年10月的24个工作日的价格指数展开预测,并与真实值进行拟合对比。
图7展示了该模型在测试集上的效果,可以看到模型预测值与真实结果拟合状况较好,棉花价格在一个较小的波动区间内变化,走势较为平滑。综合来看,本次试验中,真实值与预测值之间的MAE为62.44,RMSE为74.45,该模型与真实价格波动走势基本一致,同时由图6可见,在该模型收敛至接近全局最小值时,由于是基于SGD优化器进行梯度下降和迭代更新,出现了与BILSTM模型结构同样的问题。由于更新比较频繁,也出现了Cost Function现象,在接近全局最优值产生震荡,导致准确度会稍显下降。

(a)损失值
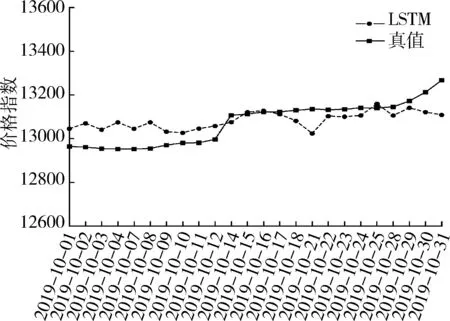
图7 LSTM模型测试集结果Fig.7 LSTM model test set results
3.5 SWA算法优化
基于上诉模型产生的震荡问题,本文采用SWA(随机权值平均)方法对模型使用的SGD优化器进行优化调整。研究表明该方法只需快速集合集成的一小部分算力,不用增加任何额外成本的情况下改进随机梯度下降的泛化。典型的深度学习网络训练过程就是用SGD或其他优化器对损失函数进行优化,使用一个衰减的学习率直到模型收敛。而SWA算法取SGD轨迹的多点简单平均值,使用一个变化的循环或高恒定学习率。
SWA的工作主要分为两个部分,首先SWA使用一个变化的学习率策略,迭代至一个相对较高性能,损失值收敛的网络。简单来说,例如第一步可以在前75%的训练时间和迭代周期内,使用标准衰减学习率策略。而后将剩余25%的训练时间和迭代周期中,设置一个相对较高的恒定学习率,对SGD遍历的网络权值进行平均,获取到最后25%训练时间内保持每个Epoch结束时获得的权值运行状态的平均值,如图8所示。
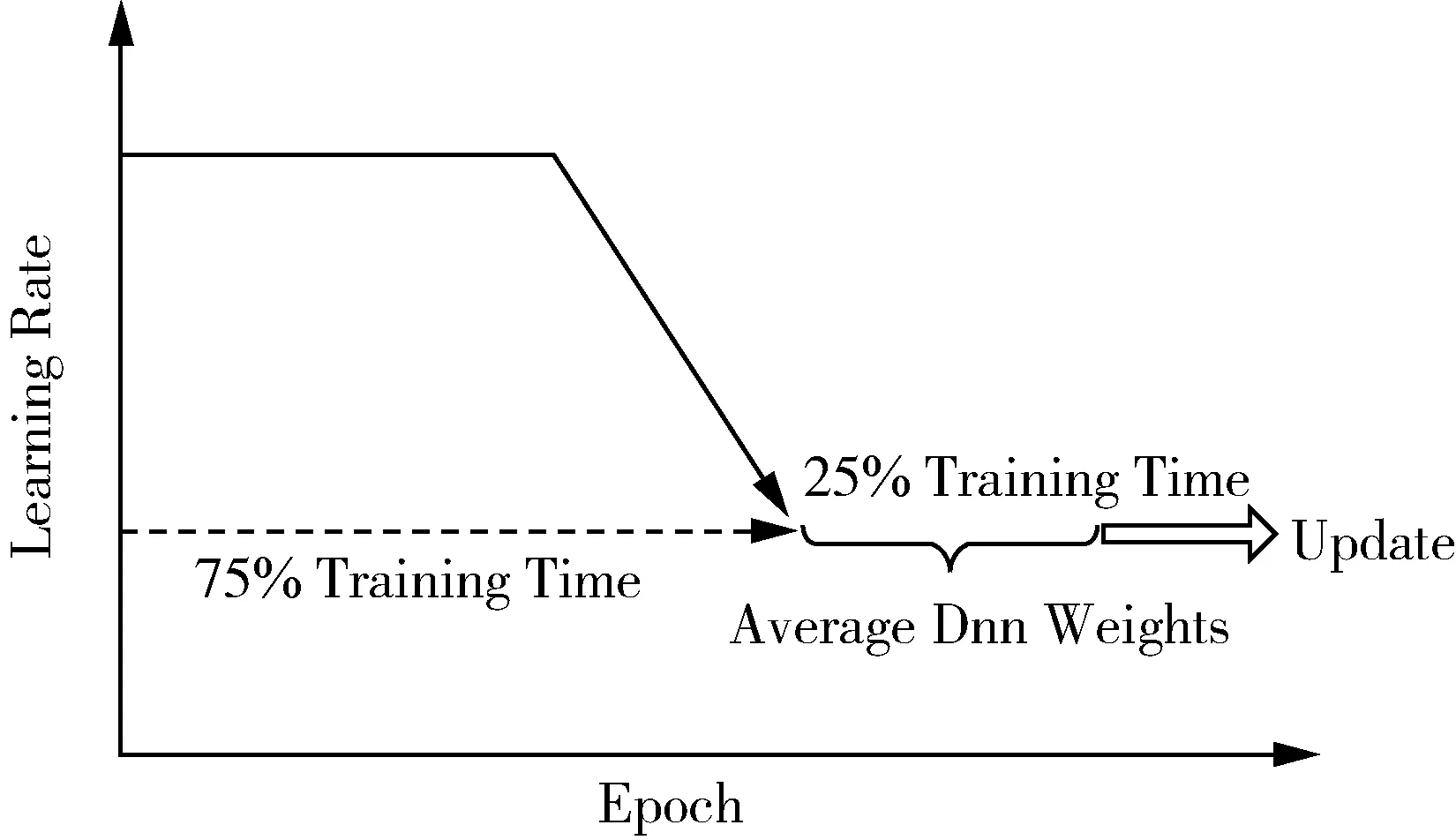
图8 SWA算法学习率策略Fig.8 SWA algorithm learning rate strategy
3.6 SWA算法优化后的实证分析
3.6.1 BILSTM模型实证分析
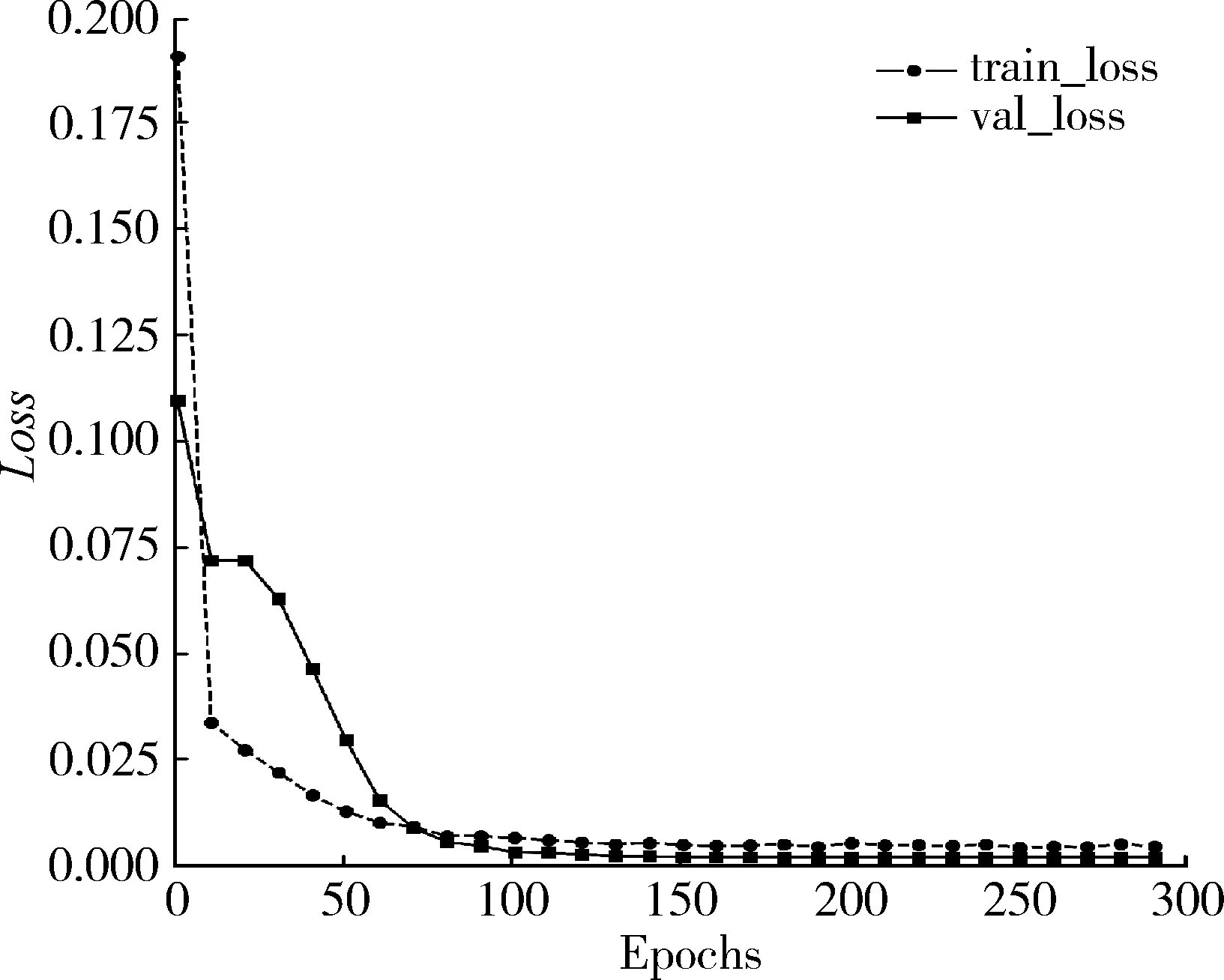
根据图9所示,使用SWA算法后的训练和验证损失能够收敛到最小值,且不会产生较大震荡。在很大程度上使模型的训练不至于陷入局部最优,能够使训练Loss收敛到更小值,拟合度更好。同时SWA类似模型集成,使模型更具鲁棒性和泛化能力。
图10展示了模型在通过SWA优化后的测试集上的效果,可以看到BILSTM+SWA模型的预测值与真实结果拟合状况较之余未优化之前的结果要好。综合来看,本次试验中,真实值与预测值之间的MAE为42.45,RMSE为68.6。可见搭建的预测模型具有良好的泛化能力,SWA算法也取得了良好的效果,试验达到了预期结果的要求。
(a)损失值
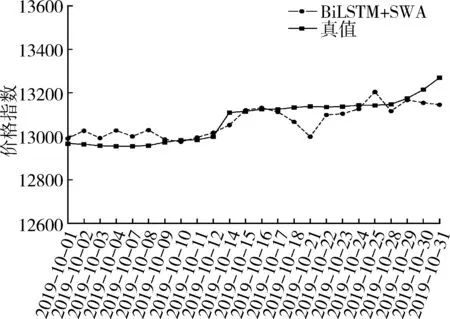
图10 SWA优化后的BILSTM模型测试集结果Fig.10 SWA optimized BILSTM model test set results
3.6.2 LSTM模型实证分析
本文为了进一步论证研究SWA算法在不同模型结构间是否具有优越的泛化性能,本文同样使用SWA算法对LSTM模型进行实证分析。
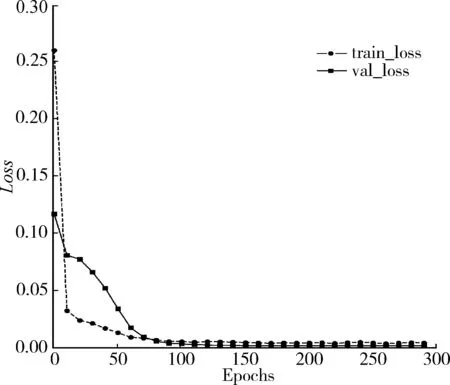
根据图11所示,利用SWA算法后的训练和验证损失同样能够收敛到最小值,且不会产生较大震荡。使LSTM模型的训练不至于陷入局部最优,能够使损失值收敛到更小值,拟合度更好。然后本文在对测试集进行预测,并与真实价格进行对比分析。
(a)损失值
图12展示了LSTM模型在通过SWA优化后的测试集上的效果,可以看到LSTM+SWA的预测值与真实结果拟合状况较之余未优化之前的结果要好。综合来看,本次试验中,真实值与预测值之间的MAE为52.62,RMSE为69.33。可见搭建的预测模型具有良好的泛化能力,SWA算法也取得了良好的效果,试验达到了预期结果的要求。
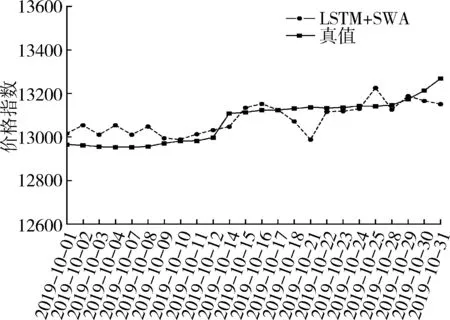
图12 SWA优化后LSTM模型的测试集结果Fig.12 SWA optimized LSTM model test set results
3.7 试验结果对比分析
为了进一步论证BILSTM模型在基于时间序列预测问题上的优越性和SWA优化后的模型性能和其算法的泛化能力。又分别建立了LightGBM单模型,并对其进行了对比试验,几种模型均采用MAE和RMSE为评价标准对同一数据集进行结果输出。结果如图13所示。

图13 几种预测模型的棉花价格预测结果Fig.13 Cotton price forecast results of several prediction models
为了更加清晰的对比这几种预测模型的优劣和结果,对各模型的误差值进行了对比分析,各个模型的误差如表2所示。
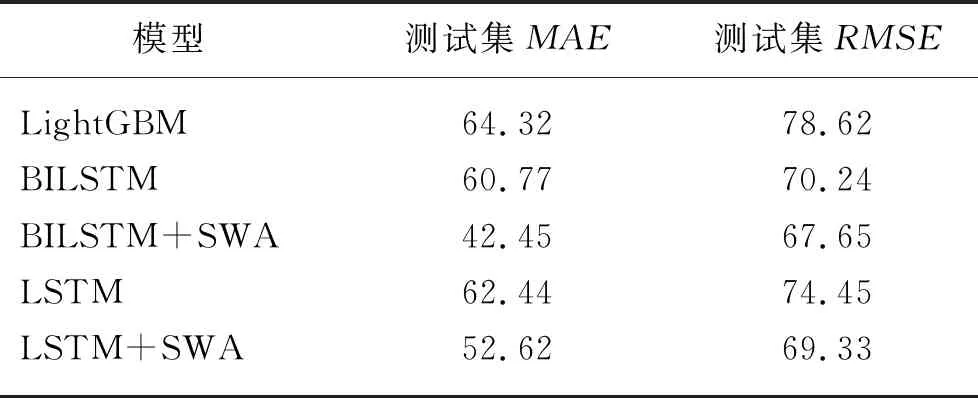
表2 棉花价格指数预测误差Tab.2 Cotton price index forecast error
由图13和表2中的对比试验分析得出:基于SWA优化的BILSTM预测模型的预测结果最优,说明BILSTM神经网络在基于时间序列的价格预测问题上同样可以取得非常好的效果。如图10中所示,BILSTM+SWA模型预测价格的曲线与真实曲线趋近一致,MAE为42.45,在棉花平均价格指数为15 388的大基数下,该误差非常小。该数据能够在一定程度上反映该模型的健壮性。LightGBM、BILSTM、LSTM单模型,其预测结果远差于SWA优化后的神经网络模型,说明SWA算法在寻求最优值域方面具有其优越的能力。同时将SWA应用于LSTM和BILSTM等不同的神经网络结构中,可以得出结论SWA算法具有较好的泛化能力,较之于未采用该算法之前,提升了LSTM模型的MAE值18%,BILSTM模型的MAE值43%,可以看出其在不同的神经网络和模型中可以取得不错的效果,具有良好的泛化能力。
4 结论
本文充分分析了棉花市场的时序信息和价格波动。在棉花价格预测问题中,特征选择上重点考虑了天气气象因素,模型的选择上使用BILSTM神经网络建立模型,并与LSTM神经网络模型和LightGbm模型进行对比试验,优化算法上使用SWA算法进行模型迭代和参数调优。
1)BILSTM神经网络与典型的时间序列预测模型相比,模型的数据拟合和预测性能整体更优。本文验证了BILSTM模型在回归预测领域中的可行性和适用性。
2)SWA优化算法可以帮助模型在梯度下降时寻找到最优值域,优化后的LSTM和BILSTM网络结构收敛至近似全局最优,平均绝对误差(MAE)分别提高了18%和43%,取得了良好的预测结果;与LightGbm单模型,LSTM+SWA、BILSTM+SWA组合的方式进行对比试验,SWA算法在不同的模型和网络结构间都表现出了不错的效果,具有较强的泛化能力。
3)通过上述的试验流程和结果分析表明,针对棉花市场的非线性、多变量、高噪音的特点,BILSTM神经网络应用于棉花价格指数预测取得了较好的效果,精度较高。该模型和优化方法在时间序列数据的研究中将会有更为广阔的应用和发展前景。
